Deep Learning for Unsupervised Classification of DNA Sequences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Beta Diversity Patterns of Fish and Conservation Implications in The
A peer-reviewed open-access journal ZooKeys 817: 73–93 (2019)Beta diversity patterns of fish and conservation implications in... 73 doi: 10.3897/zookeys.817.29337 RESEARCH ARTICLE http://zookeys.pensoft.net Launched to accelerate biodiversity research Beta diversity patterns of fish and conservation implications in the Luoxiao Mountains, China Jiajun Qin1,*, Xiongjun Liu2,3,*, Yang Xu1, Xiaoping Wu1,2,3, Shan Ouyang1 1 School of Life Sciences, Nanchang University, Nanchang 330031, China 2 Key Laboratory of Poyang Lake Environment and Resource Utilization, Ministry of Education, School of Environmental and Chemical Engi- neering, Nanchang University, Nanchang 330031, China 3 School of Resource, Environment and Chemical Engineering, Nanchang University, Nanchang 330031, China Corresponding author: Shan Ouyang ([email protected]); Xiaoping Wu ([email protected]) Academic editor: M.E. Bichuette | Received 27 August 2018 | Accepted 20 December 2018 | Published 15 January 2019 http://zoobank.org/9691CDA3-F24B-4CE6-BBE9-88195385A2E3 Citation: Qin J, Liu X, Xu Y, Wu X, Ouyang S (2019) Beta diversity patterns of fish and conservation implications in the Luoxiao Mountains, China. ZooKeys 817: 73–93. https://doi.org/10.3897/zookeys.817.29337 Abstract The Luoxiao Mountains play an important role in maintaining and supplementing the fish diversity of the Yangtze River Basin, which is also a biodiversity hotspot in China. However, fish biodiversity has declined rapidly in this area as the result of human activities and the consequent environmental changes. Beta diversity was a key concept for understanding the ecosystem function and biodiversity conservation. Beta diversity patterns are evaluated and important information provided for protection and management of fish biodiversity in the Luoxiao Mountains. -

Family-Cyprinidae-Gobioninae-PDF
SUBFAMILY Gobioninae Bleeker, 1863 - gudgeons [=Gobiones, Gobiobotinae, Armatogobionina, Sarcochilichthyna, Pseudogobioninae] GENUS Abbottina Jordan & Fowler, 1903 - gudgeons, abbottinas [=Pseudogobiops] Species Abbottina binhi Nguyen, in Nguyen & Ngo, 2001 - Cao Bang abbottina Species Abbottina liaoningensis Qin, in Lui & Qin et al., 1987 - Yingkou abbottina Species Abbottina obtusirostris (Wu & Wang, 1931) - Chengtu abbottina Species Abbottina rivularis (Basilewsky, 1855) - North Chinese abbottina [=lalinensis, psegma, sinensis] GENUS Acanthogobio Herzenstein, 1892 - gudgeons Species Acanthogobio guentheri Herzenstein, 1892 - Sinin gudgeon GENUS Belligobio Jordan & Hubbs, 1925 - gudgeons [=Hemibarboides] Species Belligobio nummifer (Boulenger, 1901) - Ningpo gudgeon [=tientaiensis] Species Belligobio pengxianensis Luo et al., 1977 - Sichuan gudgeon GENUS Biwia Jordan & Fowler, 1903 - gudgeons, biwas Species Biwia springeri (Banarescu & Nalbant, 1973) - Springer's gudgeon Species Biwia tama Oshima, 1957 - tama gudgeon Species Biwia yodoensis Kawase & Hosoya, 2010 - Yodo gudgeon Species Biwia zezera (Ishikawa, 1895) - Biwa gudgeon GENUS Coreius Jordan & Starks, 1905 - gudgeons [=Coripareius] Species Coreius cetopsis (Kner, 1867) - cetopsis gudgeon Species Coreius guichenoti (Sauvage & Dabry de Thiersant, 1874) - largemouth bronze gudgeon [=platygnathus, zeni] Species Coreius heterodon (Bleeker, 1865) - bronze gudgeon [=rathbuni, styani] Species Coreius septentrionalis (Nichols, 1925) - Chinese bronze gudgeon [=longibarbus] GENUS Coreoleuciscus -

