Ji Н Hana Two-Level Morphology of Esperanto
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparison Between Natural and Planned Languages
UvA-DARE (Digital Academic Repository) The Case of Correlatives: A Comparison between Natural and Planned Languages Gobbo, F. Publication date 2011 Document Version Final published version Published in Journal of Universal Language Link to publication Citation for published version (APA): Gobbo, F. (2011). The Case of Correlatives: A Comparison between Natural and Planned Languages. Journal of Universal Language, 12(2), 45-79. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:28 Sep 2021 Federico Gobbo 45 Journal of Universal Language 12-2 September 2011, 45-79 The Case of Correlatives: A Comparison between Natural and Planned Languages Federico Gobbo University of Insubria 1 Abstract Since the publication of Volapük, the most important functional and deictic words present in grammar—interrogative, relative and demonstrative pronouns, and adjectives among others—have been described in planned grammars in a series or a table, namely “correlatives,” showing a considerable level of regularity. -
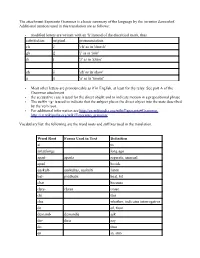
The Attachment Esperanto Grammar Is a Basic Summary of the Language by the Inventor Zamenhof
The attachment Esperanto Grammar is a basic summary of the language by the inventor Zamenhof. Additional nuances used in this translation are as follows: • modified letters are written with an 'h' instead of the diacritical mark, thus substitution original pronounciation ch ĉ 'ch' as in 'church' gh ĝ 'j' as in 'join' jh ĵ 'z' as in 'azure' sh ŝ 'sh' as in 'show' u ŭ 'u' as in 'mount' • Most other letters are pronouncable as if in English, at least for the relay. See part A of the Grammar attachment. • the accusative case is used for the direct objekt and to indicate motion in a prepositional phrase. • The suffix -ig- is used to indicate that the subject places the direct object into the state described by the verb root. • For additional information see http://en.wikipedia.org/wiki/Esperanto#Grammar http://en.wikipedia.org/wiki/Esperanto_grammar Vocabulary list: the following are the word roots and suffixes used in the translation. Word Root Forms Used in Text Definition al to antaulonge long ago apart- aparta separate, unusual apud beside auskult- auskultas, auskulti listen bat- piedbatis beat, hit char because ches- chesu cease chi this chu whether; indicates interrogative de of, from demand- demandis ask dir- diris say do thus en in, into Word Root Forms Used in Text Definition fakt- fakte fact, (fakte: in fact) far- fari to do ghen- ghenas bother ghi ghin it halt- haltu stop histori- historio stoty jhet- jhetis throw kaj and kiam when kiel how koler- kolerigis anger konsent- konsentas agree kvazau as if la the lag- lago, lagon lake -

A Complex Structure. a Linguistic Description of Esperanto in Functional Discourse Grammar
Interdisciplinary Description of Complex Systems 13(2), 275-287, 2015 GRAMMAR: A COMPLEX STRUCTURE. A LINGUISTIC DESCRIPTION OF ESPERANTO IN FUNCTIONAL DISCOURSE GRAMMAR Wim Jansen* Chair of Interlinguistics and Esperanto, University of Amsterdam Amsterdam, Netherlands DOI: 10.7906/indecs.13.2.11 Received: 1 February 2014. Regular article Accepted: 17 June 2014. ABSTRACT Functional Discourse-Grammar or FDG is the latest development in the functional grammar that was initiated by the Dutch linguist Simon Dik (1940-1995). In this paper, the FDG architecture proper is described, including the role of the extra-grammatical conceptual and contextual components. A simple interrogative clause in Esperanto is used to illustrate how a linguistic expression is built up from the formulation of its (pragmatic) intention to its articulation. Attention is paid to linguistic transparencies and opacities, defined here as the absence or presence of discontinuities between the descriptive levels in the grammar. Opacities are held accountable, among other factors, for making languages more or less easy to learn. The grammar of every human language is a complex system. This is clearly demonstrable precisely in Esperanto, in which the relatively few difficulties, identified by the opacities in the system, form such a sharp contrast to the general background of freedom, regularity and lack of exceptions. KEY WORDS Esperanto, functional grammar, linguistic transparency CLASSIFICATION JEL: O35 *Corresponding author, : [email protected]; ; *Emmaplein 17A, 2225 BK Katwijk, Netherlands * W. Jansen INTRODUCTION1 In the authoritative monolingual dictionary Plena Ilustrita Vortaro de Esperanto (PIV) 1, under the headword gramatiko (‘grammar’) we find several definitions. The first is ‘study of language rules’ (scienco pri la lingvaj reguloj); under this definition, ĝenerala gramatiko (‘general grammar’) is described as the ‘study of rules common to all languages’ (scienco pri la reguloj komunaj al ĉiuj lingvoj). -

