Representing Myanmar in Unicode Details and Examples Version 3
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Roadmaps to ISO/IEC 10646 and the Unicode Standard
Roadmaps to ISO/IEC 10646 and the Unicode Standard • INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2 N2461 2002-05-14 Title: Snapshot of Pictorial view of Roadmaps to BMP, SMP, SIP and SSP Ad hoc group on Roadmaps ( Michael Everson, Rick McGowan, and Ken Whistler) Source: Adapted by: V.S. Umamaheswaran For review and adoption WG2 at its meeting M42 Status: (includes update as of May 14, 2002) Distribution: ISO/IEC JTC 1/SC 2/WG 2, ISO/IEC JTC 1/SC 2 and Liaison Organisations Replaces: WG2 document N2409 Summary This document is the latest snapshot of the roadmap documents that has been presented to and adopted by WG2 (ISO/IEC JTC1/SC2/WG 2). Four tables containing the roadmaps to ● the Basic Multilingual Plane (BMP - Plane 0) (version bmp-3-5, 2002-04-04) ● the Supplementary Multilingual Plane (SMP - Plane 1) (version smp-3-2, 2002-04-03) ● the Supplementary Ideographic Plane (SIP - Plane 2) (version sip-3-0, 2001-10-10), and ● the Supplementary Special-purpose Plane (SSP - Plane 14) (version ssp-3-1, 2002-01-22) are included in this document. The Roadmap ad hoc group maintains and updates this document as a service to the UTC (Unicode Technical Committee) and to WG2 (ISO/IEC JTC1/SC2/WG2). The latest working version of this document can be found at http://www.unicode.org/roadmaps. This document is informative. Please send corrigenda and other comments to the authors. -

Phonetics of Sgaw Karen in Thailand
PHONETICS OF SGAW KAREN IN THAILAND: AN ACOUSTIC DESCRIPTION PONGPRAPUNT RATTANAPORN MASTER OF ARTS IN ENGLISH THE GRADUATE SCHOOL CHIANG MAI UNIVERSITY SEPTEMBER 2012 PHONETICS OF SGAW KAREN IN THAILAND: AN ACOUSTIC DESCRIPTION PONGPRAPUNT RATTANAPORN AN INDEPENDENT STUDY SUBMITTED TO THE GRADUATE SCHOOL IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS IN ENGLISH THE GRADUATE SCHOOL CHIANG MAI UNIVERSITY SEPTEMBER 2012 PHONETICS OF SGAW KAREN IN THAILAND: AN ACOUSTIC DESCRIPTION PONGPRAPUNT RATTANAPORN THIS INDEPENDENT STUDY HAS BEEN APPROVED TO BE A PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS IN ENGLISH 26 September 2012 © Copyright by Chiang Mai University iii ACKNOWLEDGEMENT I would like to express my gratitude to everybody who contributed to this research. Firstly, my deepest thanks go to both of my supervisors, Dr. Preeya Nokaew (Chiang Mai University) and Dr. Paul Sidwell (Australian National University), for their excellent support from when I first started until I finished this research. Secondly, my thanks go to the examining committee, Dr. Peter Freeouf and Dr. Sudarat Hatfield, for their useful comments. Thirdly, I would like to express my thanks to Assoc. Prof. Suphanee Jancamai and Asst. Prof. Panit Boonyavatana and all the teachers in the graduate program. Also a special thanks to Dr. Phinnarat Akharawatthanakun (Payap University) for her valuable advice. This research would not have been successful without the assistance of the Dujeto’s, Mr. Thaworn Kamponkun and all the informants and my friends Ey, Sprite, Mike, Chris, Darwin, Oh, Jay, Rose and Yrrah. Last but not least, I appreciate everybody in my family for their love, encouragement and financial support. -

Encoding Diversity for All the World's Languages
Encoding Diversity for All the World’s Languages The Script Encoding Initiative (Universal Scripts Project) Michael Everson, Evertype Westport, Co. Mayo, Ireland Bamako, Mali • 6 May 2005 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters 1. Current State of the Unicode Standard: New Script Additions Unicode 4.1 (31 March 2005): For Unicode 5.0 (2006): Buginese N’Ko Coptic Balinese Glagolitic Phags-pa New Tai Lue Phoenician Nuskhuri (extends Georgian) Syloti Nagri Cuneiform Tifinagh Kharoshthi Old Persian Cuneiform 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (many of which are used for languages with over 5 million speakers) 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat-rooms, and share text documents in their native script 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat- rooms, and share text documents in their native script • Unicode is widely supported by current fonts and operating systems, but… Over 80 scripts are missing! Missing Modern Minority Scripts India, Nepal, Southeast Asia China: -

