Automatic Identification and Utilization of Custom Instructions for Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

C5ENPA1-DS, C-5E NETWORK PROCESSOR SILICON REVISION A1
Freescale Semiconductor, Inc... SILICON REVISION A1 REVISION SILICON C-5e NETWORK PROCESSOR Sheet Data Rev 03 PRELIMINARY C5ENPA1-DS/D Freescale Semiconductor,Inc. F o r M o r G e o I n t f o o : r w m w a t w i o . f n r e O e n s c T a h l i e s . c P o r o m d u c t , Freescale Semiconductor, Inc... Freescale Semiconductor,Inc. F o r M o r G e o I n t f o o : r w m w a t w i o . f n r e O e n s c T a h l i e s . c P o r o m d u c t , Freescale Semiconductor, Inc... Freescale Semiconductor,Inc. Silicon RevisionA1 C-5e NetworkProcessor Data Sheet Rev 03 C5ENPA1-DS/D F o r M o r Preli G e o I n t f o o : r w m w a t w i o . f n r e O e n s c T a h l i e s . c P o r o m m d u c t , inary Freescale Semiconductor, Inc... Freescale Semiconductor,Inc. F o r M o r G e o I n t f o o : r w m w a t w i o . f n r e O e n s c T a h l i e s . c P o r o m d u c t , Freescale Semiconductor, Inc. C5ENPA1-DS/D Rev 03 CONTENTS . -

Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R
et International Journal on Emerging Technologies 11 (2): 668-673(2020) ISSN No. (Print): 0975-8364 ISSN No. (Online): 2249-3255 Arithmetic and Logical Unit Design for Area Optimization for Microcontroller Amrut Anilrao Purohit 1,2 , Mohammed Riyaz Ahmed 2 and R. Venkata Siva Reddy 2 1Research Scholar, VTU Belagavi (Karnataka), India. 2School of Electronics and Communication Engineering, REVA University Bengaluru, (Karnataka), India. (Corresponding author: Amrut Anilrao Purohit) (Received 04 January 2020, Revised 02 March 2020, Accepted 03 March 2020) (Published by Research Trend, Website: www.researchtrend.net) ABSTRACT: Arithmetic and Logic Unit (ALU) can be understood with basic knowledge of digital electronics and any engineer will go through the details only once. The advantage of knowing ALU in detail is two- folded: firstly, programming of the processing device can be efficient and secondly, can design a new ALU architecture as per the various constraints of the use cases. The miniaturization of digital circuits can be achieved by either reducing the size of transistor (Moore’s law) or by optimizing the gate count of the circuit. The first has been explored extensively while the latter has been ignored which deals with the application of Boolean rules and requires sound knowledge of logic design. The ultimate outcome is to have an area optimized architecture/approach that optimizes the circuit at gate level. The design of ALU is for various processing devices varies with the device/system requirements. The area optimization places a significant role in the chip design. Here in this work, we have attempted to design an ALU which is area efficient while being loaded with additional functionality necessary for microcontrollers. -

Unit 8 : Microprocessor Architecture
Unit 8 : Microprocessor Architecture Lesson 1 : Microcomputer Structure 1.1. Learning Objectives On completion of this lesson you will be able to : ♦ draw the block diagram of a simple computer ♦ understand the function of different units of a microcomputer ♦ learn the basic operation of microcomputer bus system. 1.2. Digital Computer A digital computer is a multipurpose, programmable machine that reads A digital computer is a binary instructions from its memory, accepts binary data as input and multipurpose, programmable processes data according to those instructions, and provides results as machine. output. 1.3. Basic Computer System Organization Every computer contains five essential parts or units. They are Basic computer system organization. i. the arithmetic logic unit (ALU) ii. the control unit iii. the memory unit iv. the input unit v. the output unit. 1.3.1. The Arithmetic and Logic Unit (ALU) The arithmetic and logic unit (ALU) is that part of the computer that The arithmetic and logic actually performs arithmetic and logical operations on data. All other unit (ALU) is that part of elements of the computer system - control unit, register, memory, I/O - the computer that actually are there mainly to bring data into the ALU to process and then to take performs arithmetic and the results back out. logical operations on data. An arithmetic and logic unit and, indeed, all electronic components in the computer are based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations. Data are presented to the ALU in registers. These registers are temporary storage locations within the CPU that are connected by signal paths of the ALU. -