Theosophical Review V38 N227 Jul 1906
THE THEOSOPHICAL REVIEW Vol. XXXVIII JULY, 19o6 No. 227 ON THE WATCH-TOWER Yet another Theosophical Congress to add to the long list 1 The recent Paris Congress of the Federation of the European Sections of the Theosophical Society has come and &one, ant* a pleasant memory of the Congress ^ warm hospitality of our French hosts, of splendid weather, a charming place of meeting, and excellent arrangements. The Congress was presided over by our vener able President-Founder, Colonel H. S. Olcott ; who, however, was unfortunately prevented from taking the chair at the final meeting owing to a sudden indisposition which caused us much anxiety and brought home to us the enormous value of his life to the movement. We have so long been used to consider our " " President as the official permanent atom of the Society, and have such confidence in his extraordinarily robust vitality, that his sudden and serious indisposition came to all as a great shock. Fortunately he has rallied rapidly, and though unable to attend the Dutch Convention, is almost restored to health. May the Gods grant him lustra still to add to the number of his years, for we can ill spare him ! 386 THE THEOSOPHICAL REVIEW The Paris Congress was a truly international gathering. Rus sians, Swedes, Czechs, Italians, Spaniards, Swiss, Belgians, Dutch, English, Germans, Americans, a Hindu An and a Parsi, together and regretted (Lnt'rn^tional mingled the consequences of the Tower of Babel inci dent. A "universal language" was badly needed; Esperanto, it is true, was on the programme for discussion, but the Theo- sophical Greeks are as yet shy of its barbarisms. -

University of Northern Iowa
University of Northern Iowa Esperanto Source: The North American Review, Vol. 184, No. 608 (Feb. 1, 1907), pp. xvii-xxxii Published by: University of Northern Iowa Stable URL: http://www.jstor.org/stable/25105787 Accessed: 13-02-2015 22:42 UTC Your use of the JSTOR archive indicates your acceptance of the Terms & Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. University of Northern Iowa is collaborating with JSTOR to digitize, preserve and extend access to The North American Review. http://www.jstor.org This content downloaded from 165.193.178.94 on Fri, 13 Feb 2015 22:42:34 UTC All use subject to JSTOR Terms and Conditions ESPERANTO.* GRAMMAR.?LESSON IV. Numerals.?The Cardinal numbers are:? Unu, 1: du, 2; tri, 3; levar, 4; levin, 5; ses, 6; sep, 7; oi;, 8; na?, 9 ; de??, 10 ; cent, 100 ; mil, 1,000 ; miliono, 1,000,000. From these all other numbers are formed, thus:? Dele unu, 11; dele sep, 17; dudele, 20; oledele, 80; tridele du, 32; sepdele levin, 75; na?dele nail, 99; ducent, 200; olecent, 800; tricent dudele ole, 328; rai7 olecent sepdele du, 1872. Ordinals are formed by adding -a to the above. Unu-a, first; M'-a^ third; ?Ze/?;-a^ tenth. -

The Esperantist Background of René De Saussure's Work
Chapter 1 The Esperantist background of René de Saussure’s work Marc van Oostendorp Radboud University and The Meertens Institute ené de Saussure was arguably more an esperantist than a linguist – R somebody who was primarily inspired by his enthusiasm for the language of L. L. Zamenhof, and the hope he thought it presented for the world. His in- terest in general linguistics seems to have stemmed from his wish to show that the structure of Esperanto was better than that of its competitors, and thatit reflected the ways languages work in general. Saussure became involved in the Esperanto movement around 1906, appar- ently because his brother Ferdinand had asked him to participate in an inter- national Esperanto conference in Geneva; Ferdinand himself did not want to go because he did not want to become “compromised” (Künzli 2001). René be- came heavily involved in the movement, as an editor of the Internacia Scienca Re- vuo (International Science Review) and the national journal Svisa Espero (Swiss Hope), as well as a member of the Akademio de Esperanto, the Academy of Es- peranto that was and is responsible for the protection of the norms of the lan- guage. Among historians of the Esperanto movement, he is also still known as the inventor of the spesmilo, which was supposed to become an international currency among Esperantists (Garvía 2015). At the time, the interest in issues of artificial language solutions to perceived problems in international communication was more widespread in scholarly cir- cles than it is today. In the western world, German was often used as a language of e.g. -

