Augmenting Hand Animation with Three-Dimensional Secondary Motion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UPA : Redesigning Animation
This document is downloaded from DR‑NTU (https://dr.ntu.edu.sg) Nanyang Technological University, Singapore. UPA : redesigning animation Bottini, Cinzia 2016 Bottini, C. (2016). UPA : redesigning animation. Doctoral thesis, Nanyang Technological University, Singapore. https://hdl.handle.net/10356/69065 https://doi.org/10.32657/10356/69065 Downloaded on 05 Oct 2021 20:18:45 SGT UPA: REDESIGNING ANIMATION CINZIA BOTTINI SCHOOL OF ART, DESIGN AND MEDIA 2016 UPA: REDESIGNING ANIMATION CINZIA BOTTINI School of Art, Design and Media A thesis submitted to the Nanyang Technological University in partial fulfillment of the requirement for the degree of Doctor of Philosophy 2016 “Art does not reproduce the visible; rather, it makes visible.” Paul Klee, “Creative Credo” Acknowledgments When I started my doctoral studies, I could never have imagined what a formative learning experience it would be, both professionally and personally. I owe many people a debt of gratitude for all their help throughout this long journey. I deeply thank my supervisor, Professor Heitor Capuzzo; my cosupervisor, Giannalberto Bendazzi; and Professor Vibeke Sorensen, chair of the School of Art, Design and Media at Nanyang Technological University, Singapore for showing sincere compassion and offering unwavering moral support during a personally difficult stage of this Ph.D. I am also grateful for all their suggestions, critiques and observations that guided me in this research project, as well as their dedication and patience. My gratitude goes to Tee Bosustow, who graciously -

Motion Enriching Using Humanoide Captured Motions
MASTER THESIS: MOTION ENRICHING USING HUMANOIDE CAPTURED MOTIONS STUDENT: SINAN MUTLU ADVISOR : A NTONIO SUSÌN SÀNCHEZ SEPTEMBER, 8TH 2010 COURSE: MASTER IN COMPUTING LSI DEPERTMANT POLYTECNIC UNIVERSITY OF CATALUNYA 1 Abstract Animated humanoid characters are a delight to watch. Nowadays they are extensively used in simulators. In military applications animated characters are used for training soldiers, in medical they are used for studying to detect the problems in the joints of a patient, moreover they can be used for instructing people for an event(such as weather forecasts or giving a lecture in virtual environment). In addition to these environments computer games and 3D animation movies are taking the benefit of animated characters to be more realistic. For all of these mediums motion capture data has a great impact because of its speed and robustness and the ability to capture various motions. Motion capture method can be reused to blend various motion styles. Furthermore we can generate more motions from a single motion data by processing each joint data individually if a motion is cyclic. If the motion is cyclic it is highly probable that each joint is defined by combinations of different signals. On the other hand, irrespective of method selected, creating animation by hand is a time consuming and costly process for people who are working in the art side. For these reasons we can use the databases which are open to everyone such as Computer Graphics Laboratory of Carnegie Mellon University. Creating a new motion from scratch by hand by using some spatial tools (such as 3DS Max, Maya, Natural Motion Endorphin or Blender) or by reusing motion captured data has some difficulties. -

Computerising 2D Animation and the Cleanup Power of Snakes
Computerising 2D Animation and the Cleanup Power of Snakes. Fionnuala Johnson Submitted for the degree of Master of Science University of Glasgow, The Department of Computing Science. January 1998 ProQuest Number: 13818622 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 13818622 Published by ProQuest LLC(2018). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 GLASGOW UNIVERSITY LIBRARY U3 ^coji^ \ Abstract Traditional 2D animation remains largely a hand drawn process. Computer-assisted animation systems do exists. Unfortunately the overheads these systems incur have prevented them from being introduced into the traditional studio. One such prob lem area involves the transferral of the animator’s line drawings into the computer system. The systems, which are presently available, require the images to be over- cleaned prior to scanning. The resulting raster images are of unacceptable quality. Therefore the question this thesis examines is; given a sketchy raster image is it possible to extract a cleaned-up vector image? Current solutions fail to extract the true line from the sketch because they possess no knowledge of the problem area. -

