STT RAM) Wei Xu, Hongbin Sun, Xiaobin Wang, Yiran Chen, Member, IEEE, and Tong Zhang, Senior Member, IEEE
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universal Memory
BRIEFING No.4 ICT UNIVERSAL MEMORY Memory is an integral part of information processing devices and is needed for short‐term stor‐ age such as when computer programs are being executed or text documents are processed. Currently, three main types of memory exist: SRAM offers very high speed at a high cost, DRAM is average in terms of speed and cost, and Flash memory is a low cost, low speed solution for applications that need to retain the data even when power is disconnected. A group of emerg‐ ing memory devices called universal memory aim to combine all these features in a single de‐ vice.1 Developments in universal memory devices may eventually lead to the introduction of novel October 2010 October memory architectures that offer increased performance, enable smaller mobile devices, and offer novel features in traditional products such as cars or domestic appliances. Nanotechnol‐ ogy is an integral part of emerging memory research as it is becoming increasingly difficult to enhance the performance of current devices by scaling the technology further. It is unlikely that a single technology will emerge as the universal memory technology; however, the develop‐ ments in this sector will enhance the energy efficiency and performance of memory devices. Currently, the Integrated Circuit (IC) market is dominated by US and Asia based companies. Uni‐ versal memory and nanotechnology based solutions could provide an opportunity for Europe to gain ground in the sector. Background volatility. Its disadvantage compared to SRAM and DRAM is speed. None of the existing memory technologies provide all of the required properties. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

Nanotechnology Trends in Nonvolatile Memory Devices
IBM Research Nanotechnology Trends in Nonvolatile Memory Devices Gian-Luca Bona [email protected] IBM Research, Almaden Research Center © 2008 IBM Corporation IBM Research The Elusive Universal Memory © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH Attributes for universal memories: –Highest performance –Lowest active and standby power –Unlimited Read/Write endurance –Non-Volatility –Compatible to existing technologies –Continuously scalable –Lowest cost per bit Performance © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH m+1 SLm SLm-1 WLn-1 WLn WLn+1 A new class of universal storage device : – a fast solid-state, nonvolatile RAM – enables compact, robust storage systems with solid state reliability and significantly improved cost- performance Performance © 2008 IBM Corporation IBM Research Non-volatile, universal semiconductor memory SL m+1 SL m SL m-1 WL n-1 WL n WL n+1 Everyone is looking for a dense (cheap) crosspoint memory. It is relatively easy to identify materials that show bistable hysteretic behavior (easily distinguishable, stable on/off states). IBM © 2006 IBM Corporation IBM Research The Memory Landscape © 2008 IBM Corporation IBM Research IBM Research Histogram of Memory Papers Papers presented at Symposium on VLSI Technology and IEDM; Ref.: G. Burr et al., IBM Journal of R&D, Vol.52, No.4/5, July 2008 © 2008 IBM Corporation IBM Research IBM Research Emerging Memory Technologies Memory technology remains an -

Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm
CORE Metadata, citation and similar papers at core.ac.uk Provided by DigitalCommons@USU Utah State University DigitalCommons@USU All Graduate Theses and Dissertations Graduate Studies 12-2012 Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm Satyajit Desai Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/etd Part of the Computer Engineering Commons Recommended Citation Desai, Satyajit, "Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block- Based Adaptive Body Biasing Algorithm" (2012). All Graduate Theses and Dissertations. 1419. https://digitalcommons.usu.edu/etd/1419 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Theses and Dissertations by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. PROCESS VARIATION AWARE DRAM (DYNAMIC RANDOM ACCESS MEMORY) DESIGN USING BLOCK-BASED ADAPTIVE BODY BIASING ALGORITHM by Satyajit Desai A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in Computer Engineering Approved: Dr. Sanghamitra Roy Dr. Koushik Chakraborty Major Professor Committee Member Dr. Reyhan Bhaktur Dr. Mark R. McLellan Committee Member Vice President for Research and Dean of the School of Graduate Studies UTAH STATE UNIVERSITY Logan, Utah 2012 ii Copyright c Satyajit Desai 2012 All Rights Reserved iii Abstract Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm by Satyajit Desai, Master of Science Utah State University, 2012 Major Professor: Dr. -

