Analysis and Recognition of Persian and Arabic Handwritten Characters
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

9789004165403.Pdf
The Arabic Manuscript Tradition Supplement Handbook of Oriental Studies Section 1, The Near and Middle East Editors H. Altenmüller B. Hrouda B.A. Levine R.S. O’Fahey K.R. Veenhof C.H.M. Versteegh VOLUME 95 The Arabic Manuscript Tradition A Glossary of Technical Terms and Bibliography – Supplement By Adam Gacek LEIDEN • BOSTON 2008 This book is printed on acid-free paper. Library of Congress Cataloging-in-Publication Data Gacek, Adam. The Arabic manuscript tradition : a glossary of technical terms and bibliography : supplement / by Adam Gacek. p. cm. — (Handbook of Oriental studies. Section 1, the Near and Middle East) Includes bibliographical references and index. ISBN 978-90-04-16540-3 (hardback : alk. paper) 1. Manuscripts, Arabic—History—Bibliography. 2. Codicology—Dictionaries. 3. Arabic language—Dictionaries—English. 4. Paleography, Arabic—Bibliography. I. Title. II. Series. Z6605.A6G33 2001 Suppl. 011'.31—dc22 2008005700 ISSN 0169–9423 ISBN 978 90 04 16540 3 Copyright 2008 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill, Hotei Publishing, IDC Publishers, Martinus Nijhoff Publishers and VSP. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Koninklijke Brill NV provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. Fees are subject to change. PRINTED IN THE NETHERLANDS CONTENTS Transliteration table ....................................................................... -

Creating Standards
Creating Standards Unauthenticated Download Date | 6/17/19 6:48 PM Studies in Manuscript Cultures Edited by Michael Friedrich Harunaga Isaacson Jörg B. Quenzer Volume 16 Unauthenticated Download Date | 6/17/19 6:48 PM Creating Standards Interactions with Arabic Script in 12 Manuscript Cultures Edited by Dmitry Bondarev Alessandro Gori Lameen Souag Unauthenticated Download Date | 6/17/19 6:48 PM ISBN 978-3-11-063498-3 e-ISBN (PDF) 978-3-11-063906-3 e-ISBN (EPUB) 978-3-11-063508-9 ISSN 2365-9696 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 License. For details go to http://creativecommons.org/licenses/by-nc-nd/4.0/. Library of Congress Control Number: 2019935659 Bibliographic information published by the Deutsche Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available on the Internet at http://dnb.dnb.de. © 2019 Dmitry Bondarev, Alessandro Gori, Lameen Souag, published by Walter de Gruyter GmbH, Berlin/Boston Printing and binding: CPI books GmbH, Leck www.degruyter.com Unauthenticated Download Date | 6/17/19 6:48 PM Contents The Editors Preface VII Transliteration of Arabic and some Arabic-based Script Graphemes used in this Volume (including Persian and Malay) IX Dmitry Bondarev Introduction: Orthographic Polyphony in Arabic Script 1 Paola Orsatti Persian Language in Arabic Script: The Formation of the Orthographic Standard and the Different Graphic Traditions of Iran in the First Centuries of -

Leila's Alphabet Journey Text Book 2019 -Reduced
Leila’ s Alphabet Journey A Practical Guide to the Persian Alphabet By Parastoo Danaee Beginner Level !1 Contents To The Students 4 Introduction | Facts about Persian Language 6 Unit 1 | Persian Alphabet 14 Letter Forms 15 Persian Vowel Forms 17 Practice 1 18 Unit 2 | Basic Features of the Persian Alphabet 20 Practice 2 22 Unit 3 | Letter Forms 23 Non-Connecting Letter Forms 23 Letter Forms 24 Persian Vowel Forms 26 Practice 3 27 Unit 4| Features of the Persian Vowels 29 Short Vowels 29 Long Vowels 30 Diphthongs 30 Practice 4 31 Unit 5| Persian Letters Alef, Be, Pe, Te, Se 32 Practice 5 34 Unit 6| Persian Letters Dâl, Zâl, Re, Ze, Zhe 36 Practice 6 38 Unit 7| Persian Letters Jim, Che, He, Khe 40 Practice 7 42 Unit 8| Persian Letters Sin, Shin, Sât, Zât, Tâ, Zâ 44 Practice 8 46 Unit 9 | Persian Letters ‘Ain, Ghain, Fe, Gh"f 48 Practice 9 50 Unit 10| Persian Letters K"f, Gh"f, L"m,Mim 52 !2 Practice 10 54 Unit 11| Persian Letters Nun, V"v, He, Ye 56 Practice 11 58 Unit 12 | Short Vowels 60 Practice 12 61 Unit 13 | Long Vowels 63 Practice 13 64 Unit 14 | Additional Signs 66 Practice 14 67 !3 To The Students Welcome to Persian! Leila’s Alphabet Journey represents the first in a series of textbooks aimed at teaching Persian to foreign students and is followed by Leila Goes to Iran . Leila, the leading character is a generation 1.5 young lady who grow up in Los Angeles in a home in which Persian language is spoken. -

