Machine Translation of Languages and Dialects
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

I Year Dkh11 : History of Tamilnadu Upto 1967 A.D
M.A. HISTORY - I YEAR DKH11 : HISTORY OF TAMILNADU UPTO 1967 A.D. SYLLABUS Unit - I Introduction : Influence of Geography and Topography on the History of Tamil Nadu - Sources of Tamil Nadu History - Races and Tribes - Pre-history of Tamil Nadu. SangamPeriod : Chronology of the Sangam - Early Pandyas – Administration, Economy, Trade and Commerce - Society - Religion - Art and Architecture. Unit - II The Kalabhras - The Early Pallavas, Origin - First Pandyan Empire - Later PallavasMahendravarma and Narasimhavarman, Pallava’s Administration, Society, Religion, Literature, Art and Architecture. The CholaEmpire : The Imperial Cholas and the Chalukya Cholas, Administration, Society, Education and Literature. Second PandyanEmpire : Political History, Administration, Social Life, Art and Architecture. Unit - III Madurai Sultanate - Tamil Nadu under Vijayanagar Ruler : Administration and Society, Economy, Trade and Commerce, Religion, Art and Architecture - Battle of Talikota 1565 - Kumarakampana’s expedition to Tamil Nadu. Nayakas of Madurai - ViswanathaNayak, MuthuVirappaNayak, TirumalaNayak, Mangammal, Meenakshi. Nayakas of Tanjore :SevappaNayak, RaghunathaNayak, VijayaRaghavaNayak. Nayak of Jingi : VaiyappaTubakiKrishnappa, Krishnappa I, Krishnappa II, Nayak Administration, Life of the people - Culture, Art and Architecture. The Setupatis of Ramanathapuram - Marathas of Tanjore - Ekoji, Serfoji, Tukoji, Serfoji II, Sivaji III - The Europeans in Tamil Nadu. Unit - IV Tamil Nadu under the Nawabs of Arcot - The Carnatic Wars, Administration under the Nawabs - The Mysoreans in Tamil Nadu - The Poligari System - The South Indian Rebellion - The Vellore Mutini- The Land Revenue Administration and Famine Policy - Education under the Company - Growth of Language and Literature in 19th and 20th centuries - Organization of Judiciary - Self Respect Movement. Unit - V Tamil Nadu in Freedom Struggle - Tamil Nadu under Rajaji and Kamaraj - Growth of Education - Anti Hindi & Agitation. -

List of Participants
List of participants T.V. Gopal Iyer (Ti. V¹. Kºpàlaiyar) (b. 1925) has qualified himself for the Panditam title of the Madurai Tamil Sangam, Vidwan title, B.O.L. degree and B.O.L. (Hon.) degree of the University of Madras, has served as professor of Tamil in oriental Colleges for a period of 15 years, has edited Ilakkaõa Viëakkam (eight volumes, 1971-1973), Ilakkaõak Kottu (1973) and Prayºka Viv¹kam (1973), with elaborate self-sufficient notes for the research students, has been serving as a research scholar in EFEO Pondicherry since November 1978, has brought a (pre-)critical1 edition of T¹vàram (1984-1985), has prepared a grammatical lexicon of Tamil dealing with all the branches of Tamil Grammar, has prepared the press copy of MàŸa− Akapporuë and Tiruppatikkºvai with the new commentary written by him and with all the necessary notes, has prepared for a new edition of MàŸa− Alaïkàram and Vãracº×iyam in the same way, has prepared a Tamil version of the old maõipravàëam commentary of the six books by Tirumaïkai â×vàr, and now is preparing the two books Tolkàppiyam, E×uttatikàram—Nacci−àrkki−iyam, and Tolkàppiyam, Collatikàram—Nacci−àrkki−iyam, removing all sorts of mistakes found in the previous editions and supplying them with all the necessary notes for understanding them easily. R. E. Asher (b. 1926) is Professor Emeritus of Linguistics at the University of Edinburgh, where he also served as Vice-Principal. He holds the degrees of B.A. and Ph.D. in French of the University of London and a D.Litt. -

