Brahmi-Net: a Transliteration and Script Conversion System for Languages of the Indian Subcontinent
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grammatica Et Verba Glamor and Verve
“GippertOVprint” — 2014/4/24 — 22:14 — page 81 —#1 Grammatica et verba Glamor and verve Studies in South Asian, historical, and Indo-European linguistics in honor of Hans Henrich Hock on the occasion of his seventy-fifth birthday edited by Shu-Fen Chen and Benjamin Slade Beech Stave Press Ann Arbor New York • “GippertOVprint” — 2014/4/24 — 22:14 — page 82 —#2 © Beech Stave Press, Inc. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Typeset with LATEX using the Galliard typeface designed by Matthew Carter and Greek Old Face by Ralph Hancock. The typeface on the cover is Post Hock by Steve Peter. Library of Congress Cataloging-in-Publication Data Grammatica et verba : glamor and verve : studies in South Asian, historical, and Indo- European linguistics in honor of Hans Henrich Hock on the occasion of his seventy- fifth birthday / edited by Shu-Fen Chen and Benjamin Slade. pages cm Includes bibliographical references. ISBN ---- (alk. paper) . Indo-European languages. Lexicography. Historical linguistics. I. Hock, Hans Henrich, - honoree. II. Chen, Shu-Fen, editor of compilation. III. Slade, Ben- jamin, editor of compilation. –dc Printed in the United States of America “GippertOVprint” — 2014/4/24 — 22:14 — page 83 —#3 TableHHHHHH ofHHHHHHHHHHHHHHH ContentsHHHHHHHHHHHH Preface . vii Bibliography of Hans Henrich Hock . ix List of Contributors . xxi , Traces of Archaic Human Language Structure Anvita Abbi in the Great Andamanese Language. , A Study of Punctuation Errors in the Chinese Diamond Sutra Shu-Fen Chen Based on Sanskrit Texts . -

Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs
Comparison, Selection and Use of Sentence Alignment Algorithms for New Language Pairs Anil Kumar Singh Samar Husain LTRC, IIIT LTRC, IIIT Gachibowli, Hyderabad Gachibowli, Hyderabad India - 500019 India - 500019 a [email protected] s [email protected] Abstract than 95%, and usually 98 to 99% and above). The evaluation is performed in terms of precision, and Several algorithms are available for sen- sometimes also recall. The figures are given for one tence alignment, but there is a lack of or (less frequently) more corpus sizes. While this systematic evaluation and comparison of does give an indication of the performance of an al- these algorithms under different condi- gorithm, the variation in performance under varying tions. In most cases, the factors which conditions has not been considered in most cases. can significantly affect the performance Very little information is given about the conditions of a sentence alignment algorithm have under which evaluation was performed. This gives not been considered while evaluating. We the impression that the algorithm will perform with have used a method for evaluation that the reported precision and recall under all condi- can give a better estimate about a sen- tions. tence alignment algorithm's performance, We have tested several algorithms under differ- so that the best one can be selected. We ent conditions and our results show that the per- have compared four approaches using this formance of a sentence alignment algorithm varies method. These have mostly been tried significantly, depending on the conditions of test- on European language pairs. We have ing. Based on these results, we propose a method evaluated manually-checked and validated of evaluation that will give a better estimate of the English-Hindi aligned parallel corpora un- performance of a sentence alignment algorithm and der different conditions. -

OSU WPL # 27 (1983) 140- 164. the Elimination of Ergative Patterns Of
OSU WPL # 27 (1983) 140- 164. The Elimination of Ergative Patterns of Case-Marking and Verbal Agreement in Modern Indic Languages Gregory T. Stump Introduction. As is well known, many of the modern Indic languages are partially ergative, showing accusative patterns of case- marking and verbal agreement in nonpast tenses, but ergative patterns in some or all past tenses. This partial ergativity is not at all stable in these languages, however; what I wish to show in the present paper, in fact, is that a large array of factors is contributing to the elimination of partial ergativity in the modern Indic languages. The forces leading to the decay of ergativity are diverse in nature; and any one of these may exert a profound influence on the syntactic development of one language but remain ineffectual in another. Before discussing this erosion of partial ergativity in Modern lndic, 1 would like to review the history of what the I ndian grammar- ians call the prayogas ('constructions') of a past tense verb with its subject and direct object arguments; the decay of Indic ergativity is, I believe, best envisioned as the effect of analogical develop- ments on or within the system of prayogas. There are three prayogas in early Modern lndic. The first of these is the kartariprayoga, or ' active construction' of intransitive verbs. In the kartariprayoga, the verb agrees (in number and p,ender) with its subject, which is in the nominative case--thus, in Vernacular HindOstani: (1) kartariprayoga: 'aurat chali. mard chala. woman (nom.) went (fern. sg.) man (nom.) went (masc. -

