MLDSP-GUI: an Alignment-Free Standalone Tool with an Interactive Graphical User Interface for DNA Sequence Comparison and Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ML-DSP: Machine Learning with Digital Signal Processing for Ultrafast, Accurate, and Scalable Genome Classification at All Taxonomic Levels Gurjit S
Randhawa et al. BMC Genomics (2019) 20:267 https://doi.org/10.1186/s12864-019-5571-y SOFTWARE ARTICLE Open Access ML-DSP: Machine Learning with Digital Signal Processing for ultrafast, accurate, and scalable genome classification at all taxonomic levels Gurjit S. Randhawa1* , Kathleen A. Hill2 and Lila Kari3 Abstract Background: Although software tools abound for the comparison, analysis, identification, and classification of genomic sequences, taxonomic classification remains challenging due to the magnitude of the datasets and the intrinsic problems associated with classification. The need exists for an approach and software tool that addresses the limitations of existing alignment-based methods, as well as the challenges of recently proposed alignment-free methods. Results: We propose a novel combination of supervised Machine Learning with Digital Signal Processing, resulting in ML-DSP: an alignment-free software tool for ultrafast, accurate, and scalable genome classification at all taxonomic levels. We test ML-DSP by classifying 7396 full mitochondrial genomes at various taxonomic levels, from kingdom to genus, with an average classification accuracy of > 97%. A quantitative comparison with state-of-the-art classification software tools is performed, on two small benchmark datasets and one large 4322 vertebrate mtDNA genomes dataset. Our results show that ML-DSP overwhelmingly outperforms the alignment-based software MEGA7 (alignment with MUSCLE or CLUSTALW) in terms of processing time, while having comparable classification accuracies for small datasets and superior accuracies for the large dataset. Compared with the alignment-free software FFP (Feature Frequency Profile), ML-DSP has significantly better classification accuracy, and is overall faster. We also provide preliminary experiments indicating the potential of ML-DSP to be used for other datasets, by classifying 4271 complete dengue virus genomes into subtypes with 100% accuracy, and 4,710 bacterial genomes into phyla with 95.5% accuracy. -
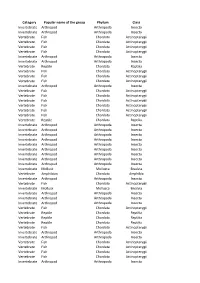
Category Popular Name of the Group Phylum Class Invertebrate
Category Popular name of the group Phylum Class Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate Reptile Chordata Reptilia Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Reptile Chordata Reptilia Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Mollusk Mollusca Bivalvia Vertebrate Amphibian Chordata Amphibia Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Invertebrate Mollusk Mollusca Bivalvia Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate -

Viet Nam Ramsar Information Sheet Published on 16 October 2018
RIS for Site no. 2360, Van Long Wetland Nature Reserve, Viet Nam Ramsar Information Sheet Published on 16 October 2018 Viet Nam Van Long Wetland Nature Reserve Designation date 10 February 2017 Site number 2360 Coordinates 20°23'35"N 105°51'10"E Area 2 736,00 ha https://rsis.ramsar.org/ris/2360 Created by RSIS V.1.6 on - 16 October 2018 RIS for Site no. 2360, Van Long Wetland Nature Reserve, Viet Nam Color codes Fields back-shaded in light blue relate to data and information required only for RIS updates. Note that some fields concerning aspects of Part 3, the Ecological Character Description of the RIS (tinted in purple), are not expected to be completed as part of a standard RIS, but are included for completeness so as to provide the requested consistency between the RIS and the format of a ‘full’ Ecological Character Description, as adopted in Resolution X.15 (2008). If a Contracting Party does have information available that is relevant to these fields (for example from a national format Ecological Character Description) it may, if it wishes to, include information in these additional fields. 1 - Summary Summary Van Long Wetland Nature Reserve is a wetland comprised of rivers and a shallow lake with large amounts of submerged vegetation. The wetland area is centred on a block of limestone karst that rises abruptly from the flat coastal plain of the northern Vietnam. It is located within the Gia Vien district of Ninh Binh Province. The wetland is one of the rarest intact lowland inland wetlands remaining in the Red River Delta, Vietnam. -

