A Glottometric Subgrouping of the Early Germanic Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Old Norse Mythology — Comparative Perspectives Old Norse Mythology— Comparative Perspectives
Publications of the Milman Parry Collection of Oral Literature No. 3 OLd NOrse MythOLOgy — COMParative PersPeCtives OLd NOrse MythOLOgy— COMParative PersPeCtives edited by Pernille hermann, stephen a. Mitchell, and Jens Peter schjødt with amber J. rose Published by THE MILMAN PARRY COLLECTION OF ORAL LITERATURE Harvard University Distributed by HARVARD UNIVERSITY PRESS Cambridge, Massachusetts & London, England 2017 Old Norse Mythology—Comparative Perspectives Published by The Milman Parry Collection of Oral Literature, Harvard University Distributed by Harvard University Press, Cambridge, Massachusetts & London, England Copyright © 2017 The Milman Parry Collection of Oral Literature All rights reserved The Ilex Foundation (ilexfoundation.org) and the Center for Hellenic Studies (chs.harvard.edu) provided generous fnancial and production support for the publication of this book. Editorial Team of the Milman Parry Collection Managing Editors: Stephen Mitchell and Gregory Nagy Executive Editors: Casey Dué and David Elmer Production Team of the Center for Hellenic Studies Production Manager for Publications: Jill Curry Robbins Web Producer: Noel Spencer Cover Design: Joni Godlove Production: Kristin Murphy Romano Library of Congress Cataloging-in-Publication Data Names: Hermann, Pernille, editor. Title: Old Norse mythology--comparative perspectives / edited by Pernille Hermann, Stephen A. Mitchell, Jens Peter Schjødt, with Amber J. Rose. Description: Cambridge, MA : Milman Parry Collection of Oral Literature, 2017. | Series: Publications of the Milman Parry collection of oral literature ; no. 3 | Includes bibliographical references and index. Identifers: LCCN 2017030125 | ISBN 9780674975699 (alk. paper) Subjects: LCSH: Mythology, Norse. | Scandinavia--Religion--History. Classifcation: LCC BL860 .O55 2017 | DDC 293/.13--dc23 LC record available at https://lccn.loc.gov/2017030125 Table of Contents Series Foreword ................................................... -

An Automatic Part-Of-Speech Tagger for Middle Low German
An automatic part-of-speech tagger for Middle Low German Mariya Koleva, Melissa Farasyn, Bart Desmet, Anne Breitbarth and Véronique Hoste Ghent University Syntactically annotated corpora are highly important for enabling large-scale diachronic and diatopic language research. Such corpora have recently been developed for a variety of historical languages, or are still under development. One of those under development is the fully tagged and parsed Corpus of Historical Low German (CHLG), which is aimed at facilitating research into the highly under-researched diachronic syntax of Low German. The present paper reports on a crucial step in creating the corpus, viz. the creation of a part-of-speech tagger for Middle Low German (MLG). Having been transmitted in several non-standardised written varieties, MLG poses a challenge to standard POS taggers, which usually rely on normalized spelling. We outline the major issues faced in the creation of the tagger and present our solutions to them. Keywords: historical linguistics, part-of-speech tagging, conditional random fields, feature selection, normalization 1. Introduction Corpora of historical texts annotated with different levels of grammatical information, such as parts of speech, (inflectional) morphology, syntactic chunks, clausal syntax, provide an important resource for studies of diachronic syntactic variation and change (e.g. Kroch et al. 2000, Rögnvaldsson & Helgadóttir 2011). They enable the automatic extraction of syntactic information from historical texts (more than is manually possible), and allow making statistically valid observations. Apart from reducing the amount of time required for data retrieval, an important advantage is that they make research testable and replicable. The Corpus of Historical Low German (CHLG) (Breitbarth et al. -