Recognition of Online Handwritten Gurmukhi Strokes Using Support Vector Machine a Thesis
Recognition of Online Handwritten Gurmukhi Strokes using Support Vector Machine A Thesis Submitted in partial fulfillment of the requirements for the award of the degree of Master of Technology Submitted by Rahul Agrawal (Roll No. 601003022) Under the supervision of Dr. R. K. Sharma Professor School of Mathematics and Computer Applications Thapar University Patiala School of Mathematics and Computer Applications Thapar University Patiala – 147004 (Punjab), INDIA June 2012 (i) ABSTRACT Pen-based interfaces are becoming more and more popular and play an important role in human-computer interaction. This popularity of such interfaces has created interest of lot of researchers in online handwriting recognition. Online handwriting recognition contains both temporal stroke information and spatial shape information. Online handwriting recognition systems are expected to exhibit better performance than offline handwriting recognition systems. Our research work presented in this thesis is to recognize strokes written in Gurmukhi script using Support Vector Machine (SVM). The system developed here is a writer independent system. First chapter of this thesis report consist of a brief introduction to handwriting recognition system and some basic differences between offline and online handwriting systems. It also includes various issues that one can face during development during online handwriting recognition systems. A brief introduction about Gurmukhi script has also been given in this chapter In the last section detailed literature survey starting from the 1979 has also been given. Second chapter gives detailed information about stroke capturing, preprocessing of stroke and feature extraction. These phases are considered to be backbone of any online handwriting recognition system. Recognition techniques that have been used in this study are discussed in chapter three. -

Slides for My Lecture for the Texperience 2010
◦ DEVELOPMENTDEVELOPMENT OF OFxxındyındy◦ SORTSORT AND AND MERGE MERGE RULES RULES FORFOR INDIC INDIC LANGUAGES LANGUAGES ZdeněkZdeněk Wagner, Wagner, Praha, Praha, Česká Česká republika republika AnshumanAnshuman Pandey, Pandey, Univ. Univ. Michigan, Michigan, USA USA JayaJaya Saraswati, Saraswati, Mumbai, Mumbai, India India ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) ◦ NoteNote on on pronunciation pronunciation of ofxxındy◦ındy Czech: ks English: usually as z Hindi: as ks., l#mF can be transliterated either Lakshmi or Laxmi Chinese: as sh Russian: 娤¨ (meaning Hindi) x◦ındy sorts Hindi MakeIndexMakeIndex • version for English and German • CSIndex – version for Czech and Slovak • unpublished version for Sanskrit (Mark Csernel) Tables defining the sort algorithm are hard-wired in the pro- gram source code. Modification for other languages is difficult and leads rather to confusion than to development of a univer- sal tool. InternationalInternationalMakeIndexMakeIndex • Tables defining the sort algorithm present in external files. • Sort rules defined by regular expressions. -
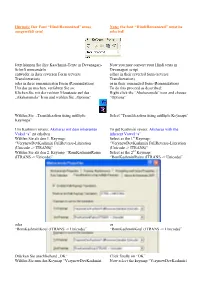
Note: the Font “Hindiromanized” Must Be Selected
Hinweis: Der Font “HindiRomanized” muss Note: the font “HindiRomanized” must be ausgewählt sein! selected! Jetzt können Sie ihre Kaschmiri-Texte in Devanagari- Now you may convert your Hindi texts in Schrift umwandeln Devanagari script entweder in ihrer reversen Form (reverse either in their reverted form (reverse Transliteration) Transliteration) oder in ihrer romanisierten Form (Romanization) or in their romanized form (Romanization) Um das zu machen, verfahren Sie so: To do this proceed as described: Klicken Sie mit der rechten Maustaste auf das Right click the “Aksharamala” icon and choose „Aksharamala” Icon und wählen Sie „Options“ “Options” Wählen Sie „Transliteration using multiple Select “Transliteration using multiple Keymaps” Keymaps” Um Kashmiri revers: Aksharas mit dem inherenten To get Kashmiri revers: Aksharas with the Vokal “a” zu erhalten inherent Vowel “a” Wählen Sie als den 1. Keymap: Select as the 1st Keymap: “VerynewDevKashmiri FullReverse-Literation “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” (Unicode -> ITRANS)” Wählen Sie als den 2. Keymap “RomKashmiriRaina Select as the 2nd Keymap: (ITRANS -> Unicode)” “RomKashmiriRaina (ITRANS -> Unicode)” oder or “RomKashmiriKoul (ITRANS -> Unicode)” “RomKashmiriKoul (ITRANS -> Unicode)” Drücken Sie anschließend „OK“ Click finally on “OK” Wählen Sie nun den Keymap “VerynewDevKashmiri Now select the keymap “VerynewDevKashmiri FullReverse-Literation (Unicode -> ITRANS)” aus FullReverse-Literation (Unicode -> ITRANS)” Um Kashmiri revers: Aksharas ohne den inherenten -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Tugboat, Volume 15 (1994), No. 4 447 Indica, an Indic Preprocessor
TUGboat, Volume 15 (1994), No. 4 447 HPXC , an Indic preprocessor for T X script, ...inMalayalam, Indica E 1 A Sinhalese TEXSystem hpx...inSinhalese,etc. This justifies the choice of a common translit- Yannis Haralambous eration scheme for all Indic languages. But why is Abstract a preprocessor necessary, after all? A common characteristic of Indic languages is In this paper a two-fold project is described: the first the fact that the short vowel ‘a’ is inherent to con- part is a generalized preprocessor for Indic scripts (scripts of languages currently spoken in India—except Urdu—, sonants. Vowels are written by adding diacritical Sanskrit and Tibetan), with several kinds of input (LATEX marks (or smaller characters) to consonants. The commands, 7-bit ascii, CSX, ISO/IEC 10646/unicode) beauty (and complexity) of these scripts comes from and TEX output. This utility is written in standard Flex the fact that one needs a special way to denote the (the gnu version of Lex), and hence can be painlessly absence of vowel. There is a notorious diacritic, compiled on any platform. The same input methods are called “vir¯ama”, present in all Indic languages, which used for all Indic languages, so that the user does not is used for this reason. But it seems illogical to add a need to memorize different conventions and commands sign, to specify the absence of a sound. On the con- for each one of them. Moreover, the switch from one lan- trary, it seems much more logical to remove some- guage to another can be done by use of user-defineable thing, and what is done usually is that letters are preprocessor directives. -

