CSE 431. Computer Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

MBP4ASG41M-VS3.Pdf
ASRock > G41M-VS3 Página 1 de 2 Home | Global / English [Change] About ASRock Products News Support Forum Download Awards Dealer Zone Where to Buy Products G41M-VS3 Motherboard Series »G41M-VS3 Translate »Overview & Specifications ■ Supports FSB1333/1066/800/533 MHz CPUs »Download ■ Supports Dual Channel DDR3 1333(OC) ■ Intel® Graphics Media Accelerator X4500, Pixel Shader 4.0, DirectX 10, Max. shared »Manual memory 1759MB »FAQ ■ EuP Ready »CPU Support List ■ Supports ASRock XFast RAM, XFast LAN, XFast USB Technologies ■ Supports Instant Boot, Instant Flash, OC DNA, ASRock OC Tuner (Up to 158% CPU »Memory QVL frequency increase) »Beta Zone ■ Supports Intelligent Energy Saver (Up to 20% CPU Power Saving) ■ Free Bundle : CyberLink DVD Suite - OEM and Trial; Creative Sound Blaster X-Fi MB - Trial This model may not be sold worldwide. Please contact your local dealer for the availability of this model in your region. Product Specifications General - LGA 775 for Intel® Core™ 2 Extreme / Core™ 2 Quad / Core™ 2 Duo / Pentium® Dual Core / Celeron® Dual Core / Celeron, supporting Penryn Quad Core Yorkfield and Dual Core Wolfdale processors - Supports FSB1333/1066/800/533 MHz CPU - Supports Hyper-Threading Technology - Supports Untied Overclocking Technology - Supports EM64T CPU - Northbridge: Intel® G41 Chipset - Southbridge: Intel® ICH7 - Dual Channel DDR3 memory technology - 2 x DDR3 DIMM slots - Supports DDR3 1333(OC)/1066/800 non-ECC, un-buffered memory Memory - Max. capacity of system memory: 8GB* *Due to the operating system limitation, the actual memory size may be less than 4GB for the reservation for system usage under Windows® 32-bit OS. For Windows® 64-bit OS with 64-bit CPU, there is no such limitation. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Intel® Technology Journal the Original 45Nm Intel Core™ Microarchitecture
Volume 12 Issue 03 Published October 2008 ISSN 1535-864X DOI: 10.1535/itj.1203 Intel® Technology Journal The Original 45nm Intel Core™ Microarchitecture Intel Technology Journal Q3’08 (Volume 12, Issue 3) focuses on Intel® Processors Based on the Original 45nm Intel Core™ Microarchitecture: The First Tick in Intel’s new Architecture and Silicon “Tick-Tock” Cadence The Technical Challenges of Transitioning Original 45nm Intel® Core™ 2 Processor Performance Intel® PRO/Wireless Solutions to a Half-Mini Card Power Management Enhancements Greater Mobility Through Lower Power in the 45nm Intel® Core™ Microarchitecture Improvements in the Intel® Core™ 2 Penryn Processor Family Architecture Power Improvements on 2008 Desktop Platforms and Microarchitecture Mobility Thin and Small Form-Factor Packaging for Intel® Processors Based on Original 45nm The First Six-Core Intel® Xeon™ Microprocessor Intel Core™ Microarchitecture More information, including current and past issues of Intel Technology Journal, can be found at: http://developer.intel.com/technology/itj/index.htm Volume 12 Issue 03 Published October 2008 ISSN 1535-864X DOI: 10.1535/itj.1203 Intel® Technology Journal The Original 45nm Intel Core™ Microarchitecture Articles Preface iii Foreword v Technical Reviewers vii Original 45nm Intel® Core™ 2 Processor Performance 157 Power Management Enhancements in the 45nm Intel® Core™ Microarchitecture 169 Improvements in the Intel® Core™ 2 Penryn Processor Family Architecture 179 and Microarchitecture Mobility Thin and Small Form-Factor Packaging -