The Phases of Flower in Sangam Tamil Literature
SHANLAX s han lax International Journal of Arts, Science and Humanities # S I N C E 1 9 9 0 The Phases of Flower in Sangam Tamil Literature M. Anbarasu OPEN ACCESS Post Doctoral Fellow, Department of Agronomy (Farm) Agricultural College and Research Institute, Madurai, Tamil Nadu, India Manuscript ID: https://orcid.org/0000-0001-7970-4454 ASH-2020-08013161 D. Udhaya Nandhini Volume: 8 Post Doctoral Fellow, Centre of Excellence in Sustaining Soil Health Anbil Dharmalingam Agricultural College and Research Institute, Trichy, Tamil Nadu, India Issue: 1 Abstract A flower is the reproductive part of flowering plants. Within the flowering stage of flower had Month: July different phases like Arumbu / Bud, Mottu / Tender flower Bud, Mugai / Opening bud, Malar / Flower blossom, Alar / Full-blown flower blossom, Vee / Flower drying and Semmal / Faded flower Year: 2020 in Sangam Tamil literature. The Sangam Tamil literature was accompanied of Tamil scholars and poets that, according to phases flower are indicated in Thirukkural, Narrinai, Purananuru, P-ISSN: 2321-788X Kuruntokai, Silappatikaram, etc., This review is more useful to researchers for understanding the floral scent properties relation to phases of flower and associated with releasing dynamics for fragrant / scent out of flower. E-ISSN: 2582-0397 Keywords: Phases of flower, Sangam literature, Flower, Flower fragrant and floral scent. Received: 22.04.2020 Introduction A flower is the reproductive part of flowering plants (Angiosperms). The Accepted: 16.06.2020 first step of the transition is the transformation of the vegetative stem primordia Published: 02.07.2020 into floral primordia. This occurs as biochemical changes take place to change cellular differentiation of leaf, bud, and stem tissues into tissue that will grow Citation: into the reproductive organs. -

Officials from the State of Tamil Nadu Trained by NIDM During the Year 209-10 to 2014-15
Officials from the state of Tamil Nadu trained by NIDM during the year 209-10 to 2014-15 S.No. Name Designation & Address City & State Department 1 Shri G. Sivakumar Superintending National Highways 260 / N Jawaharlal Nehru Salai, Chennai, Tamil Engineer, Roads & Jaynagar - Arumbakkam, Chennai - 600166, Tamil Nadu Bridges Nadu, Ph. : 044-24751123 (O), 044-26154947 (R), 9443345414 (M) 2 Dr. N. Cithirai Regional Joint Director Animal Husbandry Department, Government of Tamil Chennai, Tamil (AH), Animal husbandry Nadu, Chennai, Tamil Nadu, Ph. : 044-27665287 (O), Nadu 044-23612710 (R), 9445001133 (M) 3 Shri Maheswar Dayal SSP, Police Superintending of Police, Nagapattinam District, Tamil Nagapattinam, Nadu, Ph. : 04365-242888 (O), 04365-248777 (R), Tamil Nadu 9868959868 (M), 04365-242999 (Fax), Email : [email protected] 4 Dr. P. Gunasekaran Joint Director, Animal Animal Husbandary, Thiruvaruru, Tamil Nadu, Ph. : Thiruvarur, Tamil husbandary 04366-205946 (O), 9445001125 (M), 04366-205946 Nadu (Fax) 5 Shri S. Rajendran Dy. Director of Department of Agriculture, O/o Joint Director of Ramanakapuram, Agriculture, Agriculture Agriculture, Ramanakapuram (Disa), Tamil Nadu, Ph. : Tamil Nadu 04567-230387 (O), 04566-225389 (R), 9894387255 (M) 6 Shri R. Nanda Kumar Dy. Director of Statistics, Department of Economics & Statistics, DMS Chennai, Tamil Economics & Statistics Compound, Thenampet, Chennai - 600006, Tamil Nadu Nadu, Ph. : 044-24327001 (O), 044-22230032 (R), 9865548578 (M), 044-24341929 (Fax), Email : [email protected] 7 Shri U. Perumal Executive Engineer, Corporation of Chennai, Rippon Building, Chennai - Chennai, Tamil Municipal Corporation 600003, Ph. : 044-25361225 (O), 044-65687366 (R), Nadu 9444009009 (M), Email : [email protected] National Institute of Disaster Management (NIDM) Trainee Database is available at http://nidm.gov.in/trainee2.asp 58 Officials from the state of Tamil Nadu trained by NIDM during the year 209-10 to 2014-15 8 Shri M. -