The Judeo-Arabic Heritage
The Judea-Arabic Heritage 41 Chapter 3 tice my speaking skills, and my wife was clearly delighted to show off her Ashkenazi American husband who could speak their native tongue. A short while later, after the woman departed, I noticed that my wife had tears in her eyes. When I asked her why, she told me that she suddenly The Judeo-Arabic Heritage remembered how years earlier, when she was a schoolgirl, that if she saw that same woman from a distance, she would walk blocks out of her way to avoid her. This was to avoid embarrassment from having to speak Norman A. Stillman Moroccan Arabic in public because of the strong prejudice against Jews from Muslim countries (so-called mizrahim, or Oriental Jews) and espe cially Moroccan Jews. In the 1950S and early 1960s, it was not at all chic to speak Arabic of any kind in Israel-and certainly not to be Moroccan. The great irony in these two personal anecdotes is that, amongst all the Introductory Reflections many Jewish Diaspora languages of post-Talmudic times (Yiddish, Ladino, Shuadit (Iudeo-Provencal), Judeo-Persian, Iudeo-Greek, Iudeo-French, Nearly forty years ago, I brought my fiancee, who had been born in Iudeo-Tat, Iudeo-Berber, and still others less well known), [udeo-Arabic Morocco and raised in Israel, home to meet my family. I shall never forget held a place of special distinction. It had the longest recorded history after the moment when she met my grandmother. My grandmother, whose Hebrew and Aramaic (from the ninth century to the present)." It had the English, even after fifty years in the United States, was still heavily widest geographical diffusion, extending across three continents during accented, asked my fiancee, "Does your family speak Jewish?" Not under the Middle Ages. -

Estelle Whelan, 'Writing the Word of God: Some Early Qur'
WRITING THE WORD OF GOD: SOME EARLYQUR'AN MANUSCRIPTS AND THEIR MILIEUX, PART I BYESTELLE WHELAN One is left wondering how anyone dares to date a MS. from the cursive scripts of the calligraphers.4 In 1911 Bernhard writing alone. Moritz commented, rather confusingly, "it is impossi- S. -A. Tritton1 ble to avoid the conclusion that the difference between the two types was chiefly due to the nature of the WESrERN SCHOLARSCOMING TO GRIPSWiTH ARABIC MANU- material written on, though at the same time there scripts for the first time after years of striving to master existed a tendency to create a separate monumental the language from printed texts often find the experi- script."5Nabia Abbott attempted to identify some of the ence disheartening. Not only are they cast adrift among early Qur'anic scripts from brief textual descriptions. the idiosyncrasies of individual handwriting, their firm For example, a single phrase in the fourth-/tenth- grasp of grammar sabotaged by scribal ignorance or century Fihrist of Ibn al-Nadlim led to her identifying carelessness and their confidence shaken by violations Uijaz1 script by three rather general traits, none of of the orthographic rules (connection of supposedly them exclusive to it.6 She then defined Kfific by the unconnected letters, for example), but they are also absence of this combinationof traits and went on to unlikely to have received from either their teachers or propose two subcategories-one angular, one round- their books much guidance in how to deal with their ed. Without denying the value ofAbbott's work, it must perplexity. -