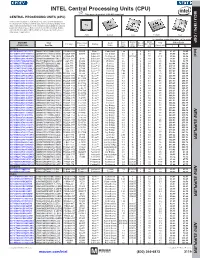
CPU) MCU / MPU / DSP This Page of Product Is Rohs Compliant
INTEL Central Processing Units (CPU) MPU /DSP MCU / This page of product is RoHS compliant. CENTRAL PROCESSING UNITS (CPU) Intel Processor families include the most powerful and flexible Central Processing Units (CPUs) available today. Utilizing industry leading 22nm device fabrication techniques, Intel continues to pack greater processing power into smaller spaces than ever before, providing desktop, mobile, and embedded products with maximum performance per watt across a wide range of applications. Atom Celeron Core Pentium Xeon For quantities greater than listed, call for quote. MOUSER Intel Core Cache Data Price Each Package Processor Family Code Freq. Size No. of Bus Width TDP STOCK NO. Part No. Series Name (GHz) (MB) Cores (bit) (Max) (W) 1 10 Desktop Intel 607-DF8064101211300Y DF8064101211300S R0VY FCBGA-559 D2550 Atom™ Cedarview 1.86 1 2 64 10 61.60 59.40 607-CM8063701444901S CM8063701444901S R10K FCLGA-1155 G1610 Celeron® Ivy Bridge 2.6 2 2 64 55 54.93 52.70 607-RK80532RC041128S RK80532RC041128S L6VR PPGA-478 - Celeron® Northwood 2.0 0.0156 1 32 52.8 42.00 40.50 607-CM8062301046804S CM8062301046804S R05J FCLGA-1155 G540 Celeron® Sandy Bridge 2.5 2 2 64 65 54.60 52.65 607-AT80571RG0641MLS AT80571RG0641MLS LGTZ LGA-775 E3400 Celeron® Wolfdale 2.6 1 2 64 65 54.93 52.70 607-HH80557PG0332MS HH80557PG0332MS LA99 LGA-775 E4300 Core™ 2 Conroe 1.8 2 2 64 65 139.44 133.78 607-AT80570PJ0806MS AT80570PJ0806MS LB9J LGA-775 E8400 Core™ 2 Wolfdale 3.0 6 2 64 65 207.04 196.00 607-AT80571PH0723MLS AT80571PH0723MLS LGW3 LGA-775 E7400 Core™ 2 Wolfdale -
Intel Desktop CPU Roadmap
Intel Desktop CPU Roadmap 2004 2005 2008 2009 2010 System Price 2006 2007 TDP Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 1H Q2 3.73GHz Core2 Extreme Kentsfield Core2 Extreme Kentsfield QX9775 (3.2GHz/ Northwood Presler QX6850 (3GHz/ 12MB/FSB1600) QX Prescott 2M 3.2GHz(840) QX6700 (2.66GHz/ Core2 Extreme 6 cores/12MB L3 3.46GHz(955) 3.73GHz(965) 8MB/FSB1333) QX9770 (3.2GHz/ Bloomfield Extreme ≧ Extreme 3.46GHz 8MB/FSB1066) 965 (3.2GHz/8MB/ Smithfield-XE QX6800 (2.93GHz/ 12MB/FSB1600) (XE) 130W Pentium 2.93GHz(X6800) 8MB/FSB1066) Yorkfield QPI6.4/DDR3 1066) Pentium 4 3.8GHz(670) Extreme Edition QX9650 (3GHz/ Extreme Edition Conroe XE 12MB/FSB1333) Core i7 Bloomfield $900 Prescott Presler Core2 Quad Yorkfield 940 (2.93GHz/8MB/ 3.8GHz(571) 3.8GHz(672) 3.4GHz(950) 3.6GHz(960) Kentsfield Q9550 (2.83GHz/ QPI4.8/DDR3 1066) 3.8GHz(570) Lynnfield 4cores/PCIe x16 Conroe Q6600 (2.4GHz/ 12MB/FSB1333) Westmere Performance Performance 3.8GHz(670) 8MB/FSB1066) Q6700 (2.66GHz/ 2.xxGHz/8MB/ Prescott 3.6GHz(660) PCIe/DDR3 1066 6 cores (P1) Prescott 2M 3.2GHz(940) Pentium D 2.66GHz(E6700) 8MB/FSB1066) Prescott 2M Q9650 (3GHz/ 3.2GHz(840) 9xx 12MB/FSB1333) Core2 Duo Nehalem/Core 2 $4xx Smithfield Pentium D Boundary 8xx Cedar Mill Core2 Quad Q9550 (2.83GHz/ 3.6GHz(662) Conroe Yorkfield 12MB/FSB1333) 3.6GHz(560) 3.6GHz(561) 3.6GHz(661) 2.40GHz(E6600) 2.66GHz(E6700) 920 (2.66GHz/8MB/ 3.6GHz(660) Q9450 (2.66GHz/ QPI4.8/DDR3 1066) $300 Q Mainstream 3 12MB/FSB1333) Bloomfield 2.xxGHz/8MB/ Lynnfield 3.4GHz(650) Core i7 95W 3GHz(930) 3.4GHz(950) -

Boulder Lake