Comparative Phylogeography of Two Codistributed Endemic Cyprinids in Southeastern Taiwan
Biochemical Systematics and Ecology 70 (2017) 283e290 Contents lists available at ScienceDirect Biochemical Systematics and Ecology journal homepage: www.elsevier.com/locate/biochemsyseco Comparative phylogeography of two codistributed endemic cyprinids in southeastern Taiwan Tzen-Yuh Chiang a, 1, Yi-Yen Chen a, 1, Teh-Wang Lee b, Kui-Ching Hsu c, * Feng-Jiau Lin d, Wei-Kuang Wang e, Hung-Du Lin f, a Department of Life Sciences, Cheng Kung University, Tainan 701, Taiwan b Taiwan Endemic Species Research Institute, ChiChi, Nantou 552, Taiwan c Department of Industrial Management, National Taiwan University of Science and Technology, Taipei 10607, Taiwan d Tainan Hydraulics Laboratory, National Cheng Kung University, Tainan 709, Taiwan e Department of Environmental Engineering and Science, Feng Chia University, Taichung 407, Taiwan f The Affiliated School of National Tainan First Senior High School, Tainan 701, Taiwan article info abstract Article history: Two cyprinid fishes, Spinibarbus hollandi and Onychostoma alticorpus, are endemic to Received 12 October 2016 southeastern Taiwan. This study examined the phylogeography of these two codistributed Received in revised form 3 December 2016 primary freshwater fishes using mitochondrial DNA cytochrome b sequences (1140 bp) to Accepted 18 December 2016 search for general patterns in the effect of historical changes in southeastern Taiwan. In total, 135 specimens belonging to these two species were collected from five populations. These two codistributed species revealed similar genetic variation patterns. The genetic Keywords: variation in both species was very low, and the geographical distribution of the genetic Spinibarbus hollandi Onychostoma alticorpus variation corresponded neither to the drainage structure nor to the geographical distances Mitochondrial between the samples. -

Two New Species of Shovel-Jaw Carp Onychostoma (Teleostei: Cyprinidae) from Southern Vietnam
Zootaxa 3962 (1): 123–138 ISSN 1175-5326 (print edition) www.mapress.com/zootaxa/ Article ZOOTAXA Copyright © 2015 Magnolia Press ISSN 1175-5334 (online edition) http://dx.doi.org/10.11646/zootaxa.3962.1.6 http://zoobank.org/urn:lsid:zoobank.org:pub:5872B302-2C4E-4102-B6EC-BC679B3645D4 Two new species of shovel-jaw carp Onychostoma (Teleostei: Cyprinidae) from southern Vietnam HUY DUC HOANG1, HUNG MANH PHAM1 & NGAN TRONG TRAN1 1Viet Nam National University Ho Chi Minh city-University of Science, Faculty of Biology, 227 Nguyen Van Cu, District 5, Ho Chi Minh City, Vietnam. E-mail: [email protected] Corresponding author: Huy D. Hoang: [email protected] Abstract Two new species of large shovel-jaw carps in the genus Onychostoma are described from the upper Krong No and middle Dong Nai drainages of the Langbiang Plateau in southern Vietnam. These new species are known from streams in montane mixed pine and evergreen forests between 140 and 1112 m. Their populations are isolated in the headwaters of the upper Sre Pok River of the Mekong basin and in the middle of the Dong Nai basin. Both species are differentiated from their congeners by a combination of the following characters: transverse mouth opening width greater than head width, 14−17 predorsal scales, caudal-peduncle length 3.9−4.2 times in SL, no barbels in adults and juveniles, a strong serrated last sim- ple ray of the dorsal fin, and small eye diameter (20.3−21.5% HL). Onychostoma krongnoensis sp. nov. is differentiated from Onychostoma dongnaiensis sp. nov. -

