Discovering Bilingual Lexicons in Polyglot Word Embeddings APREPRINT
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Caste-Based Oppression and the Class Struggle TU Senan CWI-India
Caste-based Oppression and the Class Struggle TU Senan CWI -India 24 December 2014 Leave a comment In 2013, the British government agreed to include caste- based discrimination as an amendment to the Equality Act (2010). An alliance of Tory MPs and caste-based ‘community leaders’, however, successfully stalled its implementation to after the general election. What is behind this opposition? What role does caste play, both in South Asia and Britain? Why is it an important issue for socialists today? The caste system in South Asia is one of the cruellest forms of oppression that exists today. Cold-blooded murder, sexual violence, untouchability, bonded slavery and other feudal forms of horrific discrimination are used against people from the most oppressed caste. People challenging this oppression face brutal violence, including being driven from traditional lands or the burning down of whole villages. More than half-a-billion people in India are subjected to discrimination based on their caste, which is determined by hereditary membership and marriage within the caste. Higher castes dominate certain professions, businesses, etc. Beneath this hierarchical system are more than 200 million (Dalits and others) who face the most severe forms of discrimination. Traditional castes cut across class and class loyalties, although the leaders of the higher castes are a significant component of the ruling class. Caste oppression is also present in other parts of the world where South Asians live, travelling with the migrations of populations over time. From Malaysia to Europe, caste divisions have been maintained. At least half-a- million people of South Asian descent face caste-based discrimination in Britain. -

HWPL-KAASH FOUNDATION Content the 1ST RELIGIOUS YOUTH PEACE CAMP St • HWPL-KAASH Foundation- the 1 1 Religious Youth Peace Camp
HWPL-KAASH FOUNDATION Content THE 1ST RELIGIOUS YOUTH PEACE CAMP St • HWPL-KAASH Foundation- The 1 1 Religious Youth Peace Camp • 2nd International Faculty Development Program On Pedagogy Of Teaching 2 History • 3rd International Faculty Development Program On Emerging Approaches 6 And Trends In English Language And Literature th • 8 International Webinar On ‘Start-Ups 27 In India: Current Scenario’ • From the Editor's Desk | From the 29 Founder's Desk • Wellness Of Mind, Body And Women's 30 Health • Holistic Healthcare For Happiness 32 • Breastfeeding essentials 33 • 11th International Health Conference On 'Exploring The Application Of 34 Naturopathy And Ayurveda In Human Healthcare’ • Kaash Creative Corner 36 • Upcoming Events 38 • Birthdays 39 "Sir, first of all we congratulate to you and your energetic team for KAASH KONNECT. Your conducting so many activities for the betterment of community. These type of efforts really needed for the development of Indians. I personally like, your doing the documentation of these activities through the Kaash Konnect. It will be really helpful to our next generation. My best wishes to your sincere work." Ashok Pandurang Ghule Assistant Registrar Mumbai University Page 2 Issue No. 3: July - September 2020 KAASH Konnect INTERNATIONAL FACULTY DEVELOPMENT nd PROGRAM ON PEDAGOGY