Overview of Intel® Core 2 Architecture and Software Development Tools Overview of Architecture & Tools We will discuss: What lecture materials are available What labs are available What target courses could be impacted Some high level discussion of underlying technology Objectives After completing this module, you will: Be aware of and have access to several hours worth of MC topics including Architecture, Compiler Technology, Profiling Technology, OpenMP, & Cache Effects Be able create exercises on how to avoid coding common threading hazards associated with some MC systems – such as Poor Cache Utilization, False Sharing and Threading load imbalance Be able create exercises on how to use selected compiler directives & switches to improve behavior on each core Be able create exercises on how to take advantage VTune analyzer to quickly identify load imbalance issues, poor cache reuse and false sharing issues Agenda Multi-core Motivation Tools Overview Taking advantage of Multi-core Taking advantage of parallelism within each core (SSEx) Avoiding Memory/Cache effects Why is the Industry moving to Multi-core? In order to increase performance and reduce power consumption Its is much more efficient to run several cores at a lower frequency than one single core at a much faster frequency Power and Frequency Power vs. Frequency Curve for Single Core Architecture 359 309 259 Dropping Frequency 209 = Large Drop Power 159 Lower Frequency Power (w) Allows Headroom 109 for 2nd Core 59 9 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 -

The Intel X86 Microarchitectures Map Version 2.2
The Intel x86 Microarchitectures Map Version 2.2 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • New instructions: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Microcode Revision Guidance April2 2018 MCU Recommendations the Following Table Provides Details of Availability for Microcode Updates Currently Planned by Intel
microcode revision guidance april2 2018 MCU Recommendations The following table provides details of availability for microcode updates currently planned by Intel. Changes since the previous version are highlighted in yellow. LEGEND: Production Status: • Planning – Intel has not yet determined a schedule for this MCU. • Pre-beta – Intel is performing early validation for this MCU. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. • Stopped – After a comprehensive investigation of the microarchitectures and microcode capabilities for these products, Intel has determined to not release microcode updates for these products for one or more reasons including, but not limited to the following: • Micro-architectural characteristics that preclude a practical implementation of features mitigating Variant 2 (CVE-2017-5715) • Limited Commercially Available System Software support • Based on customer inputs, most of these products are implemented as “closed systems” and therefore are expected to have a lower likelihood of exposure to these vulnerabilities. Pre-Mitigation Production MCU: • For products that do not have a Production MCU with mitigations for Variant 2 (Spectre), Intel recommends using this version of MCU. This does not impact mitigations for Variant 1 (Spectre) and Variant 3 (Meltdown). STOP deploying these MCU revs: • Intel recommends to discontinue using these select versions of MCU that were previously released with mitigations for Variant 2 (Spectre) due to system stability issues. • Lines with “***” were previously recommended to discontinue use. Subsequent testing by Intel has determined that these were unaffected by the stability issues and have been re-released without modification. -

Asrock > Products > G41M-S3 > CPU Support List
