Digital Encoding of South Asian Languages: a Contemporary Guide to Unicode and Fonts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Inpage Urdu Manual
http://www.axiscomputers.com [email protected] Concept SOFTWARE .. . . (version) . 1 Horizontal . CharacterScript Letters & VowelsLigature . . Windows 95, 3.11 Full stop 5.0 (Decorative Work) (Spot Color Separation) . . 2 . . 3 Spell Check Kerning ME NT 4 6 .......................................................................................... ......................................................................................... .................................................................................. ..................................................................................... .............................................................................................. ......................................................................................... ................................................................................................. ..................................................................................... ................................................................................ ................................................................................. .......................................................................................... .................................................................................................. .............................................................................................. ....................................................................................................... -

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Proposal to Encode 0D5F MALAYALAM LETTER ARCHAIC II
Proposal to encode 0D5F MALAYALAM LETTER ARCHAIC II Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2012-May-22 §1. Introduction In the Malayalam Unicode encoding, the independent letter form for the long vowel Ī is: ഈ where the length mark ◌ൗ is appended to the short vowel ഇ to parallel the symbols for U/UU i.e. ഉ/ഊ. However, Ī was originally written as: As these are entirely different representations of Ī, although their sound value may be the same, it is proposed to encode the archaic form as a separate character. §2. Background As the core Unicode encoding for the major Indic scripts is based on ISCII, and the ISCII code chart for Malayalam only contained the modern form for the independent Ī [1, p 24]: … thus it is this written form that came to be encoded as 0D08 MALAYALAM LETTER II. While this “new” written form is seen in print as early as 1936 CE [2]: … there is no doubt that the much earlier form was parallel to the modern Grantha , both of which are derived from the old Grantha Ī as seen below: 1 ma - īdṛgvidhā | tatarāya īṇ Old Grantha from the Iḷaiyānputtūr copper plates [3, p 13]. Also seen is the Vatteḻuttu Ī of the same time (line 2, 2nd char from right) which also exhibits the two dots. Of course, both are derived from old South Indian Brahmi Ī which again has the two dots. It is said [entire paragraph: Radhakrishna Warrier, personal communication] that it was the poet Vaḷḷattōḷ Nārāyaṇa Mēnōn (1878–1958) who introduced the new form of Ī ഈ. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD). -

Comment on L2/13-065: Grantha Characters from Other Indic Blocks Such As Devanagari, Tamil, Bengali Are NOT the Solution
Comment on L2/13-065: Grantha characters from other Indic blocks such as Devanagari, Tamil, Bengali are NOT the solution Dr. Naga Ganesan ([email protected]) Here is a brief comment on L2/13-065 which suggests Devanagari block for Grantha characters to write both Aryan and Dravidian languages. From L2/13-065, which suggests Devanagari block for writing Sanskrit and Dravidian languages, we read: “Similar dedicated characters were provided to cater different fonts as URUDU MARATHI SINDHI MARWARI KASHMERE etc for special conditions and needs within the shared DEVANAGARI range. There are provisions made to suit Dravidian specials also as short E short O LLLA RRA NNNA with new created glyptic forms in rhythm with DEVANAGARI glyphs (with suitable combining ortho-graphic features inside DEVANAGARI) for same special functions. These will help some aspirant proposers as a fall out who want to write every Indian language contents in Grantham when it is unified with DEVANAGARI because those features were already taken care of by the presence in that DEVANAGARI. Even few objections seen in some docs claim them as Tamil characters to induce a bug inside Grantham like letters from GoTN and others become tangential because it is going to use the existing Sanskrit properties inside shared DEVANAGARI and also with entirely new different glyph forms nothing connected with Tamil. In my doc I have shown rhythmic non-confusable glyphs for Grantham LLLA RRA NNNA for which I believe there cannot be any varied opinions even by GoTN etc which is very much as Grantham and not like Tamil form at all to confuse (as provided in proposals).” Grantha in Devanagari block to write Sanskrit and Dravidian languages will not work. -
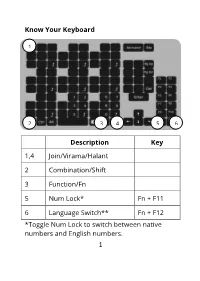
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

MICROSOFT OEM *** ( (Special Prices) Taxes RTP(Rs.) SP (Rs.) Support : [email protected] / 1800-111100 / Airtel: 18001021100 / +91 80 40103000
SOFTMART SOLUTIONS - RESELLER PRICE LIST - September 8, 2021 The rates on the pricelist are valid only for the date of the pricelist. Please reconfirm / request for the current or extended validity prices by email : [email protected] & [email protected] before quoting to your customers or before placing any orders to us. PRICELIST CODE : PL-20210908 SAC CODE OF *SOFTWARE LICENCE : 997331 SAC CODE OF *SOFTWARE SUBSCRIPTION : 998434 HSN CODE OF SOFTWARE WITH MEDIA: 85238020 Customer Licence Information Form required for all licence orders / Deal Registration requests : www.softmartonline.com/LForm.doc and www.softmartonline.com/DealReg.doc The following details are mandatory for processing for ESD Purchase Orders : Name or organisation / Complete Physical Location Address / City / State / PINCODE / Contact Person Full Name / Contact Person Company Email-id / Tel. Number / Copy of Enduser PO required. ALL LICENCE ORDERS ARE NON-CANCELLABLE WITHOUT EXCEPTION. When you send us any enquiry for software not listed, to enable us to reply asap, please include the maximum details possible. Category of Enduser (Government / Educational / Charity/ NGO / Commercial), Software Name & Software Website, Operating System (Win 2012 / 16 / 19 Server, Win 10 / 8 / 7 Pro / Home / Linux / Macintosh), Number of users / devices and the objective which the customer plans to use the software. Enduser details are required to get ensure partner transfer rates. ESD : Electronic Software Delivery (Software to be downloaded from weblink / website ). It is mandatory -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR. -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display.