OF TEACHING HISTORY 2 by Pamela Dhonde A Teacher affects eternity, he can never tell organised its 2nd International Faculty where his influence stops. Development Program on Pedagogy of Teaching History. Held in collaboration - Henry Brooks Adams with St. Xavier’s Institute of Education, Mumbai and endorsed by the University of he above lines by Henry Brooks Ottawa, Canada, the International Faculty Adams, an American Historian, Development Program spanned across spells out the vital role that a seven days i.e. -

12DLTDC COL 04R1.Qxd (Page 1)
DLD‰‰†‰KDLD‰‰†‰DLD‰‰†‰MDLD‰‰†‰C 4 LEISURE DELHI TIMES, THE TIMES OF INDIA MONDAY 12 MAY 2003 DAILY CROSSWORD BELIEVE IT OR NOT TELEVISION tvguide.indiatimes.com CINEMA DD I 1400 Kutumb 1300 Hit Machine Hindi LIVE ENGLISH FILMS p.m.), Priya (2.25 & 7.45 p.m.), Satyam C’plexes BOL TARA BOL (5 p.m. Only) 0902 Series 1430 Dhadkan 1330 Zabardast Hits 2205 Aus Tour of WI 03: WI TEARS OF THE SUN (A): (Bruce Willis, Monica Shelly von Strunkel 1500 Ghar Ek Mandir 1400 Back To Back vs. Aus, 4th Test, Day Bellucci) 3 C’s (12.15 & 10.15 p.m.), DT Cinemas HINDI FILMS 0930 India Invented: Holi- (11.45 a.m., 5.25 & 10.25 p.m.), PVR Saket (3.35 1530 Alpviram 1430 Zabardast Hits 4, Session 2&3 LIVE ISHQ VISHQ: (Shahid, Amrita, Shenaz) Delite, day Spl. for Children & 11.30 p.m.), PVR Vikaspuri (11 a.m. & 8.15 ARIES (March 21 - April 19) Irritating as various 1600 Kaun Apna Kaun 1500 Back to Back Chanakya (12.30 & 3.30 p.m.), DT Cinemas (12 1000 News in Sanskrit p.m.), PVR Naraina (11.45 a.m., 5.15 & 10.45 disputes are, you’d be well advised at least to lis- Paraya 1530 Hit Machine NEWS noon, 2.40, 5.25, 7.45 & 10.30 p.m.), Rachna, PVR 1005 India Invented: p.m.), Priya (11.50 a.m., 4.55 & ten to what others have to say. While it’s true that 1630 Malgudi Days 1600 Hotline Saket (11.30 a.m., 2.15, 5, 7.45 & 10.30 p.m.), Holiday Spl. -

No. SONG TITLE MOVIE/ALBUM SINGER 20001 AA AA BHI JA
No. SONG TITLE MOVIE/ALBUM SINGER 20001 AA AA BHI JA TEESRI KASAM LATA MANGESHKAR 20002 AA AB LAUT CHALE JIS DESH MEIN GANGA BEHTI HAI MUKESH, LATA 20003 AA CHAL KE TUJHE DOOR GAGAN KI CHHAON MEIN KISHOE KUMAR 20004 AA DIL SE DIL MILA LE NAVRANG ASHA BHOSLE 20005 AA GALE LAG JA APRIL FOOL MOHD. RAFI 20006 AA JAANEJAAN INTEQAM LATA MANGESHKAR 20007 AA JAO TADAPTE HAI AAWAARA LATA MANGESHKAR 20008 AA MERE HUMJOLI AA JEENE KI RAAH LATA, MOHD. RAFI 20009 AA MERI JAAN CHANDNI LATA MANGESHKAR 20010 AADAMI ZINDAGI VISHWATMA MOHD. AZIZ 20011 AADHA HAI CHANDRAMA NAVRANG MAHENDRA & ASHA BHOSLE 20012 AADMI MUSAFIR HAI APNAPAN LATA, MOHD. RAFI 20013 AAGE BHI JAANE NA TU WAQT ASHA BHOSLE 20014 AAH KO CHAHIYE MIRZA GAALIB JAGJEET SINGH 20015 AAHA AYEE MILAN KI BELA AYEE MILAN KI BELA ASHA, MOHD. RAFI 20016 AAI AAI YA SOOKU SOOKU JUNGLEE MOHD. RAFI 20017 AAINA BATA KAISE MOHABBAT SONU NIGAM, VINOD 20018 AAJ HAI DO OCTOBER KA DIN PARIVAR LATA MANGESHKAR 20019 AAJ KAL PAANV ZAMEEN PAR GHAR LATA MANGESHKAR 20020 AAJ KI RAAT PIYA BAAZI GEETA DUTT 20021 AAJ KI SHAAM TAWAIF ASHA BHOSLE 20022 AAJ MADAHOSH HUA JAAYE RE SHARMILEE LATA, KISHORE 20023 AAJ MAIN JAWAAN HO GAYI HOON MAIN SUNDAR HOON LATA MANGESHKAR 20024 AAJ MAUSAM BADA BEIMAAN HAI LOAFER MOHD. RAFI 20025 AAJ MERE MAAN MAIN SAKHI AAN LATA MANGESHKAR 20026 AAJ MERE YAAR KI SHAADI HAI AADMI SADAK KA MOHD.RAFI 20027 AAJ NA CHHODENGE KATI PATANG KISHORE KUMAR, LATA 20028 AAJ PHIR JEENE KI GUIDE LATA MANGESHKAR 20029 AAJ PURANI RAAHON SE AADMI MOHD. -

