On Mongolian Punctuation Marks
Total Page:16
File Type:pdf, Size:1020Kb
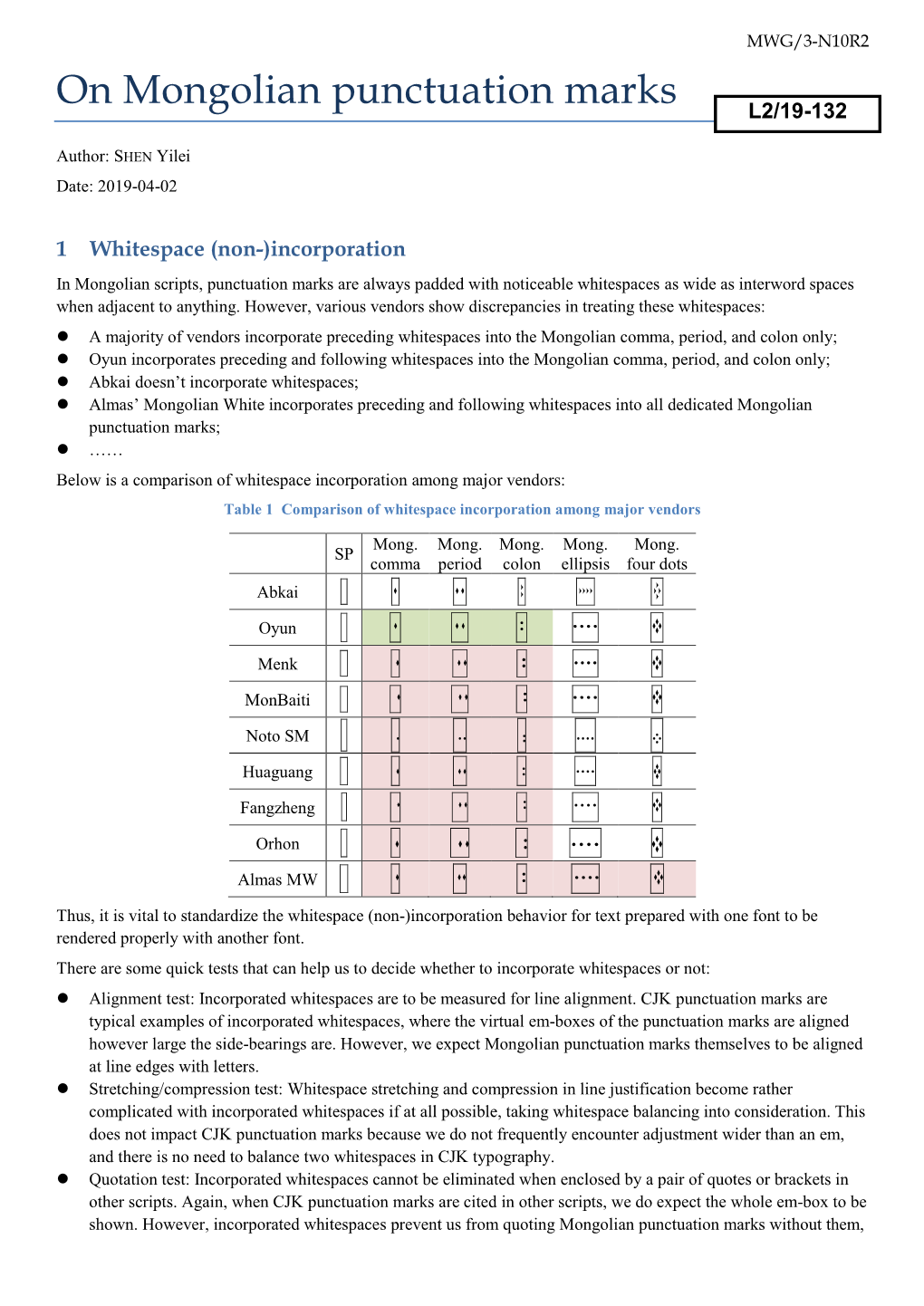
Load more
Recommended publications
-

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Unicode Encoding the TITUS Project
ALCTS "Library Catalogs and Non- 2004 ALA Annual Conference Orlando Roman Scripts" Program Unicode Encoding and Online Data Access Ralf Gehrke / Jost Gippert The TITUS Project („Thesaurus indogermanischer Text- und Sprachmaterialien“) (since 1987/1993) www.ala.org/alcts 1 ALCTS "Library Catalogs and Non- 2004 ALA Annual Conference Orlando Roman Scripts" Program Scope of the TITUS project: • Electronic retrieval engine covering the textual heritage of all ancient Indo-European languages • Present retrieval task: – Documentation of the usage of all word forms occurring in the texts, in their resp. contexts • Survey of the parts of the text database: – http://titus.uni-frankfurt.de/texte/texte2.htm Data formats (since 1995): • Text formats: – WordCruncher Text format (8-Bit) – HTML (UTF-8 Unicode 4.0) – (Plain 7-bit ASCII format) • Database format: – MS Access (relational, Unicode-based) – Retrieval via SQL www.ala.org/alcts 2 ALCTS "Library Catalogs and Non- 2004 ALA Annual Conference Orlando Roman Scripts" Program Original Scripts Covered: • Latin (with all kinds of diacritics), incl. variants* • Greek • Slavic (Cyrillic and Glagolitic*) • Armenian • Georgian • Devangar • Other Brhm scripts (Tocharian, Khotanese)* • Avestan* • Middle Persian (Pahlav)* • Manichean* • Arabic (incl. Persian) • Runic • Ogham • and many more * not yet encodable (as such) in Unicode Example 1a: Donelaitis (Lithuanian: formatted text incl. diacritics: 8-bit version) www.ala.org/alcts 3 ALCTS "Library Catalogs and Non- 2004 ALA Annual Conference Orlando Roman Scripts" Program Example 1b: Donelaitis (Lithuanian: formatted text incl. diacritics: Unicode version) Example 2a: Catechism (Old Prussian: formatted text incl. diacritics: 8-bit version, special TITUS font) www.ala.org/alcts 4 ALCTS "Library Catalogs and Non- 2004 ALA Annual Conference Orlando Roman Scripts" Program Example 2b: Catechism (Old Prussian: formatted text incl. -

Name Synopsis Description
Perl version 5.10.0 documentation - Locale::Script NAME Locale::Script - ISO codes for script identification (ISO 15924) SYNOPSIS use Locale::Script; use Locale::Constants; $script = code2script('ph'); # 'Phoenician' $code = script2code('Tibetan'); # 'bo' $code3 = script2code('Tibetan', LOCALE_CODE_ALPHA_3); # 'bod' $codeN = script2code('Tibetan', LOCALE_CODE_ALPHA_NUMERIC); # 330 @codes = all_script_codes(); @scripts = all_script_names(); DESCRIPTION The Locale::Script module provides access to the ISOcodes for identifying scripts, as defined in ISO 15924.For example, Egyptian hieroglyphs are denoted by the two-lettercode 'eg', the three-letter code 'egy', and the numeric code 050. You can either access the codes via the conversion routines(described below), or with the two functions which return listsof all script codes