Arabic Alphabet 1 Arabic Alphabet
Arabic alphabet 1 Arabic alphabet Arabic abjad Type Abjad Languages Arabic Time period 400 to the present Parent systems Proto-Sinaitic • Phoenician • Aramaic • Syriac • Nabataean • Arabic abjad Child systems N'Ko alphabet ISO 15924 Arab, 160 Direction Right-to-left Unicode alias Arabic Unicode range [1] U+0600 to U+06FF [2] U+0750 to U+077F [3] U+08A0 to U+08FF [4] U+FB50 to U+FDFF [5] U+FE70 to U+FEFF [6] U+1EE00 to U+1EEFF the Arabic alphabet of the Arabic script ﻍ ﻉ ﻅ ﻁ ﺽ ﺹ ﺵ ﺱ ﺯ ﺭ ﺫ ﺩ ﺥ ﺡ ﺝ ﺙ ﺕ ﺏ ﺍ ﻱ ﻭ ﻩ ﻥ ﻡ ﻝ ﻙ ﻕ ﻑ • history • diacritics • hamza • numerals • numeration abjadiyyah ‘arabiyyah) or Arabic abjad is the Arabic script as it is’ ﺃَﺑْﺠَﺪِﻳَّﺔ ﻋَﺮَﺑِﻴَّﺔ :The Arabic alphabet (Arabic codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[7] stand for consonants, it is classified as an abjad. Arabic alphabet 2 Consonants The basic Arabic alphabet contains 28 letters. Adaptations of the Arabic script for other languages added and removed some letters, such as Persian, Ottoman, Sindhi, Urdu, Malay, Pashto, and Arabi Malayalam have additional letters, shown below. There are no distinct upper and lower case letter forms. Many letters look similar but are distinguished from one another by dots (’i‘jām) above or below their central part, called rasm. These dots are an integral part of a letter, since they distinguish between letters that represent different sounds. -

Bamana Texts in Arabic Characters: Some Leaves from Mali
Tal Tamari Bamana Texts in Arabic Characters: Some Leaves from Mali Abstract: This study analyses five Bamana-language texts composed in the ear- lier twentieth century by Amadou Jomworo Bary, a Fulbe scholar from the Masina (Mali), that were hand copied in 1972 by the Fulbe scholar and researcher Al- mamy Maliki Yattara. The writing system, which uses modified Arabic characters to note phonemes specific to Bamana, is compared to other West African adapta- tions of Arabic script. The article also examines the doctrinal positions developed and world view implicit in the texts, which concern water rites in San (Mali), Is- lamic belief and practice, and healing. Attention is drawn as to how knowledge of local cultural contexts can contribute to a better understanding of these manu- scripts. 1 Introduction In 1994, I published a study of five short texts (totalling five and a half pages), written in Arabic characters in the Bamana language. These texts had been cop- ied by Almamy Maliki Yattara, a Muslim scholar then employed by the Institut des Sciences Humaines in Bamako, from originals held by a friend of his, Abou- bacar (commonly known as Bory) Bary, in 1972 in San (Mali). Research conducted in the intervening twenty years has confirmed the analysis of the writing system, and has led to few changes in the transliteration (Arabic to Latin characters), transcription (reconstitution of the Bamana discourse) and translations of these texts. On the other hand, personal fieldwork undertaken in the interval, as well as general progress in the understanding of West African writing practices, makes it possible to place these texts in much sharper historical and cultural per- spective. -

Speaking Arabic
Chapter 1 I Say It How? Speaking Arabic In This Chapter ▶ Discovering English words that come from Arabic ▶ Figuring out the Arabic alphabet ▶ Practicing the sounds arHaba (mahr-hah-bah; welcome) to the won- Mderful world of Arabic! In this chapter, I ease you into the language by showing you some familiar English words that trace their roots to Arabic. You discover the Arabic alphabet and its beautiful letters, and I give you tips on how to pronounce those letters. Part of exploring a new language is discovering a new culture and a new way of looking at things, so in this first chapter of Arabic Phrases For Dummies, you begin your discovery of Arabic and its unique characteristics. Taking Stock of What’s Familiar If English is your primary language, part of grasping COPYRIGHTEDa new lougha (loo-ghah; language) MATERIAL is creating con- nections between the kalimaat (kah-lee-maht; words) of the lougha, in this case Arabic and English. You may be surprised to hear that quite a few English words trace their origins to Arabic. For example, did you know that “magazine,” “candy,” and “coffee” are 005_225233-ch01.indd5_225233-ch01.indd 5 11/30/09/30/09 111:39:491:39:49 PPMM 6 Arabic Phrases For Dummies actually Arabic words? Table 1-1 lists some familiar English words with Arabic origins. Table 1-1 Arabic Origins of English Words English Arabic Origin Arabic Meaning admiral amir al-baHr Ruler of the Sea alcohol al-kuHul a mixture of powdered antimony alcove al-qubba a dome or arch algebra al-jabr to reduce or consolidate almanac al-manakh a -

