14.30 Introduction to Statistical Methods in Economics Spring 2009
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Lecture 22: Bivariate Normal Distribution Distribution
6.5 Conditional Distributions General Bivariate Normal Let Z1; Z2 ∼ N (0; 1), which we will use to build a general bivariate normal Lecture 22: Bivariate Normal Distribution distribution. 1 1 2 2 f (z1; z2) = exp − (z1 + z2 ) Statistics 104 2π 2 We want to transform these unit normal distributions to have the follow Colin Rundel arbitrary parameters: µX ; µY ; σX ; σY ; ρ April 11, 2012 X = σX Z1 + µX p 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 1 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - Marginals General Bivariate Normal - Cov/Corr First, lets examine the marginal distributions of X and Y , Second, we can find Cov(X ; Y ) and ρ(X ; Y ) Cov(X ; Y ) = E [(X − E(X ))(Y − E(Y ))] X = σX Z1 + µX h p i = E (σ Z + µ − µ )(σ [ρZ + 1 − ρ2Z ] + µ − µ ) = σX N (0; 1) + µX X 1 X X Y 1 2 Y Y 2 h p 2 i = N (µX ; σX ) = E (σX Z1)(σY [ρZ1 + 1 − ρ Z2]) h 2 p 2 i = σX σY E ρZ1 + 1 − ρ Z1Z2 p 2 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY = σX σY ρE[Z1 ] p 2 = σX σY ρ = σY [ρN (0; 1) + 1 − ρ N (0; 1)] + µY = σ [N (0; ρ2) + N (0; 1 − ρ2)] + µ Y Y Cov(X ; Y ) ρ(X ; Y ) = = ρ = σY N (0; 1) + µY σX σY 2 = N (µY ; σY ) Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 2 / 22 Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 3 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - RNG Multivariate Change of Variables Consequently, if we want to generate a Bivariate Normal random variable Let X1;:::; Xn have a continuous joint distribution with pdf f defined of S. -

Laws of Total Expectation and Total Variance
Laws of Total Expectation and Total Variance Definition of conditional density. Assume and arbitrary random variable X with density fX . Take an event A with P (A) > 0. Then the conditional density fXjA is defined as follows: 8 < f(x) 2 P (A) x A fXjA(x) = : 0 x2 = A Note that the support of fXjA is supported only in A. Definition of conditional expectation conditioned on an event. Z Z 1 E(h(X)jA) = h(x) fXjA(x) dx = h(x) fX (x) dx A P (A) A Example. For the random variable X with density function 8 < 1 3 64 x 0 < x < 4 f(x) = : 0 otherwise calculate E(X2 j X ≥ 1). Solution. Step 1. Z h i 4 1 1 1 x=4 255 P (X ≥ 1) = x3 dx = x4 = 1 64 256 4 x=1 256 Step 2. Z Z ( ) 1 256 4 1 E(X2 j X ≥ 1) = x2 f(x) dx = x2 x3 dx P (X ≥ 1) fx≥1g 255 1 64 Z ( ) ( )( ) h i 256 4 1 256 1 1 x=4 8192 = x5 dx = x6 = 255 1 64 255 64 6 x=1 765 Definition of conditional variance conditioned on an event. Var(XjA) = E(X2jA) − E(XjA)2 1 Example. For the previous example , calculate the conditional variance Var(XjX ≥ 1) Solution. We already calculated E(X2 j X ≥ 1). We only need to calculate E(X j X ≥ 1). Z Z Z ( ) 1 256 4 1 E(X j X ≥ 1) = x f(x) dx = x x3 dx P (X ≥ 1) fx≥1g 255 1 64 Z ( ) ( )( ) h i 256 4 1 256 1 1 x=4 4096 = x4 dx = x5 = 255 1 64 255 64 5 x=1 1275 Finally: ( ) 8192 4096 2 630784 Var(XjX ≥ 1) = E(X2jX ≥ 1) − E(XjX ≥ 1)2 = − = 765 1275 1625625 Definition of conditional expectation conditioned on a random variable. -

