Forecasting San Francisco Bay Area Rapid Transit (BART) Ridership
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SFO to San Francisco in 45 Minutes for Only $6.55!* in 30 Minutes for Only $5.35!*
Fold in to the middle; outside right Back Panel Front Panel Fold in to the middle; outside left OAK to San Francisco SFO to San Francisco in 45 minutes for only $6.55!* in 30 minutes for only $5.35!* BART (Bay Area Rapid Transit) from OAK is fast, easy and BART (Bay Area Rapid Transit) provides one of the world’s inexpensive too! Just take the convenient AirBART shuttle Visitors Guide best airport-to-downtown train services. BART takes you bus from OAK to BART to catch the train to downtown San downtown in 30 minutes for only $5.35 one-way or $10.70 Francisco. The entire trip takes about 45 minutes and costs round trip. It’s the fast, easy, inexpensive way to get to only $6.55 one-way or $13.10 round trip. to BART San Francisco. The AirBART shuttle departs every 15 minutes from the The BART station is located in the SFO International Terminal. 3rd curb across from the terminals. When you get off the It’s only a five minute walk from Terminal Three and a shuttle at the Coliseum BART station, buy a round trip BART 10 minute walk from Terminal One. Both terminals have ticket from the ticket machine. Take the escalator up to the Powell Street-Plaza Entrance connecting walkways to the International Terminal. You can westbound platform and board a San Francisco or Daly City also take the free SFO Airtrain to the BART station. bound train. The BART trip to San Francisco takes about 20 minutes. Terminal 2 (under renovation) Gates 40 - 48 Gates 60 - 67 Terminal 3 Terminal 1 Gates 68 - 90 Gates 20 - 36 P Domestic Want to learn about great deals on concerts, plays, Parking museums and other activities during your visit? Go to www.mybart.org to learn about fantastic special offers for BART customers. -

2017-2026 Samtrans Short Range Transit Plan
SAN MATEO COUNTY TRANSIT DISTRICT Short-Range Transit Plan Fiscal Years 2017 – 2026 May 3, 2017 Acknowledgements San Mateo County Transit District Board of Directors 2017 Rose Guilbault, Chair Charles Stone, Vice Chair Jeff Gee Carole Groom Zoe Kersteen-Tucker Karyl Matsumoto Dave Pine Josh Powell Peter Ratto Senior Staff Michelle Bouchard, Chief Operating Officer, Rail Michael Burns, Interim Chief Officer, Caltrain Planning / CalMod April Chan, Chief Officer, Planning, Grants, and Transportation Authority Jim Hartnett, General Manager/CEO Kathleen Kelly, Interim Chief Financial Officer / Treasurer Martha Martinez, Executive Officer, District Secretary, Executive Administration Seamus Murphy, Chief Communications Officer David Olmeda, Chief Operating Officer, Bus Mark Simon, Chief of Staff Short Range Transit Plan Project Staff and Contributors Douglas Kim, Director, Planning Lindsey Kiner, Senior Planner, Planning David Pape, Planner, Planning Margo Ross, Director of Transportation, Bus Transportation Karambir Cheema, Deputy Director ITS, Bus Transportation Ana Rivas, South Base Superintendent, Bus Transportation Ladi Millard, Director of Budgets, Finance Ryan Hinchman, Manager Financial Planning & Analysis, Finance Donald G. Esse, Senior Operations Financial Analyst, Bus Operations Leslie Fong, Senior Administrative Analyst, Grants Tina Dubost, Manager, Accessible Transit Services Natalie Chi, Bus Maintenance Contract Administrator, Bus Transportation Joan Cassman, Legal Counsel (Hanson Bridgett) Shayna M. van Hoften, Legal Counsel (Hanson -