or all script names. There are three different code sets you can use for identifyingscripts: alpha-2 Two letter codes, such as 'bo' for Tibetan.This code set is identified with the symbol LOCALE_CODE_ALPHA_2. alpha-3 Three letter codes, such as 'ell' for Greek.This code set is identified with the symbol LOCALE_CODE_ALPHA_3. numeric Numeric codes, such as 410 for Hiragana.This code set is identified with the symbol LOCALE_CODE_NUMERIC. All of the routines take an optional additional argumentwhich specifies the code set to use.If not specified, it defaults to the two-letter codes.This is partly for backwards compatibility (previous versionsof Locale modules only supported the alpha-2 codes), andpartly because they are the most widely used codes. The alpha-2 and alpha-3 codes are not case-dependent,so you can use 'BO', 'Bo', 'bO' or 'bo' for Tibetan.When a code is returned by one of the functions inthis module, it will always be lower-case. -

Supplemental Punctuation Range: 2E00–2E7F
Supplemental Punctuation Range: 2E00–2E7F This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Pageflex Character Entitiesa
Pageflex Character EntitiesA A list of all special character entities recognized by Pageflex products n 1 Pageflex Character Entities The NuDoc composition engine inside Pageflex applications recognizes many special entities beginning with the “&” symbol and end with the “;” symbol. Each represents a particular Unicode character in XML content. For information on entity definitions, look up their Unicode identifiers in The Unicode Standard book. This appendix contains two tables: the first lists character entities by name, the second by Unicode identifier. Character Entities by Entity Name This section lists character entities by entity name. You must precede the entity name by “&” and follow it by “;” for NuDoc to recognize the name (e.g., “á”). Note: Space and break characters do not have visible entity symbols. The entity symbol column for these characters is purposely blank. Entity Entity Name Unicode Unicode Name Symbol aacute 0x00E1 á LATIN SMALL LETTER A WITH ACUTE Aacute 0x00C1 Á LATIN CAPITAL LETTER A WITH ACUTE acirc 0x00E2 â LATIN SMALL LETTER A WITH CIRCUMFLEX Acirc 0x00C2 Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX acute 0x00B4 ´ ACUTE ACCENT aelig 0x00E6 æ LATIN SMALL LIGATURE AE AElig 0x00C6 Æ LATIN CAPITAL LIGATURE AE agrave 0x00E0 à LATIN SMALL LETTER A WITH GRAVE Agrave 0x00C0 À LATIN CAPITAL LETTER A WITH GRAVE ape 0x2248 ALMOST EQUAL TO aring 0x00E5 å LATIN SMALL LETTER A WITH RING ABOVE n 2 Entity Entity Name Unicode Unicode Name Symbol Aring 0x00C5 Å LATIN CAPITAL LETTER A WITH RING ABOVE atilde 0x00E3 ã LATIN SMALL LETTER A WITH TILDE Atilde 0x00C3 Ã LATIN CAPITAL LETTER A WITH TILDE auml 0x00E4 ä LATIN SMALL LETTER A WITH DIERESIS Auml 0x00C4 Ä LATIN CAPITAL LETTER A WITH DIERESIS bangbang 0x203C DOUBLE EXCLAMATION MARK br 0x2028 LINE SEPERATOR (I.E. -

Interrobang, for the Incredibility of Modern Life: Or, How to Punctuate the Zeitgeist