ASRock > Products > G41M-S3 > CPU Support List Home | Global / English [Change] About ASRock Products News Support Forum Download Awards Dealer Zone Where to Buy Products G41M-S3 Motherboard Series »G41M-S3 CPU Support List »Overview & Specifications Processor Info Since »Download Socket Family Number Core Frequency FSB Cache BIOS »Manual 775 Core 2 Extreme X6800 Conroe XE 2.93GHz 1066MHz 4MB All 775 Core 2 Quad Q9650(E0) Yorkfield 3.0GHz 1333MHz 12MB All »FAQ 775 Core 2 Quad Q9550(C1) Yorkfield 2.83GHz 1333MHz 12MB All »CPU Support List 775 Core 2 Quad Q9550(E0) Yorkfield 2.83GHz 1333MHz 12MB All »Memory QVL 775 Core 2 Quad Q9550(C0) Yorkfield 2.83GHz 1333MHz 12MB All 775 Core 2 Quad Q9505S(R0) Yorkfield 2.83GHz 1333MHz 6MB All 775 Core 2 Quad Q9505(R0) Yorkfield 2.83GHz 1333MHz 6MB All 775 Core 2 Quad Q9450(C1) Yorkfield 2.66GHz 1333MHz 12MB All 775 Core 2 Quad Q9450(C0) Yorkfield 2.66GHz 1333MHz 12MB All 775 Core 2 Quad Q9400(R0) Yorkfield 2.66GHz 1333MHz 6MB All 775 Core 2 Quad Q9300(M1) Yorkfield 2.50GHz 1333MHz 6MB All 775 Core 2 Quad Q9300(M0) Yorkfield 2.5GHz 1333MHz 6MB All 775 Core 2 Quad Q8400S(R0) Yorkfield 2.66GHz 1333MHz 4MB All 775 Core 2 Quad Q8400(R0) Yorkfield 2.66GHz 1333MHz 4MB All 775 Core 2 Quad Q8300(R0) Yorkfield 2.50GHz 1333MHz 4MB All 775 Core 2 Quad Q8200(R0) Yorkfield 2.33GHz 1333MHz 4MB All 775 Core 2 Quad Q8200(M1) Yorkfield 2.33GHz 1333MHz 4MB All 775 Core 2 Quad Q6700(G0) Kentsfield 2.66GHz 1066MHz 8MB All 775 Core 2 Quad Q6600(G0) Kentsfield 2.4GHz 1066MHz 8MB All 775 Core 2 Quad Q6600(B3) Kentsfield 2.40GHz -
![CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel Created Pentium (From Quad-Core CPU](https://docslib.b-cdn.net/cover/8530/cpu-history-tualatin-banias-dothan-yonah-jonah-conroe-allendale-yorkfield-xe-intel-created-pentium-from-quad-core-cpu-3058530.webp)
CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel Created Pentium (From Quad-Core CPU
2nd Generation 4th Generation 5th Generation 6th Generation 7th Generation 3rd Generation Intel Pentium III-S Intel Pentium-M (Centrino) Intel Pentium-M (Centrino) Intel Core Duo (Viiv) Intel Core 2 Duo (Viiv)/Xeon Intel Core 2 Duo (Viiv) Intel Core 2 Extreme (Viiv) Intel had the first consumer CPU History [Tualatin] [Banias] [Dothan] [Yonah (Jonah)] [Conroe] [Allendale] [Yorkfield XE] Intel created Pentium (from quad-core CPU. x86/CISC Microprocessors Greek penta which means (2001) (2003) (2004) (2006) (2006) (2007) (2007) 1st Generation Intel Pentium II Xeon Intel Pentium III Xeon Centrino is not a CPU; it is Begin Core five) to distinguish the Intel [P6] [Tanner] a mobile Intel CPU paired nomeclature brand from clones. Names (1998) (1999) Intel Celeron with an Intel Wi-Fi adapter. Intel Celeron Intel Core Solo can be copyrighted, product [Tualeron] [Dothan-1024] Intel Xeon LV Intel Celeron Intel Celeron [Yonah] ID's cannot. (2001) (2004) [Sossaman] [Banias-512] [Shelton (Banias-0)] (2006) (2006) Intel Core 2 Duo Intel Core 2 Extreme Intel Celeron Intel 80386 DX Intel 80486 DX Intel Pentium Intel Pentium Pro Intel Pentium II Intel Pentium II Intel Pentium III Intel Pentium III Intel Pentium 4 Intel Pentium 4 (2004) (2004) Intel Pentium 4 Intel Pentium 4 Intel 4004 Intel 8008 Intel 8086 Intel 80286 [Conroe XE] [Conroe-L] [P3] [P4] [P5/P54/P54C] [P6] [Klamath] [Deuschutes] [Katmai] [Coppermine] [Williamette] [Northwood] [Prescott] [Cedar Mill] END-OF-LINE (Centrino Duo) (1971) (1972) (1978) (1982) (2006) (2007) (1985) (1989) (1993) (1995) (1997) (1998) (1999) (1999) (2000) (2002) (2004) (2006) [Merom] (2006) Yonah is Hebrew for Jonah.