Grammar Grammatical and Weight Wise Concordance of Qur'an Quran
Idea & Some Work on Grammatical and Weight Wise Concordance of the Qur'an (Version 1.1) I am thankful to ALLAH for honoring me with this oppurtunity to serve Qur'an, no credit is mine at all. All credit goes only to ALLAH. Any mistake is due to me. Advantage: Grammatical concordance of the Qur'an. Many efforts are being made on vocabulary and root wise concordance of the Qur'an , but this idea focuses on grammatical and weight wise concordance of the Qur'an using similar weights of different roots. Like in vocabulary concordance different weights of the same root have some link to the root meaning, similarly in grammar concordance same weights usually have some similar effects on the meaning of the root. Column named Fa Ayn Laam is meant to put 3 letter roots of words e.g. for Raheem root is ra ha miim, column weight is to put weight of root e.g for Raheem weight is fa'eel, and G2 is meant to put noun forms for ease of grouping related words, like verbal forms have terms like I, II, III etc. Similarly these can have terms like N01.1, N01.2..., N02.1..., N03.1... etc. For columns, weight and root, additional columns containing text in Arabic in addition to transliteration can be added making total new columns as 5. For roots containing 2 letters suad laam is used and for 4 letters ba ra zay kha is used. Source: Lemmas sorted by : Group & Frequency from http://corpus.quran.com/lemmas.jsp as on 1-December-2010 . -
Translation: Arthur John Arberry; Transliteration: German…
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 2 ǁ September 2016. www.ijahss.com Contrastive Suprasegmental Features on English and Arabic IPA Transcription of Surah Al Ya Sin Assist. Prof. Dr. Metin Yurtbaşı Bayburt University, Faculty of Education, ELT Department, Bayburt, Turkey ABSTRACT: The greatest difficulty in reading Arabic script for nonnatives has long been considered as the absence of short vowels, however there is more to be dealt with. While the correlation of 28 Arabic consonants pose no great difficulty in decyphering the script, the six vowel phonemes voiced only by three letters even with help of some relevant diacritical marks (ḥarakāt) do not satisfy the needs of nonnatives. As the bulk of Arabic publications is written without such marks, foreign readers are at a loss to read the written work intelligibly unless they are familiar with the grammar of the language. Especially practicing Muslims who are required to read the Islamic Scripture Qur’an even without a deep knowledge of its language are unable to produce acceptable pronunciation. In order to meet the needs of such nonnative believers and the learnerns of the Arabic language, many attempts have been made to transliterate (romanize) the texts replacing letters with their close equivalents in the Latin alphabet by some modifications. Although this method has helped somewhat in decoding the consonants, the issue of vowel representation has always been an unresolved issue. The IPA advocates suggested corresponding vowels from its files and that seems to have solved at least the segmental part of the problem. However knowing that the overall speech intelligibility lies more with prosody, i.e. -