The Sixteen Rules of Esperanto Grammar Commented by Don Harlow
The Sixteen Rules of Esperanto Grammar commented by Don Harlow -------------------------------------------------------------------------------- Copyright Notice This material is copyright © 1995 by Donald J. Harlow. Hard copies may be made for personal use only. Any user may make one electronic copy for personal use only. All copies must contain this copyright notice, including the date given below. No electronic copy may be located elsewhere for public access. Links to this original copy on the World Wide Web are encouraged. Please respect the conditions of this copyright notice; I simply don't want to have various unofficial (and perhaps not up-to-date) copies floating around elsewhere. Date: 1995.09.11. [Edits noted in [square brackets], as well as other headings and formatting by Doug Bigham , 2005, for LIN 312.] [NOTE: The Swadesh vocabulary list (above) contains an Esperanto column.] -------------------------------------------------------------------------------- The Rules 1. Articles 2. Nouns 3. Adjectives 4. Numerals 5. Pronouns 6. Verbs 7. Adverbs 8. Prepositions 9. Pronunciation 10. Accent 11. Compound Words 12. Negatives 13. Direction 14. The Multipurpose Preposition 15. Borrowing Words 16. Elision -------------------------------------------------------------------------------- In the following, [(parenthesized)] expressions are [Harlow's] interpolations. Indented notes are commentary by [Harlow]. EXAMPLES are introduced by [Harlow], and are as shown. -------------------------------------------------------------------------------- 1. ARTICLES There is no indefinite ARTICLE (English a, an); there is only a definite article la, alike for all genders, cases and numbers (English the). Author's note: The use of the article is as in other languages. People for whom use of the article offers difficulties (e.g. speakers of Russian, Chinese, etc.)may at first elect not to use it at all. -

Eenzijdig Rapport 2007
Virgo Sapientiae Instituut An artificial language Esperanto Justine Mercier 2016-2017 6 Latin Modern-Languages Promoter: Mr. Ives Delporte Mentor: Mrs. Ulrike Houwenhuyse An artificial language Esperanto PREFACE As part of my sixth year in high school, I got the task to write a paper about any random subject. For me, it was a mission to choose an unfamiliar topic. This way I would be able to teach myself something foreign and spread the new knowledge. After the reflection of several options, I have chosen for the artificial and almost forgotten language Esperanto. Having decided on Esperanto as my theme, I was full of excitement to start writing about one of my interests, languages. In that way, it would be feasible for me to learn new things that could enrich my knowledge and could help me in the development of some new perspectives. My study selection has contributed to the choice of writing in English. Next year, I am willing to study applied languages English-Chinese. Therefore I see this as the excellent opportunity to refine my English. All of this would not have been possible without the help of Mr. Ives Delporte. He has given me a lot of advice about the language and the content of my work. My mentor, Mrs. Ulrike Houwenhuyse, on the other hand, has been able to assist me with the structural layout in order to handle a neat style. The next one I would like to thank is Mr. Cyreen Marcel Knockaert. As a board member of the Flemish Federation of Esperanto, voluntary librarian of the Flemish Federation of Esperanto and voluntary contributor of the Library of Heritage from Hendrik Conscience, he has taken his time to formulate an elaborate answer to all my questions. -

Guide to the Norman A. Mcquown Papers 1850-2004
University of Chicago Library Guide to the Norman A. McQuown Papers 1850-2004 © 2018 University of Chicago Library Table of Contents Descriptive Summary 4 Information on Use 4 Access 4 Citation 5 Biographical Note 5 Scope Note 7 Related Resources 10 Subject Headings 11 INVENTORY 11 Series I: Personal and Biographical 11 Subseries 1: Biographical 11 Subseries 2: Correspondence 15 Subseries 3: General files 18 Subseries 4: Clippings, related publications, and personal card catalog 19 Series II: Correspondence and Subject files 23 Series III: Writing 248 Subseries 1: Writings, translations, and language notes 249 Subseries 2: Instructional Texts 295 Series IV: Research 309 Subseries 1: Archival Research 310 Subseries 2: Computing 313 Subseries 3: Central American Languages 325 Subseries 4: Mayan languages – projects and general resources 351 Subseries 5: Mayan languages – writings by others 356 Subseries 6: Turkish 375 Subseries 7: Card file boxes 379 Series V: Chiapas Projects 385 Subseries 1: Field work and research 386 Subseries 2: Correspondence 413 Subseries 3: Writing 420 Series VI: Teaching 458 Series VII: Manuel Andrade Papers 475 Subseries 1: Correspondence 475 Subseries 2: Writings 478 Subseries 3: Research and texts 482 Series VIII: Writings by Others 505 Series IX: Audiovisual 687 Subseries 1: Audio and video recordings 688 Subseries 2: Microfilm and microfiche 689 Subseries 3: Negatives and Photographs 689 Subseries 4: Slides 696 Subseries 5: Magnetic computer data tapes and floppy disks 732 Series X: Oversize 733 Series XI: -