Inflectional Morphology Analyzer for Sanskrit
Inflectional Morphology Analyzer for Sanskrit Girish Nath Jha, Muktanand Agrawal, Subash, Sudhir K. Mishra, Diwakar Mani, Diwakar Mishra, Manji Bhadra, Surjit K. Singh [email protected] Special Centre for Sanskrit Studies Jawaharlal Nehru University New Delhi-110067 The paper describes a Sanskrit morphological analyzer that identifies and analyzes inflected noun- forms and verb-forms in any given sandhi-free text. The system which has been developed as java servlet RDBMS can be tested at http://sanskrit.jnu.ac.in (Language Processing Tools > Sanskrit Tinanta Analyzer/Subanta Analyzer) with Sanskrit data as unicode text. Subsequently, the separate systems of subanta and ti anta will be combined into a single system of sentence analysis with karaka interpretation. Currently, the system checks and labels each word as three basic POS categories - subanta, ti anta, and avyaya. Thereafter, each subanta is sent for subanta processing based on an example database and a rule database. The verbs are examined based on a database of verb roots and forms as well by reverse morphology based on Pāini an techniques. Future enhancements include plugging in the amarakosha ( http://sanskrit.jnu.ac.in/amara ) and other noun lexicons with the subanta system. The ti anta will be enhanced by the k danta analysis module being developed separately. 1. Introduction The authors in the present paper are describing the subanta and ti anta analysis systems for Sanskrit which are currently running at http://sanskrit.jnu.ac.in . Sanskrit is a heavily inflected language, and depends on nominal and verbal inflections for communication of meaning. A fully inflected unit is called pada . -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi . -

Relation Between Harappan and Brahmi Scripts
Relation Between Harappan And Brahmi Scripts Subhajit Ganguly Email: [email protected] Copyright © Subhajit Ganguly, 2012 Abstract: Around 45 odd signs out of the total number of Harappan signs found make up almost 100 percent of the inscriptions, in some form or other, as said earlier. Out of these 45 signs, around 40 are readily distinguishable. These form an almost exclusive and unique set. The primary signs are seen to have many variants, as in Brahmi. Many of these provide us with quite a vivid picture of their evolution, depending upon the factors of time, place and usefulness. Even minor adjustments in such signs, depending upon these factors, are noteworthy. Many of the signs in this list are the same as or are very similar to the corresponding Brahmi signs. These are similarities that simply cannot arise from mere chance. It is also to be noted that the most frequently used signs in the Brahmi look so similar to the most frequent Harappan symbols. The Harappan script transformed naturally into the Brahmi, depending upon the factors channelizing evolution of scripts. Brahmi Signs: hough a few variants of the Brahmi alphabet system have been known to exist, with the evolution of Brahmi characters, the core signs are seen to be quite consistent over T time. The syntax of their usage has also been found to be roughly consistent throughout this evolution process. Lists of Brahmi numerals, vowels and consonants are provided here in fig. 2and fig. 3 , respectively: 1 Fig. 2 : Brahmi numerals from 1-9. 2 Fig. 3 : Brahmi vowels and consonants.