DRAM and Storage-Class Memory (SCM) Overview
Page 1 of 7 DRAM and Storage-Class Memory (SCM) Overview Introduction/Motivation Looking forward, volatile and non-volatile memory will play a much greater role in future infrastructure solutions. Figure 1 illustrates a typical processor with its DDR DRAM memory modules (e.g. DIMMs) connected to it. Notice that the integrated memory controller within the processor supports the DDR DRAM bus protocol and only DDR DRAM devices, or those that operate like DDR DRAM, are supported. The tight coupling of computing resources (CPUs, GPUs, FPGAs, etc.) with memory resources pose challenges to memory’s expanding importance. These challenges include: Memory capacity requirements are increasing, driven by in-memory workloads, server virtualization, etc. Compute capacity of CPUs are increasing, requiring more memory controllers and channels per socket Fewer high speed DIMMs per channel require more memory controllers and channels to maintain capacity Design/support lifecycles for compute and memory resources are tightly coupled making each dependent on the other Memory capacity is dependent on the number of CPUs, yielding over-provisioned compute for many workloads Gen-Z is a new data access technology that can significantly enhance memory solutions built with existing or emerging memory technologies. The following sections are designed to unveil the features and capabilities of the Gen-Z architecture by first describing the foundational features and building on these to illustrate the next generation components and system solutions that are made possible by Gen-Z technology. Note: many components require byte-addressable memory (e.g. CPU, SoC, GPUs, FPGAs, gateways, etc.), but, in this document, the term “processor” will be used to generically describe these roles. -

Semiconductor Memory
Semiconductor Memory Seong-Ook Jung 2011. 4. 1. [email protected] VLSI SYSTEM LAB, YONSEI University School of Electrical & Electronic Engineering Contents 1. Current Memory 2. Future of NAND Flash 3. Universal memory 1. PRAM 2. STT-MRAM 2 YONSEI Univ. School of EEE Current Memory Memory Hierarchy by Samsung electronics 4 YONSEI Univ. School of EEE Volatile vs. Non-Volatile Volatile memory DRAM: fast speed, high density Main memory SRAM: very fast speed, very low density Cache memory Non-volatile memory NOR: very slow speed, low density Program memory Flash: very slow speed, very high density Storage memory 5 YONSEI Univ. School of EEE Charge Based vs. Resistance Based Charge based device (Current memory) DRAM SRAM Flash Resistance base memory (Future memory Universal memory) PRAM RRAM 6 YONSEI Univ. School of EEE SRAM Cache hierarchy in Lynnfield L1 ; 32KB (1core) L2 ; 256KB (1core) L3 ; 8MB (shared) Intel processor ; Lynnfield Layout of Lynnfield SRAM cell 7 YONSEI Univ. School of EEE DRAM SAMSUNG DDR3 4GB DRAM DRAM cell 8 YONSEI Univ. School of EEE DRAM Cell 9 YONSEI Univ. School of EEE Flash Memory Samsung 256GB SSD Flash memory cell Samsung 32GB USB memory 10 YONSEI Univ. School of EEE Comparison by Korea Institute of Science & Technology Information (KISTI) 11 YONSEI Univ. School of EEE DRAM and SRAM Trend Improve performance and capacity of DRAM and SRAM Technology scaling Design technique Function and role of DRAM and SRAM are not changed. SRAM ; cache memory in processor DRAM ; main memory unit in system NGM XDR DRAM diff? DDR4 DDR3 DRDRAM Bandwidth DDR2 DDR SDRAM 1996 2000 2004 2008 2012 Year by Intel Technology Journal 12 YONSEI Univ. -
James A. Bain the Oracle at Delphi Outline • Logistics of the Advising and Mentoring Process
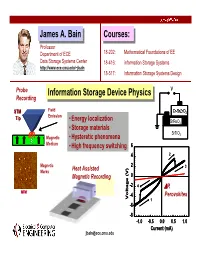
JamesJames A.A. BainBain Courses:Courses: Professor Department of ECE 18-202: Mathematical Foundations of EE Data Storage Systems Center 18-416: information Storage Systems http://www.ece.cmu.edu/~jbain 18-517: Information Storage Systems Design Probe Information Storage Device Physics V Recording Information Storage Device Physics Ti/A Field STM Cr-SrZrO3 Tip Emission • Energy localization SrRuO3 • Storage materials SrTiO3 Magnetic • Hysteretic phenomena Medium • High frequency switching 6 4 2 Magnetic 2 3 Marks Heat Assisted Magnetic Recording 0 -2 4 ∆R MFM -4 Perovskites Voltage (V)Voltage (V) 1 -6 -8 -1.0 -0.5 0.0 0.5 1.0 Current (mA) [email protected] ECE Advising: Getting Your Questions Answered James A. Bain The Oracle at Delphi Outline • Logistics of the advising and mentoring process • Objectives of the advising and mentoring process • Advising summary • Data storage technology overview ... Logistics of Advising Process • Fall Sophomore Year – Take 18-200: Emerging Trends in ECE – Receive advisor assignment – Complete advising preparation worksheet – Meet with advisor (possibly more than once) – Select classes for Spring 05 • Spring Sophomore Year – Meet with advisor (possibly more than once) – Request/select a faculty mentor – Meet with faculty mentor – Select classes for Fall 06 • Junior and Senior Years – Meet with faculty mentor as desired – Select classes for each semester – Plan for post-graduation: internships, jobs, fellowships, grad schools, etc. ECE Undergraduate Advising Committee Undergraduate Program Staff Susan Farrington - [email protected] HH 1118, 8-6955 Director of Alumni and Student Relations Structures relationships with students during and after ECE, student organizations, profession societies, alumni events Janet Peters- [email protected] HH 1110, 8-3666 Assistant for Undergraduate Education Monitors student academic progress, handles procedural and policy information and information on Co-op, IMB, Bruce Krogh Double Majors and Minors, Career Center, Health Center, etc. -