ML-DSP: Machine Learning with Digital Signal Processing for Ultrafast, Accurate, and Scalable Genome Classification at All Taxonomic Levels Gurjit S
Randhawa et al. BMC Genomics (2019) 20:267 https://doi.org/10.1186/s12864-019-5571-y SOFTWARE ARTICLE Open Access ML-DSP: Machine Learning with Digital Signal Processing for ultrafast, accurate, and scalable genome classification at all taxonomic levels Gurjit S. Randhawa1* , Kathleen A. Hill2 and Lila Kari3 Abstract Background: Although software tools abound for the comparison, analysis, identification, and classification of genomic sequences, taxonomic classification remains challenging due to the magnitude of the datasets and the intrinsic problems associated with classification. The need exists for an approach and software tool that addresses the limitations of existing alignment-based methods, as well as the challenges of recently proposed alignment-free methods. Results: We propose a novel combination of supervised Machine Learning with Digital Signal Processing, resulting in ML-DSP: an alignment-free software tool for ultrafast, accurate, and scalable genome classification at all taxonomic levels. We test ML-DSP by classifying 7396 full mitochondrial genomes at various taxonomic levels, from kingdom to genus, with an average classification accuracy of > 97%. A quantitative comparison with state-of-the-art classification software tools is performed, on two small benchmark datasets and one large 4322 vertebrate mtDNA genomes dataset. Our results show that ML-DSP overwhelmingly outperforms the alignment-based software MEGA7 (alignment with MUSCLE or CLUSTALW) in terms of processing time, while having comparable classification accuracies for small datasets and superior accuracies for the large dataset. Compared with the alignment-free software FFP (Feature Frequency Profile), ML-DSP has significantly better classification accuracy, and is overall faster. We also provide preliminary experiments indicating the potential of ML-DSP to be used for other datasets, by classifying 4271 complete dengue virus genomes into subtypes with 100% accuracy, and 4,710 bacterial genomes into phyla with 95.5% accuracy. -
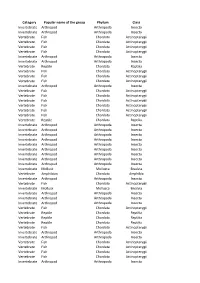
Category Popular Name of the Group Phylum Class Invertebrate
Category Popular name of the group Phylum Class Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate Reptile Chordata Reptilia Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Fish Chordata Actinopterygii Vertebrate Reptile Chordata Reptilia Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Mollusk Mollusca Bivalvia Vertebrate Amphibian Chordata Amphibia Invertebrate Arthropod Arthropoda Insecta Vertebrate Fish Chordata Actinopterygii Invertebrate Mollusk Mollusca Bivalvia Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Invertebrate Arthropod Arthropoda Insecta Vertebrate -

Occasional Papers of the Museum of Zoology the University of Michigan
OCCASIONAL PAPERS OF THE MUSEUM OF ZOOLOGY THE UNIVERSITY OF MICHIGAN DISCHERODONTUS, A NEW GENUS OF CYPRINID FISHES FROM SOUTHEASTERN ASIA ABSTRACT.-Rainboth, WalterJohn. 1989. Discherodontus, a new genw of cyprinid firhes from southeastern Asia. Occ. Pap. Mzcs. 2001. Univ. Michigan, 718:I-31, figs. 1-6. Three species of southeast Asian barbins were found to have two rows of pharyngeal teeth, a character unique among barbins. These species also share several other characters which indicate their close relationship, and allow the taxonomic recognition of the genus. Members of this new genus, Discherodontzcs, are found in the Mekong, Chao Phrya, and Meklong basins of Thailand and the Pahang basin of the Malay peninsula. The new genus appears to be most closely related to Chagunizcs of Burma and India, and a group of at least six genera of the southeast Asia-Sunda Shelf basins. Key words: Discherodontus, fihes, Cyprinidae, taxonomy, natural history, Southemt Asia. INTRODUCTION Among the diverse array of barbins of southern and southeastern Asia, there are a number of generic-ranked groups which are poorly understood, or which still await taxonomic recognition. One group of three closely related species, included until now in two genera, is the subject of this paper. Prior to this study, two of the three species in this new genus have been relegated to Puntius of Hamilton (1822), but as understood by Weber and de Beaufort (1916), and by Smith (1945). The remaining species has been placed in Acrossocheilus not of *Department of Biology, University of California (UCLA), Los Angeles, CA 90024 2 Walter J. -