The University of Chicago Looking at Cartoons
THE UNIVERSITY OF CHICAGO LOOKING AT CARTOONS: THE ART, LABOR, AND TECHNOLOGY OF AMERICAN CEL ANIMATION A DISSERTATION SUBMITTED TO THE FACULTY OF THE DIVISION OF THE HUMANITIES IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF CINEMA AND MEDIA STUDIES BY HANNAH MAITLAND FRANK CHICAGO, ILLINOIS AUGUST 2016 FOR MY FAMILY IN MEMORY OF MY FATHER Apparently he had examined them patiently picture by picture and imagined that they would be screened in the same way, failing at that time to grasp the principle of the cinematograph. —Flann O’Brien CONTENTS LIST OF FIGURES...............................................................................................................................v ABSTRACT.......................................................................................................................................vii ACKNOWLEDGMENTS....................................................................................................................viii INTRODUCTION LOOKING AT LABOR......................................................................................1 CHAPTER 1 ANIMATION AND MONTAGE; or, Photographic Records of Documents...................................................22 CHAPTER 2 A VIEW OF THE WORLD Toward a Photographic Theory of Cel Animation ...................................72 CHAPTER 3 PARS PRO TOTO Character Animation and the Work of the Anonymous Artist................121 CHAPTER 4 THE MULTIPLICATION OF TRACES Xerographic Reproduction and One Hundred and One Dalmatians.......174 -

Best Picture of the Yeari Best. Rice of the Ear
SUMMER 1984 SUP~LEMENT I WORLD'S GREATEST SELECTION OF THINGS TO SHOW Best picture of the yeari Best. rice of the ear. TERMS OF ENDEARMENT (1983) SHIRLEY MacLAINE, DEBRA WINGER Story of a mother and daughter and their evolving relationship. Winner of 5 Academy Awards! 30B-837650-Beta 30H-837650-VHS .............. $39.95 JUNE CATALOG SPECIAL! Buy any 3 videocassette non-sale titles on the same order with "Terms" and pay ONLY $30 for "Terms". Limit 1 per family. OFFER EXPIRES JUNE 30, 1984. Blackhawk&;, SUMMER 1984 Vol. 374 © 1984 Blackhawk Films, Inc., One Old Eagle Brewery, Davenport, Iowa 52802 Regular Prices good thru June 30, 1984 VIDEOCASSETTE Kew ReleMe WORLDS GREATEST SHE Cl ION Of THINGS TO SHOW TUMBLEWEEDS ( 1925) WILLIAMS. HART William S. Hart came to the movies in 1914 from a long line of theatrical ex perience, mostly Shakespearean and while to many he is the strong, silent Western hero of film he is also the peer of John Ford as a major force in shaping and developing this genre we enjoy, the Western. In 1889 in what is to become Oklahoma Territory the Cherokee Strip is just a graz ing area owned by Indians and worked day and night be the itinerant cowboys called 'tumbleweeds'. Alas, it is the end of the old West as the homesteaders are moving in . Hart becomes involved with a homesteader's daughter and her evil brother who has a scheme to jump the line as "sooners". The scenes of the gigantic land rush is one of the most noted action sequences in film history. -