Iso/Iec Jtc1/Sc2/Wg2 N2383
ISO/IEC JTC1/SC2/WG2 N2383 2001-10-10 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation internationale de normalisation еждународная организация по стандартизации Doc Type: Working Group Document Title: Roadmaps Source: The Unicode Consortium Status: Liaison Contribution Date: 2001-10-10 Distribution: WG2 and UTC The Roadmaps to the UCS have been maintained by the ad-hoc committee on the Roadmap, which consists of Michael Everson, Rick McGowan, and Ken Whistler. They were hosted on Michael Everson’s site, and this caused difficulties for WG2 in referencing them. The Unicode Consortium has offered to host the Roadmap documents as official Unicode documents, acknowledging their usefulness and stability. This should allow WG2 to reference them by URL (http://www.unicode.org/roadmaps). Whenever major revisions are made, the Unicode Consortium will forward a document similar to this one to WG2. 1 2001-04-01 Roadmap to the BMP 2001-10-10 15:28 Roadmap to the BMP Home ||Site Map Search Tables Roadmap to the BMP Roadmap Introduction Roadmap to the Revision 3.0 BMP (Plane 0) Authors Michael Everson, Rick McGowan, Ken Whistler Roadmap to the SMP (Plane 1) Date 2001-10-10 Roadmap to the SIP (Plane 2) This Version http://www.unicode.org/roadmaps/bmp-3-0.html Roadmap to the SSP (Plane 14) Previous Version n/a Not the Roadmap Latest Version http://www.unicode.org/roadmaps/bmp-3-0.html More Information Summary The Unicode Standard, Version 3.0 The following table comprises a proportional map of Plane 0, the BMP (Basic Multilingual Proposed Plane). -

Universal Scripts Project: Statement of Significance and Impact
Universal Scripts Project: Statement of Significance and Impact The Universal Scripts Project expands the capabilities of the Internet by providing digital access to text materials from a variety of modern and historical cultures whose writing systems are not currently included in the international standard for electronic representation of scripts, known as Unicode. People who write in these scripts find it difficult to use email, compose and send documents electronically, and post documents on the World Wide Web, without relying on nonstandard fonts or other cumbersome workarounds, and are therefore left out of the “technological revolution.” About 66 scripts are currently included in the Unicode standard, but over 80 are not. Some 40 of these missing scripts belong to modern linguistic minorities in Africa, the Indian subcontinent, China, and other countries in Southeast Asia; about 40 are scripts of historical importance. The project’s goal for 2007–2008 is to provide the standards bodies overseeing character sets with proposals for 15 scripts to be included in the Unicode standard. The scripts selected for inclusion include 9 modern minority scripts and 6 historical scripts. The need is urgent, because the entire process, from first proposal to acceptance, typically takes from 2 to 5 years, and support among corporations and national bodies for adding more scripts to Unicode is uncertain. If the proposals are not submitted soon, these user communities will not be able to use their scripts in the near future. The scripts selected for this grant have established scholarly and user-community connections, which will help guarantee that the proposals meet the users' needs. -

With the Power of Their Forefathers (Revue) Copie DP Edit