INTERROBANG, FOR THE INCREDIBILITY OF MODERN LIFE: OR, HOW TO PUNCTUATE THE ZEITGEIST In 1968, Remington began promoting a new piece of JULIETTE punctuation, the Interrobang. In recalling a footnote in the history of writing, Juliette Kristensen, a KRISTENSEN material culture theorist and self-confessed print addict, asks how we had previously marked the text, and how we are punctuating it today. KIOSK. Left: An Interrobang (‽). KIOSK. 24 25 ‘May you live in interesting times’ – so the curse goes. For text was once written with no punctuation; even ing lost a hand to evolve it; the bodily notation of text And undoubtedly, this is prescient for 2008. From the the space between letters, which counts as an item of became fixed, condensed, punctual. This was cement- =^D :-{) cataclysmic devastation of large parts of Asia, to the punctuation, was missing. Whilst our reading selves find ed further into our chirographic culture in subsequent unfolding political drama in Zimbabwe, to the US presi- this strangely unsettling, we who mentally translate the centuries, most notably when we began to individually dential election and the spreading global credit crunch, spoken word into alphabetic form, identifying the sen- hammer letterforms on the page with the typewriter. this year has all the environmental, political and eco- tence once lay within the words themselves, to readers =^* :-{)} nomic markers of ‘interestingness’. Yet this year also and writers rigorously trained in the classic arts of rhet- The Emotion of Digital Punctuation marks the anniversary of another tumultuous time, in- oric and logic. teresting too for shifting the ground beneath societies’ And where are we now, in our hyper-mediated, digitised, feet: 1968. -

INVERTED INTERROBANG to the UCS Source: Michael Everson Status: Individual Contribution Date: 2005-04-01
ISO/IEC JTC1/SC2/WG2 N2935 L2/05-086 2005-04-01 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to add INVERTED INTERROBANG to the UCS Source: Michael Everson Status: Individual Contribution Date: 2005-04-01 The Universal Character Set encodes ! U+0021 EXCLAMATION MARK and ? U+003F QUESTION MARK, and it encodes ¡ U+00A1 INVERTED EXCLAMATION MARK and ¿ U+00BF INVERTED QUESTION MARK for use in Spanish, Asturian, and Galician. The Standard also encodes a fusion of the first two, ?! U+203D INTERROBANG, a mark which was devised in 1962 by Martin K. Speckter for use in asking a question in an excited manner or expressing excitement or disbelief in the form of a question. The Standard does not, however, provide its inverted counterpart for use in Spanish, Asturian, and Galician. The Wikipedia notes that some people have called this character the GNABORRETNI (interrobang spelled backwards). The French name of this character would be, I believe, POINT EXCLARROGATIF RENVERSÉ. It should be noted that this proposal is not “inventing” the character; it was invented quite some time ago. “Gnaborretni” itself has a rather small Google presence, and many of the references there