An Esperanto Grammar
: : —: MISCELLANEOUS. 445 private in the Fifteenth New Hampshire Volunteers. Later he was made chaplain and as such accompanied his regiment to New Orleans. There, in connection with Rev. George H. Hcpworth, he was commissioned as a Lieu- tenant and detailed by General Banks to investigate complaints of abuse and ill-treatment toward plantation negroes, and subsequently was commissioned as active member of the military board to establish Freedmen's Schools in Louisiana. The war ending, Mr. Wheelock moved with his family to Texas. Here he occupied a number of important public trusts, being at one time State Superintendent of Public Instruction, at another Superintendent of the State Institute for the Blind. For several years he was Reporter of the State Supreme Court. In 1887, Mr. Wheelock organized a Unitarian Society in Spokane, Wash- ington, and for two years served as its minister. He then returned to Texas and not long after began his pastorate of the Unitarian movement in Austin. He continued in that work for eight years, when the gathering infirmities of age compelled his resignation. His death occurred two years later. Striking of person, endowed with an intellect in which the poetic and the practical mingled in rare combination, master of an eloquence which made his discourses models of impressiveness and beauty, the author of Proteus might have graced a distinguished pulpit and achieved a conspicuous place in litera- ture; but he was of a retiring disposition and unambitious of applause, traits of character deepened by the mysticism which throughout his life held for him so rich a charm. -

Artificial Languages in J. R. R. Tolkien's Novel the Fellowship Of
Università degli Studi di Padova Dipartimento di Studi Linguistici e Letterari Corso di Laurea Magistrale in Lingue Moderne per la Comunicazione e la Cooperazione Internazionale Classe LM-38 Tesi di Laurea Artificial languages in J. R. R. Tolkien’s novel The Fellowship of the Ring and its film version Relatore Laureanda Prof. Maria Teresa Musacchio Sara Bracchi n° matr.1182867 / LMLCC Anno Accademico 2018 / 2019 TABLE OF CONTENTS INTRODUCTION.................................................................................................................. 1 CHAPTER 1 – Defining artificial languages 1.1. Artificial languages and natural languages .................................................................... 5 1.2. Classifications of artificial languages ............................................................................ 9 1.2.1. Umberto Eco’s classification .............................................................................. 10 1.2.2. Alan Reed Libert’s classification ........................................................................ 12 1.2.3. David Joshua Peterson’s classification ............................................................... 15 1.3. Two examples: Esperanto and Newspeak ..................................................................... 18 CHAPTER 2 – A brief history of artificial languages 2.1. Ancient times ............................................................................................................... 27 2.2. From the Middle Ages to the 18th century .................................................................... -

A Short History of the International Language Movement
1 ICD 5 co SU>G 30 A Short History of the Inter- national Language Movement A SHORT HISTORY OF THE INTERNATIONAL LANGUAGE MOVEMENT BY ALBERT LEON GUERARD S' Q i 'j ' cD BONI AND LIVERIGHT PUBLISHERS NEW YORK Printed in Great Britain (All Rights Reserved) A THERINA GVERARD Mfatis suce XI Mignonnefee aux yeux d'aurore, Donne-moi ta petite main. Tu ne saurais comprendre encore chemin. Quel rive eclaire mon cuirasse Tu Vapprendras : sous leur A Veclat brutal et trompeur, de race Orgueil de caste, orgueil Les hommes sont ivres de peur. Malgre le fracas des armures, cru saisir Seul, dans la nuit, j'ai Un bruissement dans les ramures, Frisson d'espoir et de desir. Chassant la peur, chassant la haine, Tu souriras sur les sommets, Aube de justice sereine, Que mes yeux ne verront jamais ! la Qu'importe ? J'ai transmis flamme. ma Qu'importe ? J'ai vecu /oi. Chair de ma chair, fteur de mon dme, Prends done ce livre : il est pour toi. SAN FRANCISCO. 16 AoOt. 1921. CONTENTS PAGE FOREWORD : THE PROBLEM 9 PART I NATURAL LANGUAGES I. FRENCH 17 II. ENGLISH 34 III. AN ANGLO-FRENCH CONDOMINIUM . 45 IV. LATIN 57 PAET II ARTIFICIAL LANGUAGES I. THE ARTIFICIAL ELEMENT IN LANGUAGE 71 " " II. PHILOSOPHICAL LANGUAGES . 82 III. VOLAPUK 96 IV. ESPERANTO: INCEPTION AND STRUCTURE OF THE LANGUAGE .... 107 V. HISTORY OF THE ESPERANTO MOVEMENT . 116 VI. THE NEO-ROMANIC GROUP : IDIOM NEU- TRAL, PANROMAN, ETC. 133 VII. THE DELEGATION FOR THE ADOPTION OF AN INTERNATIONAL LANGUAGE IDO . 145 VIII. LATINO SINE FLEXIONE.