Design and Implementation of a Stateful Network Packet Processing
610 IEEE/ACM TRANSACTIONS ON NETWORKING, VOL. 25, NO. 1, FEBRUARY 2017 Design and Implementation of a Stateful Network Packet Processing Framework for GPUs Giorgos Vasiliadis, Lazaros Koromilas, Michalis Polychronakis, and Sotiris Ioannidis Abstract— Graphics processing units (GPUs) are a powerful and TCAMs, have greatly reduced both the cost and time platform for building the high-speed network traffic process- to develop network traffic processing systems, and have ing applications using low-cost hardware. The existing systems been successfully used in routers [4], [7] and network tap the massively parallel architecture of GPUs to speed up certain computationally intensive tasks, such as cryptographic intrusion detection systems [27], [34]. These systems offer a operations and pattern matching. However, they still suffer from scalable method of processing network packets in high-speed significant overheads due to critical-path operations that are still environments. However, implementations based on special- being carried out on the CPU, and redundant inter-device data purpose hardware are very difficult to extend and program, transfers. In this paper, we present GASPP, a programmable net- and prohibit them from being widely adopted by the industry. work traffic processing framework tailored to modern graphics processors. GASPP integrates optimized GPU-based implemen- In contrast, the emergence of commodity many-core tations of a broad range of operations commonly used in the architectures, such as multicore CPUs and modern graph- network traffic processing applications, including the first purely ics processors (GPUs) has proven to be a good solution GPU-based implementation of network flow tracking and TCP for accelerating many network applications, and has led stream reassembly. -

Embedded Multi-Core Processing for Networking
12 Embedded Multi-Core Processing for Networking Theofanis Orphanoudakis University of Peloponnese Tripoli, Greece [email protected] Stylianos Perissakis Intracom Telecom Athens, Greece [email protected] CONTENTS 12.1 Introduction ............................ 400 12.2 Overview of Proposed NPU Architectures ............ 403 12.2.1 Multi-Core Embedded Systems for Multi-Service Broadband Access and Multimedia Home Networks . 403 12.2.2 SoC Integration of Network Components and Examples of Commercial Access NPUs .............. 405 12.2.3 NPU Architectures for Core Network Nodes and High-Speed Networking and Switching ......... 407 12.3 Programmable Packet Processing Engines ............ 412 12.3.1 Parallelism ........................ 413 12.3.2 Multi-Threading Support ................ 418 12.3.3 Specialized Instruction Set Architectures ....... 421 12.4 Address Lookup and Packet Classification Engines ....... 422 12.4.1 Classification Techniques ................ 424 12.4.1.1 Trie-based Algorithms ............ 425 12.4.1.2 Hierarchical Intelligent Cuttings (HiCuts) . 425 12.4.2 Case Studies ....................... 426 12.5 Packet Buffering and Queue Management Engines ....... 431 399 400 Multi-Core Embedded Systems 12.5.1 Performance Issues ................... 433 12.5.1.1 External DRAMMemory Bottlenecks ... 433 12.5.1.2 Evaluation of Queue Management Functions: INTEL IXP1200 Case ................. 434 12.5.2 Design of Specialized Core for Implementation of Queue Management in Hardware ................ 435 12.5.2.1 Optimization Techniques .......... 439 12.5.2.2 Performance Evaluation of Hardware Queue Management Engine ............. 440 12.6 Scheduling Engines ......................... 442 12.6.1 Data Structures in Scheduling Architectures ..... 443 12.6.2 Task Scheduling ..................... 444 12.6.2.1 Load Balancing ................ 445 12.6.3 Traffic Scheduling ................... -