With the power of their forefathers: Kinship between early Tibetan ritualists and the Naxi dongba of south- west China1 Duncan Poupard (The Chinese University of Hong Kong) here is a well-documented history of translation between In- dia, Tibet and China beginning in the seventh century and T continuing for almost a millennium. The transmission of the Buddhist canon that took place during this time has been perceived as one of the world’s greatest cultural exchanges.2 But what about the transmission of the non-Buddhist Tibetan canon (if indeed it can be called a canon), that is, the ritual tradition from early Tibet that has been classified by some as “Bon”? In the mid-twentieth century it was suggested that the explication of the still-extant religious literature of a small tribe in southwest China, the Naxi, would lead to a fuller un- derstanding of the Tibetan Bon tradition. But there has still been little comparative study between these two lineages. Analysis of the Dunhuang manuscripts, in particular the textual references to the ar- chetypal ritualist, gShen-rab myi-bo, reveals a common through line from old Tibet, to Bon tradition, to Naxi ritual manuscripts, which fea- ture prominently a chief ritualist known as Do-bbaq sheel-lo.3 I sug- gest that the Naxi manuscripts show an inheritance from early Tibet – perhaps before the formation of an organized “Bon” religion. In this essay I posit that the existence of an archetypal ritualist in the Naxi canon is a continuation of a narrative theme (that of the well-versed ritual practitioner), and indeed possibly of specific ritual personages themselves, from the old Tibetan manuscripts, filtered through the 1 This work has been supported by a British Academy Stein-Arnold Exploration Fund Grant (SA1819\190000). -

Chinese Views on Nature
Chinese Views on Nature Shan Ni, Shanghai, People's Republic of China Email: [email protected] 1. Summary The People's Republic of China (referred to as China), is located in Eastern Eurasia, on the Pacific West Coast. Geographically speaking, nature has played a significant role in Chinese culture through its long history. China is filled with various kinds of natural resources. This paper explores some worldviews of nature from Chinese perspectives, particularly from traditional Chinese views on nature. 2. Introduction to China and Traditional Chinese Cultural Influences on Ethics China (known as " Zhong Guo" in Chinese) is the world's most-populous country with a population of over 1.3 billion in 2010 (2011 Sixth Chinese national census major data communiqué) accounting for approximately 19% of the world population. China has one of the largest areas for a single country, covering about 9.6 million square kilometers and borders 14 countries. 2.1 The Origins of "Zhong Guo" and its Ethics Value The word "China" means literally the "central state". According to the "Ci Yuan" (also known as "Chinese Etymology Dictionary"), in ancient times, the Chinese Huaxia group established their state in the Yellow River Basin area. They thought the state is located in the center of the world, thus, they called it as "Zhong Guo". Meanwhile, other places around China are called as "Si Fang" (four directions of north, south, west and east). It is also recognized as the origin of Tributary System (known as "Sino-centric sphere of order") in the ancient China. The word "Zhong" (literally meaning centre or mean) plays an important role throughout Chinese history, cultural and ethics development. -
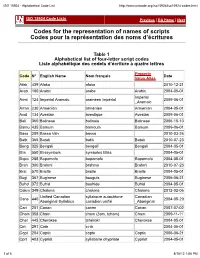
ISO 15924 - Alphabetical Code List
