Heteroskedasticity in the Linear Model 2 Fall 2020 Unversit¨Atbasel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 22: Bivariate Normal Distribution Distribution
6.5 Conditional Distributions General Bivariate Normal Let Z1; Z2 ∼ N (0; 1), which we will use to build a general bivariate normal Lecture 22: Bivariate Normal Distribution distribution. 1 1 2 2 f (z1; z2) = exp − (z1 + z2 ) Statistics 104 2π 2 We want to transform these unit normal distributions to have the follow Colin Rundel arbitrary parameters: µX ; µY ; σX ; σY ; ρ April 11, 2012 X = σX Z1 + µX p 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 1 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - Marginals General Bivariate Normal - Cov/Corr First, lets examine the marginal distributions of X and Y , Second, we can find Cov(X ; Y ) and ρ(X ; Y ) Cov(X ; Y ) = E [(X − E(X ))(Y − E(Y ))] X = σX Z1 + µX h p i = E (σ Z + µ − µ )(σ [ρZ + 1 − ρ2Z ] + µ − µ ) = σX N (0; 1) + µX X 1 X X Y 1 2 Y Y 2 h p 2 i = N (µX ; σX ) = E (σX Z1)(σY [ρZ1 + 1 − ρ Z2]) h 2 p 2 i = σX σY E ρZ1 + 1 − ρ Z1Z2 p 2 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY = σX σY ρE[Z1 ] p 2 = σX σY ρ = σY [ρN (0; 1) + 1 − ρ N (0; 1)] + µY = σ [N (0; ρ2) + N (0; 1 − ρ2)] + µ Y Y Cov(X ; Y ) ρ(X ; Y ) = = ρ = σY N (0; 1) + µY σX σY 2 = N (µY ; σY ) Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 2 / 22 Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 3 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - RNG Multivariate Change of Variables Consequently, if we want to generate a Bivariate Normal random variable Let X1;:::; Xn have a continuous joint distribution with pdf f defined of S. -

Generalized Linear Models and Generalized Additive Models
00:34 Friday 27th February, 2015 Copyright ©Cosma Rohilla Shalizi; do not distribute without permission updates at http://www.stat.cmu.edu/~cshalizi/ADAfaEPoV/ Chapter 13 Generalized Linear Models and Generalized Additive Models [[TODO: Merge GLM/GAM and Logistic Regression chap- 13.1 Generalized Linear Models and Iterative Least Squares ters]] [[ATTN: Keep as separate Logistic regression is a particular instance of a broader kind of model, called a gener- chapter, or merge with logis- alized linear model (GLM). You are familiar, of course, from your regression class tic?]] with the idea of transforming the response variable, what we’ve been calling Y , and then predicting the transformed variable from X . This was not what we did in logis- tic regression. Rather, we transformed the conditional expected value, and made that a linear function of X . This seems odd, because it is odd, but it turns out to be useful. Let’s be specific. Our usual focus in regression modeling has been the condi- tional expectation function, r (x)=E[Y X = x]. In plain linear regression, we try | to approximate r (x) by β0 + x β. In logistic regression, r (x)=E[Y X = x] = · | Pr(Y = 1 X = x), and it is a transformation of r (x) which is linear. The usual nota- tion says | ⌘(x)=β0 + x β (13.1) · r (x) ⌘(x)=log (13.2) 1 r (x) − = g(r (x)) (13.3) defining the logistic link function by g(m)=log m/(1 m). The function ⌘(x) is called the linear predictor. − Now, the first impulse for estimating this model would be to apply the transfor- mation g to the response. -