Using Dragonframe 4.Pdf
Using DRAGONFRAME 4 Welcome Dragonframe is a stop-motion solution created by professional anima- tors—for professional animators. It's designed to complement how the pros animate. We hope this manual helps you get up to speed with Dragonframe quickly. The chapters in this guide give you the information you need to know to get proficient with Dragonframe: “Big Picture” on page 1 helps you get started with Dragonframe. “User Interface” on page 13 gives a tour of Dragonframe’s features. “Camera Connections” on page 39 helps you connect cameras to Drag- onframe. “Cinematography Tools” on page 73 and “Animation Tools” on page 107 give details on Dragonframe’s main workspaces. “Using the Timeline” on page 129 explains how to use the timeline in the Animation window to edit frames. “Alternative Shooting Techniques (Non Stop Motion)” on page 145 explains how to use Dragonframe for time-lapse. “Managing Your Projects and Files” on page 149 shows how to use Dragonframe to organize and manage your project. “Working with Audio Clips” on page 159 and “Reading Dialogue Tracks” on page 171 explain how to add an audip clip and create a track reading. “Using the X-Sheet” on page 187 explains our virtual exposure sheet. “Automate Lighting with DMX” on page 211 describes how to use DMX to automate lights. “Adding Input and Output Triggers” on page 241 has an overview of using Dragonframe to trigger events. “Motion Control” on page 249 helps you integrate your rig with the Arc Motion Control workspace or helps you use other motion control rigs. -

Authoring Motion Cycles
Authoring Motion Cycles Loïc Ciccone Martin Guay ETH Zurich Disney Research Zurich Maurizio Nitti Robert W. Sumner Disney Research Zurich ETH Zurich, Disney Research Zurich Figure 1: Left: To specify a motion cycle, the user acts out several loops of the motion using a variety of capture devices. Middle: A looping motion cycle is automatically extracted from the noisy performance. Right: A custom motion representation tool, called MoCurves, allows controlling and coordinating spatial and temporal transformations from a single viewport. ABSTRACT CCS CONCEPTS Motion cycles play an important role in animation production • Computing methodologies → Animation; Graphics systems and game development. However, creating motion cycles relies and interfaces; on general-purpose animation packages with complex interfaces that require expert training. Our work explores the specic chal- KEYWORDS lenges of motion cycle authoring and provides a system simple Motion cycles, Animation interface, Performance, Motion curves enough for novice animators while maintaining the exibility of control demanded by experts. Due to their cyclic nature, we show ACM Reference format: that performance animation provides a natural interface for mo- Loïc Ciccone, Martin Guay, Maurizio Nitti, and Robert W. Sumner. 2017. tion cycle specication. Our system allows the user to act several Authoring Motion Cycles. In Proceedings of ACM SIGGRAPH / Eurographics loops of motion using a variety of capture devices and automat- Symposium on Computer Animation, Los Angeles, California USA, July 2017 (SCA’17), 9 pages. ically extracts a looping cycle from this potentially noisy input. DOI: 10.475/123_4 Motion cycles for dierent character components can be authored in a layered fashion, or our method supports cycle extraction from higher-dimensional data for capture devices that deliver many de- 1 INTRODUCTION grees of freedom. -
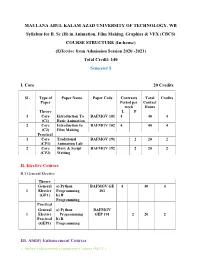
MAULANA ABUL KALAM AZAD UNIVERSITY of TECHNOLOGY, WB Syllabus for B. Sc (H) in Animation, Film Making, Graphics & VFX (CBCS)
MAULANA ABUL KALAM AZAD UNIVERSITY OF TECHNOLOGY, WB Syllabus for B. Sc (H) in Animation, Film Making, Graphics & VFX (CBCS) COURSE STRUCTURE (In-house) (Effective from Admission Session 2020 -2021) Total Credit: 140 Semester I I. Core 20 Credits SL Type of Paper Name Paper Code Contracts Total Credits Paper Period per Contact week Hours Theory L P 1 Core Introduction To BAFMGV 101 4 40 4 (C1) Basic Animation 2 Core Introduction to BAFMGV 102 4 40 4 (C2) Film Making Practical 1 Core Traditional BAFMGV 191 2 20 2 (CP1) Animation Lab 2 Core Story & Script BAFMGV 192 2 20 2 (CP2) Writing II. Elective Courses B.1 General Elective Theory General a) Python BAFMGV GE 4 40 4 1 Elective Programming 101 (GE1) b) R Programming Practical General a) Python BAFMGV 1 Elective Programming GEP 191 2 20 2 Practical b) R (GEP1) Programming III. Ability Enhancement Courses 1. Ability Enhancement Compulsory Courses (AECC) Theory Ability Communicative BAFMGV AECC 1 Enhance English I 101 2 20 2 ment Compuls ory Courses (AECC1) Semester II I. Core 20 Credits SL Type of Paper Name Paper Code Contracts Total Credits Paper Period per Contact week Hours L P Theory Introduction to BAFMGV 201 1 Core (C3) Graphic Design 4 40 4 & Visual Art Introduction to BAFMGV 202 2 Core (C4) 2D Animation 4 40 4 Practical Digital Design, 1 Core Info graphics & BAFMGV 291 2 20 2 (CP3) Branding (Adobe Photoshop, illustrator, Corel Draw) 2 Core 2D animation lab BAFMGV 292 2 20 2 (CP4) (Flash) II. Elective Courses B.1 General Elective Theory General a) Web Design BAFMGV 1 Elective b)Computer GE201 4 40 4 (GE2) Networks Practical General a) Webpage BAFMGV 1 Elective Design GEP291 2 20 2 Practical (GEP2) b)Networking Lab III. -