suggest that there are some implementations of it. The page css.sfu.ca/nsg/cssnetdocs/latex2e/ A dc/dcdoc/node10.html gives a short list of LTEX characters, which turns up in a number of different sites. A full character set which contains both of the characters is listed at www.tug.org/tex- archive/fonts/lm/fonts/enc/dvips/lm/ts1-lm.enc and Unicode discussion list contributor Jörg Knappen’s page at www.tug.org/ftp/pub/pub/ historic/fonts/dc-ec/ec-1.0/tc-chg.txt shows that on 1995-07-22, he “Added interrobang and gnaborretni” to the font. -

The Literary Magazine of Kirby School Santa Cruz, California
Volume 10, Number 1 Winter 2021 Interrobang ‽ The Literary Magazine of Kirby School Santa Cruz, California Interrobang i Interrobang Staff Anna Aiono, Poetry Editor Eddie Couder Averie Huang Tyree Milhorn, Fiction Editor Hunter Reid Penelope Strong Ren Takahashi-Kelso Yunqi (Nick) Zhang Maria Elena Caballero-Robb, Faculty Advisor Interrobang publishes excellent poetry, short fiction, creative nonfiction, drama, and comics written by the students of the Kirby School. Interrobang appears twice yearly, in winter and spring. Share your original, proofread work with our staff at [email protected] anytime between August and May. Contributors need not be on staff. We welcome submissions from Kirby middle school and high school students. Submission guidelines available upon request. The staff of Interrobang meets Friday mornings during club time. We always welcome new members with interests in creative writing, art, literature, and ideas. Interrobang Literary Magazine Kirby School 425 Encinal Street Santa Cruz, CA 95060 Interrobang ii Interrobang Volume 10, Number 1 Winter 2021 iv A Note from the Staff Anna Aiono 1 Pear Treat Yunqi (Nick) Zhang 2 A Riot of Antonyms Tiago Beck 4 Foul Sinners in the Hands of an Angry Fowl Yuenan Huang 7 The Untold Tale of Marco Polo Tyree Milhorn 13 The Progeny Penelope Strong 18 Pumpkin Spice Invasion Yunqi (Nick) Zhang 20 A Verb Study: Speak Yunqi (Nick) Zhang 21 A Verb Study: Talk Tyree Milhorn 22 Silverfish Anna Aiono 36 Bask/Chauffer Yunqi (Nick) Zhang 37 Fugue from the Raven Field Vanessa McKelvey 38 Gas Station Hunter Reid 40 Meditation (for Matthew, Part III) Anna Aiono 42 Off-leash Yunqi (Nick) Zhang 43 Witch Julien Jacklin 45 Stories Are Complicated Interrobang iii January 2021 Dear Readers, In Winter 2021 issue, we are proud to present stories, a personal essay, and a wealth of poems. -

Fun with Unicode - an Overview About Unicode Dangers
Fun with Unicode - an overview about Unicode dangers by Thomas Skora Overview ● Short Introduction to Unicode/UTF-8 ● Fooling charset detection ● Ambigiuous Encoding ● Ambigiuous Characters ● Normalization overflows your buffer ● Casing breaks your XSS filter ● Unicode in domain names – how to short payloads ● Text Direction Unicode/UTF-8 ● Unicode = Character set ● Encodings: – UTF-8: Common standard in web, … – UTF-16: Often used as internal representation – UTF-7: if the 8th bit is not safe – UTF-32: yes, it