Automatic Conversion of Dialectal Tamil Text to Standard Written Tamil Text Using Fsts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Un/Selfish Leader Changing Notions in a Tamil Nadu Village
The un/selfish leader Changing notions in a Tamil Nadu village Björn Alm The un/selfish leader Changing notions in a Tamil Nadu village Doctoral dissertation Department of Social Anthropology Stockholm University S 106 91 Stockholm Sweden © Björn Alm, 2006 Department for Religion and Culture Linköping University S 581 83 Linköping Sweden This book, or parts thereof, may be reproduced in any form without the permission of the author. ISBN 91-7155-239-1 Printed by Edita Sverige AB, Stockholm, 2006 Contents Preface iv Note on transliteration and names v Chapter 1 Introduction 1 Structure of the study 4 Not a village study 9 South Indian studies 9 Strength and weakness 11 Doing fieldwork in Tamil Nadu 13 Chapter 2 The village of Ekkaraiyur 19 The Dindigul valley 19 Ekkaraiyur and its neighbours 21 A multi-linguistic scene 25 A religious landscape 28 Aspects of caste 33 Caste territories and panchayats 35 A village caste system? 36 To be a villager 43 Chapter 3 Remodelled local relationships 48 Tanisamy’s model of local change 49 Mirasdars and the great houses 50 The tenants’ revolt 54 Why Brahmans and Kallars? 60 New forms of tenancy 67 New forms of agricultural labour 72 Land and leadership 84 Chapter 4 New modes of leadership 91 The parliamentary system 93 The panchayat system 94 Party affiliation of local leaders 95 i CONTENTS Party politics in Ekkaraiyur 96 The paradox of party politics 101 Conceptualising the state 105 The development state 108 The development block 110 Panchayats and the development block 111 Janus-faced leaders? 119 -

Curriculum Vitae Dr. A. Selvam
CURRICULUM VITAE DR. A. SELVAM Associate Professor Department of Plant Science Manonmaniam Sundaranar University Abishekapatti, Tirunelveli – 627012 Tamil Nadu, India Phone: +91-75985 51578 E-mail: [email protected] ACADEMIC QUALIFICATIONS Ph.D.: Botany, Centre for Advanced Studies in Botany, University of Madras, Chennai, India, 2001 M.Phil.: Botany (Mycology), Centre for Advanced Studies in Botany, University of Madras, Chennai, India, 1995. M.Sc.: Botany, Bharathiar University, Coimbatore, India B.Sc.: Botany, Bharathidasan University, Trichirappalli, India CITATION METRICS i) Journals published - National / International : 1/ 77 ii) Cumulative impact factor : 319.26 (JCR) iii) H-Index (Researcher ID) : 18 iv) H-Index (Google scholar) : 25 v) Citation : 1143 CAREER HISTORY Previous Positions Research Assistant Professor: Sino-Forest Applied Research Centre for Pearl River Delta Environment & Department of Biology, Hong Kong Baptist University, Hong Kong SAR (2012 – 2016). Research Fellow: Sino-Forest Applied Research Centre for Pearl River Delta Environment, Hong Kong Baptist University, Hong Kong SAR (2012). Research Associate, Sino-Forest Applied Research Centre for Pearl River Delta Environment, Hong Kong Baptist University, Hong Kong SAR (2010 –2012). Post-Doctoral Visiting Research Scholar, Department of Biology, Hong Kong Baptist University, Hong Kong SAR (2008 – 2010). Post-doctoral Fellow, Department of Microbiology and Biochemistry, National Taiwan University, Taiwan (2005 – 2008). Post-Doctoral Visiting Research Scholar, Department of Biology, Hong Kong Baptist University, 1 Hong Kong SAR (2004 – 2005). Lecturer, Department of Biotechnology, Periyar Maniammai College of Technology for Women, Vallam, Thanjavur, India (2003-2004). Project Assistant, Centre for Environmental Studies, Anna University, Chennai, India (2001 – 2003). Research Fellow (Jawaharlal Nehru memorial fund), Centre for Advanced Studies in Botany, University of Madras, Chennai (2000-2000). -