Probability Cheatsheet V2.0 Thinking Conditionally Law of Total Probability (LOTP)
Probability Cheatsheet v2.0 Thinking Conditionally Law of Total Probability (LOTP) Let B1;B2;B3; :::Bn be a partition of the sample space (i.e., they are Compiled by William Chen (http://wzchen.com) and Joe Blitzstein, Independence disjoint and their union is the entire sample space). with contributions from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Independent Events A and B are independent if knowing whether P (A) = P (AjB )P (B ) + P (AjB )P (B ) + ··· + P (AjB )P (B ) Jessy Hwang. Material based on Joe Blitzstein's (@stat110) lectures 1 1 2 2 n n A occurred gives no information about whether B occurred. More (http://stat110.net) and Blitzstein/Hwang's Introduction to P (A) = P (A \ B1) + P (A \ B2) + ··· + P (A \ Bn) formally, A and B (which have nonzero probability) are independent if Probability textbook (http://bit.ly/introprobability). Licensed and only if one of the following equivalent statements holds: For LOTP with extra conditioning, just add in another event C! under CC BY-NC-SA 4.0. Please share comments, suggestions, and errors at http://github.com/wzchen/probability_cheatsheet. P (A \ B) = P (A)P (B) P (AjC) = P (AjB1;C)P (B1jC) + ··· + P (AjBn;C)P (BnjC) P (AjB) = P (A) P (AjC) = P (A \ B1jC) + P (A \ B2jC) + ··· + P (A \ BnjC) P (BjA) = P (B) Last Updated September 4, 2015 Special case of LOTP with B and Bc as partition: Conditional Independence A and B are conditionally independent P (A) = P (AjB)P (B) + P (AjBc)P (Bc) given C if P (A \ BjC) = P (AjC)P (BjC). -

Probability Cheatsheet
Probability Cheatsheet v1.1.1 Simpson's Paradox Expected Value, Linearity, and Symmetry P (A j B; C) < P (A j Bc;C) and P (A j B; Cc) < P (A j Bc;Cc) Expected Value (aka mean, expectation, or average) can be thought Compiled by William Chen (http://wzchen.com) with contributions yet still, P (A j B) > P (A j Bc) of as the \weighted average" of the possible outcomes of our random from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Jessy Hwang. variable. Mathematically, if x1; x2; x3;::: are all of the possible values Material based off of Joe Blitzstein's (@stat110) lectures Bayes' Rule and Law of Total Probability that X can take, the expected value of X can be calculated as follows: P (http://stat110.net) and Blitzstein/Hwang's Intro to Probability E(X) = xiP (X = xi) textbook (http://bit.ly/introprobability). Licensed under CC i Law of Total Probability with partitioning set B1; B2; B3; :::Bn and BY-NC-SA 4.0. Please share comments, suggestions, and errors at with extra conditioning (just add C!) Note that for any X and Y , a and b scaling coefficients and c is our http://github.com/wzchen/probability_cheatsheet. constant, the following property of Linearity of Expectation holds: P (A) = P (AjB1)P (B1) + P (AjB2)P (B2) + :::P (AjBn)P (Bn) Last Updated March 20, 2015 P (A) = P (A \ B1) + P (A \ B2) + :::P (A \ Bn) E(aX + bY + c) = aE(X) + bE(Y ) + c P (AjC) = P (AjB1; C)P (B1jC) + :::P (AjBn; C)P (BnjC) If two Random Variables have the same distribution, even when they are dependent by the property of Symmetry their expected values P (AjC) = P (A \ B jC) + P (A \ B jC) + :::P (A \ B jC) Counting 1 2 n are equal. -
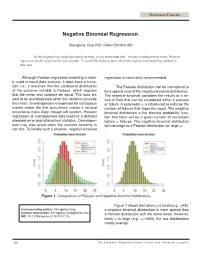
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Section 1: Regression Review
Section 1: Regression review Yotam Shem-Tov Fall 2015 Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 1 / 58 Contact information Yotam Shem-Tov, PhD student in economics. E-mail: [email protected]. Office: Evans hall room 650 Office hours: To be announced - any preferences or constraints? Feel free to e-mail me. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 2 / 58 R resources - Prior knowledge in R is assumed In the link here is an excellent introduction to statistics in R . There is a free online course in coursera on programming in R. Here is a link to the course. An excellent book for implementing econometric models and method in R is Applied Econometrics with R. This is my favourite for starting to learn R for someone who has some background in statistic methods in the social science. The book Regression Models for Data Science in R has a nice online version. It covers the implementation of regression models using R . A great link to R resources and other cool programming and econometric tools is here. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 3 / 58 Outline There are two general approaches to regression 1 Regression as a model: a data generating process (DGP) 2 Regression as an algorithm (i.e., an estimator without assuming an underlying structural model). Overview of this slides: 1 The conditional expectation function - a motivation for using OLS. 2 OLS as the minimum mean squared error linear approximation (projections). 3 Regression as a structural model (i.e., assuming the conditional expectation is linear). -

