TECHNOLOGY IMPLICATIONS for LARGE LAST-LEVEL CACHES Mu
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universal Memory
BRIEFING No.4 ICT UNIVERSAL MEMORY Memory is an integral part of information processing devices and is needed for short‐term stor‐ age such as when computer programs are being executed or text documents are processed. Currently, three main types of memory exist: SRAM offers very high speed at a high cost, DRAM is average in terms of speed and cost, and Flash memory is a low cost, low speed solution for applications that need to retain the data even when power is disconnected. A group of emerg‐ ing memory devices called universal memory aim to combine all these features in a single de‐ vice.1 Developments in universal memory devices may eventually lead to the introduction of novel October 2010 October memory architectures that offer increased performance, enable smaller mobile devices, and offer novel features in traditional products such as cars or domestic appliances. Nanotechnol‐ ogy is an integral part of emerging memory research as it is becoming increasingly difficult to enhance the performance of current devices by scaling the technology further. It is unlikely that a single technology will emerge as the universal memory technology; however, the develop‐ ments in this sector will enhance the energy efficiency and performance of memory devices. Currently, the Integrated Circuit (IC) market is dominated by US and Asia based companies. Uni‐ versal memory and nanotechnology based solutions could provide an opportunity for Europe to gain ground in the sector. Background volatility. Its disadvantage compared to SRAM and DRAM is speed. None of the existing memory technologies provide all of the required properties. -

Error Detection and Correction Methods for Memories Used in System-On-Chip Designs
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 – 8958, Volume-8, Issue-2S2, January 2019 Error Detection and Correction Methods for Memories used in System-on-Chip Designs Gunduru Swathi Lakshmi, Neelima K, C. Subhas ABSTRACT— Memory is the basic necessity in any SoC Static Random Access Memory (SRAM): It design. Memories are classified into single port memory and consists of a latch or flipflop to store each bit of multiport memory. Multiport memory has ability to source more memory and it does not required any refresh efficient execution of operation and high speed performance operation. SRAM is mostly used in cache memory when compared to single port. Testing of semiconductor memories is increasing because of high density of current in the and in hand-held devices. It has advantages like chips. Due to increase in embedded on chip memory and memory high speed and low power consumption. It has density, the number of faults grow exponentially. Error detection drawback like complex structure and expensive. works on concept of redundancy where extra bits are added for So, it is not used for high capacity applications. original data to detect the error bits. Error correction is done in Read Only Memory (ROM): It is a non-volatile memory. two forms: one is receiver itself corrects the data and other is It can only access data but cannot modify data. It is of low receiver sends the error bits to sender through feedback. Error detection and correction can be done in two ways. One is Single cost. Some applications of ROM are scanners, ID cards, Fax bit and other is multiple bit. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

Nanotechnology Trends in Nonvolatile Memory Devices
IBM Research Nanotechnology Trends in Nonvolatile Memory Devices Gian-Luca Bona [email protected] IBM Research, Almaden Research Center © 2008 IBM Corporation IBM Research The Elusive Universal Memory © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH Attributes for universal memories: –Highest performance –Lowest active and standby power –Unlimited Read/Write endurance –Non-Volatility –Compatible to existing technologies –Continuously scalable –Lowest cost per bit Performance © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH m+1 SLm SLm-1 WLn-1 WLn WLn+1 A new class of universal storage device : – a fast solid-state, nonvolatile RAM – enables compact, robust storage systems with solid state reliability and significantly improved cost- performance Performance © 2008 IBM Corporation IBM Research Non-volatile, universal semiconductor memory SL m+1 SL m SL m-1 WL n-1 WL n WL n+1 Everyone is looking for a dense (cheap) crosspoint memory. It is relatively easy to identify materials that show bistable hysteretic behavior (easily distinguishable, stable on/off states). IBM © 2006 IBM Corporation IBM Research The Memory Landscape © 2008 IBM Corporation IBM Research IBM Research Histogram of Memory Papers Papers presented at Symposium on VLSI Technology and IEDM; Ref.: G. Burr et al., IBM Journal of R&D, Vol.52, No.4/5, July 2008 © 2008 IBM Corporation IBM Research IBM Research Emerging Memory Technologies Memory technology remains an -