Inventory of Fishes in the Upper Pelus River (Perak River Basin, Perak, Malaysia)
13 4 315 Ikhwanuddin et al ANNOTATED LIST OF SPECIES Check List 13 (4): 315–325 https://doi.org/10.15560/13.4.315 Inventory of fishes in the upper Pelus River (Perak river basin, Perak, Malaysia) Mat Esa Mohd Ikhwanuddin,1 Mohammad Noor Azmai Amal,1 Azizul Aziz,1 Johari Sepet,1 Abdullah Talib,1 Muhammad Faiz Ismail,1 Nor Rohaizah Jamil2 1 Department of Biology, Faculty of Science, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia. 2 Department of Environmental Sciences, Faculty of Environmental Studies, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia. Corresponding author: Mohammad Noor Azmai Amal, [email protected] Abstract The upper Pelus River is located in the remote area of the Kuala Kangsar district, Perak, Malaysia. Recently, the forest along the upper portion of the Pelus River has come under threat due to extensive lumbering and land clearing for plantations. Sampling at 3 localities in the upper Pelus River at 457, 156 and 89 m above mean sea level yielded 521 specimens representing 4 orders, 11 families, 23 genera and 26 species. The most abundant species was Neolissochilus hexagonolepis, followed by Homalopteroides tweediei and Glyptothorax major. The fish community structure indices was observed to increase from the upper to lower portion of the river, which might reflect differences in water velocity. Key words Faunal inventory; freshwater; species diversity; tropical forest. Academinc editor: Barbára Calegari | Received 28 July 2015 | Accepted 27 June 2017 | Published 18 August 2017 Citation: Ikhwanuddin MEM, Amal MNA, Aziz A, Sepet J, Talib A, Ismail MS, Jamil NR (2017). Inventory of fishes in the upper Pelus River (Perak river basin, Perak, Malaysia). -

Viet Nam Ramsar Information Sheet Published on 16 October 2018
RIS for Site no. 2360, Van Long Wetland Nature Reserve, Viet Nam Ramsar Information Sheet Published on 16 October 2018 Viet Nam Van Long Wetland Nature Reserve Designation date 10 February 2017 Site number 2360 Coordinates 20°23'35"N 105°51'10"E Area 2 736,00 ha https://rsis.ramsar.org/ris/2360 Created by RSIS V.1.6 on - 16 October 2018 RIS for Site no. 2360, Van Long Wetland Nature Reserve, Viet Nam Color codes Fields back-shaded in light blue relate to data and information required only for RIS updates. Note that some fields concerning aspects of Part 3, the Ecological Character Description of the RIS (tinted in purple), are not expected to be completed as part of a standard RIS, but are included for completeness so as to provide the requested consistency between the RIS and the format of a ‘full’ Ecological Character Description, as adopted in Resolution X.15 (2008). If a Contracting Party does have information available that is relevant to these fields (for example from a national format Ecological Character Description) it may, if it wishes to, include information in these additional fields. 1 - Summary Summary Van Long Wetland Nature Reserve is a wetland comprised of rivers and a shallow lake with large amounts of submerged vegetation. The wetland area is centred on a block of limestone karst that rises abruptly from the flat coastal plain of the northern Vietnam. It is located within the Gia Vien district of Ninh Binh Province. The wetland is one of the rarest intact lowland inland wetlands remaining in the Red River Delta, Vietnam. -