Ordinary Least Squares 1 Ordinary Least Squares
Ordinary least squares 1 Ordinary least squares In statistics, ordinary least squares (OLS) or linear least squares is a method for estimating the unknown parameters in a linear regression model. This method minimizes the sum of squared vertical distances between the observed responses in the dataset and the responses predicted by the linear approximation. The resulting estimator can be expressed by a simple formula, especially in the case of a single regressor on the right-hand side. The OLS estimator is consistent when the regressors are exogenous and there is no Okun's law in macroeconomics states that in an economy the GDP growth should multicollinearity, and optimal in the class of depend linearly on the changes in the unemployment rate. Here the ordinary least squares method is used to construct the regression line describing this law. linear unbiased estimators when the errors are homoscedastic and serially uncorrelated. Under these conditions, the method of OLS provides minimum-variance mean-unbiased estimation when the errors have finite variances. Under the additional assumption that the errors be normally distributed, OLS is the maximum likelihood estimator. OLS is used in economics (econometrics) and electrical engineering (control theory and signal processing), among many areas of application. Linear model Suppose the data consists of n observations { y , x } . Each observation includes a scalar response y and a i i i vector of predictors (or regressors) x . In a linear regression model the response variable is a linear function of the i regressors: where β is a p×1 vector of unknown parameters; ε 's are unobserved scalar random variables (errors) which account i for the discrepancy between the actually observed responses y and the "predicted outcomes" x′ β; and ′ denotes i i matrix transpose, so that x′ β is the dot product between the vectors x and β. -

Generalized and Weighted Least Squares Estimation
LINEAR REGRESSION ANALYSIS MODULE – VII Lecture – 25 Generalized and Weighted Least Squares Estimation Dr. Shalabh Department of Mathematics and Statistics Indian Institute of Technology Kanpur 2 The usual linear regression model assumes that all the random error components are identically and independently distributed with constant variance. When this assumption is violated, then ordinary least squares estimator of regression coefficient looses its property of minimum variance in the class of linear and unbiased estimators. The violation of such assumption can arise in anyone of the following situations: 1. The variance of random error components is not constant. 2. The random error components are not independent. 3. The random error components do not have constant variance as well as they are not independent. In such cases, the covariance matrix of random error components does not remain in the form of an identity matrix but can be considered as any positive definite matrix. Under such assumption, the OLSE does not remain efficient as in the case of identity covariance matrix. The generalized or weighted least squares method is used in such situations to estimate the parameters of the model. In this method, the deviation between the observed and expected values of yi is multiplied by a weight ω i where ω i is chosen to be inversely proportional to the variance of yi. n 2 For simple linear regression model, the weighted least squares function is S(,)ββ01=∑ ωii( yx −− β0 β 1i) . ββ The least squares normal equations are obtained by differentiating S (,) ββ 01 with respect to 01 and and equating them to zero as nn n ˆˆ β01∑∑∑ ωβi+= ωiixy ω ii ii=11= i= 1 n nn ˆˆ2 βω01∑iix+= βω ∑∑ii x ω iii xy. -

18.650 (F16) Lecture 10: Generalized Linear Models (Glms)
Statistics for Applications Chapter 10: Generalized Linear Models (GLMs) 1/52 Linear model A linear model assumes Y X (µ(X), σ2I), | ∼ N And ⊤ IE(Y X) = µ(X) = X β, | 2/52 Components of a linear model The two components (that we are going to relax) are 1. Random component: the response variable Y X is continuous | and normally distributed with mean µ = µ(X) = IE(Y X). | 2. Link: between the random and covariates X = (X(1),X(2), ,X(p))⊤: µ(X) = X⊤β. · · · 3/52 Generalization A generalized linear model (GLM) generalizes normal linear regression models in the following directions. 1. Random component: Y some exponential family distribution ∼ 2. Link: between the random and covariates: ⊤ g µ(X) = X β where g called link function� and� µ = IE(Y X). | 4/52 Example 1: Disease Occuring Rate In the early stages of a disease epidemic, the rate at which new cases occur can often increase exponentially through time. Hence, if µi is the expected number of new cases on day ti, a model of the form µi = γ exp(δti) seems appropriate. ◮ Such a model can be turned into GLM form, by using a log link so that log(µi) = log(γ) + δti = β0 + β1ti. ◮ Since this is a count, the Poisson distribution (with expected value µi) is probably a reasonable distribution to try. 5/52 Example 2: Prey Capture Rate(1) The rate of capture of preys, yi, by a hunting animal, tends to increase with increasing density of prey, xi, but to eventually level off, when the predator is catching as much as it can cope with. -