exists... UTF-8 ● Often used in Internet communication, e.g. the web. ● Efficient: minimum length 1 byte ● Variable length, up to 7 bytes (theoretical). ● Downwards-compatible: First 127 chars use ASCII encoding ● 1 Byte: 0xxxxxxx ● 2 Bytes: 110xxxxx 10xxxxxx ● 3 Bytes: 1110xxxx 10xxxxxx 10xxxxxx ● ...got it? ;-) UTF-16 ● Often used for internal representation: Java, .NET, Windows, … ● Inefficient: minimum length per char is 2 bytes. ● Byte Order? Byte Order Mark! → U+FEFF – BOM at HTML beginning overrides character set definition in IE. ● Y\x00o\x00u\x00 \x00k\x00n\x00o\x00w\x00 \x00t\x00h\x00i\x00s\x00?\x00 UTF-7 ● Unicode chars in not 8 bit-safe environments. Used in SMTP, NNTP, … ● Personal opinion: browser support was an inside job of the security industry. ● Why? Because: <script>alert(1)</script> == +Adw-script+AD4-alert(1)+ADw-/script+AD4- ● Fortunately (for the defender) support is dropped by browser vendors. Byte Order Mark ● U+FEFF ● Appears as:  ● W3C says: BOM has priority over declaration – IE 10+11 just dropped this insecure behavior, we should expect that it comes back. – http://www.w3.org/International/tests/html-css/character- encoding/results-basics#precedence – http://www.w3.org/International/questions/qa-byte-order -mark.en#bomhow ● If you control the first character of a HTML document, then you also control its character set. -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

Day One Consistency
MMW | 1 MANUSCRIPT MAKEOVER WORKSHOP Day One Consistency I hope you’re ready to get started—I’m so excited to share these next ten days with you, and to help you learn some “trade secrets” to line/copy edit your own work a little more efficiently. I think it’s true that often we’re too close to our own work to part with some of it, yet I also think that, given the right tools, it’s easier to take a more objective, more clinical approach to the work of editing. Honestly, the first thing I do when I look at a new manuscript is technical stuff. I find that doing some cut-and-dried tasks to start—spelling checks, bits of formatting, punctuation—helps me to get the ball rolling. And makes it easier to come back with harder tasks later. Here are the first things I’ll check when I start a new project. They fall under the categories of Spelling and Punctuation, but ultimately are concerned with Consistency: • Spelling: o Check name spellings for main characters, then all characters as you come across them. Look for both correct spellings and a few incorrect just in case. For example, Tiffani/Tifany (or look for Tif and see what comes up). o Repeat for place names. o Repeat for book-specific and variable spellings. A big one here is gray/grey. Both are correct, but you must choose and use only one. (Unless you have a Mr. Grey whose cat is gray. Then you’ll have two, but you must keep them ©2020 TheEditingSoprano.com MMW | 2 straight!) A book-specific spelling is particularly important with built worlds (as in fantasy, paranormal, sci-fi) which won’t necessarily be in a dictionary.