PUBLIC UTILITIES COMMISSION March 28, 2017 Agenda ID# 15631
STATE OF CALIFORNIA EDMUND G. BROWN JR., Governor PUBLIC UTILITIES COMMISSION 505 VAN NESS AVENUE SAN FRANCISCO, CA 94102 March 28, 2017 Agenda ID# 15631 TO PARTIES TO RESOLUTION ST-203 This is the Resolution of the Safety and Enforcement Division. It will be on the April 27, 2017, Commission Meeting agenda. The Commission may act then, or it may postpone action until later. When the Commission acts on the Resolution, it may adopt all or part of it as written, amend or modify it, or set it aside and prepare its own decision. Only when the Commission acts does the resolution become binding on the parties. Parties may file comments on the Resolution as provided in Article 14 of the Commission’s Rules of Practice and Procedure (Rules), accessible on the Commission’s website at www.cpuc.ca.gov. Pursuant to Rule 14.3, opening comments shall not exceed 15 pages. Late-submitted comments or reply comments will not be considered. An electronic copy of the comments should be submitted to Colleen Sullivan (email: [email protected]). /s/ ELIZAVETA I. MALASHENKO ELIZAVETA I. MALASHENKO, Director Safety and Enforcement Division SUL:vdl Attachment CERTIFICATE OF SERVICE I certify that I have by mail this day served a true copy of Draft Resolution ST-203 on all identified parties in this matter as shown on the attached Service List. Dated March 28, 2017, at San Francisco, California. /s/ VIRGINIA D. LAYA Virginia D. Laya NOTICE Parties should notify the Safety Enforcement Division, California Public Utilities Commission, 505 Van Ness Avenue, San Francisco, CA 94102, of any change of address to ensure that they continue to receive documents. -

SAMTRANS CORRESPONDENCE As of 12-11-2020
SAMTRANS CORRESPONDENCE as of 12-11-2020 December 8, 2020 The Honorable Gavin Newsom Governor, State of California State Capitol, Suite 1173 Sacramento, CA 95814 Dear Governor Newsom: Bay Area transit systems continue to struggle in the face of dramatically reduced ridership and revenues due to the COVID-19 pandemic. This challenge was already the most significant crisis in the history of public transportation, and now it has persisted far longer than any of us would have predicted. Since the beginning, our workers have been on the front lines, doing their jobs as essential workers, responsible for providing other front line workers with a way to safely travel to and from essential jobs. Now that the availability of a vaccine is on the horizon, we are proud to echo the attached call from the Amalgamated Transit Union (ATU). Specifically, we urge you to work to ensure that transit, paratransit, and school transportation workers are prioritized along with other essential workers to receive the vaccine following the critical need to vaccinate the State’s healthcare workers. Even with reduced ridership, an average of 8 million monthly riders continue to depend on Bay Area transit services. These riders are the healthcare workers, grocery clerks, caregivers, emergency services personnel and others doing the critical work that has kept California functioning during the pandemic. They cannot continue to do so without access to reliable public transportation, and are therefore dependent on the health of the transit workers that serve them every day. Our agencies have worked hard to ensure the public health of riders and transit workers during this crisis. -

BART to Antioch Extension Title VI Equity Analysis & Public
BART to Antioch Extension Title VI Equity Analysis & Public Participation Report October 2017 Prepared by the Office of Civil Rights San Francisco Bay Area Rapid Transit District Table of Contents I. BART to Antioch Title VI Equity Analysis Executive Summary 1 Section 1: Introduction 7 Section 2: Project Description 8 Section 3: Methodology 20 Section 4: Service Analysis Findings 30 Section 5: Fare Analysis Findings 39 II. Appendices Appendix A: 2017 BART to Antioch Survey Appendix B: Proposed Service Plan Appendix C: BART Ridership Project Analysis Appendix D: C-Line Vehicle Loading Analysis III. BART to Antioch Public Participation Report i ii BART to Antioch Title VI Equity Analysis and Public Participation Report Executive Summary In October 2011, staff completed a Title VI Analysis for Antioch Station (formerly known as Hillcrest Avenue Station). A Title VI/Environmental Justice analysis was conducted on the Pittsburg Center Station on March 19, 2015. Per the Federal Transit Administration (FTA) Title VI Circular (Circular) 4702.1B, Title VI Requirements and Guidelines for Federal Transit Administration Recipients (October 1, 2012), the District is required to conduct a Title VI Service and Fare Equity Analysis (Title VI Equity Analysis) for the Project's proposed service and fare plan six months prior to revenue service. Accordingly, staff completed an updated Title VI Equity Analysis for the BART to Antioch (Project) service and fare plan, which evaluates whether the Project’s proposed service and fare will have a disparate impact on minority populations or a disproportionate burden on low-income populations based on the District’s Disparate Impact and Disproportionate Burden Policy (DI/DB Policy) adopted by the Board on July 11, 2013 and FTA approved Title VI service and fare methodologies. -