ISO 15924 - Alphabetical Code List http://www.unicode.org/iso15924/iso15924-codes.html ISO 15924 Code Lists Previous | RA Home | Next Codes for the representation of names of scripts Codes pour la représentation des noms d’écritures Table 1 Alphabetical list of four-letter script codes Liste alphabétique des codets d’écriture à quatre lettres Property Code N° English Name Nom français Date Value Alias Afak 439 Afaka afaka 2010-12-21 Arab 160 Arabic arabe Arabic 2004-05-01 Imperial Armi 124 Imperial Aramaic araméen impérial 2009-06-01 _Aramaic Armn 230 Armenian arménien Armenian 2004-05-01 Avst 134 Avestan avestique Avestan 2009-06-01 Bali 360 Balinese balinais Balinese 2006-10-10 Bamu 435 Bamum bamoum Bamum 2009-06-01 Bass 259 Bassa Vah bassa 2010-03-26 Batk 365 Batak batik Batak 2010-07-23 Beng 325 Bengali bengalî Bengali 2004-05-01 Blis 550 Blissymbols symboles Bliss 2004-05-01 Bopo 285 Bopomofo bopomofo Bopomofo 2004-05-01 Brah 300 Brahmi brahma Brahmi 2010-07-23 Brai 570 Braille braille Braille 2004-05-01 Bugi 367 Buginese bouguis Buginese 2006-06-21 Buhd 372 Buhid bouhide Buhid 2004-05-01 Cakm 349 Chakma chakma Chakma 2012-02-06 Unified Canadian syllabaire autochtone Canadian Cans 440 2004-05-29 Aboriginal Syllabics canadien unifié _Aboriginal Cari 201 Carian carien Carian 2007-07-02 Cham 358 Cham cham (čam, tcham) Cham 2009-11-11 Cher 445 Cherokee tchérokî Cherokee 2004-05-01 Cirt 291 Cirth cirth 2004-05-01 Copt 204 Coptic copte Coptic 2006-06-21 Cprt 403 Cypriot syllabaire chypriote Cypriot 2004-05-01 1 of 6 8/16/12 1:56 PM ISO -

Draft Additional Repertoire for ISO/IEC 10646:2016 (5Th Edition)
Title: Draft additional repertoire for ISO/IEC 10646:2016 (5th edition) DIS Date: 2016-10-26 L2/15-170 WG2 N4728 Source: Michel Suignard, project editor Status: Project Editor's summary of the character repertoire addition as included in the DIS ballot Action: For review by WG2 and UTC experts Distribution: WG2 and UTC Replaces: Status This document presents a summary of all characters that constitute the tentative new repertoire for ISO/IEC 10646 5th edition, with code positions, representative glyphs and character names. Manner of Presentation The character names and code points shown are the same for Unicode and ISO/IEC 10646, including annotations. Note to Reviewers UTC/WG2 Reviewers, please use this document as a description of the result from the disposition of ballot comments for the CD.2. Contents This document lists 8447 characters. The following list shows all 26 blocks (existing or new) to which characters are proposed to be added, or which have been affected by other changes documented here. 0860-086F Syriac Supplement see document L2/15-088 0980-09FF Bengali See document: L2/15-161 L2/15-172 0A80-0AFF Gujarati see document L2/15-103 0D00-0D7F Malayalam See document L2/14-015R L2/14-292 L2/15-045 1CD0-1CFF Vedic Extensions See document: L2/15-160 1DC0-1DFF Combining Diacritical Marks Supplement See document L2/14-285 L2/15-173R 20A0-20CF Currency Symbols See document L2/15-299 2300-23FF Miscellaneous Technical See document L2/15-031 2B00-2BFF Miscellaneous Symbols and Arrows See document L2/15-083 2E00-2E7F Supplemental Punctuation -
Leaks in the Unicode Pipeline: Script, Script, Script…
Leaks in the Unicode pipeline: script, script, script… Michael Everson, Everson Typography, www.evertype.com Some 52 scripts are currently allocated in the Unicode Standard. This reflects an enormous amount of work on the part of a great many people. An examination of the Roadmap shows, however, that there are at present no less than 96 scripts yet to be encoded! These scripts range from large, complex and famous dead scripts like Egyptian hieroglyphs, to small, little-known but simple scripts like Old Permic. But, importantly, about a third of the scripts are living scripts which are intended to go on the BMP. Over the past few years, some implementers and standardizers alike have expressed their concern about how much work remains to be done. “When will the standard be finished?” they have asked. This talk will give a brief overview of the history of Unicode allocations, and discuss the standardization process required for newly- allocated scripts, including discussion of the kinds of procedural, political, and implementation issues which are met with in trying to get a script standardized. The different types of scripts remaining to be encoded will be discussed with regard to the ease with which they can be both