Minnows and Molecules: Resolving the Broad and Fine-Scale Evolutionary Patterns of Cypriniformes
Minnows and molecules: resolving the broad and fine-scale evolutionary patterns of Cypriniformes by Carla Cristina Stout A dissertation submitted to the Graduate Faculty of Auburn University in partial fulfillment of the requirements for the Degree of Doctor of Philosophy Auburn, Alabama May 7, 2017 Keywords: fish, phylogenomics, population genetics, Leuciscidae, sequence capture Approved by Jonathan W. Armbruster, Chair, Professor of Biological Sciences and Curator of Fishes Jason E. Bond, Professor and Department Chair of Biological Sciences Scott R. Santos, Professor of Biological Sciences Eric Peatman, Associate Professor of Fisheries, Aquaculture, and Aquatic Sciences Abstract Cypriniformes (minnows, carps, loaches, and suckers) is the largest group of freshwater fishes in the world. Despite much attention, previous attempts to elucidate relationships using molecular and morphological characters have been incongruent. The goal of this dissertation is to provide robust support for relationships at various taxonomic levels within Cypriniformes. For the entire order, an anchored hybrid enrichment approach was used to resolve relationships. This resulted in a phylogeny that is largely congruent with previous multilocus phylogenies, but has much stronger support. For members of Leuciscidae, the relationships established using anchored hybrid enrichment were used to estimate divergence times in an attempt to make inferences about their biogeographic history. The predominant lineage of the leuciscids in North America were determined to have entered North America through Beringia ~37 million years ago while the ancestor of the Golden Shiner (Notemigonus crysoleucas) entered ~20–6 million years ago, likely from Europe. Within Leuciscidae, the shiner clade represents genera with much historical taxonomic turbidity. Targeted sequence capture was used to establish relationships in order to inform taxonomic revisions for the clade. -

Native Fish of Conservation Concern in Hong Kong (Part 1)
NATIVE FISH OF CONSERVATION CONCERN IN HONG KONG (PART 1) February 2019 Native Fish of Conservation Concern in Hong Kong (Part 1) Native Fish of Conservation Concern in Hong Kong (Part 1) February 2019 Authors CHENG Hung Tsun & Tony NIP Editors Tony NIP & Gary ADES Contents Contents .......................................................................................................................................... 2 1. Background and Introduction .................................................................................................. 3 2. Methodology ........................................................................................................................... 3 3. Results .................................................................................................................................... 4 4. References .............................................................................................................................. 4 Figure 1. A Hong Kong map with 1 km2 grid lines. ......................................................................... 6 Appendix 1: Anguilla japonica ....................................................................................................... 7 Appendix 2: Anguilla marmorata .................................................................................................. 12 Appendix 3: Acrossocheilus beijiangensis ..................................................................................... 17 Appendix 4: Acrossocheilus parallens ......................................................................................... -

Comparative Phylogeography of Two Codistributed Endemic Cyprinids in Southeastern Taiwan
Biochemical Systematics and Ecology 70 (2017) 283e290 Contents lists available at ScienceDirect Biochemical Systematics and Ecology journal homepage: www.elsevier.com/locate/biochemsyseco Comparative phylogeography of two codistributed endemic cyprinids in southeastern Taiwan Tzen-Yuh Chiang a, 1, Yi-Yen Chen a, 1, Teh-Wang Lee b, Kui-Ching Hsu c, * Feng-Jiau Lin d, Wei-Kuang Wang e, Hung-Du Lin f, a Department of Life Sciences, Cheng Kung University, Tainan 701, Taiwan b Taiwan Endemic Species Research Institute, ChiChi, Nantou 552, Taiwan c Department of Industrial Management, National Taiwan University of Science and Technology, Taipei 10607, Taiwan d Tainan Hydraulics Laboratory, National Cheng Kung University, Tainan 709, Taiwan e Department of Environmental Engineering and Science, Feng Chia University, Taichung 407, Taiwan f The Affiliated School of National Tainan First Senior High School, Tainan 701, Taiwan article info abstract Article history: Two cyprinid fishes, Spinibarbus hollandi and Onychostoma alticorpus, are endemic to Received 12 October 2016 southeastern Taiwan. This study examined the phylogeography of these two codistributed Received in revised form 3 December 2016 primary freshwater fishes using mitochondrial DNA cytochrome b sequences (1140 bp) to Accepted 18 December 2016 search for general patterns in the effect of historical changes in southeastern Taiwan. In total, 135 specimens belonging to these two species were collected from five populations. These two codistributed species revealed similar genetic variation patterns. The genetic Keywords: variation in both species was very low, and the geographical distribution of the genetic Spinibarbus hollandi Onychostoma alticorpus variation corresponded neither to the drainage structure nor to the geographical distances Mitochondrial between the samples. -