Internationalization and Math
Internationalization and Math Test collection Made by ckepper • English • 2 articles • 156 pages Contents Internationalization 1. Arabic alphabet . 3 2. Bengali alphabet . 27 3. Chinese script styles . 47 4. Hebrew language . 54 5. Iotation . 76 6. Malayalam . 80 Math Formulas 7. Maxwell's equations . 102 8. Schrödinger equation . 122 Appendix 9. Article ourS ces and Contributors . 152 10. Image Sources, Licenses and Contributors . 154 Internationalization Arabic alphabet Arabic Alphabet Type Abjad Languages Arabic Time peri- 356 AD to the present od Egyptian • Proto-Sinaitic ◦ Phoenician Parent ▪ Aramaic systems ▪ Syriac ▪ Nabataean ▪ Arabic Al- phabet Arabic alphabet | Article 1 fo 2 3 َْ Direction Right-to-left األ ْب َج ِد َّية :The Arabic alphabet (Arabic ا ْل ُح ُروف al-ʾabjadīyah al-ʿarabīyah, or ا ْل َع َربِ َّية ISO ْ al-ḥurūf al-ʿarabīyah) or Arabic Arab, 160 ال َع َربِ َّية 15924 abjad is the Arabic script as it is codi- Unicode fied for writing Arabic. It is written Arabic alias from right to left in a cursive style and includes 28 letters. Most letters have • U+0600–U+06FF contextual letterforms. Arabic • U+0750–U+077F Originally, the alphabet was an abjad, Arabic Supplement with only consonants, but it is now con- • U+08A0–U+08FF sidered an "impure abjad". As with other Arabic Extended-A abjads, such as the Hebrew alphabet, • U+FB50–U+FDFF scribes later devised means of indicating Unicode Arabic Presentation vowel sounds by separate vowel diacrit- range Forms-A ics. • U+FE70–U+FEFF Arabic Presentation Consonants Forms-B • U+1EE00–U+1EEFF The basic Arabic alphabet contains 28 Arabic Mathematical letters. -
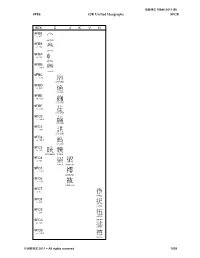
Unibook Document
ISO/IEC 10646:2011 (E) 9FB8 CJK Unified Ideographs 9FCB HEX C JKVH 9FB8 , 42.2 龸 G9-FE6D 9FB9 12.4 龹 G9-FE7E 9FBA 24.6 龺 G9-FE90 9FBB 149.12 龻 G9-FEA0 9FBC " 32.14 UTC-00836 9FBD L 86.11 UTC-00835 9FBE f 107.8 UTC-00837 9FBF 140.8 UTC-00838 9FC0 140.18 UTC-00839 9FC1 149.6 UTC-00840 9FC2 159.11 UTC-00841 9FC3 i 109.7 鿃 鿃 GKX-0809.02 T4-3946 9FC4 I 75.6 鿄 鿄 TC-4A76 JARIB-754F 9FC5 m 113.13 鿅 JARIB-7621 9FC6 m 113.4 舘 JARIB-757D 9FC7 9.6 鿇 H-87C2 9FC8 : 60.4 鿈 H-87D2 9FC9 : 60.4 鿉 H-87D6 9FCA 140.7 鿊 H-87DA 9FCB 145.12 鿋 H-87DF © ISO/IEC 2011 – All rights reserved 1029 ISO/IEC 10646:2011 (E) A000 Yi Syllables A0EF A00 A01 A02 A03 A04 A05 A06 A07 A08 A09 A0A A0B A0C A0D A0E 0 ꀀ ꀐ ꀠ ꀰ ꁀ ꁐ ꁠ ꁰ ꂀ ꂐ ꂠ ꂰ ꃀ ꃐ ꃠ A000 A010 A020 A030 A040 A050 A060 A070 A080 A090 A0A0 A0B0 A0C0 A0D0 A0E0 1 ꀁ ꀑ ꀡ ꀱ ꁁ ꁑ ꁡ ꁱ ꂁ ꂑ ꂡ ꂱ ꃁ ꃑ ꃡ A001 A011 A021 A031 A041 A051 A061 A071 A081 A091 A0A1 A0B1 A0C1 A0D1 A0E1 2 ꀂ ꀒ ꀢ ꀲ ꁂ ꁒ ꁢ ꁲ ꂂ ꂒ ꂢ ꂲ ꃂ ꃒ ꃢ A002 A012 A022 A032 A042 A052 A062 A072 A082 A092 A0A2 A0B2 A0C2 A0D2 A0E2 3 ꀃ ꀓ ꀣ ꀳ ꁃ ꁓ ꁣ ꁳ ꂃ ꂓ ꂣ ꂳ ꃃ ꃓ ꃣ A003 A013 A023 A033 A043 A053 A063 A073 A083 A093 A0A3 A0B3 A0C3 A0D3 A0E3 4 ꀄ ꀔ ꀤ ꀴ ꁄ ꁔ ꁤ ꁴ ꂄ ꂔ ꂤ ꂴ ꃄ ꃔ ꃤ A004 A014 A024 A034 A044 A054 A064 A074 A084 A094 A0A4 A0B4 A0C4 A0D4 A0E4 5 ꀅ ꀕ ꀥ ꀵ ꁅ ꁕ ꁥ ꁵ ꂅ ꂕ ꂥ ꂵ ꃅ ꃕ ꃥ A005 A015 A025 A035 A045 A055 A065 A075 A085 A095 A0A5 A0B5 A0C5 A0D5 A0E5 6 ꀆ ꀖ ꀦ ꀶ ꁆ ꁖ ꁦ ꁶ ꂆ ꂖ ꂦ ꂶ ꃆ ꃖ ꃦ A006 A016 A026 A036 A046 A056 A066 A076 A086 A096 A0A6 A0B6 A0C6 A0D6 A0E6 7 ꀇ ꀗ ꀧ ꀷ ꁇ ꁗ ꁧ ꁷ ꂇ ꂗ ꂧ ꂷ ꃇ ꃗ ꃧ A007 A017 A027 A037 A047 A057 A067 A077 A087 A097 A0A7 A0B7 A0C7 A0D7 A0E7 8 ꀈ ꀘ ꀨ