Tamil Nadu Public Service Commission Bulletin
© [Regd. No. TN/CCN-466/2012-14. GOVERNMENT OF TAMIL NADU [R. Dis. No. 196/2009 2015 [Price: Rs. 280.80 Paise. TAMIL NADU PUBLIC SERVICE COMMISSION BULLETIN No. 18] CHENNAI, SUNDAY, AUGUST 16, 2015 Aadi 31, Manmadha, Thiruvalluvar Aandu-2046 CONTENTS DEPARTMENTAL TESTS—RESULTS, MAY 2015 Name of the Tests and Code Numbers Pages. Pages. Second Class Language Test (Full Test) Part ‘A’ The Tamil Nadu Wakf Board Department Test First Written Examination and Viva Voce Parts ‘B’ ‘C’ Paper Detailed Application (With Books) (Test 2425-2434 and ‘D’ (Test Code No. 001) .. .. .. Code No. 113) .. .. .. .. 2661 Second Class Language Test Part ‘D’ only Viva Departmental Test in the Manual of the Firemanship Voce (Test Code No. 209) .. .. .. 2434-2435 for Officers of the Tamil Nadu Fire Service First Paper & Second Paper (Without Books) Third Class Language Test - Hindi (Viva Voce) (Test Code No. 008 & 021) .. .. .. (Test Code 210), Kannada (Viva Voce) 2661 (Test Code 211), Malayalam (Viva Voce) (Test The Agricultural Department Test for Members of Code 212), Tamil (Viva Voce) (Test Code 213), the Tamil Nadu Ministerial Service in the Telegu (Viva Voce) (Test Code 214), Urdu (Viva Agriculture Department (With Books) Test Voce) (Test Code 215) .. .. .. 2435-2436 Code No. 197) .. .. .. .. 2662-2664 The Account Test for Subordinate Officers - Panchayat Development Account Test (With Part-I (With Books) (Test Code No. 176) .. 2437-2592 Books) (Test Code No. 202).. .. .. 2664-2673 The Account Test for Subordinate Officers The Agricultural Department Test for the Technical Part II (With Books) (Test Code No. 190) .. 2593-2626 Officers of the Agriculture Department Departmental Test for Rural Welfare Officer (With Books) (Test Code No. -
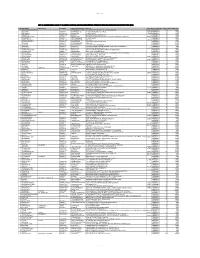
Unpaid Data 1
Unpaid_Data_1 LIST OF SHAREHOLDERS LIABLE TO TRANSFER OF UNPAID AND UNCLAIMED DIVIDEND DIVIDEND TO INVESTOR EDUCATION PROTECTION FUND (IEPF) S.No First Name Middle Name Last Name Father/Husband Name Address PINCodeFolio NumberNo of SharesAmount Due(in Rs.) 1 RADHAKRISHNANTSSSD SRITSSSDURAISAMY CO-OPERATIVE STORES LTD., VIRUDHUNAGAR 626001 P00000011 15 13500 2 MUTHIAH NADAR M SRIMARIMUTHU THIRUTHANGAL SATTUR TALUK 626130 P00000014 2 1800 3 SHUNMUGA NADAR GAS SRISUBBIAH THOOTHUKUDI 628001 P00000015 11 9900 4 KALIAPPA NADAR NAA SRIAIYA ELAYIRAMPANNAI, SATTUR VIA P00000023 2 1800 5 SANKARALINGAM NADAR A SRIARUMUGA C/O SRI.S.S.M.MAYANDI NADAR, 24-KALMANDAPAM ROAD, CHENNAI 600013 P00000024 2 1800 6 GANAPATHY NADAR P SRIPERIAKUMAR THOOTHUKUDI P00000046 10 9000 7 SANKARALINGA NADAR ASS SRICHONAMUTHU SIVAKASI 626123 P00000050 1 900 8 SHUNMUGAVELU NADAR VS SRIVSUBBIAH 357-MOGUL STREET, RANGOON P00000084 11 9900 9 VELLIAH NADAR S SRIVSWAMIDASS RANGOON P00000090 3 2700 10 THAVASI NADAR KP SRIKPERIANNA 40-28TH STREET, RANGOON P00000091 2 1800 11 DAWSON NADAR A NAPPAVOO C/O SRI.N.SAMUEL, PRASER STREET, POST OFFICE, RANGOON-1 P00000095 1 900 12 THIRUVADI NADAR R RAMALINGA KALKURICHI, ARUPPUKOTTAI 