Background Statement to Bay Area Regional Government
~1t1!trm./ALAMEDA-CONTRA COSTA TRANSIT DISTRICT Latham Square Building· 508 Sixteenth Street, Oakland, California 94612 • Telephone 654-7878 April 11, 1968 Mr. Chairman and Members of the Joint Committee on Bay Area Regional Government STATEMENT BY ALAMEDA-CONTRA COSTA TRANSIT DISTRICT BACKGROUND AND HISTORY The Alameda-Contra Costa Transit District was created in 1956 by a vote of the electorate in the East Bay. The enabling statute I the IITransi t District Law," ,..,.as adopted by the Legislature in 1955 after a long period of study and agonizing over the transit service offered by the Key System Transit Lines. As early as 1950 a report was issued to the Mayors and City Managers of the cities of the East Bay, recommending that a public agency be created to take over and operate a transit system in the East Bay. In 1953, after the disasterous 76-day Key System strike, the cities and counties of the East Bay fashioned the legislation which eventually resulted in the creation of the Alameda-Contra Costa Transit Districto Two-thirds of the cities in the originally proposed area of the District had to vote in favor of placing the matter on the ballot. The electorate in an equal number of cities in the proposed district had to vote in favor of creating the District. The Board of Directors of the District are directly elected by the voters, two at-large and five from wards evenly dis tributed throughout the district. The voters of the district approved a bond issue in 1959, permitting the District to purchase facilities from Key System Transit Lines and to commence operations in 1960. -

West Contra Costa High-Capacity Transit Study
West Contra Costa High-Capacity Transit Study FINAL TECHNICAL MEMORANDUM #4 Summary and Evaluation of Prior Studies September 2015 West Contra Costa High-Capacity Transit Study Document Version Control Revision Updated By Organization Description of Revision Date Incorporate feedback from BART 8/14/2015 Doris Lee Parsons Brinckerhoff Board Member City of Richmond staff requested that South Richmond Transportation 8/20/2015 Doris Lee Parsons Brinckerhoff Connectivity Plan be included. Tech memo updated to note that this plan is covered in Section 2.15 Incorporated edits to address SMG 8/27/2015 Doris Lee Parsons Brinckerhoff and TAC feedback 9/16/15 Tam Tran Parsons Brinckerhoff Made minor edits related to tense Document Sign-off Name Date Signature Rebecca Kohlstrand 09/16/15 ii Draft Summary and Evaluation of Prior Studies September 2015 West Contra Costa High-Capacity Transit Study Table of Contents 1 Introduction ......................................................................................................... 1 1.1 West Contra Costa County Transportation Setting ........................................... 1 1.2 Study Purpose .................................................................................................. 2 1.3 Purpose of this Technical Memorandum ........................................................... 3 2 Review OF Prior Studies .................................................................................... 4 2.1 BART West Contra Costa Extension Study, 1983 ........................................... -