Reverse Engineering X86 Processor Microcode
Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz, Ruhr-University Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/koppe This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz Ruhr-Universitat¨ Bochum Abstract hardware modifications [48]. Dedicated hardware units to counter bugs are imperfect [36, 49] and involve non- Microcode is an abstraction layer on top of the phys- negligible hardware costs [8]. The infamous Pentium fdiv ical components of a CPU and present in most general- bug [62] illustrated a clear economic need for field up- purpose CPUs today. In addition to facilitate complex and dates after deployment in order to turn off defective parts vast instruction sets, it also provides an update mechanism and patch erroneous behavior. Note that the implementa- that allows CPUs to be patched in-place without requiring tion of a modern processor involves millions of lines of any special hardware. While it is well-known that CPUs HDL code [55] and verification of functional correctness are regularly updated with this mechanism, very little is for such processors is still an unsolved problem [4, 29]. known about its inner workings given that microcode and the update mechanism are proprietary and have not been Since the 1970s, x86 processor manufacturers have throughly analyzed yet. -

Reconfigurable Accelerators in the World of General-Purpose Computing
Reconfigurable Accelerators in the World of General-Purpose Computing Dissertation A thesis submitted to the Faculty of Electrical Engineering, Computer Science and Mathematics of Paderborn University in partial fulfillment of the requirements for the degree of Dr. rer. nat. by Tobias Kenter Paderborn, Germany August 26, 2016 Acknowledgments First and foremost, I would like to thank Prof. Dr. Christian Plessl for the advice and support during my research. As particularly helpful, I perceived his ability to communicate suggestions depending on the situation, either through open questions that give room to explore and learn, or through concrete recommendations that help to achieve results more directly. Special thanks go also to Prof. Dr. Marco Platzner for his advice and support. I profited especially from his experience and ability to systematically identify the essence of challenges and solutions. Furthermore, I would like to thank: • Prof. Dr. João M. P. Cardoso, for serving as external reviewer for my dissertation. • Prof. Dr. Friedhelm Meyer auf der Heide and Dr. Matthias Fischer for serving on my oral examination committee. • All colleagues with whom I had the pleasure to work at the PC2 and the Computer Engineering Group, researchers, technical and administrative staff. In a variation to one of our coffee kitchen puns, I’d like to state that research without colleagues is possible, but pointless. However, I’m not sure about the first part. • My long-time office mates Lars Schäfers and Alexander Boschmann for particularly extensive discussions on our research and far beyond. • Gavin Vaz, Heinrich Riebler and Achim Lösch for intensive and productive collabo- ration on joint research interests. -

Network Processors: Building Block for Programmable Networks
NetworkNetwork Processors:Processors: BuildingBuilding BlockBlock forfor programmableprogrammable networksnetworks Raj Yavatkar Chief Software Architect Intel® Internet Exchange Architecture [email protected] 1 Page 1 Raj Yavatkar OutlineOutline y IXP 2xxx hardware architecture y IXA software architecture y Usage questions y Research questions Page 2 Raj Yavatkar IXPIXP NetworkNetwork ProcessorsProcessors Control Processor y Microengines – RISC processors optimized for packet processing Media/Fabric StrongARM – Hardware support for Interface – Hardware support for multi-threading y Embedded ME 1 ME 2 ME n StrongARM/Xscale – Runs embedded OS and handles exception tasks SRAM DRAM Page 3 Raj Yavatkar IXP:IXP: AA BuildingBuilding BlockBlock forfor NetworkNetwork SystemsSystems y Example: IXP2800 – 16 micro-engines + XScale core Multi-threaded (x8) – Up to 1.4 Ghz ME speed RDRAM Microengine Array Media – 8 HW threads/ME Controller – 4K control store per ME Switch MEv2 MEv2 MEv2 MEv2 Fabric – Multi-level memory hierarchy 1 2 3 4 I/F – Multiple inter-processor communication channels MEv2 MEv2 MEv2 MEv2 Intel® 8 7 6 5 y NPU vs. GPU tradeoffs PCI XScale™ Core MEv2 MEv2 MEv2 MEv2 – Reduce core complexity 9 10 11 12 – No hardware caching – Simpler instructions Î shallow MEv2 MEv2 MEv2 MEv2 Scratch pipelines QDR SRAM 16 15 14 13 Memory – Multiple cores with HW multi- Controller Hash Per-Engine threading per chip Unit Memory, CAM, Signals Interconnect Page 4 Raj Yavatkar IXPIXP 24002400 BlockBlock DiagramDiagram Page 5 Raj Yavatkar XScaleXScale -