Haal E Dil Tujhko Sunata Song Download Pagalworld
Haal e dil tujhko sunata song download pagalworld CLICK TO DOWNLOAD Description. renuzap.podarokideal.ru muder 2 download mp3 n video link renuzap.podarokideal.ru Watch the complete video song 'Haal e dil tujhko sunata' of movie Murder 2 . list of Haal E Dil (), Download Hale Dil Tujhko Sunata Murder 2 Full Song Emraan Hashmi mp3 for free. Haal E Dil ( MB) song and listen to Haal E Dil popular song on renuzap.podarokideal.ru 09/05/ · Hale Dil Lyrics & pdf – Harshit Saxena – Murder 2. The Haal E Dil Tujhko Sunata Lyrics from Emraan Hashmi and Jacqueline Fernandes’s Movie Murder 2. If there are any mistakes in the Haal E Dil Tujhko Sunata Lyrics, kindly post below in the comments section, we will rectify it . Hale Dil Tujhko Sunata Cover Download In 64 KBPS - mb Download In KBPS - mb Download In KBPS - mb Download In KBPS - mb Previous Track» Aankhon Mein Aansoon New Cover Mp3 Song Next Track» Network New Punjabi Cover Mp3 Song. The Haal E Dil Tujhko Sunata Lyrics from Emraan Hashmi and Jacqueline Fernandes’s Movie Murder 2. If there are any mistakes in the Haal E Dil Tujhko Sunata Lyrics, kindly post below in the comments section, we will rectify it as soon as possible.. Mahesh Bhatt’s Vishesh Films Banner presents Murder 2 is Directed by Mohit Suri. Haal E Dil Tujhko Sunata Music been composed by Harshit Saxena. 30/05/ · Hale Dil MP3 Song by Harshit Saxena from the movie Murder 2. Download Hale Dil (हाले िदल) song on renuzap.podarokideal.ru and listen Murder 2 Hale Dil song offline. -
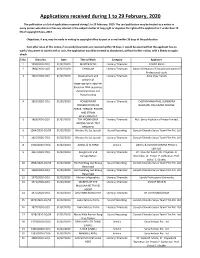
Applications Received During 1 to 29 February, 2020
Applications received during 1 to 29 February, 2020 The publication is a list of applications received during 1 to 29 February, 2020. The said publication may be treated as a notice to every person who claims or has any interest in the subject matter of Copyright or disputes the rights of the applicant to it under Rule 70 (9) of Copyright Rules, 2013. Objections, if any, may be made in writing to copyright office by post or e-mail within 30 days of the publication. Even after issue of this notice, if no work/documents are received within 30 days, it would be assumed that the applicant has no work / document to submit and as such, the application would be treated as abandoned, without further notice, with a liberty to apply afresh. S.No. Diary No. Date Title of Work Category Applicant 1 1959/2020-CO/L 01/02/2020 MASTER SCAN Literary/ Dramatic FAHAD KHAN 2 1960/2020-CO/L 01/02/2020 Certificate Literary/ Dramatic Swami Vivekanand Educational Council of Professional study 3 1961/2020-CO/L 01/02/2020 Development and Literary/ Dramatic Asha Vijay Durafe analysis of steganographic algoritm based on DNA sequence, dynamical chaos and fractal coding 4 1962/2020-CO/L 01/02/2020 POWERPOINT Literary/ Dramatic CHETAN MAHATME, SURENDRA PRESENTATION ON NAGPURE, RAJKUMAR CHADGE FORCE, TORQUE, POWER AND STRAIN MEASUREMENT 5 1963/2020-CO/L 01/02/2020 THE WORKHORSE Literary/ Dramatic M/s. Servo Hydraulics Private Limited, AMONG VALVE TEST BENCHES! 6 1964/2020-CO/SR 01/02/2020 Bhataru Ke Sut Jayeda Sound Recording Ganesh Chandra Surya Team Film Pvt. -

Mahesh Bhatt Филм ÑÐ ¿Ð¸ÑÑ ŠÐº (ФилмографиÑ)