Lipid M Etabolism in the Brazilian Teleost Tam Baqui
Colossoma Colossoma ) 20 DOUTORAMENTO EM CIÊNCIA ANIMALDOUTORAMENTO EM CIÊNCIA E EMGENÉTICA MELHORAMENTO ESPECIALIDADE From genes to nutrition: lipid metabolism in in metabolism lipid nutrition: to genes From the Brazilian teleost tambaqui ( macropomum Ferraz Renato Barbosa Maria João Maria Peixoto 20 D Renato Barbosa Ferraz D.ICBAS 2020 From genes to nutrition: lipid metabolism in the Brazilian teleost tambaqui (Colossoma macropomum) From genes to nutrition: lipid metabolism in the Brazilian teleost tambaqui (Colossoma macropomum) Renato Barbosa Ferraz INSTITUTO DE CIÊNCIAS BIOMÉDICAS ABEL SALAZAR Renato Barbosa Ferraz 2020 From genes to nutrition: lipid metabolism in the Brazilian teleost tambaqui (Colossoma macropomum) Tese de Candidatura ao grau de Doutor em Ciências Animal - Especialidade em Genética e Melhoramento - submetida ao Instituto de Ciências Biomédicas Abel Salazar da Universidade do Porto. Orientador Professor Doutor Luís Filipe Castro, Professor da Faculdade de Ciências da Universidade do Porto. Co-orientador Doutor Rodrigo Ozório, Investigador no CIIMAR. Co-orientador Professora Doutora Ana Lúcia Salário, Professora da Universidade Federal de Viçosa (Brasil). Financial support This study was supported by CNPq, Conselho Nacional de Desenvolvimento Científico e Tecnológico – Brazil, for the doctoral scholarship to student Renato Barbosa Ferraz with process number 201864 / 2015-0. And, by COMPETE 2020, Portugal 2020 and the European Union through the ERDF, grant number 031342, and by FCT through national funds (PTDC/CTA-AMB/31342/2017) and the strategic project UID/Multi/04423/2019 granted to CIIMAR. The research reported in this thesis was conducted at: 1) Instituto de Ciências Biomédicas Abel Salazar (ICBAS), Universidade do Porto (Portugal), 2) Centro Interdisciplinar de Investigação Marinha e Ambiental (CIIMAR), Universidade do Porto and 3) Departamento de Biologia Animal, Universidade Federal de Viçosa (Brasil). -

Mitochondrial Genome of Onychostoma Macrolepis (Osteichthyes: Cyprinidae)
Mitochondrial DNA The Journal of DNA Mapping, Sequencing, and Analysis ISSN: 1940-1736 (Print) 1940-1744 (Online) Journal homepage: http://www.tandfonline.com/loi/imdn20 Mitochondrial genome of Onychostoma macrolepis (Osteichthyes: Cyprinidae) Aihong Chai, Jie Zhang, Qingman Cui & Chunying Yuan To cite this article: Aihong Chai, Jie Zhang, Qingman Cui & Chunying Yuan (2014): Mitochondrial genome of Onychostoma macrolepis (Osteichthyes: Cyprinidae), Mitochondrial DNA To link to this article: http://dx.doi.org/10.3109/19401736.2014.883605 Published online: 18 Feb 2014. Submit your article to this journal Article views: 20 View related articles View Crossmark data Full Terms & Conditions of access and use can be found at http://www.tandfonline.com/action/journalInformation?journalCode=imdn20 Download by: [Texas A & M International University] Date: 20 September 2015, At: 08:46 http://informahealthcare.com/mdn ISSN: 1940-1736 (print), 1940-1744 (electronic) Mitochondrial DNA, Early Online: 1–2 ! 2014 Informa UK Ltd. DOI: 10.3109/19401736.2014.883605 MITOGENOME ANNOUNCEMENT Mitochondrial genome of Onychostoma macrolepis (Osteichthyes: Cyprinidae) Aihong Chai1,2, Jie Zhang2, Qingman Cui1, and Chunying Yuan1 1College of Marine Science & Engineering, Tianjin University of Science &Technology, Tianjin, PR China and 2Key Laboratory of Zoological Systematics and Evolution, Institute of Zoology, Chinese Academy of Sciences, Beijing, PR China Abstract Keywords Onychostoma macrolepis, which belongs to the genus Onychostoma (Cypriniformes, Genome, mitochondrial, Onychostoma Cyprinidae), is a benthopelagic fish that inhabits the flowing freshwaters in China. The macrolepis complete mitochondrial genome sequence of O. macrolepis is 16,595 bp in length and com- prises 13 protein-coding genes, 22 tRNA genes, 2 rRNA genes and 1 control region. -
Complete Mitochondrial Genome of the Freshwater Fish Onychostoma Lepturum (Teleostei, Cyprinidae): Genome Characterization and Phylogenetic Analysis
ZooKeys 1005: 57–72 (2020) A peer-reviewed open-access journal doi: 10.3897/zookeys.1005.57592 RESEARCH ARTICLE https://zookeys.pensoft.net Launched to accelerate biodiversity research Complete mitochondrial genome of the freshwater fish Onychostoma lepturum (Teleostei, Cyprinidae): genome characterization and phylogenetic analysis I-Chen Wang1*, Hung-Du Lin2*, Chih-Ming Liang1, Chi-Chun Huang3, Rong-Da Wang4, Jin-Quan Yang4, Wei-Kuang Wang1 1 Department of Environmental Engineering and Science, Feng Chia University, Taichung 407, Taiwan 2 The Affiliated School of National Tainan First Senior High School, Tainan 701, Taiwan3 Taiwan Endemic Species Research Institute, Nantou 552, Taiwan 4 Shanghai Universities Key Laboratory of Marine Animal Taxonomy and Evolution, Shanghai Ocean University, Shanghai 201306, China Corresponding author: Wei-Kuang Wang ([email protected]) Academic editor: M.E. Bichuette | Received 13 August 2020 | Accepted 25 November 2020 | Published 18 December 2020 http://zoobank.org/92DDFB54-0FC4-404D-BF2C-7C0B373E2992 Citation: Wang I-C, Lin H-D, Liang C-M, Huang C-C, Wang R-D, Yang J-Q,Wang W-K (2020) Complete mitochondrial genome of the freshwater fish Onychostoma lepturum (Teleostei, Cyprinidae): genome characterization and phylogenetic analysis. ZooKeys 1005: 57–72. https://doi.org/10.3897/zookeys.1005.57592 Abstract The cyprinid genus Onychostoma Günther, 1896 consists of 24 valid species distributed in Southeast Asia, including Taiwan, Hainan, mainland China and the Indochina region. In the present study, we deter- mined the complete mitochondrial genome of O. lepturum, which is 16,598 bp in length, containing 13 protein-coding genes, two rRNA genes, 22 tRNA genes and a typical control region (D-loop). -