Multiple Dynamic Pivots Rig for 3D Biped Character Designed Along Human-Computer Interaction Principles
Multiple Dynamic Pivots Rig for 3D Biped Character Designed along Human-Computer Interaction Principles by Mihaela D. Petriu A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of the requirements for the degree of Master of Computer Science in Human-Computer Interaction Carleton University Ottawa, Ontario © 2020, Mihaela D. Petriu Abstract This thesis is addressing the design, implementation and usability testing of a modular extensible animator-centric authoring tool-independent 3D Multiple Dynamic Pivots (MDP) biped character rig. An objective of the thesis is to show that the design of the character rig must be independent of its platform, cater to the needs of the animation workflow based on HCI principles (particularly that of Direct Manipulation) and be modular and extensible in order to build and grow as needed within the production pipeline. In the thesis, the proposed rig design is implemented in Maya, the most widely used and taught commercial 3D animation authoring tool. Another thesis objective is to perform usability testing of the MDP rig with animation students and professionals, in order to gauge the new design’s intuitiveness for those relatively new to the trade and those already steeped in its decades of accumulated technical idiosyncrasies. ii Acknowledgements My deepest gratitude goes to my supervisor Dr. Chris Joslin for his constant guidance and support. I would also like to thank my family for their continuous help and encouragement. Finally, I thank my friend Sandra E. Hobbs for her constructive chaos that shed light on my design's weaknesses. iii Table of Contents Abstract ............................................................................................................................. -

Crisis Communication Effectiveness in The
©2008 Gina M. Serafin ALL RIGHTS RESERVED MEDIA MINDFULNESS: DEVELOPING THE ABILITY AND MOTIVATION TO PROCESS ADVERTISEMENTS by GINA MARCELLO-SERAFIN A Dissertation submitted to the Graduate School-New Brunswick Rutgers, The State University of New Jersey in partial fulfillment of the requirements for the degree of Doctor of Philosophy Graduate Program in Communication, Information and Library Studies written under the direction of Professor Robert Kubey and approved by _________________________________ _________________________________ _________________________________ _________________________________ New Brunswick, New Jersey May, 2008 ABSTRACT OF THE DISSERTATION Media Mindfulness: Developing the Motivation and Ability to Process Advertisements by GINA M. SERAFIN Dissertation Director: Robert Kubey The present study utilized the theories of flow, mindfulness, and the elaboration likelihood model of persuasion to explore which factors may influence the cognitive processing of advertisements by students who participated in a five-week media education curriculum. The purpose of this study was to determine if students who participated in a media education curriculum that focused on advertising differed in their cognitive processing, attitudes, and knowledge of advertisements from students who did not participate in the curriculum. Participants were eighth grade middle school students from an affluent community in Morris County, New Jersey. Differences in attitudes, number of thoughts, and knowledge were investigated. A grounded theory approach was used to analyze student thought listings. The results showed that students who participated in the media education curriculum were more mindful of their advertising consumption. Additionally, students had more positive attitudes toward advertising, language arts class, and working as a member of a team. Students who participated in the curriculum were also more knowledgeable about advertising. -