Mahesh Bhatt Филм ÑÐ ¿Ð¸ÑÑ ŠÐº (ФилмографиÑ) The Gentleman https://bg.listvote.com/lists/film/movies/the-gentleman-11270582/actors Dhun https://bg.listvote.com/lists/film/movies/dhun-15637724/actors Chaahat https://bg.listvote.com/lists/film/movies/chaahat-1058193/actors Abhimanyu https://bg.listvote.com/lists/film/movies/abhimanyu-10990569/actors Lahu Ke Do Rang https://bg.listvote.com/lists/film/movies/lahu-ke-do-rang-11007191/actors Jurm https://bg.listvote.com/lists/film/movies/jurm-11047430/actors Saatwan Aasman https://bg.listvote.com/lists/film/movies/saatwan-aasman-11051382/actors Duplicate https://bg.listvote.com/lists/film/movies/duplicate-1121918/actors Thikana https://bg.listvote.com/lists/film/movies/thikana-11274071/actors Kabhie Kabhie https://bg.listvote.com/lists/film/movies/kabhie-kabhie-12418180/actors Papa Kehte Hai https://bg.listvote.com/lists/film/movies/papa-kehte-hai-12437665/actors Gumrah https://bg.listvote.com/lists/film/movies/gumrah-16248726/actors Aaj https://bg.listvote.com/lists/film/movies/aaj-18109318/actors Naya Daur https://bg.listvote.com/lists/film/movies/naya-daur-19573253/actors Hum Hain Rahi Pyar Ke https://bg.listvote.com/lists/film/movies/hum-hain-rahi-pyar-ke-2060167/actors The Silent Heroes https://bg.listvote.com/lists/film/movies/the-silent-heroes-24904900/actors Aashiqui https://bg.listvote.com/lists/film/movies/aashiqui-2820108/actors Daddy https://bg.listvote.com/lists/film/movies/daddy-3011754/actors Naajayaz https://bg.listvote.com/lists/film/movies/naajayaz-3334649/actors -

Blair Opens up on Sex and Politics
WORLD: PAGE 5 SPORTS: PAGE 11 MAGAZINE: PAGE 16 WASHINGTON: OBAMA HOLLYWOOD LOVES WADES INTO MIDDLE CRICKET: PAKISTAN STARS DEPART HALLOWEEN: FEASTS ON EAST PEACE EFFORT FOR BETTING SCAM PROBE THE WEIRD AND WACKY theVOL 1, NO 250, PORT LOUIS Independent THURSDAY, SEPTEMBER 2, 2010 ● 16 PAGES ● RS 10 DAILY NEWSDIGEST ADSU tightens Minister Choonee files France teams up with complaint for slander airport arrival checks PORT LOUIS: Minister of Arts and Culture Mookhesswur Independent News Service Police also managed to nab his Choonee lodged a complaint Plaisance, September 1 other local accomplices. at the Independent Broadcast- Since the arrest of Ndrenato, ing Authority (IBA) against a Officers of the Anti Drug police has been on alert. After island on key issues Smuggling Unit (ADSU) based brown sugar and Subutex, the private radio station on Wednesday. He stated that his at the Sir Seewoosagur Ram- police are working hard to pre- comments have been wrongly TO JOIN FORCES WITH MAURITIUS ON TOURISM, CULTURE, INFRASTRUCTURE, EDUCATION goolam International Airport at vent heroin from hitting the reported and this has tar- Plaisance are under strict or- market too. FRANCK THIBAULT nished his image. The contro- ders to maintain a rigid control The ADSU has been work- versy is about the speech of over the movement of any sus- ing closely with the anti drug the minister at an event organ- picious passengers, especially unit of Madagascar, Tanzania ised by the Vaish Welfare Asso- those arriving from Madagas- and Uganda and the Sub Re- ciation lasst Sunday. RELATED car, Tanzania and Uganda. gional Bureau of Interpol as STORY ON PAGE 2 There are growing fears that well as the Mauritius Revenue the country is increasingly be- Authority and the customs. -

SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I the Birth of Cinema Lumie