encoded and implemented. Finally, a proposal for the way forward will be given. Many of you will know me as the author of a rather large number of proposals to add various scripts and characters to the standard. One of our colleagues recently sent me an e-mail saying that he considered me to be to Unicode script proposals what the inherent vowel is to Indic consonants! Though the title of my talk is “Leaks in the Unicode pipeline”, I don’t mean to imply that there are errors or faults in our encoding process – I just mean to underscore the fact that a good many scripts remain to be encoded, and that, given the current rate of demand or urgency for them, as well as the lack of resources to facilitate the work, we can expect these scripts to be added slowly, like drips out of a pipe. -
Roadmaps to ISO/IEC 10646 and the Unicode Standard
Roadmaps to ISO/IEC 10646 and the Unicode Standard • INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2 Universal Multiple-Octet Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2 N2559 2002-12-06 Title: Snapshot of Pictorial view of Roadmaps to BMP, SMP, SIP and SSP Ad hoc group on Roadmaps ( Michael Everson, Rick McGowan, and Ken Whistler) Source: Adapted by: V.S. Umamaheswaran For review and adoption WG2 at its meeting M42 Status: (includes update as of December, 05, 2002) Distribution: ISO/IEC JTC 1/SC 2/WG 2, ISO/IEC JTC 1/SC 2 and Liaison Organisations Replaces: WG2 document N2461 Summary This document is the latest snapshot of the roadmap documents that has been presented to and adopted by WG2 (ISO/IEC JTC1/SC2/WG 2). Four tables containing the roadmaps to ● the Basic Multilingual Plane (BMP - Plane 0) (versionbmp-3-10, 2002-12-03) ● the Supplementary Multilingual Plane (SMP - Plane 1) (version smp-3-4, 2002-12-03) ● the Supplementary Ideographic Plane (SIP - Plane 2) (version sip-3-1, 2002-11-11), and ● the Supplementary Special-purpose Plane (SSP - Plane 14) (version ssp-3-1, 2002-01-22) are included in this document. The Roadmap ad hoc group maintains and updates this document as a service to the UTC (Unicode Technical Committee) and to WG2 (ISO/IEC JTC1/SC2/WG2). The latest working version of this document can be found at http://www.unicode.org/roadmaps. This document is informative. Please send corrigenda and other comments to the authors. -
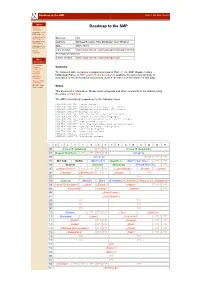
Roadmap to the SMP Home | Site Map | Search
Roadmap to the SMP Home | Site Map | Search Tables Roadmap to the SMP Roadmap Introduction Roadmap to the BMP (Plane 0) Roadmap to the SMP (Plane 1) Revision 3.0 Roadmap to the Authors Michael Everson, Rick McGowan, Ken Whistler SIP (Plane 2) Roadmap to the Date 2001-10-10 SSP (Plane 14) Not the This Version http://www.unicode.org/roadmaps/smp/smp-3-0.html Roadmap Previous Version n/a Latest Version http://www.unicode.org/roadmaps/smp/ More Information The Unicode Standard, Summary Version 3.0 Proposed The following table comprises a proportional map of Plane 1, the SMP (Supplementary characters Multilingual Plane). A PDF version of this document is available for convenient printing. A Submitting Proposals description of the presentation conventions used in the table is at the bottom of this page. ISO/IEC 10646 Collections ISO/IEC 15924 Status (script codes) This document is informative. Please send corrigenda and other comments to the authors using the online contact form. The SMP is tentatively mapped out to the following zones. 00010000-000102FF Aegean scripts 00010300-000107FF Alphabetic and syllabic LTR scripts 00010800-00010FFF Alphabetic and syllabic RTL scripts 00011000-000117FF Brahmic scripts 00011800-00011FFF African and other syllabic scripts 00012000-000127FF Scripts for invented languages 00012800-00012DFF Cuneiform and other Near Eastern scripts 00012E00-000133FF Undeciphered scripts 00013400-00013FFF North American ideographs and pictograms 00014000-00016BFF Egyptian and Mayan hieroglyphs 00016C00 00016FFF Sumerian pictograms