“Lost in Translation”: a Study of the History of Sri Lankan Literature
Karunakaran / Lost in Translation “Lost in Translation”: A Study of the History of Sri Lankan Literature Shamila Karunakaran Abstract This paper provides an overview of the history of Sri Lankan literature from the ancient texts of the precolonial era to the English translations of postcolonial literature in the modern era. Sri Lanka’s book history is a cultural record of texts that contains “cultural heritage and incorporates everything that has survived” (Chodorow, 2006); however, Tamil language works are written with specifc words, ideas, and concepts that are unique to Sri Lankan culture and are “lost in translation” when conveyed in English. Keywords book history, translation iJournal - Journal Vol. 4 No. 1, Fall 2018 22 Karunakaran / Lost in Translation INTRODUCTION The phrase “lost in translation” refers to when the translation of a word or phrase does not convey its true or complete meaning due to various factors. This is a common problem when translating non-Western texts for North American and British readership, especially those written in non-Roman scripts. Literature and texts are tangible symbols, containing signifed cultural meaning, and they represent varying aspects of an existing international ethnic, social, or linguistic culture or group. Chodorow (2006) likens it to a cultural record of sorts, which he defnes as an object that “contains cultural heritage and incorporates everything that has survived” (pg. 373). In particular, those written in South Asian indigenous languages such as Tamil, Sanskrit, Urdu, Sinhalese are written with specifc words, ideas, and concepts that are unique to specifc culture[s] and cannot be properly conveyed in English translations. -

Religion, Ethics, and Poetics in a Tamil Literary Tradition
Tacit Tirukku#a#: Religion, Ethics, and Poetics in a Tamil Literary Tradition The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Smith, Jason William. 2020. Tacit Tirukku#a#: Religion, Ethics, and Poetics in a Tamil Literary Tradition. Doctoral dissertation, Harvard Divinity School. Citable link https://nrs.harvard.edu/URN-3:HUL.INSTREPOS:37364524 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA ! ! ! ! ! !"#$%&!"#$%%$&'('& ()*$+$,-.&/%0$#1.&"-2&3,)%$#1&$-&"&!"4$*&5$%)6"67&!6"2$%$,-& ! ! "!#$%%&'()($*+!,'&%&+(&#! -.! /)%*+!0$11$)2!32$(4! (*! 54&!6)781(.!*9!:)';)'#!<$;$+$(.!374**1! $+!,)'($)1!9819$112&+(!*9!(4&!'&=8$'&2&+(%! 9*'!(4&!#&>'&&!*9! <*7(*'!*9!54&*1*>.! $+!(4&!%8-?&7(!*9! 54&!3(8#.!*9!@&1$>$*+! :)';)'#!A+$;&'%$(.! B)2-'$#>&C!D)%%)748%&((%! ",'$1!EFEF! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! G!EFEF!/)%*+!0$11$)2!32$(4! "11!'$>4(%!'&%&';&#H! ! ! ! ! ! <$%%&'()($*+!"#;$%*'I!J'*9&%%*'!6')+7$%!KH!B1**+&.!! ! ! !!/)%*+!0$11$)2!32$(4! ! !"#$%&!"#$%%$&'('&()*$+$,-.&/%0$#1.&"-2&3,)%$#1&$-&"&!"4$*&5$%)6"67&!6"2$%$,-! ! "-%(')7(! ! ! 54$%!#$%%&'()($*+!&L)2$+&%!(4&!!"#$%%$&'(C!)!,*&2!7*2,*%&#!$+!5)2$1!)'*8+#!(4&!9$9(4! 7&+(8'.!BHMH!(4)(!$%!(*#).!)(('$-8(&#!(*!)+!)8(4*'!+)2&#!5$'8;)NN8;)'H!54&!,*&2!7*+%$%(%!*9!OCPPF! ;&'%&%!)'')+>&#!$+(*!OPP!74),(&'%!*9!(&+!;&'%&%!&)74C!Q4$74!)'&!(4&+!#$;$#&#!$+(*!(4'&&!(4&2)($7! -