626101 P00000096 10 9000 13 KARUPPANASAMY NADAR ALM MAHALINGA KASI VISWANATHAN NORTH STREET, KUMBAKONAM P00000097 10 9000 14 PADMAVATHI ALBERT SRIPEALBERT EAST GATE, SAWYERPURAM P00000101 40 36000 15 KANAPATHY NADAR TKAA TKAANNAMALAI C/O SRI.N.S.S.CHINNASAMY NADAR, CHITRAKARA VEEDHI, MADURAI P00000105 5 4500 16 MUTHUCHAMY NADAR PR PRAJAKUMARU EAST MASI STREET, MADURAI P00000107 10 9000 17 CHIDAMBARA NADAR M VMARIAPPA 207-B EAST MARRET STREET, MADURAI 625001 P00000108 5 4500 18 KARUPPIAH NADAR KKM LATE SRIKKMUTHU EMANESWARAM, PARAMAKUDI T.K. -

Standard Punjabi Text to Lahndi Dialect Text Conversion System
International Journal of Science and Research (IJSR) ISSN (Online): 2319-7064 Index Copernicus Value (2013): 6.14 | Impact Factor (2015): 6.391 Standard Punjabi Text to Lahndi Dialect Text Conversion System Parneet Kaur1, Simrat Kaur2 1, 2Baba Banda Singh Bahadur Engineering College, Fatehgarh Sahib 1Research Scholar, 2Assistant Professor Abstract: In modern world, web is used as a medium to exchange information, ideas, and thoughts etc. Further people like to exchange this information in their native language. There are many online translators which translates one language to another or from many languages to English, so that everyone can get the required information even if one does not understand that language. In recent times people has started using colloquial data also. Translation of colloquial and informal data presents many challenges as one-to-many word mapping, sub dialects and incorrect spellings. In this paper, a system is presented for the conversion of Punjabi text to its Dialectal Lahndi form. The system is developed using a rule based approach which include approximately eighty five rules for conversion and a bilingual dictionary consisting 3247 words. The conversion system first segments the sentences into words and identifies the words which need conversion and then it converts the words by applying conversion rules and bilingual dictionary. This Conversion system can be extended to other dialects of Punjabi also. Keywords: Rule based approach, Machine Translation, Bilingual Dictionary, Punjabi Dialects, Colloquial data. 1. Introduction Punjab i.e., Western Punjab than Eastern Punjab. Even though Punjabi has become a tolerated language in Western Punjabi being one of the world‟s 14 widely spoken Punjab. -

Winmeen Tnpsc Gr 1 & 2 Self Preparation Course 2018
Winmeen Tnpsc Gr 1 & 2 Self Preparation Course 2018 Indian Polity – Part 30, 31 30] Unity In Diversity - National Integration Notes Notes Indian states are separated by several states based on language in the year of 1956. A great tamil poet Umar done an islamic tamil literature about nabigal nayagam story in an effective tamil poem form called viruttham .That is popularly known as Seerap puraanam. Brihadishvara Temple, also called Rajarajesvaram or Peruvudaiyar Kovil, is a Hindu temple dedicated to Shiva located in Thanjavur, Tamil Nadu, India.It is one of the largest South Indian temples and an exemplary example of a fully realized Tamil architecture.It is called as Dhakshina Meru of south. Built by Raja Raja Chola I between 1003 and 1010 AD, the temple is a part of the UNESCO World Heritage Site known as the "Great Living Chola Temples", along with the Chola dynasty era Gangaikonda Cholapuram temple and Airavatesvara temple that are about 70 kilometres (43 mi) and 40 kilometres (25 mi) to its northeast respectively. Meenakshi Temple, also referred to as Meenakshi Amman or Minakshi- Sundareshwara Temple,is a historic Hindu temple located on the southern bank of the Vaigai Riverin the temple city of Madurai, Tamil Nadu, India. It is dedicated to Meenakshi, a form of Parvati, and her consort, Sundareshwar, a form of Shiva. The kanchi Kailasanathar temple is the oldest structure in Kanchipuram. Located in Tamil Nadu, India, it is a Hindu temple in the Dravidian architectural style. It is dedicated to the Lord Shiva, and is known for its historical importance. -