(Introduction to Probability at an Advanced Level) - All Lecture Notes
Fall 2018 Statistics 201A (Introduction to Probability at an advanced level) - All Lecture Notes Aditya Guntuboyina August 15, 2020 Contents 0.1 Sample spaces, Events, Probability.................................5 0.2 Conditional Probability and Independence.............................6 0.3 Random Variables..........................................7 1 Random Variables, Expectation and Variance8 1.1 Expectations of Random Variables.................................9 1.2 Variance................................................ 10 2 Independence of Random Variables 11 3 Common Distributions 11 3.1 Ber(p) Distribution......................................... 11 3.2 Bin(n; p) Distribution........................................ 11 3.3 Poisson Distribution......................................... 12 4 Covariance, Correlation and Regression 14 5 Correlation and Regression 16 6 Back to Common Distributions 16 6.1 Geometric Distribution........................................ 16 6.2 Negative Binomial Distribution................................... 17 7 Continuous Distributions 17 7.1 Normal or Gaussian Distribution.................................. 17 1 7.2 Uniform Distribution......................................... 18 7.3 The Exponential Density...................................... 18 7.4 The Gamma Density......................................... 18 8 Variable Transformations 19 9 Distribution Functions and the Quantile Transform 20 10 Joint Densities 22 11 Joint Densities under Transformations 23 11.1 Detour to Convolutions...................................... -

Large Scale Conditional Covariance Matrix Modeling, Estimation and Testing
Large Scale Conditional Covariance Matrix Modeling, Estimation and Testing Zhuanxin Ding1 Frank Russell Company, Tacoma, WA 98401, USA and Robert F. Engle University of California, San Diego, La Jolla, CA 92093, USA June 1996 This Revision May 2001 Abstract A new representation of the diagonal Vech model is given using the Hadamard product. Sufficient conditions on parameter matrices are provided to ensure the positive definiteness of covariance matrices from the new representation. Based on this, some new and simple models are discussed. A set of diagnostic tests for multivariate ARCH models is proposed. The tests are able to detect various model misspecifications by examing the orthogonality of the squared normalized residuals. A small Monte-Carlo study is carried out to check the small sample performance of the test. An empirical example is also given as guidance for model estimation and selection in the multivariate framework. For the specific data set considered, it is found that the simple one and two parameter models and the constant conditional correlation model perform fairly well. Keywords: conditional covariance, Multivariate ARCH, Hadamard product, M-test. 1 We would like to thank Clive Granger, Hong-Ye Gao, Doug Martin, Jeffrey Wang and Hal White for many helpful discussions. 2 1. Introduction It has now become common knowledge that the risk of the financial market, which is mainly represented by the variance of individual stock returns and the covariance between different assets or with the market, is highly forecastable. The research in this area however is far from complete and the application of different econometric models is just at its beginning. -

On the Method of Moments for Estimation in Latent Variable Models Anastasia Podosinnikova
On the Method of Moments for Estimation in Latent Variable Models Anastasia Podosinnikova To cite this version: Anastasia Podosinnikova. On the Method of Moments for Estimation in Latent Variable Models. Machine Learning [cs.LG]. Ecole Normale Superieure de Paris - ENS Paris, 2016. English. tel- 01489260v1 HAL Id: tel-01489260 https://tel.archives-ouvertes.fr/tel-01489260v1 Submitted on 14 Mar 2017 (v1), last revised 5 Apr 2018 (v2) HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. THÈSE DE DOCTORAT de l’Université de recherche Paris Sciences Lettres – PSL Research University préparée à l’École normale supérieure Sur la méthode des mo- École doctorale n°386 ments pour d’estimation Spécialité: Informatique des modèles à variable latentes Soutenue le 01.12.2016 On the method of moments for es- timation in latent variable models par Anastasia Podosinnikova Composition du Jury : Mme Animashree ANANDKUMAR University of California Irvine Rapporteur M Samuel KASKI Aalto University Rapporteur M Francis BACH École normale supérieure Directeur de thèse M Simon LACOSTE-JULIEN École normale supérieure Directeur de thèse M Alexandre D’ASPREMONT École normale supérieure Membre du Jury M Pierre COMON CNRS Membre du Jury M Rémi GRIBONVAL INRIA Membre du Jury Abstract Latent variable models are powerful probabilistic tools for extracting useful latent structure from otherwise unstructured data and have proved useful in numerous ap- plications such as natural language processing and computer vision. -