B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I The birth of cinema Lumier brother’s package The Grand father of Indian cinema: Dada Saheb Phalke The silent era (1896-1930) The talkie era and decade wise trend up to 1990 The new trends in Indian cinema (1991-2007) UNIT – II The brief study and analysis of trend setter film directors V ShantaramSohrab ModiMehboob KhanVijay BhattWadia brothersRaj KapoorGuruduttBimal RoySatyajit RayB. R. Chopra Yash ChopraHrishikesh Mukherjee Chetan Anand Basu Chaterjee Sai ParanjapeGuljarBasu BhattacharyaMahesh Bhatt Ramesh SippyShyam BenegalKetan MehtaGovind Nihlani Suraj BarjatyaVidhu Vinod ChopraJ P DuttaSanjay Leela Bhansali Ramgopal VermaKaran JojarAditya Chopra Raj kumar santoshi Rakesh Mehra Rj kumar Hirani UNIT – III Film as an art Film and painting Film and theatre Film and literature Film and music UNIT – IV Film language and grammar (A)Shot, scene & cut, (B)Camera Distance, (C) Camera Angles, (D)Camera movements (E) Lighting (F) Sound in films (G) Film Editing devices UNIT – V Film institutions in India Film festivals (National and International) Film awards Film censorships 45, Anurag Nagar, Behind Press Complex, Indore (M.P.) Ph.: 4262100, www.rccmindore.com 1 B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism UNIT I THE BIRTH OF CINEMA Lumiere brothers The Lumiere brothers were born in Besancon, France, in 1862 and 1864, and moved to Lyon in 1870. This is where they spent most of their lives and where their father ran a photographic firm. The brothers worked there starting at a young age but never started experimenting with moving film until after their father had died in 1892.The brothers worked on their new film projects for years, Auguste making the first experiments. -

SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I the Birth of Cinema Lumie
B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism SYLLABUS Class – B.A. (HONS.) MASS COMMUNICATION VI Semester Subject – Film Journalism UNIT – I The birth of cinema Lumier brother’s package The Grand father of Indian cinema: Dada Saheb Phalke The silent era (1896-1930) The talkie era and decade wise trend up to 1990 The new trends in Indian cinema (1991-2007) UNIT – II The brief study and analysis of trend setter film directors V ShantaramSohrab ModiMehboob KhanVijay BhattWadia brothersRaj KapoorGuruduttBimal RoySatyajit RayB. R. Chopra Yash ChopraHrishikesh Mukherjee Chetan Anand Basu Chaterjee Sai ParanjapeGuljarBasu BhattacharyaMahesh Bhatt Ramesh SippyShyam BenegalKetan MehtaGovind Nihlani Suraj BarjatyaVidhu Vinod ChopraJ P DuttaSanjay Leela Bhansali Ramgopal VermaKaran JojarAditya Chopra Raj kumar santoshi Rakesh Mehra Rj kumar Hirani UNIT – III Film as an art Film and painting Film and theatre Film and literature Film and music UNIT – IV Film language and grammar (A)Shot, scene & cut, (B)Camera Distance, (C) Camera Angles, (D)Camera movements (E) Lighting (F) Sound in films (G) Film Editing devices Film institutions in India Film festivals (National and International) Film awards Film censorships 45, Anurag Nagar, Behind Press Complex, Indore (M.P.) Ph.: 4262100, www.rccmindore.com 1 B.A. (HONS.) Mass Communication VI Semester Subject – Film Journalism UNIT I THE BIRTH OF CINEMA The Lumiere brothers were born in Besancon, France, in 1862 and 1864, and moved to Lyon in 1870. This is where they spent most of their lives and where their father ran a photographic firm. The brothers worked there starting at a young age but never started experimenting with moving film until after their father had died in 1892.The brothers worked on their new film projects for years, Auguste making the first experiments. -