San Francisco Bay Area Regional Rail Plan, Chapter 7
7.0 ALTERNATIVES DEFINITION & Fig. 7 Resolution 3434 EVALUATION — STEP-BY-STEP Step One: Base Network Healdsburg Sonoma Recognizing that Resolution 3434 represents County 8 MTC’s regional rail investment over the next 25 Santa years as adopted first in the 2001 Regional Trans- Rosa Napa portation Plan and reaffirmed in the subsequent County Vacaville 9 plan update, Resolution 3434 is included as part Napa of the “base case” network. Therefore, the study Petaluma Solano effort focuses on defining options for rail improve- County ments and expansions beyond Resolution 3434. Vallejo Resolution 3434 rail projects include: Marin County 8 9 Pittsburg 1. BART/East Contra Costa Rail (eBART) San Antioch 1 Rafael Concord Richmond 2. ACE/Increased Services Walnut Berkeley Creek MTC Resolution 3434 Contra Costa 3. BART/I-580 Rail Right-of-Way Preservation County Rail Projects Oakland 4. Dumbarton Bridge Rail Service San 1 BART: East Contra Costa Extension Francisco 10 6 3 2 ACE: Increased Service 5. BART/Fremont-Warm Springs to San Jose Daly City 2 Pleasanton Livermore 3 South Extension BART: Rail Right-of-Way Preservation San Francisco Hayward Union City 4 Dumbarton Rail Alameda 6. Caltrain/Rapid Rail/Electrification & Extension San Mateo Fremont County 5 BART: Fremont/Warm Springs 4 to Downtown San Francisco/Transbay Transit to San Jose Extension 7 Redwood City 5 Center 6 & Extension to Downtown SF/ Mountain Milpitas Transbay Transit Center View Palo Alto 7. Caltrain/Express Service 7 Caltrain: Express Service Sunnyvale Santa Clara San San Santa Clara 8 Jose 8. SMART (Sonoma-Marin Rail) SMART (Sonoma-Marin Rail) Mateo Cupertino County 9 County 9. -
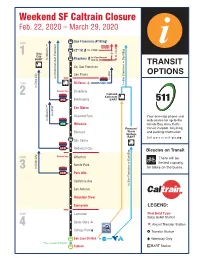
Weekend SF Caltrain Closure Feb
Weekend SF Caltrain Closure Feb. 22, 2020 – March 29, 2020 San Francisco (4th/King) ZONE st nd to 3rd/20th 22 St 8 1 Daly T 9 City to San Bruno/ BART to Mission/1 Bayshore Arleta So. San Francisco TRANSIT San Bruno OPTIONS to Downtown San Francisco to SFO SFO ZONE Millbrae to San Francisco or East Bay to Daly City Weekend Only Broadway 2 Oakland Coliseum 292 Burlingame BART st San Mateo via SFO Hayward Park Your one-stop phone and to Mission/1 web source for up-to-the 398 Hillsdale minute Bay Area traffic, Fremont/ transit, carpool, bicycling Belmont Warm and parking information Springs BART San Carlos ECR Redwood City Bicycles on Transit Weekend Only ZONE Atherton There will be limited capacity Menlo Park 3 to Daly City for bikes on the buses. ECR Palo Alto California Ave to San Francisco or East Bay San Antonio Mountain View Sunnyvale LEGEND: ZONE Lawrence Red Bold Type - Baby Bullet Station Santa Clara 4 Airport Transfer Station College Park ◊ • Transfer Station San Jose Diridon 181 ◊ Weekday Only Free weekend Shuttle Tamien BART Station Caltrain will NOT provide weekend service to San Francisco or 22nd Street stations February 22, 2020 to March 29, 2020. Trains will terminate at Bayshore Station. Free bus service will be available for Caltrain riders from Bayshore Station to 22nd Street and San Francisco stations. Listed below are some transit options that might work better for you. Connect with BART (bart.gov) at the Use SamTrans Bus Service (Limited Millbrae Transit Center Number of Bikes Allowed) Estimated Travel Time (From Millbrae BART From/To Downtown San Francisco Station): Route 292 (samtrans.com/292) • Approx. -
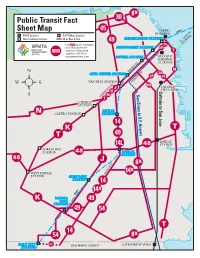
Transit Fact Sheet and Muni Tips With
8x Public Transit Fact 30 Sheet Map 45 FERRY BUILDING BART BART Stations BART/Muni Stations AND AKL GE ID Muni Subway Stations Muni Bus & Rail EMBARCADERO STATION - O F. 49 S. Y BR For route, schedule, 14 BA fare and accessible MONTGOMERY STATION 14x services information T anytime: Call 311 or visit www.sfmta.com POWELL STATION TRANSBAY TERMINAL (AC TRANSIT) N MARKET ST. CIVIC CENTER STATION 30 8x 45 VAN NESS STATION MISSION ST. D x N 14 U CALTRAIN O J R Caltrain to San Jose San to Caltrain 4TH & KING G K ER D SamTrans to S.F. Airport N N U T CHURCH STATION 16TH ST. N CASTRO STATION STATION 14 K T T 49 22ND ST. 14L 48 STATION FOREST HILL STATION 48 24TH ST. STATION 48 J 8x 14x WEST PORTAL MISSION ST. STATION GLEN PARK STATION 14 14x BART BALBOA K PARK 49 STATION 49 54 T 14 54 8x DALY CITY 14L SAN MATEO COUNTY BAYSHORE STATION STATION San Francisco Public Transit Options FACT SHEET AND MUNI ROUTE TIPS Muni bus routes providing alternate, parallel service to BART service within San Francisco are indicated with numbers, while Muni rail lines are indicated with letters. Adult full Muni fare is $2. Youth and Senior/Disabled fare is 75 cents. Exact change or Clipper Cards are required on Muni vehicles; Muni Metro tickets can be purchased at the Metro vend- ing machines in the subway stations for use at subway fare gates. To reach San Francisco International Airport or other peninsula destinations use SamTrans or Caltrain service. -