Trichirapalli.Pdf
Contents TITLE Page No. Message by Member Secretary, State Planning Commission i Preface by the District Collector iii Acknowledgement v List of Boxes vii List of Figures viii List of Tables ix Chapters 1. DistrictProfile 1 2. Status of Human Development 11 3. Employment, Income and Poverty 29 4. Demography, Health and Nutrition 45 5. Literacy and Education 75 6. Gender 105 7. Social Security 113 8. Infrastructure 123 9. Summary and Way Forward 133 Annexures Technical Notes A20 Abbreviations A27 References A29 TIRUCHIRAPPALI DISTRICT HUMAN DEVELOPMENT REPORT 2017 District Administration, Tiruchirappali and State Planning Commission, Tamil Nadu in association with Bharathidasan University Contents TITLE Page No. Message by Member Secretary, State Planning Commission i Preface by the District Collector iii Acknowledgement v List of Boxes vii List of Figures viii List of Tables ix Chapters 1. DistrictProfile 1 2. Status of Human Development 11 3. Employment, Income and Poverty 29 4. Demography, Health and Nutrition 45 5. Literacy and Education 75 6. Gender 105 7. Social Security 113 8. Infrastructure 123 9. Summary and Way Forward 133 Annexures Technical Notes A20 Abbreviations A27 References A29 Dr. K.S.Palanisamy,I.A.S., Office : 0431-2415358 District Collector, Fax : 0431-2411929 Tiruchirappalli. Res : 0431-2420681 0431-2420181 Preface India has the potential to achieve and the means to secure a reasonable standard of living for all the sections of its population. Though the economy touched the nine per cent growth rate during the Eleventh Five Year Plan (2007-12), there are socio-economically disadvantaged people who are yet to benefit from this growth. -
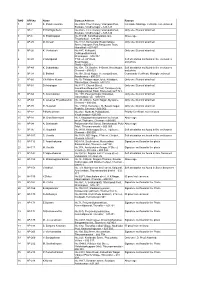
SNO APP.No Name Contact Address Reason 1 AP-1 K
SNO APP.No Name Contact Address Reason 1 AP-1 K. Pandeeswaran No.2/545, Then Colony, Vilampatti Post, Intercaste Marriage certificate not enclosed Sivakasi, Virudhunagar – 626 124 2 AP-2 P. Karthigai Selvi No.2/545, Then Colony, Vilampatti Post, Only one ID proof attached. Sivakasi, Virudhunagar – 626 124 3 AP-8 N. Esakkiappan No.37/45E, Nandhagopalapuram, Above age Thoothukudi – 628 002. 4 AP-25 M. Dinesh No.4/133, Kothamalai Road,Vadaku Only one ID proof attached. Street,Vadugam Post,Rasipuram Taluk, Namakkal – 637 407. 5 AP-26 K. Venkatesh No.4/47, Kettupatti, Only one ID proof attached. Dokkupodhanahalli, Dharmapuri – 636 807. 6 AP-28 P. Manipandi 1stStreet, 24thWard, Self attestation not found in the enclosures Sivaji Nagar, and photo Theni – 625 531. 7 AP-49 K. Sobanbabu No.10/4, T.K.Garden, 3rdStreet, Korukkupet, Self attestation not found in the enclosures Chennai – 600 021. and photo 8 AP-58 S. Barkavi No.168, Sivaji Nagar, Veerampattinam, Community Certificate Wrongly enclosed Pondicherry – 605 007. 9 AP-60 V.A.Kishor Kumar No.19, Thilagar nagar, Ist st, Kaladipet, Only one ID proof attached. Thiruvottiyur, Chennai -600 019 10 AP-61 D.Anbalagan No.8/171, Church Street, Only one ID proof attached. Komathimuthupuram Post, Panaiyoor(via) Changarankovil Taluk, Tirunelveli, 627 761. 11 AP-64 S. Arun kannan No. 15D, Poonga Nagar, Kaladipet, Only one ID proof attached. Thiruvottiyur, Ch – 600 019 12 AP-69 K. Lavanya Priyadharshini No, 35, A Block, Nochi Nagar, Mylapore, Only one ID proof attached. Chennai – 600 004 13 AP-70 G. -

Page BRAHMANISM, BRAHMINS and BRAHMIN TAMIL in the CONTEXT of SPEECH to TEXT TECHNOLOGY Corresponding Email:[email protected]
BRAHMANISM, BRAHMINS AND BRAHMIN TAMIL IN THE CONTEXT OF SPEECH TO TEXT TECHNOLOGY R S Vignesh Raja, Ashik Alib Dr. BabakKhazaeic aResearch degree student, cSenior Lecturer Sheffield Hallam University, Sheffield, United Kingdom bSoftware Developer Fireflyapps Limited, Sheffield, United Kingdom Corresponding email:[email protected] Abstract Brahmanism in today's world is largely viewed as a 'caste' within Hinduism than its predecessor religion. This research paper explores the impact and influence religious affiliation could have on using certain advanced technologies such as the voice-to-text. This research paper attempts to reintroduce Brahmanism as a distinct religion and justifies through an empirical study and other literature as to why it is important, more specifically in language-related technology. Keywords: Tamil; speech to text; technology; Brahmanism; Brahmins 1. Introduction Speech-to-text is a fascinating area of research. The speech-to-text system exists for popular languages such as English. Whilst dealing with the user acceptance of technology, previous experiments suggest that it is vital to consider the religious affiliation as it could influence 'pronunciation' which is perceived to be very important for the users to be able to use voice-to- text technology in syllabic languages such as Tamil (Rama et al., 2002). Some of the previous experiments have identified the effect of code mixing, mispronunciation or in some cases the inability to correctly pronounce a syllable by the native Tamil speakers (Raj, Ali&Khazaei, 2015). This research paper aims to look into the code mixing and pronunciation aspects of 'Brahmin Tamil'- a dialect of Tamil spoken by the Brahmins who speak Tamil as their mother tongue. -