91Juoi9zcjs.Pdf
STATION - 90's CHARTBUSTERS No Track Artists Album Duration 1 Roja (Version 1) S.P. Balasubrahmanyam, K.S. Chithra Roja 0:05:06 2 Jab Kisiki Taraf Dil Kumar Sanu Pyaar To Hona Hi Tha 0:06:55 3 Ae Kash Ke Hum Kumar Sanu Kabhi Haan Kabhi Naa 0:05:07 4 Piya Basanti Ustad Sultan Khan, K.S. Chithra Piya Basanti 0:04:33 5 Yeh Haseen Vadiyan Yeh Khula Aasman S.P. Balasubrahmanyam, K.S. Chithra Roja 0:05:20 6 Yaaron KK Rockford 0:04:33 7 Woh Pehli Baar Shaan Pyaar Mein Kabhi Kabhi 0:04:23 8 Chhoti Si Aasha (Version 1) Minmini Roja 0:04:57 9 Pyaar Ke Pal KK Pal 0:06:02 10 Hai Na Udit Narayan, Alka Yagnik Zubeidaa 0:04:58 11 O Sanam Lucky Ali Sunoh 0:03:43 12 Dooba Dooba Silk Route Boondein 0:05:03 13 Dekha Hai Aise Bhi Lucky Ali Sifar 0:03:58 14 Aur Kya Alka Yagnik, Abhijeet Phir Bhi Dil Hai Hindustani 0:05:03 15 Ajnabi Mujhko Itna Bata Udit Narayan, Asha Bhosle Pyaar To Hona Hi Tha 0:06:13 16 Pyar Ke Liye Alka Yagnik Dil Kya Kare 0:05:02 17 Kuch Kuch Hota Hai Udit Narayan, Alka Yagnik Kuch Kuch Hota Hai 0:04:57 18 Neele Neele Ambar Par (Male) Kishore Kumar Kalaakaar 0:05:20 19 Aye Zindagi Gale Lagaa Le Suresh Wadkar Sadma 0:05:30 20 Agar Tum Na Hote (Male) Kishore Kumar Agar Tum Na Hote 0:04:09 21 Surmayee Ankhiyon Mein Happy K.J. -
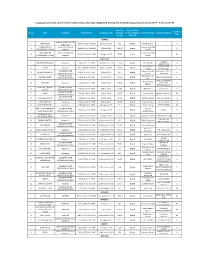
Language Wise List of the Feature Films Indian/Foreign (Digital & Video)
Language wise List of the feature films Indian/Foreign (Digital & Video) Certified during period (01/01/2019 - 01/12/2019) Certified Type Of Film Certificate Sr. No Title Language Certificate No. Certificate Date Duration/ (Video/Digital/C Producer Name Production House Type Length elluloid) ARABIC ARABIC WITH ENGLISH 1 YOMEDDINE DFL/1/16/2019-MUM 26 March 2019 99.2 Digital WILD BUNCH - U SUBTITLES CAPHARNAUM ( Arabic With English Capharnaum Film 2 DFL/3/25/2019-MUM 02 May 2019 128.08 Digital - A CHILDREN OF CHAOS) Subtitles Ltd BVI CAPHARNAUM Arabic with English Capharnaum Film 3 VFL/2/448/2019-MUM 13 August 2019 127.54 Video - UA (CHILDREN OF CHAOS) Subtitles Ltd BVI ASSAMESE DREAM 1 KOKAIDEU BINDAAS Assamese DIL/1/1/2019-GUW 14 February 2019 120.4 Digital Rahul Modi U PRODUCTION Ajay Vishnu Children's Film 2 GATTU Assamese DIL/1/59/2019-MUM 22 March 2019 74.41 Digital U Chavan Society, India ASSAMESE WITH Anupam Kaushik Bhaworiya - The T- 3 BORNODI BHOTIAI DIL/1/5/2019-GUW 18 April 2019 120 Digital U ENGLISH SUBTITLES Borah Posaitives ASSAMESE WITH Kunjalata Gogoi 4 JANAKNANDINI DIL/1/8/2019-GUW 25 June 2019 166.23 Digital NIZI PRODUCTION U ENGLISH SUBTITLES Das SKYPLEX MOTION Nazim Uddin 5 ASTITTWA Assamese DIL/1/9/2019-GUW 04 July 2019 145.03 Digital PICTURES U Ahmed INTERNATIONAL FIREFLIES... JONAKI ASSAMESE WITH 6 DIL/3/2/2019-GUW 04 July 2019 93.06 Digital Milin Dutta vortex films A PORUA ENGLISH SUBTITLES ASSAMESE WITH 7 AAMIS DIL/2/4/2019-GUW 10 July 2019 109.07 Digital Poonam Deol Signum Productions UA ENGLISH SUBTITLES ASSAMESE WITH 8 JI GOLPOR SES NAI DIL/3/3/2019-GUW 26 July 2019 94.55 Digital Krishna Kalita M/S.