Embedded DRAM
Embedded DRAM Raviprasad Kuloor Semiconductor Research and Development Centre, Bangalore IBM Systems and Technology Group DRAM Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example References Slide 1 Acknowledgement • John Barth, IBM SRDC for most of the slides content • Madabusi Govindarajan • Subramanian S. Iyer • Many Others Slide 2 Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example Slide 3 Memory Classification revisited Slide 4 Motivation for a memory hierarchy – infinite memory Memory store Processor Infinitely fast Infinitely large Cycles per Instruction Number of processor clock cycles (CPI) = required per instruction CPI[ ∞ cache] Finite memory speed Memory store Processor Finite speed Infinite size CPI = CPI[∞ cache] + FCP Finite cache penalty Locality of reference – spatial and temporal Temporal If you access something now you’ll need it again soon e.g: Loops Spatial If you accessed something you’ll also need its neighbor e.g: Arrays Exploit this to divide memory into hierarchy Hit L2 L1 (Slow) Processor Miss (Fast) Hit Register Cache size impacts cycles-per-instruction Access rate reduces Slower memory is sufficient Cache size impacts cycles-per-instruction For a 5GHz -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory -

Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm
CORE Metadata, citation and similar papers at core.ac.uk Provided by DigitalCommons@USU Utah State University DigitalCommons@USU All Graduate Theses and Dissertations Graduate Studies 12-2012 Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm Satyajit Desai Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/etd Part of the Computer Engineering Commons Recommended Citation Desai, Satyajit, "Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block- Based Adaptive Body Biasing Algorithm" (2012). All Graduate Theses and Dissertations. 1419. https://digitalcommons.usu.edu/etd/1419 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Theses and Dissertations by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. PROCESS VARIATION AWARE DRAM (DYNAMIC RANDOM ACCESS MEMORY) DESIGN USING BLOCK-BASED ADAPTIVE BODY BIASING ALGORITHM by Satyajit Desai A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in Computer Engineering Approved: Dr. Sanghamitra Roy Dr. Koushik Chakraborty Major Professor Committee Member Dr. Reyhan Bhaktur Dr. Mark R. McLellan Committee Member Vice President for Research and Dean of the School of Graduate Studies UTAH STATE UNIVERSITY Logan, Utah 2012 ii Copyright c Satyajit Desai 2012 All Rights Reserved iii Abstract Process Variation Aware DRAM (Dynamic Random Access Memory) Design Using Block-Based Adaptive Body Biasing Algorithm by Satyajit Desai, Master of Science Utah State University, 2012 Major Professor: Dr. -

SRAM Edram DRAM
Technology Challenges and Directions of SRAM, DRAM, and eDRAM Cell Scaling in Sub- 20nm Generations Jai-hoon Sim SK hynix, Icheon, Korea Outline 1. Nobody is perfect: Main memory & cache memory in the dilemma in sub-20nm era. 2. SRAM Scaling: Diet or Die. 6T SRAM cell scaling crisis & RDF problem. 3. DRAM Scaling: Divide and Rule. Unfinished 1T1C DRAM cell scaling and its technical direction. 4. eDRAM Story: Float like a DRAM & sting like a SRAM. Does logic based DRAM process work? 5. All for one. Reshaping DRAM with logic technology elements. 6. Conclusion. 2 Memory Hierarchy L1$ L2$ SRAM Higher Speed (< few nS) Working L3$ Better Endurance eDRAM Memory (>1x1016 cycles) Access Speed Access Stt-RAM Main Memory DRAM PcRAM ReRAM Lower Speed Bigger Size Storage Class Memory NAND Density 3 Technologies for Cache & Main Memories SRAM • 6T cell. • Non-destructive read. • Performance driven process Speed technology. eDRAM • Always very fast. • 1T-1C cell. • Destructive read and Write-back needed. • Leakage-Performance compromised process technology. Standby • Smaller than SRAM and faster than Density Power DRAM. DRAM • 1T-1C cell. • Destructive read and Write-back needed. • Leakage control driven process technology. • Not always fast. • Smallest cell and lowest cost per bit. 4 eDRAM Concept: Performance Gap Filler SRAM 20-30X Cell Size Cell eDRAM DRAM 50-100X Random Access Speed • Is there any high density & high speed memory solution that could be 100% integrated into logic SoC? 5 6T-SRAM Cell Operation VDD WL WL DVBL PU Read PG SN SN WL Icell PD BL VSS BL V SN BL BL DD SN PD Read Margin: Write PG PG V Write Margin: SS PU Time 6 DRAM’s Charge Sharing DVBL VS VBL Charge Sharing Write-back VPP WL CS CBL V BL DD 1 SN C V C V C C V S DD B 2 DD S B BL 1/2VDD Initial Charge After Charge Sharing DVBL T d 1 1 V BL SS DVBL VBL VBL VDD 1 CB / CS 2 VBBW Time 1 1 I t L RET if cell leakage included Cell select DVBL VDD 1 CB / CS 2 CS 7 DRAM Scalability Metrics BL Cell WL CS • Cell CS. -