Video Puppetry: a Performative Interface for Cutout Animation
Video Puppetry: A Performative Interface for Cutout Animation Connelly Barnes1 David E. Jacobs2 Jason Sanders2 Dan B Goldman3 Szymon Rusinkiewicz1 Adam Finkelstein1 Maneesh Agrawala2 1Princeton University 2University of California, Berkeley 3Adobe Systems Figure 1: A puppeteer (left) manipulates cutout paper puppets tracked in real time (above) to control an animation (below). Abstract 1 Introduction Creating animated content is difficult. While traditional hand- We present a video-based interface that allows users of all skill drawn or stop-motion animation allows broad expressive freedom, levels to quickly create cutout-style animations by performing the creating such animation requires expertise in composition and tim- character motions. The puppeteer first creates a cast of physical ing, as the animator must laboriously craft a sequence of frames puppets using paper, markers and scissors. He then physically to convey motion. Computer-based animation tools such as Flash, moves these puppets to tell a story. Using an inexpensive overhead Toon Boom and Maya provide sophisticated interfaces that allow camera our system tracks the motions of the puppets and renders precise and flexible control over the motion. Yet, the cost of pro- them on a new background while removing the puppeteer’s hands. viding such control is a complicated interface that is difficult to Our system runs in real-time (at 30 fps) so that the puppeteer and learn. Thus, traditional animation and computer-based animation the audience can immediately see the animation that is created. Our tools are accessible only to experts. system also supports a variety of constraints and effects including Puppetry, in contrast, is a form of dynamic storytelling that per- articulated characters, multi-track animation, scene changes, cam- 1 formers of all ages and skill levels can readily engage in. -

Animation of a High-Definition 2D Fighting Game Character
Tuula Rantala ANIMATION OF A HIGH-DEFINITION 2D FIGHTING GAME CHARACTER Thesis Kajaani University of Applied Sciences School of Business Business Information Technology Spring 2013 OPINNÄYTETYÖ TIIVISTELMÄ Koulutusala Koulutusohjelma Luonnontieteiden ala Tietojenkäsittely Tekijä(t) Tuula Rantala Työn nimi Teräväpiirtoisen 2d-taistelupelihahmon animointi Vaihtoehtoisetvaihtoehtiset ammattiopinnot Ohjaaja(t) Peligrafiikka Nick Sweetman Toimeksiantaja - Aika Sivumäärä ja liitteet Kevät 2013 56 Tämä opinnäytetyö pyrkii erittelemään hyvän pelihahmoanimaation periaatteita ja tarkastelee eri lähestymistapoja 2d-animaation luomiseen. Perinteisen animaation periaatteet, kuten ajoitus ja liikkeen välistys, pätevät pelianimaa- tiossa samalla tavalla kuin elokuva-animaatiossakin. Pelien tekniset rajoitukset ja interaktiivisuus asettavat kuiten- kin lisähaasteita animaatioiden toteuttamiseen tavalla, joka sekä tukee pelimekaniikkaa että on visuaalisesti kiin- nostava. Vetoava hahmoanimaatio on erityisen tärkeää taistelupeligenressä. Varhaiset taistelupelit 1990–luvun alusta käyt- tivät matalaresoluutioista bittikarttagrafiikkaa ja niissä oli alhainen määrä animaatiokehyksiä, mutta nykyään pelien standardit grafiikan ja animaation suhteen ovat korkealla. Viime vuosina monet pelinkehittäjät ovat siirtyneet käyttämään 2d-grafiikan sijasta 3d-grafiikkaa, koska 3d-animaation tuottaminen on monella tavalla joustavampaa. Perinteiselle 2d-grafiikalle on kuitenkin edelleen kysyntää, sillä käsin piirretyn animaation ainutlaatuista ulkoasua ei voi täysin korvata