Ordinary Least Squares: the Univariate Case
Introduction The OLS method The linear causal model A simulation & applications Conclusion and exercises Ordinary Least Squares: the univariate case Clément de Chaisemartin Majeure Economie September 2011 Clément de Chaisemartin Ordinary Least Squares Introduction The OLS method The linear causal model A simulation & applications Conclusion and exercises 1 Introduction 2 The OLS method Objective and principles of OLS Deriving the OLS estimates Do OLS keep their promises ? 3 The linear causal model Assumptions Identification and estimation Limits 4 A simulation & applications OLS do not always yield good estimates... But things can be improved... Empirical applications 5 Conclusion and exercises Clément de Chaisemartin Ordinary Least Squares Introduction The OLS method The linear causal model A simulation & applications Conclusion and exercises Objectives Objective 1 : to make the best possible guess on a variable Y based on X . Find a function of X which yields good predictions for Y . Given cigarette prices, what will be cigarettes sales in September 2010 in France ? Objective 2 : to determine the causal mechanism by which X influences Y . Cetebus paribus type of analysis. Everything else being equal, how a change in X affects Y ? By how much one more year of education increases an individual’s wage ? By how much the hiring of 1 000 more policemen would decrease the crime rate in Paris ? The tool we use = a data set, in which we have the wages and number of years of education of N individuals. Clément de Chaisemartin Ordinary Least Squares Introduction The OLS method The linear causal model A simulation & applications Conclusion and exercises Objective and principles of OLS What we have and what we want For each individual in our data set we observe his wage and his number of years of education. -

Chapter 2: Ordinary Least Squares Regression
Chapter 2: Ordinary Least Squares In this chapter: 1. Running a simple regression for weight/height example (UE 2.1.4) 2. Contents of the EViews equation window 3. Creating a workfile for the demand for beef example (UE, Table 2.2, p. 45) 4. Importing data from a spreadsheet file named Beef 2.xls 5. Using EViews to estimate a multiple regression model of beef demand (UE 2.2.3) 6. Exercises Ordinary Least Squares (OLS) regression is the core of econometric analysis. While it is important to calculate estimated regression coefficients without the aid of a regression program one time in order to better understand how OLS works (see UE, Table 2.1, p.41), easy access to regression programs makes it unnecessary for everyday analysis.1 In this chapter, we will estimate simple and multivariate regression models in order to pinpoint where the regression statistics discussed throughout the text are found in the EViews program output. Begin by opening the EViews program and opening the workfile named htwt1.wf1 (this is the file of student height and weight that was created and saved in Chapter 1). Running a simple regression for weight/height example (UE 2.1.4): Regression estimation in EViews is performed using the equation object. To create an equation object in EViews, follow these steps: Step 1. Open the EViews workfile named htwt1.wf1 by selecting File/Open/Workfile on the main menu bar and click on the file name. Step 2. Select Objects/New Object/Equation from the workfile menu.2 Step 3. -
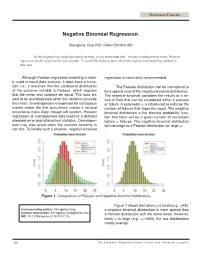
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Heteroscedastic Errors
Heteroscedastic Errors ◮ Sometimes plots and/or tests show that the error variances 2 σi = Var(ǫi ) depend on i ◮ Several standard approaches to fixing the problem, depending on the nature of the dependence. ◮ Weighted Least Squares. ◮ Transformation of the response. ◮ Generalized Linear Models. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Weighted Least Squares ◮ Suppose variances are known except for a constant factor. 2 2 ◮ That is, σi = σ /wi . ◮ Use weighted least squares. (See Chapter 10 in the text.) ◮ This usually arises realistically in the following situations: ◮ Yi is an average of ni measurements where you know ni . Then wi = ni . 2 ◮ Plots suggest that σi might be proportional to some power of 2 γ γ some covariate: σi = kxi . Then wi = xi− . Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Variances depending on (mean of) Y ◮ Two standard approaches are available: ◮ Older approach is transformation. ◮ Newer approach is use of generalized linear model; see STAT 402. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Transformation ◮ Compute Yi∗ = g(Yi ) for some function g like logarithm or square root. ◮ Then regress Yi∗ on the covariates. ◮ This approach sometimes works for skewed response variables like income; ◮ after transformation we occasionally find the errors are more nearly normal, more homoscedastic and that the model is simpler. ◮ See page 130ff and check under transformations and Box-Cox in the index. Richard Lockhart STAT 350: Heteroscedastic Errors and GLIM Generalized Linear Models ◮ Transformation uses the model T E(g(Yi )) = xi β while generalized linear models use T g(E(Yi )) = xi β ◮ Generally latter approach offers more flexibility. -