Cytogenetics of Two Onychostoma Species in Taiwan by Ag-NOR And
Zoological Studies 56: 25 (2017) doi:10.6620/ZS.2017.56-25 Cytogenetics of Two Onychostoma Species in Taiwan by Ag-NOR and 18S rDNA Profiles Chiao-Chuan Han1,2, Tsair-Bor Yen3, Nian-Cih Chen4, and Mei-Chen Tseng4,* 1National Museum of Marine Biology and Aquarium, Pingtung 944, Taiwan. E-mail: [email protected] 2Graduate Institute of Marine Biology, National Dong Hwa University, Hualien 974, Taiwan 3Department of Tropical Agriculture and International Cooperation, National Pingtung University of Science and Technology, Pingtung 912, Taiwan. E-mail: [email protected] 4Department of Aquaculture, National Pingtung University of Science and Technology, Pingtung 912, Taiwan (Received 5 June 2017; Accepted 5 September 2017; Published 25 September 2017; Communicated by Hin-Kiu Mok) Chiao-Chuan Han, Tsair-Bor Yen, Nian-Cih Chen, and Mei-Chen Tseng (2017) Both Onychostoma barbatulum and O. alticorpus are primary freshwater fish in Taiwan. The former has been developed as an aquaculture species with high economic value, while the latter is a native endemic species in Taiwan. Understanding the cytogenetic information of these two species is necessary for their selected breeding, recovery, and management. In this study, Giemsa staining, silver-binding nucleolar organizer region (Ag-NOR), C-banding, and fluorescence in situ hybridization (FISH) with 18S ribosomal (r)DNA probes were used to analyze the cytogenetic characteristics. Results of Giemsa staining showed that the two Onychostoma species shared the same number of chromosomes, 2n = 50. Respective karyotype formulas of the female and male were 10 m + 22 sm + 10 st + 8 t and 11 m + 22 sm + 10 st + 7 t in O. -