Building a Better BART: the Future of the Bay Area's Rapid Transit
BUILDING A BETTER BART Investing in the Future of the Bay Area’s Rapid Transit System July 2014 DRAFT Building a Better BART TABLE OF CONTENTS Introduction BART’s Role in the Region Investing in BART’s Future Overview of the BART System BART’s Recent Accomplishments Building a Better BART: Major Investment Initiatives Conclusion: Allocating Limited Resources III 392,300 daily riders 331,600 daily riders 1976 Embarcadero station opens daily riders 1973 211,600 20 new stations daily riders 146,800 1962 daily riders Voters approve 2003 $792 million 1996 Four SFO Extension bond to fund Colma and stations begin 2011 construction of Pittsburg/Bay service: South San West Dublin/ 71-mile Point stations Francisco, San Bruno, Pleasanton BART System open SFIA, and Millbrae station opens 1978 1985 2001 2013 1957 California State 1995 2007 2012 Legislature North Concord/ Annual ridership Record ridership creates the Martinez station BART District hits a record of 568,061 opens 101.7 million exits in a day 1997 1972 Castro Valley and BART begins serving Dublin/Pleasanton 12 stations between stations open MacArthur and Fremont 1974 Transbay Service begins The Story of BART BART’s capacity as demographic changes have made INTRODUCTION transit increasingly popular. The region is planning for In 1962, the residents of the Bay Area made a visionary much of its future growth to be located around BART investment in the region’s future by voting to fund stations, which will add even more passengers. Finally, the initial construction of the Bay Area Rapid Transit system extensions are under construction to southern system (BART). -

BAY AREA RAPID TRANSIT DISTRICT 300 Lakeside Drive, P.O
SAN FRANCISCO BAY AREA RAPID TRANSIT DISTRICT 300 Lakeside Drive, P.O. Box 12688 Oakland, CA 94604-2688 (510) 464-6000 2008 April 18, 2008 Gail Murray PRESIDENT V1A E-MAIL and Thomas M. Blalock, P.E. VICE PRESIDENT U.S. POSTAL SERVICE Dorothy W. Dugger GENERAL MANAGER Mr. Kevin Kennedy, Chief Program Evaluation Branch DIRECTORS Office of Climate Change California Air Resources Board Gail Murray 1ST DISTRICT 1001 I Street Joel Keller Sacramento, CA 95814 2ND DISTRICT Bob Franklin RE: Role of Offsets Under AB 32 3RD DISTRICT Carole Ward Allen 4TH DISTRICT Dear Mr. Kennedy: Zoyd Luce 5TH DISTRICT The San Francisco Bay Area Rapid Transit Dist1ict ("BART") operates a heavy Thomas M. Blalock, P.E. rail public rapid-transit system serving the San Francisco Bay Area. The system 6TH DISTRICT consists of 104 miles of track and 43 stations, and serves 1.3 billion passenger Lynette Sweet miles per year. Because each BART trip is estimated to produce onl y 14% of 7TH DISTRICT the per-mile greenhouse gas ("GHG") emissions generated by travel by private JamesFang 8TH DISTRICT auto, BART helps to reduce the Bay Area's net greenhouse gas emissions by an Tom Radulovich estimated 0.4 million metric tons ("MMT") CO2 per year. Thi s reducti on is 9TH DISTRICT equi valent to roughl y one percent of the Bay Area's transpo11ation sector CO2 emissions, and is the same magnitude as many of the Discrete Early Action measures adopted by ARB. BART appreciates the oppo11unity to respond to the GHG emission offsets questions posed by Air Resources Board staff in connectiory with the April 4, 2008 AB 32 Technical Stakeholder Worki ng Group Meeting on offsets.