Middle East-I 9 Modern and Liturgical Scripts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alif and Hamza Alif) Is One of the Simplest Letters of the Alphabet
’alif and hamza alif) is one of the simplest letters of the alphabet. Its isolated form is simply a vertical’) ﺍ stroke, written from top to bottom. In its final position it is written as the same vertical stroke, but joined at the base to the preceding letter. Because of this connecting line – and this is very important – it is written from bottom to top instead of top to bottom. Practise these to get the feel of the direction of the stroke. The letter 'alif is one of a number of non-connecting letters. This means that it is never connected to the letter that comes after it. Non-connecting letters therefore have no initial or medial forms. They can appear in only two ways: isolated or final, meaning connected to the preceding letter. Reminder about pronunciation The letter 'alif represents the long vowel aa. Usually this vowel sounds like a lengthened version of the a in pat. In some positions, however (we will explain this later), it sounds more like the a in father. One of the most important functions of 'alif is not as an independent sound but as the You can look back at what we said about .(ﺀ) carrier, or a ‘bearer’, of another letter: hamza hamza. Later we will discuss hamza in more detail. Here we will go through one of the most common uses of hamza: its combination with 'alif at the beginning or a word. One of the rules of the Arabic language is that no word can begin with a vowel. Many Arabic words may sound to the beginner as though they start with a vowel, but in fact they begin with a glottal stop: that little catch in the voice that is represented by hamza. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -
Cat Stevens Debuta En Chile Con Dos Conciertos El Cantautor Británico Yusuf Islam Llega Por Primera Vez a Santiago Para Presentarse En Noviembre
DOMINGO 23 DE JUNIO DE 2013 ESPECTÁCULOS [email protected] C19 KC & The Sunshine Band regresa a Chile La banda realizará cuatro conciertos en el país entre el 5 y el 8 de diciembre en los casinos Enjoy Johansson reemplaza de Antofagasta, Coquimbo, Santiago y Viña del a Samantha Morton Mar. Las entradas van desde los $57 mil. Schwarzenegger en “Her” encabeza filme de zombies La actriz norteamericana Scarlett Johansson El actor austriaco protagonizará la cinta “Maggie”, tomó el rol de Samantha Morton en la nueva de Henry Hobson. Se trata de una producción cinta de Spike Jonze “Her”. Pese a que la pro- postapocalíptica, donde interpretará a un padre “Transformers 4” ducción estaba casi terminada y Morton había que debe proteger a su hija que se convierte en filmado sus escenas, el director señaló que “el zombie. no destruirá Beijing personaje no encajaba y necesitaba a alguien Tras los rumores que circularon en redes diferente”, por lo tanto, asignó el rol a la pro- Helena Bonham Carter, sociales, que indicaban una destrucción de tagonista de “Match point”. “Her” es una de hada madrina diversos íconos de la capital China en la película de ciencia ficción que cuenta, además, cuarta entrega de “Transformers”, los pro- con Joaquin Phoenix, Rooney Mara y Amy La nueva versión de “Cenicienta”, dirigida por ductores de la cinta debieron aclarar que el Adams en el reparto. Kenneth Branagh, confirmó a Helena Bonham rodaje en Beijing no incluye escenas que Carter en el rol de hada madrina. La cinta comienza dañen el patrimonio de la ciudad. -
The Ogham-Runes and El-Mushajjar
c L ite atu e Vo l x a t n t r n o . o R So . u P R e i t ed m he T a s . 1 1 87 " p r f ro y f r r , , r , THE OGHAM - RUNES AND EL - MUSHAJJAR A D STU Y . BY RICH A R D B URTO N F . , e ad J an uar 22 (R y , PART I . The O ham-Run es g . e n u IN tr ating this first portio of my s bj ect, the - I of i Ogham Runes , have made free use the mater als r John collected by Dr . Cha les Graves , Prof. Rhys , and other students, ending it with my own work in the Orkney Islands . i The Ogham character, the fair wr ting of ' Babel - loth ancient Irish literature , is called the , ’ Bethluis Bethlm snion e or , from its initial lett rs, like “ ” Gree co- oe Al hab e t a an d the Ph nician p , the Arabo “ ” Ab ad fl d H ebrew j . It may brie y be describe as f b ormed y straight or curved strokes , of various lengths , disposed either perpendicularly or obliquely to an angle of the substa nce upon which the letters n . were i cised , punched, or rubbed In monuments supposed to be more modern , the letters were traced , b T - N E E - A HE OGHAM RU S AND L M USH JJ A R . n not on the edge , but upon the face of the recipie t f n l o t sur ace ; the latter was origi al y wo d , s aves and tablets ; then stone, rude or worked ; and , lastly, metal , Th . -