DRAM and Storage-Class Memory (SCM) Overview
Page 1 of 7 DRAM and Storage-Class Memory (SCM) Overview Introduction/Motivation Looking forward, volatile and non-volatile memory will play a much greater role in future infrastructure solutions. Figure 1 illustrates a typical processor with its DDR DRAM memory modules (e.g. DIMMs) connected to it. Notice that the integrated memory controller within the processor supports the DDR DRAM bus protocol and only DDR DRAM devices, or those that operate like DDR DRAM, are supported. The tight coupling of computing resources (CPUs, GPUs, FPGAs, etc.) with memory resources pose challenges to memory’s expanding importance. These challenges include: Memory capacity requirements are increasing, driven by in-memory workloads, server virtualization, etc. Compute capacity of CPUs are increasing, requiring more memory controllers and channels per socket Fewer high speed DIMMs per channel require more memory controllers and channels to maintain capacity Design/support lifecycles for compute and memory resources are tightly coupled making each dependent on the other Memory capacity is dependent on the number of CPUs, yielding over-provisioned compute for many workloads Gen-Z is a new data access technology that can significantly enhance memory solutions built with existing or emerging memory technologies. The following sections are designed to unveil the features and capabilities of the Gen-Z architecture by first describing the foundational features and building on these to illustrate the next generation components and system solutions that are made possible by Gen-Z technology. Note: many components require byte-addressable memory (e.g. CPU, SoC, GPUs, FPGAs, gateways, etc.), but, in this document, the term “processor” will be used to generically describe these roles. -

Digital Recorded Announcement Machine DRAM and EDRAM Guide
297-1001-527 DMS-100 Family Digital Recorded Announcement Machine DRAM and EDRAM Guide BASE09 and up Standard 13.06 August 1999 DMS-100 Family Digital Recorded Announcement Machine DRAM and EDRAM Guide Publication number: 297-1001-527 Product release: BASE09 and up Document release: Standard 13.06 Date: August 1999 1982, 1984, 1985, 1986, 1987, 1988, 1990, 1991, 1993, 1994, 1995, 1996, 1997, 1999 Northern Telecom All rights reserved Printed in the United States of America NORTHERN TELECOM CONFIDENTIAL: The information contained in this document is the property of Northern Telecom. Except as specifically authorized in writing by Northern Telecom, the holder of this document shall keep the information contained herein confidential and shall protect same in whole or in part from disclosure and dissemination to third parties and use same for evaluation, operation, and maintenance purposes only. Information is subject to change without notice. Northern Telecom reserves the right to make changes in design or components as progress in engineering and manufacturing may warrant. This equipment has been tested and found to comply with the limits for a Class A digital device pursuant to Part 15 of the FCC Rules, and the radio interference regulations of the Canadian Department of Communications. These limits are designed to provide reasonable protection against harmful interference when the equipment is operated in a commercial environment. This equipment generates, uses and can radiate radio frequency energy and, if not installed and used in accordance with the instruction manual, may cause harmful interference to radio communications. Operation of this equipment in a residential area is likely to cause harmful interference in which case the user will be required to correct the interference at the user’s own expense. -