Automatic Conversion of Dialectal Tamil Text to Standard Written Tamil Text Using Fsts
Automatic Conversion of Dialectal Tamil Text to Standard Written Tamil Text using FSTs Marimuthu K Sobha Lalitha Devi AU-KBC Research Centre, AU-KBC Research Centre, MIT Campus of Anna University, MIT Campus of Anna University, Chrompet, Chennai, India. Chrompet, Chennai, India. [email protected] [email protected] oriented activities such as blogging, social media Abstract chats, and discussions in online forums. Given the unmediated nature of these services, users We present an efficient method to auto- conveniently share the contents in their native matically transform spoken language text languages in a more natural and informal way. to standard written language text for var- This has resulted in bringing together the con- ious dialects of Tamil. Our work is novel tents of various languages. More often these con- in that it explicitly addresses the problem tents are informal, colloquial, and dialectal in and need for processing dialectal and nature. The dialect is defined as a variety of a spoken language Tamil. Written language language that is distinguished from other varie- equivalents for dialectal and spoken lan- ties of the same language by features of phonol- guage forms are obtained using Finite ogy, grammar, and vocabulary and by its use by State Transducers (FSTs) where spoken a group of speakers who are set off from others language suffixes are replaced with ap- geographically or socially. The dialectal varia- propriate written language suffixes. Ag- tion refers to changes in a language due to vari- glutination and compounding in the re- ous influences such as geographic, social, educa- sultant text is handled using Conditional tional, individual and group factors. -

GST Registration Certificate of TANGEDCO
(Amended) Government of India Form GST REG-06 [See Rule 10(1)] Registration Certificate Registration Number :33AADCT4784E1ZC 1. Legal Name TAMILNADU GENERATION AND DISTRIBUTION CORPORATION LIMITED 2. Trade Name, if any TAMILNADU GENERATION AND DISTRIBUTION CORPORATION LIMITED 3. Constitution of Business Public Sector Undertaking 4. Address of Principal Place of 144, NPKRR MAALIGAI, Anna Salai, Mount Road, Chennai, Tamil Business Nadu, 600002 5. Date of Liability 01/07/2017 6. Date of Validity From 01/07/2017 To NA 7. Type of Registration Regular 8. Particulars of Approving Authority Signature Name Designation Jurisdictional Office 9. Date of issue of Certificate 08/03/2019 Note: The registration certificate is required to be prominently displayed at all places of Business/Office(s) in the State. Annexure A Details of Additional Place of Business(s) GSTIN 33AADCT4784E1ZC Legal Name TAMILNADU GENERATION AND DISTRIBUTION CORPORATION LIMITED Trade Name, if any TAMILNADU GENERATION AND DISTRIBUTION CORPORATION Total Number of Additional Places of Business(s) in the State 323 Sr. No. Address 1 131 132, Ettaiyapuram Road, TUTICORIN, Thoothukudi, Tamil Nadu, 628002 2 65/1, RAMAMOORTHY ROAD,, VIRUDHUNAGAR, Virudhunagar, Tamil Nadu, 626001 3 7, Harbour Estate, Tuticorin, Thoothukudi, Tamil Nadu, 628004 4 36, SATTAYAPPAR EAST STREET, NAGAPATTINAM, Nagapattinam, Tamil Nadu, 611001 5 1, VALLAM ROAD, THANJAVUR, Thanjavur, Tamil Nadu, 613007 6 14, Mannarpuram, TRICHY, Tiruchirappalli, Tamil Nadu, 620020 7 11, Rameswaram Road, Rameswaram, Ramanathapuram, -