On the Autoregressive Conditional Heteroskedasticity Models
On the Autoregressive Conditional Heteroskedasticity Models By Erik Stenberg Department of Statistics Uppsala University Bachelor’s Thesis Supervisor: Yukai Yang 2016 Abstract This thesis aims to provide a thorough discussion on the early ARCH- type models, including a brief background with volatility clustering, kur- tosis, skewness of financial time series. In-sample fit of the widely used GARCH(1,1) is discussed using both standard model evaluation criteria and simulated values from estimated models. A rolling scheme out-of sam- ple forecast is evaluated using several different loss-functions and R2 from the Mincer-Zarnowitz regression, with daily realized volatility constructed using five minute intra-daily squared returns to proxy the true volatility. Keywords: ARCH, GARCH, Volatility clustering, fat tail, forecasting, intra-daily returns Contents 1 Introduction 3 2 Volatility 3 3 Autoregressive Conditional Heteroskedasticity 7 3.1 ARCH(1) . 8 3.2 Implied Kurtosis of ARCH(1) . 8 4 Generalized Autoregressive Conditional Heteroskedasticity 9 4.1 GARCH(1,1) . 9 5 Other Distributional Assumptions 11 5.1 Student-t . 11 5.2 Skewed Student-t . 12 5.3 Skewed Generalized Error Distribution . 12 6 Diagnostics 13 6.1 In-Sample Fit Evaluation . 13 6.2 Forecast Evaluation . 13 6.2.1 Value-at-Risk . 17 7 Illustrations 17 7.1 In-Sample Fit . 17 7.2 Forecast . 19 8 Summary, Conclusions and Further Research 21 9 Appendix 24 1 Introduction Ever since the first of many Autoregressive Conditional Heteroskedastic (ARCH) models was presented, see Engle (1982), fitting models to describe conditional heteroskedasticity has been a widely discussed topic. The main reason for this is the fact that up to that point, many of the conventional time series and models used in finance assumed a constant standard deviation in asset returns, see Black and Scholes (1973). -

Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation Author(S): Robert F
Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation Author(s): Robert F. Engle Source: Econometrica, Vol. 50, No. 4 (Jul., 1982), pp. 987-1007 Published by: The Econometric Society Stable URL: http://www.jstor.org/stable/1912773 Accessed: 06-11-2017 22:41 UTC REFERENCES Linked references are available on JSTOR for this article: http://www.jstor.org/stable/1912773?seq=1&cid=pdf-reference#references_tab_contents You may need to log in to JSTOR to access the linked references. JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at http://about.jstor.org/terms The Econometric Society is collaborating with JSTOR to digitize, preserve and extend access to Econometrica This content downloaded from 176.21.124.211 on Mon, 06 Nov 2017 22:41:38 UTC All use subject to http://about.jstor.org/terms Econometrica, Vol. 50, No. 4 (July, 1982) AUTOREGRESSIVE CONDITIONAL HETEROSCEDASTICITY WITH ESTIMATES OF THE VARIANCE OF UNITED KINGDOM INFLATION1 BY ROBERT F. ENGLE Traditional econometric models assume a constant one-period forecast variance. To generalize this implausible assumption, a new class of stochastic processes called autore- gressive conditional heteroscedastic (ARCH) processes are introduced in this paper. These are mean zero, serially uncorrelated processes with nonconstant variances conditional on the past, but constant unconditional variances. -

Lecture 21: Conditional Distributions and Covariance / Correlation
6.3, 6.4 Conditional Distributions Conditional Probability / Distributions Let X and Y be random variables then Lecture 21: Conditional Distributions and Covariance / Conditional probability: Correlation P(X = x; Y = y) P(X = xjY = y) = P(Y = y) Statistics 104 f (x; y) f (xjy) = Colin Rundel fY (y) Product rule: April 9, 2012 P(X = x; Y = y) = P(X = xjY = y)P(Y = y) f (x; y) = f (xjy)fY (y) Statistics 104 (Colin Rundel) Lecture 21 April 9, 2012 1 / 23 6.3, 6.4 Conditional Distributions 6.3, 6.4 Conditional Distributions Bayes' Theorem and the Law of Total Probability Example - Conditional Uniforms Let X and Y be random variables then Let X ∼ Unif(0; 1) and Y jX ∼ Unif(x; 1), find f (x; y), fY (y), and f (xjy). Bayes' Theorem: f (x; y) f (yjx)f (x) f (xjy) = = X fY (y) fY (y) f (x; y) f (xjy)f (y) f (yjx) = = Y fX (x) fX (x) Law of Total Probability: Z 1 Z 1 fX (x) = f (x; y) dy = f (xjy)fY (y) dy −∞ −∞ Z 1 Z 1 fY (y) = f (x; y) dx = f (yjx)fX (x) dx −∞ −∞ Statistics 104 (Colin Rundel) Lecture 21 April 9, 2012 2 / 23 Statistics 104 (Colin Rundel) Lecture 21 April 9, 2012 3 / 23 6.3, 6.4 Conditional Distributions 6.3, 6.4 Conditional Expectation Independence and Conditional Distributions Conditional Expectation If X and Y are independent random variables then If X and Y are independent random variables then we define the conditional expectation as follows f (xjy) = f (x) 4.7 Conditional Expectation X 257 X The value of E(Y x) will not be uniquely defined for those values of x such that E(X jY = y) = xf (xjy) dx f (they marginaljx) = p.f.fY or( p.d.f.y| ) of X satisfies f (x) 0.