Predictable, Low-Power Arithmetic Logic Unit for the 8051 Microcontroller Using Asynchronous Logic D
1 Predictable, Low-power Arithmetic Logic Unit for the 8051 Microcontroller using Asynchronous Logic D. Mc Carthy, N. Zeinolabedini, J. Chen, E. Popovici Abstract| Modern embedded systems require all their components, including their microcontroller, to be opti- mised with respect to the power budget. Two properties are desirable. The first is low power usage and the sec- ond is predicable power usage, for improved estimation of firmware performance. In this paper we present all the arithmetic circuits for an ALU of an 8051 microcontroller implemented in Asynchronous Charge Sharing Logic (ACSL). This im- plementation seeks to give these two desirable proper- ties for a processor for embedded systems. The first, low power usage, obtained through charge sharing. The Fig. 1. Block diagram of an 8051 microcontroller. second, predictable power usage, is sought by ensuring that the power required to complete an operation is in- dependent of its inputs. The experimental techniques used in designing ACSL were also improved in the execution of this work, allow- ing the ACSL circuits to be entered using Verilog for fast The 8051 is an 8-bit microcontroller designed by In- initial testing and then translated to SPICE for detailed tel in 1980. A block diagram is shown in Figure 1. simulation. Through implementation and simulation, it was deter- This microcontroller was chosen for this work because mined that the use of ACSL can offer power predictabil- it is a very common microcontroller. 8051 compatible ity. parts are available from a wide variety of sources. More background of the 8051 will be discussed in section II. -

The Central Processing Unit (CPU)
The Central Processing Unit (CPU) Crash Course Computer Science #7 The Central Processing Unit https://www.youtube.com/watch?v=FZGugFqdr60 Internals ● Arithmetic Logic Unit (ALU) ● Control Unit (CU) ● Registers ● Cache Memory ● The Fetch-Execute Cycle Arithmetic Logic Unit An arithmetic logic unit (ALU) is a digital circuit used to perform arithmetic and logic operations. It represents the fundamental building block of the central processing unit (CPU) of a computer. Modern CPUs contain very powerful and complex ALUs. In addition to ALUs, modern CPUs contain a control unit (CU). Most of the operations of a CPU are performed by one or more ALUs, which load data from input registers. A register is a small amount of storage available as part of a CPU. The control unit tells the ALU what operation to perform on that data and the ALU stores the result in an output register. The control unit moves the data between these registers, the ALU, and memory. Control Unit A control unit coordinates how data moves around a cpu. The control unit (CU) is a component of a computer's central processing unit (CPU) that directs operation of the processor. It tells the computer's memory, arithmetic/logic unit and input and output devices how to respond to a program's instructions. ● The control unit obtains data / instructions from memory ● Interprets / decodes the instructions into commands / signals ● Controls transfer of instructions and data in the CPU ● Coordinates the parts of the CPU Registers In computer architecture, a processor register is a quickly accessible location available to a digital processor's central processing unit (CPU). -