International Standard Iso/Iec 10646
This is a preview - click here to buy the full publication INTERNATIONAL ISO/IEC STANDARD 10646 Sixth edition 2020-12 Information technology — Universal coded character set (UCS) Technologies de l'information — Jeu universel de caractères codés (JUC) Reference number ISO/IEC 10646:2020(E) © ISO/IEC 2020 This is a preview - click here to buy the full publication ISO/IEC 10646:2020 (E) CONTENTS 1 Scope ..................................................................................................................................................1 2 Normative references .........................................................................................................................1 3 Terms and definitions .........................................................................................................................2 4 Conformance ......................................................................................................................................8 4.1 General ....................................................................................................................................8 4.2 Conformance of information interchange .................................................................................8 4.3 Conformance of devices............................................................................................................8 5 Electronic data attachments ...............................................................................................................9 6 General structure -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

M. Ricklefs an Inventory of the Javanese Manuscript Collection in the British Museum
M. Ricklefs An inventory of the Javanese manuscript collection in the British Museum In: Bijdragen tot de Taal-, Land- en Volkenkunde 125 (1969), no: 2, Leiden, 241-262 This PDF-file was downloaded from http://www.kitlv-journals.nl Downloaded from Brill.com09/29/2021 11:29:04AM via free access AN INVENTORY OF THE JAVANESE MANUSCRIPT COLLECTION IN THE BRITISH MUSEUM* he collection of Javanese manuscripts in the British Museum, London, although small by comparison with collections in THolland and Indonesia, is nevertheless of considerable importance. The Crawfurd collection, forming the bulk of the manuscripts, provides a picture of the types of literature being written in Central Java in the late eighteenth and early nineteenth centuries, a period which Dr. Pigeaud has described as a Literary Renaissance.1 Because they were acquired by John Crawfurd during his residence as an official of the British administration on Java, 1811-1815, these manuscripts have a convenient terminus ad quem with regard to composition. A large number of the items are dated, a further convenience to the research worker, and the dates are seen to cluster in the four decades between AD 1775 and AD 1815. A number of the texts were originally obtained from Pakualam I, who was installed as an independent Prince by the British admini- stration. Some of the manuscripts are specifically said to have come from him (e.g. Add. 12281 and 12337), and a statement in a Leiden University Bah ad from the Pakualaman suggests many other volumes in Crawfurd's collection also derive from this source: Tuwan Mister [Crawfurd] asked to be instructed in adat law, with examples of the Javanese usage. -

Arabic Alphabet - Wikipedia, the Free Encyclopedia Arabic Alphabet from Wikipedia, the Free Encyclopedia
2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia Arabic alphabet From Wikipedia, the free encyclopedia َأﺑْ َﺠ ِﺪﯾﱠﺔ َﻋ َﺮﺑِﯿﱠﺔ :The Arabic alphabet (Arabic ’abjadiyyah ‘arabiyyah) or Arabic abjad is Arabic abjad the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[1] stand for consonants, it is classified as an abjad. Type Abjad Languages Arabic Time 400 to the present period Parent Proto-Sinaitic systems Phoenician Aramaic Syriac Nabataean Arabic abjad Child N'Ko alphabet systems ISO 15924 Arab, 160 Direction Right-to-left Unicode Arabic alias Unicode U+0600 to U+06FF range (http://www.unicode.org/charts/PDF/U0600.pdf) U+0750 to U+077F (http://www.unicode.org/charts/PDF/U0750.pdf) U+08A0 to U+08FF (http://www.unicode.org/charts/PDF/U08A0.pdf) U+FB50 to U+FDFF (http://www.unicode.org/charts/PDF/UFB50.pdf) U+FE70 to U+FEFF (http://www.unicode.org/charts/PDF/UFE70.pdf) U+1EE00 to U+1EEFF (http://www.unicode.org/charts/PDF/U1EE00.pdf) Note: This page may contain IPA phonetic symbols. Arabic alphabet ا ب ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع en.wikipedia.org/wiki/Arabic_alphabet 1/20 2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia غ ف ق ك ل م ن ه و ي History · Transliteration ء Diacritics · Hamza Numerals · Numeration V · T · E (//en.wikipedia.org/w/index.php?title=Template:Arabic_alphabet&action=edit) Contents 1 Consonants 1.1 Alphabetical order 1.2 Letter forms 1.2.1 Table of basic letters 1.2.2 Further notes -