Phylogenetic Classification of Extant Genera of Fishes of the Order Cypriniformes (Teleostei: Ostariophysi)
Zootaxa 4476 (1): 006–039 ISSN 1175-5326 (print edition) http://www.mapress.com/j/zt/ Article ZOOTAXA Copyright © 2018 Magnolia Press ISSN 1175-5334 (online edition) https://doi.org/10.11646/zootaxa.4476.1.4 http://zoobank.org/urn:lsid:zoobank.org:pub:C2F41B7E-0682-4139-B226-3BD32BE8949D Phylogenetic classification of extant genera of fishes of the order Cypriniformes (Teleostei: Ostariophysi) MILTON TAN1,3 & JONATHAN W. ARMBRUSTER2 1Illinois Natural History Survey, University of Illinois Urbana-Champaign, 1816 South Oak Street, Champaign, IL 61820, USA. 2Department of Biological Sciences, Auburn University, 101 Rouse Life Sciences Building, Auburn, AL 36849, USA. E-mail: [email protected] 3Corresponding author. E-mail: [email protected] Abstract The order Cypriniformes is the most diverse order of freshwater fishes. Recent phylogenetic studies have approached a consensus on the phylogenetic relationships of Cypriniformes and proposed a new phylogenetic classification of family- level groupings in Cypriniformes. The lack of a reference for the placement of genera amongst families has hampered the adoption of this phylogenetic classification more widely. We herein provide an updated compilation of the membership of genera to suprageneric taxa based on the latest phylogenetic classifications. We propose a new taxon: subfamily Esom- inae within Danionidae, for the genus Esomus. Key words: Cyprinidae, Cobitoidei, Cyprinoidei, carps, minnows Introduction The order Cypriniformes is the most diverse order of freshwater fishes, numbering over 4400 currently recognized species (Eschmeyer & Fong 2017), and the species are of great interest in biology, economy, and in culture. Occurring throughout North America, Africa, Europe, and Asia, cypriniforms are dominant members of a range of freshwater habitats (Nelson 2006), and some have even adapted to extreme habitats such as caves and acidic peat swamps (Romero & Paulson 2001; Kottelat et al. -

Deep Learning for (Unsupervised) Clustering of DNA Sequences
bioRxiv preprint doi: https://doi.org/10.1101/2021.05.13.444008; this version posted August 23, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. DeLUCS: Deep Learning for (Unsupervised) Clustering of DNA Sequences Pablo Mill´anArias 1]*, Fatemeh Alipour1]**, Kathleen A. Hill2, Lila Kari1 1 School of Computer Science, University of Waterloo, Waterloo, ON, Canada 2 Department of Biology, University of Western Ontario, London, ON, Canada ] These authors contributed equally to this work. * [email protected], ** [email protected] Abstract We present a novel Deep Learning method for the (Unsupervised) Clustering of DNA Sequences (DeLUCS) that does not require sequence alignment, sequence homology, or (taxonomic) identifiers. DeLUCS uses Chaos Game Representations (CGRs) of primary DNA sequences, and generates \mimic" sequence CGRs to self-learn data patterns (genomic signatures) through the optimization of multiple neural networks. A majority voting scheme is then used to determine the final cluster assignment for each sequence. The clusters learned by DeLUCS match true taxonomic groups for large and diverse datasets, with accuracies ranging from 77% to 100%: 2,500 complete vertebrate mitochondrial genomes, at taxonomic levels from sub-phylum to genera; 3,200 randomly selected 400 kbp-long bacterial genome segments, into clusters corresponding to bacterial families; three viral genome and gene datasets, averaging 1,300 sequences each, into clusters corresponding to virus subtypes. DeLUCS significantly outperforms two classic clustering methods (K-means++ and Gaussian Mixture Models) for unlabelled data, by as much as 47%. -

Cyprininae Phylogeny Revealed Independent Origins of the Tibetan
SCIENCE CHINA Life Sciences • RESEARCH PAPER • November 2016 Vol.59 No.11: 1149–1165 doi: 10.1007/s11427-016-0007-7 Cyprininae phylogeny revealed independent origins of the Tibetan Plateau endemic polyploid cyprinids and their diversifications related to the Neogene uplift of the plateau Xuzhen Wang, Xiaoni Gan, Junbing Li, Yiyu Chen & Shunping He* Key Laboratory of Aquatic Biodiversity and Conservation of the Chinese Academy of Sciences, Institute of Hydrobiology, Chinese Academy of Sciences, Wuhan 430072, China Received May 20, 2016 ; accepted July 13, 2016; published online September 14, 2016 Origin and diversification of the Tibetan polyploid cyprinids (schizothoracins) may help us to explore relationships between diversification of the cyprinids and the Tibetan Plateau uplift. Cyprininae phylogeny was analyzed using mitochondrial and nuclear DNA sequences to trace origins of polyploidy and diversifications of schizothoracins. Ancestral states reconstruction for ploidy levels indicated that the Cyprininae was diploid origin and the schizothoracin clades tetraploid origins. There were two diversification rate shifts along with diversification of the cyprinine fishes in response to the Tibetan uplift. The unusual diversification shifts were located to branches subtending the clades of Tibetan polyploid cyprinids. Our analyses suggested that (i) phylogeny of Cyprininae recovered two independent origins of the Tibetan polyploidy schizothoracins; (ii) diversifica- tions of the schizothoracins were closely related to the Neogene uplift