A Survey of Architectural Approaches for Managing Embedded DRAM and Non-Volatile On-Chip Caches Sparsh Mittal, Jeffrey S
A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Jeffrey S. Vetter, Dong Li To cite this version: Sparsh Mittal, Jeffrey S. Vetter, Dong Li. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE Transactions on Parallel and Distributed Systems, Institute of Electrical and Electronics Engineers, 2015, pp.14. 10.1109/TPDS.2014.2324563. hal-01102387 HAL Id: hal-01102387 https://hal.archives-ouvertes.fr/hal-01102387 Submitted on 12 Jan 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. This is the author's version of an article that has been published in this journal. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TPDS.2014.2324563 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTING SYSTEMS 1 A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Member, IEEE, Jeffrey S. Vetter, Senior Member, IEEE, and Dong Li Abstract—Recent trends of CMOS scaling and increasing number of on-chip cores have led to a large increase in the size of on- chip caches. -

A Study About Non-Volatile Memories
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 29 July 2016 doi:10.20944/preprints201607.0093.v1 1 Article 2 A Study about Non‐Volatile Memories 3 Dileep Kumar* 4 Department of Information Media, The University of Suwon, Hwaseong‐Si South Korea ; [email protected] 5 * Correspondence: [email protected] ; Tel.: +82‐31‐229‐8212 6 7 8 Abstract: This paper presents an upcoming nonvolatile memories (NVM) overview. Non‐volatile 9 memory devices are electrically programmable and erasable to store charge in a location within the 10 device and to retain that charge when voltage supply from the device is disconnected. The 11 non‐volatile memory is typically a semiconductor memory comprising thousands of individual 12 transistors configured on a substrate to form a matrix of rows and columns of memory cells. 13 Non‐volatile memories are used in digital computing devices for the storage of data. In this paper 14 we have given introduction including a brief survey on upcoming NVMʹs such as FeRAM, MRAM, 15 CBRAM, PRAM, SONOS, RRAM, Racetrack memory and NRAM. In future Non‐volatile memory 16 may eliminate the need for comparatively slow forms of secondary storage systems, which include 17 hard disks. 18 Keywords: Non‐volatile Memories; NAND Flash Memories; Storage Memories 19 PACS: J0101 20 21 22 1. Introduction 23 Memory is divided into two main parts: volatile and nonvolatile. Volatile memory loses any 24 data when the system is turned off; it requires constant power to remain viable. Most kinds of 25 random access memory (RAM) fall into this category. -