Semiconductor Memory
Semiconductor Memory Seong-Ook Jung 2011. 4. 1. [email protected] VLSI SYSTEM LAB, YONSEI University School of Electrical & Electronic Engineering Contents 1. Current Memory 2. Future of NAND Flash 3. Universal memory 1. PRAM 2. STT-MRAM 2 YONSEI Univ. School of EEE Current Memory Memory Hierarchy by Samsung electronics 4 YONSEI Univ. School of EEE Volatile vs. Non-Volatile Volatile memory DRAM: fast speed, high density Main memory SRAM: very fast speed, very low density Cache memory Non-volatile memory NOR: very slow speed, low density Program memory Flash: very slow speed, very high density Storage memory 5 YONSEI Univ. School of EEE Charge Based vs. Resistance Based Charge based device (Current memory) DRAM SRAM Flash Resistance base memory (Future memory Universal memory) PRAM RRAM 6 YONSEI Univ. School of EEE SRAM Cache hierarchy in Lynnfield L1 ; 32KB (1core) L2 ; 256KB (1core) L3 ; 8MB (shared) Intel processor ; Lynnfield Layout of Lynnfield SRAM cell 7 YONSEI Univ. School of EEE DRAM SAMSUNG DDR3 4GB DRAM DRAM cell 8 YONSEI Univ. School of EEE DRAM Cell 9 YONSEI Univ. School of EEE Flash Memory Samsung 256GB SSD Flash memory cell Samsung 32GB USB memory 10 YONSEI Univ. School of EEE Comparison by Korea Institute of Science & Technology Information (KISTI) 11 YONSEI Univ. School of EEE DRAM and SRAM Trend Improve performance and capacity of DRAM and SRAM Technology scaling Design technique Function and role of DRAM and SRAM are not changed. SRAM ; cache memory in processor DRAM ; main memory unit in system NGM XDR DRAM diff? DDR4 DDR3 DRDRAM Bandwidth DDR2 DDR SDRAM 1996 2000 2004 2008 2012 Year by Intel Technology Journal 12 YONSEI Univ. -
James A. Bain the Oracle at Delphi Outline • Logistics of the Advising and Mentoring Process
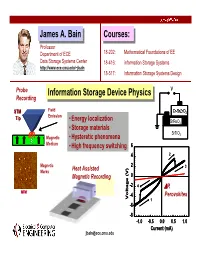
JamesJames A.A. BainBain Courses:Courses: Professor Department of ECE 18-202: Mathematical Foundations of EE Data Storage Systems Center 18-416: information Storage Systems http://www.ece.cmu.edu/~jbain 18-517: Information Storage Systems Design Probe Information Storage Device Physics V Recording Information Storage Device Physics Ti/A Field STM Cr-SrZrO3 Tip Emission • Energy localization SrRuO3 • Storage materials SrTiO3 Magnetic • Hysteretic phenomena Medium • High frequency switching 6 4 2 Magnetic 2 3 Marks Heat Assisted Magnetic Recording 0 -2 4 ∆R MFM -4 Perovskites Voltage (V)Voltage (V) 1 -6 -8 -1.0 -0.5 0.0 0.5 1.0 Current (mA) [email protected] ECE Advising: Getting Your Questions Answered James A. Bain The Oracle at Delphi Outline • Logistics of the advising and mentoring process • Objectives of the advising and mentoring process • Advising summary • Data storage technology overview ... Logistics of Advising Process • Fall Sophomore Year – Take 18-200: Emerging Trends in ECE – Receive advisor assignment – Complete advising preparation worksheet – Meet with advisor (possibly more than once) – Select classes for Spring 05 • Spring Sophomore Year – Meet with advisor (possibly more than once) – Request/select a faculty mentor – Meet with faculty mentor – Select classes for Fall 06 • Junior and Senior Years – Meet with faculty mentor as desired – Select classes for each semester – Plan for post-graduation: internships, jobs, fellowships, grad schools, etc. ECE Undergraduate Advising Committee Undergraduate Program Staff Susan Farrington - [email protected] HH 1118, 8-6955 Director of Alumni and Student Relations Structures relationships with students during and after ECE, student organizations, profession societies, alumni events Janet Peters- [email protected] HH 1110, 8-3666 Assistant for Undergraduate Education Monitors student academic progress, handles procedural and policy information and information on Co-op, IMB, Bruce Krogh Double Majors and Minors, Career Center, Health Center, etc.