Intel® IXP42X Product Line of Network Processors with ETHERNET Powerlink Controlled Node
Application Brief Intel® IXP42X Product Line of Network Processors With ETHERNET Powerlink Controlled Node The networked factory floor enables the While different real-time Ethernet solutions adoption of systems for remote monitoring, are available or under development, EPL, long-distance support, diagnostic services the real-time protocol solution managed and the integration of in-plant systems by the open vendor and user group EPSG with the enterprise. The need for flexible (ETHERNET Powerlink Standardization Group), connectivity solutions and high network is the only deterministic data communication bandwidth is driving a fundamental shift away protocol that is fully conformant with Ethernet from legacy industrial bus architectures and networking standards. communications protocols to industry EPL takes the standard approach of IEEE standards and commercial off-the shelf (COTS) 802.3 Ethernet with a mixed polling and time- solutions. Standards-based interconnect slicing mechanism to transfer time-critical data technologies and communications protocols, within extremely short and precise isochronous especially Ethernet, enable simpler and more cycles. In addition, EPL provides configurable cost-effective integration of network elements timing to synchronize networked nodes with and applications, from the enterprise to the www.intel.com/go/embedded high precision while asynchronously transmitting factory floor. data that is less time-critical. EPL is the ideal The Intel® IXP42X product line of network solution for meeting the timing demands of processors with ETHERNET Powerlink (EPL) typical high performance industrial applications, software helps manufacturers of industrial such as automation and motion control. control and automation devices bridge Current implementations have reached 200 µs between real-time Ethernet on the factory cycle-time with a timing deviation (jitter) less floor and standard Ethernet IT networks in than 1 µs. -
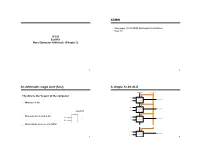
ADMIN an Arithmetic Logic Unit (ALU) a Simple 32-Bit
ADMIN • Read pages 211-215 (MIPS floating point instructions) • Read 3.9 IC220 Set #10: More Computer Arithmetic (Chapter 3) 1 2 An Arithmetic Logic Unit (ALU) A simple 32-bit ALU C arryIn O pe ratio n The ALU is the ‘brawn’ of the computer a0 C arry In R e su lt0 A LU 0 b0 • What does it do? C arry O u t a1 C arry In R e su lt1 A LU 1 b1 operation C arry O u t • How wide does it need to be? a a2 C arry In R e su lt2 A LU 2 b2 b C arry O u t • What outputs do we need for MIPS? a3 1 C arry In R e su lt31 A LU 3 1 b3 1 3 4 ALU Control and Symbol Multiplication • More complicated than addition – accomplished via shifting and addition • Example: grade-school algorithm 0010 (multiplicand) ALU Control Lines Function __x_1011 (multiplier) 0000 AND 0001 OR 0010 Add 0110 Subtract 0111 Set on less than 1100 NOR • Multiply m * n bits, How wide (in bits) should the product be? 5 6 Multiplication: Simple Implementation Multiplicand Shift left 64bits Multiplier 64-bit ALU Shift right 32bits Product Control test Write 64bits 7 Using Multiplication Floating Point • Product requires 64 bits • We need a way to represent – Use dedicated registers – numbers with fractions, e.g., 3.1416 – HI – more significant part of product – – LO – less significant part of product very small numbers, e.g., .000000001 • MIPS instructions – very large numbers, e.g., 3.15576 1023 mult $s2, $s3 • Representation: multu $s2, $s3 mfhi $t0 – sign, exponent, significand: mflo $t1 • (–1)sign significand 2exponent(some power) • Division – Significand always in normalized form: – Can perform with same hardware! (see book) div $s2, $s3 Lo = $s2 / $s3 • Yes: Hi = $s2 mod $s3 • No: divu $s2, $s3 – more bits for significand gives more – more bits for exponent increases 9 10 IEEE754 Standard IEEE 754 – Optimizations Single Precision (float): 8 bit exponent, 23 bit significand 31 30 29 28 27 26 25 24 23 22 21 20 .