Evolutionary Trends of the Pharyngeal Dentition in Cypriniformes (Actinopterygii: Ostariophysi)
Evolutionary trends of the pharyngeal dentition in Cypriniformes (Actinopterygii: Ostariophysi). Emmanuel Pasco-Viel, Cyril Charles, Pascale Chevret, Marie Semon, Paul Tafforeau, Laurent Viriot, Vincent Laudet To cite this version: Emmanuel Pasco-Viel, Cyril Charles, Pascale Chevret, Marie Semon, Paul Tafforeau, et al.. Evolution- ary trends of the pharyngeal dentition in Cypriniformes (Actinopterygii: Ostariophysi).. PLoS ONE, Public Library of Science, 2010, 5 (6), pp.e11293. 10.1371/journal.pone.0011293. hal-00591939 HAL Id: hal-00591939 https://hal.archives-ouvertes.fr/hal-00591939 Submitted on 31 May 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Evolutionary Trends of the Pharyngeal Dentition in Cypriniformes (Actinopterygii: Ostariophysi) Emmanuel Pasco-Viel1, Cyril Charles3¤, Pascale Chevret2, Marie Semon2, Paul Tafforeau4, Laurent Viriot1,3*., Vincent Laudet2*. 1 Evo-devo of Vertebrate Dentition, Institut de Ge´nomique Fonctionnelle de Lyon, Universite´ de Lyon, CNRS, INRA, Ecole Normale Supe´rieure de Lyon, Lyon, France, 2 Molecular Zoology, Institut de Ge´nomique Fonctionnelle de Lyon, Universite´ de Lyon, CNRS, INRA, Ecole Normale Supe´rieure de Lyon, Lyon, France, 3 iPHEP, CNRS UMR 6046, Universite´ de Poitiers, Poitiers, France, 4 European Synchrotron Radiation Facility, Grenoble, France Abstract Background: The fish order Cypriniformes is one of the most diverse ray-finned fish groups in the world with more than 3000 recognized species. -

Two New Species of Shovel-Jaw Carp Onychostoma (Teleostei: Cyprinidae) from Southern Vietnam
Zootaxa 3962 (1): 123–138 ISSN 1175-5326 (print edition) www.mapress.com/zootaxa/ Article ZOOTAXA Copyright © 2015 Magnolia Press ISSN 1175-5334 (online edition) http://dx.doi.org/10.11646/zootaxa.3962.1.6 http://zoobank.org/urn:lsid:zoobank.org:pub:5872B302-2C4E-4102-B6EC-BC679B3645D4 Two new species of shovel-jaw carp Onychostoma (Teleostei: Cyprinidae) from southern Vietnam HUY DUC HOANG1, HUNG MANH PHAM1 & NGAN TRONG TRAN1 1Viet Nam National University Ho Chi Minh city-University of Science, Faculty of Biology, 227 Nguyen Van Cu, District 5, Ho Chi Minh City, Vietnam. E-mail: [email protected] Corresponding author: Huy D. Hoang: [email protected] Abstract Two new species of large shovel-jaw carps in the genus Onychostoma are described from the upper Krong No and middle Dong Nai drainages of the Langbiang Plateau in southern Vietnam. These new species are known from streams in montane mixed pine and evergreen forests between 140 and 1112 m. Their populations are isolated in the headwaters of the upper Sre Pok River of the Mekong basin and in the middle of the Dong Nai basin. Both species are differentiated from their congeners by a combination of the following characters: transverse mouth opening width greater than head width, 14−17 predorsal scales, caudal-peduncle length 3.9−4.2 times in SL, no barbels in adults and juveniles, a strong serrated last sim- ple ray of the dorsal fin, and small eye diameter (20.3−21.5% HL). Onychostoma krongnoensis sp. nov. is differentiated from Onychostoma dongnaiensis sp. nov.