Section 1: Regression Review
Section 1: Regression review Yotam Shem-Tov Fall 2015 Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 1 / 58 Contact information Yotam Shem-Tov, PhD student in economics. E-mail: [email protected]. Office: Evans hall room 650 Office hours: To be announced - any preferences or constraints? Feel free to e-mail me. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 2 / 58 R resources - Prior knowledge in R is assumed In the link here is an excellent introduction to statistics in R . There is a free online course in coursera on programming in R. Here is a link to the course. An excellent book for implementing econometric models and method in R is Applied Econometrics with R. This is my favourite for starting to learn R for someone who has some background in statistic methods in the social science. The book Regression Models for Data Science in R has a nice online version. It covers the implementation of regression models using R . A great link to R resources and other cool programming and econometric tools is here. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 3 / 58 Outline There are two general approaches to regression 1 Regression as a model: a data generating process (DGP) 2 Regression as an algorithm (i.e., an estimator without assuming an underlying structural model). Overview of this slides: 1 The conditional expectation function - a motivation for using OLS. 2 OLS as the minimum mean squared error linear approximation (projections). 3 Regression as a structural model (i.e., assuming the conditional expectation is linear). -

4.3 Least Squares Approximations
218 Chapter 4. Orthogonality 4.3 Least Squares Approximations It often happens that Ax D b has no solution. The usual reason is: too many equations. The matrix has more rows than columns. There are more equations than unknowns (m is greater than n). The n columns span a small part of m-dimensional space. Unless all measurements are perfect, b is outside that column space. Elimination reaches an impossible equation and stops. But we can’t stop just because measurements include noise. To repeat: We cannot always get the error e D b Ax down to zero. When e is zero, x is an exact solution to Ax D b. When the length of e is as small as possible, bx is a least squares solution. Our goal in this section is to compute bx and use it. These are real problems and they need an answer. The previous section emphasized p (the projection). This section emphasizes bx (the least squares solution). They are connected by p D Abx. The fundamental equation is still ATAbx D ATb. Here is a short unofficial way to reach this equation: When Ax D b has no solution, multiply by AT and solve ATAbx D ATb: Example 1 A crucial application of least squares is fitting a straight line to m points. Start with three points: Find the closest line to the points .0; 6/; .1; 0/, and .2; 0/. No straight line b D C C Dt goes through those three points. We are asking for two numbers C and D that satisfy three equations. -

Power Comparisons of the Mann-Whitney U and Permutation Tests
Power Comparisons of the Mann-Whitney U and Permutation Tests Abstract: Though the Mann-Whitney U-test and permutation tests are often used in cases where distribution assumptions for the two-sample t-test for equal means are not met, it is not widely understood how the powers of the two tests compare. Our goal was to discover under what circumstances the Mann-Whitney test has greater power than the permutation test. The tests’ powers were compared under various conditions simulated from the Weibull distribution. Under most conditions, the permutation test provided greater power, especially with equal sample sizes and with unequal standard deviations. However, the Mann-Whitney test performed better with highly skewed data. Background and Significance: In many psychological, biological, and clinical trial settings, distributional differences among testing groups render parametric tests requiring normality, such as the z test and t test, unreliable. In these situations, nonparametric tests become necessary. Blair and Higgins (1980) illustrate the empirical invalidity of claims made in the mid-20th century that t and F tests used to detect differences in population means are highly insensitive to violations of distributional assumptions, and that non-parametric alternatives possess lower power. Through power testing, Blair and Higgins demonstrate that the Mann-Whitney test has much higher power relative to the t-test, particularly under small sample conditions. This seems to be true even when Welch’s approximation and pooled variances are used to “account” for violated t-test assumptions (Glass et al. 1972). With the proliferation of powerful computers, computationally intensive alternatives to the Mann-Whitney test have become possible.