Newly Recruited Forester Allotted Circle / Division TAMIL NADU FOREST DEPARTMENT
TAMIL NADU FOREST DEPARTMENT Newly Recruited Forester allotted Circle / Division Name Sl.No Reg.No Address Gender Allotted Circle Allotted Division (Thiruvargal) 1 2 3 4 5 6 7 1 THAMODHARAN R 18010000069 183 MALE Thanjavur Thiruvarur PONNINAGAR,PUNGANUR,RAMJINAG Division, AR Thiruvarur POST,SRIRANGAM,TIRUCHIRAPPALLI, TAMILNADU,620009 2 THAMILARASAN S 18010000467 5 252 NEAR MGR MALE Dharmapuri Dharmapuri STATUE,KOMALIVATTAM,SUKKAMPAT Division, TY Dharmapuri POST,SALEM,SALEM,TAMILNADU,6361 22 3 SRINIVASAN A 18010000560 422 AMBETHKAR MALE Salem Salem Division, STREET,VENKATASAMUDRAM Salem PO,PAPPIREDDIPATTI TK,PAPPIREDDIPATTI,DHARMAPURI,T AMILNADU,636905 4 SANDHIYA SHREE B 18010000569 577 PATCHUR MAIN FEMALE Vellore Thiruvannamalai ROAD,NATTRAMPALLI,TIRUPATTUR Division, TALUK,TIRUPATTUR,VELLORE,TAMILN Thiruvannamalai ADU,635854 5 SIVACHANDIRAN S 18010000584 02 KALAINGAR KARUNANITHI MALE Villupuram Cuddalore STREET,KONDANGI,,VILLUPPURAM,VI Division, LLUPURAM,TAMILNADU,605301 Cuddalore 6 GOKUL K 18010000628 1 125 VEERABATHIRAN KOVIL MALE Salem Salem Division, STREET,A.PALLIPATTI Salem POST,PAPPIREDDIPATTI TALUK,PAPPIREDDIPATTI,DHARMAPU RI,TAMILNADU,636905 7 SAKTHIVEL T 18010003069 203 359 VELLALAR MALE Dharmapuri Wildlife Division, SREET,KODAMBAKADU,NETHIMEDU,S Hosur ALEM,SALEM,TAMILNADU,636002 8 DIVYA S 18010003815 2 3 380 VALANESAM,PUDHUPUTHOOR FEMALE Madurai Madurai Division, POST,KODAIKANAL,KODAIKANAL,DIN Madurai DIGUL,TAMILNADU,624103 9 MUTHUKUMAR 18010003822 1 25 KANNANTHOTTAM,ANIYAR MALE STR, Erode Erode Division, KOLANDAPALLAYAM Erode -
National Institute of Technology, Tiruchirappalli - 620 015 Tamilnadu, India
1/51 National Institute of Technology, Tiruchirappalli - 620 015 Tamilnadu, India Instructions to the candidates shortlisted for Written Test for Temporary Faculty position The written test for shortlisted candidates is scheduled on 14.07.2013(Sunday). The duration of the test will be for one hour from 10.30 a.m. to 11.30 a.m. on 14.07.2013. The syllabus for the written test of the concerned department is available from page no 27-51. The candidates are requested to be present in the test venue half-an-hour before test i.e.by 10 a.m. on 14.07.2013. The candidates are requested to produce a valid Photo ID proof at the time of written test. The written test would be conducted at two centers, one at NIT, Tiruchirappalli and another one at Jawaharlal Nehru Government Polytechnic College (JNGP), Near TV Studio, Ramanthapur, Hyderabad-500013. The candidates can prefer any one of the centre for written test. However, candidates are requested to intimate their choice of preference for written test centre to the email: [email protected] on or before 11-07-2013. After the written test, the candidates will be shortlisted and then they will be called for oral presentation on the topic of their interest (to test communication skills) and interview. The oral presentation and interview will be held at NIT, Tiruchirappalli. The date and time for this oral presentation and interview will be put up in our website www.nitt.edu The duly filled and signed data sheet (see page 2) be scanned and this scanned copy be sent to the email: [email protected] on or before 12.07.2013 .