UMP11 Thesis.Docx
MC68HC11 MICROCONTROLLER BASED UNIVERSAL MEMORY PROGRAMMER ONG KIAN CHUN This thesis is submitted as partial fulfillment of the requirements for the award of the Bachelor of Electrical Engineering (Electronics) Faculty of Electrical & Electronics Engineering Universiti Malaysia Pahang NOVEMBER, 2010 ii “I hereby acknowledge that the scope and quality of this thesis is qualified for the award of the Bachelor Degree of Electrical Engineering (Electronics)” Signature : ______________________________________________ Name : EN. NIK MOHD. KAMIL BIN NIK YUSOFF Date : 1 NOVEMBER 2010 iii “All the trademark and copyrights use herein are property of their respective owner. References of information from other sources are quoted accordingly; otherwise the information presented in this report is solely work of the author.” Signature : ____________________________ Author : ONG KIAN CHUN Date : 1 NOVEMBER 2010 v ACKNOWLEDGEMENT In complishing this thesis, I would like to take this opportunity to extend my deepest gratitude to the following persons who have helped me a lot in contributed towards my understanding and thoughts. I am greatly indebted to my supervisor, Mr. Nik Mohd Kamil bin Nik Yusoff for his advise and guidance throughout my project. Thank you. I would like to thank my family member for giving me their loves and supports throughout my four years of studies in Universiti Malaysia Pahang. Special thanks to FKEE staffs for helping me to complete my project. Suggestions and critisms from my friends have always been helpful in finding solutions to my problems. Thanks you all. Finally, I would like to express my thanks to those who involves directly or indirectly in completion of my project. vi ABSTRACT Memory product is an essential component for all microcontroller and microprocessor system. -

Memory Technology for Space
Aerospace Data Storage and Processing Systems Memory Technology for Space Ian Troxel SEAKR Engineering, Inc. Seminar Day Military and Aerospace Programmable Logic Devices (MAPLD) NASA Goddard Space Flight Center August 31, 2009 Product names that appear in this presentation are for identification purposes only. All trademarks and registered trademarks are the property of their respective owners. Motivation Aerospace Data Storage and Processing Systems J When considering PLD performance, peripheral devices must be included J After the processor, memory is often the device limiting space system capability c/o Flickr Memory Devices for Space Applications 2 of 36 MAPLD 2009 Overview Aerospace Data Storage and Processing Systems JMemory types covered • Non-volatile –EEPROM –Flash EEPROM Flash –Other Programmable • Volatile Logic Device Other –SRAM SRAM DRAM –DRAM JOther special types are used as well JAll results from the open literature and “ITAR safe” JInternal PLD memory not included in this discussion Memory Devices for Space Applications 3 of 36 MAPLD 2009 Memory Specialization Aerospace Data Storage and Processing Systems J Specialization seen in commercial systems also prevalent in space systems J Non-volatile memory • Persistent values, also… • Greater capacity • Lower power dissipation • Slower access times, throughput • Apps: start-up memory, persistent storage J Volatile memory c/o Scholarpedia.com • Values are not persistent, also … • Decreased capacity • Increased power dissipation • Fast access times, throughput • Apps: run-time -

NVRAM Workshop M Harrand.Pdf
Breaking the Memory Bottleneck in Computing Applications with Emerging Memory Technologies: a Design and Technology Perspective M. HARRAND CEA-LIST, LABORATOIRE INFRASTRUCTURE ET ATELIER LOGICIEL SUR PUCE, 17 RUE DES MARTYRS, 38000 GRENOBLE – FRANCE G. MOLAS CEA-LETI, LABORATOIRE DES COMPOSANTS MÉMOIRE, 17 RUE DES MARTYRS, 38000 GRENOBLE – FRANCE 2017 NVRAM Workshop | May 29-30th- 2017 OBJECTIVES OF THIS TALK • What are the limitations and challenges of current computing systems memory hierarchy ? • What are the main emerging non-volatile memory technologies ? • What are the main eNVM internal architectures ? • How these emerging memories can help to solve these limitations ? What changes can we envisage in computing systems ? • Which characteristics should be targeted for these memories ? • Note : this talk focuses on computing in servers and data centers, not on the embedded market M. Harrand, G. Molas – NVRAM Workshop May 2017 | 2 OUTLINE Introduction Memory hierarchy system aspects • Memory hierarchy • Limitations in computing systems, Emerging NVM • Technology • Design How emerging memories can help to solve current computing systems limitations • Storage • Main memory • Embedded caches • Universal memory Conclusions | 3 OUTLINE Introduction Memory hierarchy system aspects • Memory hierarchy • Limitations in computing systems, Emerging NVM • Technology • Design How emerging memories can help to solve current computing systems limitations • Storage • Main memory • Embedded caches • Universal memory Conclusions | 4 WHY A MEMORY HIERARCHY ? • Because storage memory is far too slow to be used directly by the processor • Processors require data to be accessible in ~1ns : • only SRAM embedded with the processor are fast enough for that… • but can only store small amounts of data • Then, cheaper/intermediate speed memory – DRAM today – is used in between M.