GRAMMAR of OLD TAMIL for STUDENTS 1 St Edition Eva Wilden
GRAMMAR OF OLD TAMIL FOR STUDENTS 1 st Edition Eva Wilden To cite this version: Eva Wilden. GRAMMAR OF OLD TAMIL FOR STUDENTS 1 st Edition. Eva Wilden. Institut français de Pondichéry; École française d’Extrême-Orient, 137, 2018, Collection Indologie. halshs- 01892342v2 HAL Id: halshs-01892342 https://halshs.archives-ouvertes.fr/halshs-01892342v2 Submitted on 24 Jan 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. GRAMMAR OF OLD TAMIL FOR STUDENTS 1st Edition L’Institut Français de Pondichéry (IFP), UMIFRE 21 CNRS-MAE, est un établissement à autonomie financière sous la double tutelle du Ministère des Affaires Etrangères (MAE) et du Centre National de la Recherche Scientifique (CNRS). Il est partie intégrante du réseau des 27 centres de recherche de ce Ministère. Avec le Centre de Sciences Humaines (CSH) à New Delhi, il forme l’USR 3330 du CNRS « Savoirs et Mondes Indiens ». Il remplit des missions de recherche, d’expertise et de formation en Sciences Humaines et Sociales et en Écologie dans le Sud et le Sud- est asiatiques. Il s’intéresse particulièrement aux savoirs et patrimoines culturels indiens (langue et littérature sanskrites, histoire des religions, études tamoules…), aux dynamiques sociales contemporaines, et aux ecosystèmes naturels de l’Inde du Sud. -

Between Convergence and Divergence: Reformatting Language Purism in the Montreal Tamil Diasporas
Sonia Neela Das UNIVERSITY OF MICHIGAN Between Convergence and Divergence: Reformatting Language Purism in the Montreal Tamil Diasporas This article examines how ideologies of language purism are reformatted by creating inter- discursive links across spatial and temporal scales. I trace convergences and divergences between South Asian and Québécois sociohistorical regimes of language purism as they pertain to the contemporary experiences of Montreal’s Tamil diasporas. Indian Tamils and Sri Lankan Tamils in Montreal emphasize their status differences by claiming that the former speak a modern “vernacular” Tamil and the latter speak an ancient “literary” Tamil. The segregation and purification of these social groups and languages depend upon the intergen- erational reproduction of scalar boundaries between linguistic forms, interlocutors, and decentered contexts. [Tamils, Quebec, diaspora, linguistic purism, spatiotemporal scales] ontreal is situated within the Canadian province of Quebec, a self- identifying francophone nation that seeks to be recognized as a “distinct Msociety” within North America1 (Lemco 1994). This society’s ever-present fear of being engulfed by a demographically expanding, English-speaking populace has contributed to a heightened level of metalinguistic awareness among French- speaking Québécois citizens. For the residents of Montreal, this metalinguistic aware- ness appears to be even more acute. Often characterized by scholars, politicians, and media as an inassimilable, globalizing element located within the otherwise -