Urdu Alphabet 1 Urdu Alphabet
Urdu alphabet 1 Urdu alphabet Urdu alphabet ﺍﺭﺩﻭ ﺗﮩﺠﯽ Example of writing in the Urdu alphabet: Urdu Type Abjad Languages Urdu, Balti, Burushaski, others Parent systems Proto-Sinaitic • Phoenician • Aramaic • Nabataean • Arabic • Perso-Arabic • Urdu alphabet ﺍﺭﺩﻭ ﺗﮩﺠﯽ [1] Unicode range U+0600 to U+06FF [2] U+0750 to U+077F [3] U+FB50 to U+FDFF [4] U+FE70 to U+FEFF Urdu alphabet ﮮ ﯼ ء ﮪ ﻩ ﻭ ﻥ ﻡ ﻝ ﮒ ﮎ ﻕ ﻑ ﻍ ﻉ ﻅ ﻁ ﺽ ﺹ ﺵ ﺱ ﮊ ﺯ ﮌ ﺭ ﺫ ﮈ ﺩ ﺥ ﺡ ﭺ ﺝ ﺙ ﭦ ﺕ ﭖ ﺏ ﺍ Extended Perso-Arabic script • History • Diacritics • Hamza • Numerals • Numeration The Urdu alphabet is the right-to-left alphabet used for the Urdu language. It is a modification of the Persian alphabet, which is itself a derivative of the Arabic alphabet. With 38 letters and no distinct letter cases, the Urdu alphabet is typically written in the calligraphic Nasta'liq script, whereas Arabic is more commonly in the Naskh style. Usually, bare transliterations of Urdu into Roman letters (called Roman Urdu) omit many phonemic elements that have no equivalent in English or other languages commonly written in the Latin script. The National Language Authority of Pakistan has developed a number of systems with specific notations to signify non-English sounds, but ﺥ ﻍ ﻁ these can only be properly read by someone already familiar with Urdu, Persian, or Arabic for letters such as Urdu alphabet 2 [citation needed].ﮌ and Hindi for letters such as ﻕ or ﺹ ﺡ ﻉ ﻅ ﺽ History The Urdu language emerged as a distinct register of Hindustani well before the Partition of India, and it is distinguished most by its extensive Persian influences (Persian having been the official language of the Mughal government and the most prominent lingua franca of the Indian subcontinent for several centuries prior to the solidification of British colonial rule during the 19th century). -
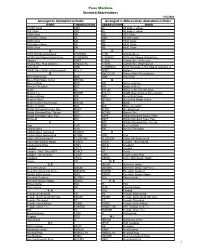
Arranged in Abbreviation Alphabetical Order Arranged in Alphabetical Order Penn Machine Standard Abbreviations
Penn Machine Standard Abbreviations 1/25/2008 Arranged in Alphabetical Order Arranged in Abbreviation Alphabetical Order WORD ABBREVIATION ABBREVIATION WORD 10,000 Class 10M 45 45 degree elbow 150 Class 150 90 90 degree elbow 3000 Class 3M 150 150 Class 45 degree elbow 45 10M 10,000 Class 6000 Class 6M 3M 3000 Class 90 degree elbow 90 6M 6000 Class 9000 Class 9M 9M 9000 Class A A A105 Hot Dip Galvanized A105HDG A105 Carbon Steel A105N Hot Dipped Galvanized A105NHDG A105HDG A105 Hot Dipped Galvanized Adapter ADPT A105A Carbon Steel Annealed Amoco Pipe Plug w/groove AMOCO PL A105N Carbon Steel Normalized Annealed ANN A105NHDG A105 Normalized Hot Dipped Galvanized ASME Spec Defines Dimensions* B16.11 ADPT Adapter B AMOCO PL Amoco Pipe Plug w/groove Bevel Both Ends BBE ANN Annealed Bevel End Nipple Outlet BE NOL B Bevel x Plain BXP B/B Brass to Brass Bevel x Threaded BXT B/S Brass to Steel Blank BL B/S UN Brass to Steel Seat Union Branch Tee BRTEE B16.11 ASME Spec Defines Dimensions* Brass to Brass B/B BBE Bevel Both Ends Brass to Steel B/S BE NOL Bevel End Nipple Outlet Brass to Steel Seat Union B/S UN BL Blank Braze-on Outlet BOL BOL Braze-on Outlet British Standard Parallel Pipe BSPP BOSS Welding Boss British Standard Pipe Thread BST BRTEE Branch Tee British Standard Taper Pipe BSPT BSPP British Standard Parallel Pipe Buttweld BW BSPT British Standard Taper Pipe C BST British Standard Pipe Thread Cap CAP BXP Bevel x Plain Carbon Steel A105 BXT Bevel x Threaded Carbon Steel Annealed A105HT C Carbon Steel Normalized A105N CAP Cap Class 200 -

IQAS International Education Guide
International Education Guide FOR THE ASSESSMENT OF EDUCATION FROM THE FORMER USSR AND THE RUSSIAN FEDERATION Welcome to the Alberta Government’s International Education Guides The International Qualifications Assessment Service (IQAS) developed the International Education Guides for educational institutions, employers and professional licensing bodies to help facilitate and streamline their decisions regarding the recognition of international credentials. These guides compare educational systems from around the world to educational standards in Canada. The assessment recommendations contained in the guides are based on extensive research and well documented standards and criteria. This research project, a first in Canada, is based on a broad range of international resources and considerable expertise within the IQAS program. Organizations can use these guides to make accurate and efficient decisions regarding the recognition of international credentials. The International Education Guides serve as a resource comparing Alberta standards with those of other countries, and will assist all those who need to make informed decisions, including: • employers who need to know whether an applicant with international credentials meets the educational requirements for a job, and how to obtain information comparing the applicant’s credentials to educational standards in Alberta and Canada • educational institutions that need to make a decision about whether a prospective student meets the education requirements for admission, and who need to find accurate and reliable information about the educational system of another country • professional licensing bodies that need to know whether an applicant meets the educational standards for licensing bodies The guides include a country overview, a historical educational overview, and descriptions of school education, higher education, professional/technical/vocational education, teacher education, grading scales, documentation for educational credentials and a bibliography.