I Year Dkh11 : History of Tamilnadu Upto 1967 A.D
M.A. HISTORY - I YEAR DKH11 : HISTORY OF TAMILNADU UPTO 1967 A.D. SYLLABUS Unit - I Introduction : Influence of Geography and Topography on the History of Tamil Nadu - Sources of Tamil Nadu History - Races and Tribes - Pre-history of Tamil Nadu. SangamPeriod : Chronology of the Sangam - Early Pandyas – Administration, Economy, Trade and Commerce - Society - Religion - Art and Architecture. Unit - II The Kalabhras - The Early Pallavas, Origin - First Pandyan Empire - Later PallavasMahendravarma and Narasimhavarman, Pallava’s Administration, Society, Religion, Literature, Art and Architecture. The CholaEmpire : The Imperial Cholas and the Chalukya Cholas, Administration, Society, Education and Literature. Second PandyanEmpire : Political History, Administration, Social Life, Art and Architecture. Unit - III Madurai Sultanate - Tamil Nadu under Vijayanagar Ruler : Administration and Society, Economy, Trade and Commerce, Religion, Art and Architecture - Battle of Talikota 1565 - Kumarakampana’s expedition to Tamil Nadu. Nayakas of Madurai - ViswanathaNayak, MuthuVirappaNayak, TirumalaNayak, Mangammal, Meenakshi. Nayakas of Tanjore :SevappaNayak, RaghunathaNayak, VijayaRaghavaNayak. Nayak of Jingi : VaiyappaTubakiKrishnappa, Krishnappa I, Krishnappa II, Nayak Administration, Life of the people - Culture, Art and Architecture. The Setupatis of Ramanathapuram - Marathas of Tanjore - Ekoji, Serfoji, Tukoji, Serfoji II, Sivaji III - The Europeans in Tamil Nadu. Unit - IV Tamil Nadu under the Nawabs of Arcot - The Carnatic Wars, Administration under the Nawabs - The Mysoreans in Tamil Nadu - The Poligari System - The South Indian Rebellion - The Vellore Mutini- The Land Revenue Administration and Famine Policy - Education under the Company - Growth of Language and Literature in 19th and 20th centuries - Organization of Judiciary - Self Respect Movement. Unit - V Tamil Nadu in Freedom Struggle - Tamil Nadu under Rajaji and Kamaraj - Growth of Education - Anti Hindi & Agitation. -

Why I Became a Hindu
Why I became a Hindu Parama Karuna Devi published by Jagannatha Vallabha Vedic Research Center Copyright © 2018 Parama Karuna Devi All rights reserved Title ID: 8916295 ISBN-13: 978-1724611147 ISBN-10: 1724611143 published by: Jagannatha Vallabha Vedic Research Center Website: www.jagannathavallabha.com Anyone wishing to submit questions, observations, objections or further information, useful in improving the contents of this book, is welcome to contact the author: E-mail: [email protected] phone: +91 (India) 94373 00906 Please note: direct contact data such as email and phone numbers may change due to events of force majeure, so please keep an eye on the updated information on the website. Table of contents Preface 7 My work 9 My experience 12 Why Hinduism is better 18 Fundamental teachings of Hinduism 21 A definition of Hinduism 29 The problem of castes 31 The importance of Bhakti 34 The need for a Guru 39 Can someone become a Hindu? 43 Historical examples 45 Hinduism in the world 52 Conversions in modern times 56 Individuals who embraced Hindu beliefs 61 Hindu revival 68 Dayananda Saraswati and Arya Samaj 73 Shraddhananda Swami 75 Sarla Bedi 75 Pandurang Shastri Athavale 75 Chattampi Swamikal 76 Narayana Guru 77 Navajyothi Sree Karunakara Guru 78 Swami Bhoomananda Tirtha 79 Ramakrishna Paramahamsa 79 Sarada Devi 80 Golap Ma 81 Rama Tirtha Swami 81 Niranjanananda Swami 81 Vireshwarananda Swami 82 Rudrananda Swami 82 Swahananda Swami 82 Narayanananda Swami 83 Vivekananda Swami and Ramakrishna Math 83 Sister Nivedita -

Women's Roles and Participation in Rituals in the Maintenance of Cultural Identity: a Study of the Malaysian Iyers
SEARCH: The Journal of the South East Asia Research centre ISSN 2229-872X for Communications and Humanities. Vol. 7 No. 1, 2015, pp 1-21 Women’s Roles and Participation in Rituals in the Maintenance of Cultural Identity: A Study of the Malaysian Iyers Lokasundari Vijaya Sankar Taylor’s University, Malaysia © The Author(s) 2014. This article is published with open access by Taylor’s Press. ABSTRACT This paper examines the roles and rituals practiced by Malaysian Iyer women. The Iyers are a small community of Tamil Brahmins who live and work mainly in the Klang Valley. As an Indian diasporic community, who moved to Malaysia from the early 1900s, they have been slowly shifting from Tamil to English and Malay. They are upwardly mobile and place great emphasis on education but at the same time, value their traditions and culture. Data was derived from interactions between women and men from the Malaysian Iyer community together with personal observations made during visits to their homes, weddings and prayer sessions. This data was studied to obtain insights into cultural elements that ruled their discourse. The findings show that for this diasporic community that was slowly losing its language, ethnic identity can still be found in their cultural practices. Women were seen as keepers of tradition and customs that are important to the community. They followed certain cultural and traditional practices in their homes: practiced vegetarianism while cooking and serving food in their homes, followed taboos regarding food preparation, maintained patriarchal practices especially in religious practices and lived in extended families which usually included paternal grandparents.