Dynamics of Religious Ritual: Migration and Adaptation in Early Medieval Britain
Dynamics of Religious Ritual: Migration and Adaptation in Early Medieval Britain A Dissertation SUBMITTED TO THE FACULTY OF THE UNIVERSITY OF MINNESOTA BY Brooke Elizabeth Creager IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY Peter S. Wells August 2019 Brooke Elizabeth Creager 2019 © For my Mom, I could never have done this without you. And for my Grandfather, thank you for showing me the world and never letting me doubt I can do anything. Thank you. i Abstract: How do migrations impact religious practice? In early Anglo-Saxon England, the practice of post-Roman Christianity adapted after the Anglo-Saxon migration. The contemporary texts all agree that Christianity continued to be practiced into the fifth and sixth centuries but the archaeological record reflects a predominantly Anglo-Saxon culture. My research compiles the evidence for post-Roman Christian practice on the east coast of England from cemeteries and Roman churches to determine the extent of religious change after the migration. Using the case study of post-Roman religion, the themes religion, migration, and the role of the individual are used to determine how a minority religion is practiced during periods of change within a new culturally dominant society. ii Table of Contents Abstract …………………………………………………………………………………...ii List of Figures ……………………………………………………………………………iv Preface …………………………………………………………………………………….1 I. Religion 1. Archaeological Theory of Religion ...………………………………………………...3 II. Migration 2. Migration Theory and the Anglo-Saxon Migration ...……………………………….42 3. Continental Ritual Practice before the Migration, 100 BC – AD 400 ………………91 III. Southeastern England, before, during and after the Migration 4. Contemporary Accounts of Religion in the Fifth and Sixth Centuries……………..116 5. -

Explorationsprojekt Sterup Planung
Zusammenfassung Februar 2014 Explorationsprojekt Sterup Informationsschreiben Abbildung 1: Lage des Lizenzgebietes Sterup. Quelle: LBEG Jahresbericht 2012 Stand: Februar 2014 Zuteilung der Erlaubnislizenz ist im Dezember 2013 erfolgt und gilt bis 30.11.2016. Arbeitsprogramm 2014 besteht aus geologischen Studien und mikrobieller Probennahme. Weitere geplante operative Arbeiten 2015 und 2016 sind durch Betriebsplanverfahren und Anhörungen vorab zu genehmigen. CA schafft Öffentlichkeit und Transparenz für alle Aktivitäten. Es wird regelmäßig an den geplanten Informationsbeirat berichtet werden. Allgemeines Die Central Anglia AS, Oslo, plant ab 2014 im Kreis Schleswig-Flensburg, Schleswig-Holstein, auf konventionelle Weise nach Öl und Gas zu suchen. Bisher waren die Gründer der Central Anglia für Großunternehmen schwerpunktmäßig im skandinavischen und deutschen Explorationsgeschäft tätig. Die über viele Jahre gewonnene Expertise ist die Grundlage für ein Engagement auch in Deutschland. Die vermutete Lagerstätte in der Lizenz Sterup liegt in Sandsteinschichten aus der Jura-und Triaszeit in 1.100-1.400 m Tiefe. Die Reservoireigenschaften sind aus Nachbarbohrungen bekannt und sind so gut, dass im Erfolgsfall rein konventionell gefördert werden kann und keinerlei Bezug zu der umstrittenen „Fracking-Technologie“ bestehen wird. Fracking ist kein Thema oder Geschäftsfeld für Cental Anglia. Sterup: Lage des Lizenzgebietes mit seismischen Linien, Lage des Salzstockes und geologischer Querschnitt durch die Lizenz Die bisher nur vermutete Lagerstätte ist nach Abschluss der laufenden geologischen Studien im Jahre 2015 durch seismische Vermessungen zu bestätigen. Das Einmessen von Seismiklinien stellt eine Verdichtung bereits vorhandener Linien dar, die in der 1 Explorationsprojekt Sterup - Informationsschreiben Vergangenheit gemessen wurden, wird aber nicht wie früher mit Sprengseismik sondern mit Vibratortechnik vermessen und dient der genaueren Definition der Gesteinslagerung im Untergrund. -

《International Symposium》 Let's Talk About Trees National Museum
《International Symposium》 Let’s Talk about Trees National Museum of Ethnology, Osaka, Japan. February 10, 2013 Abstract [Austronesian Language Case Studies 2] Limitations of the tree model: A case study from North Vanuatu Siva KALYAN1 and Alexandre FRANÇOIS2 1. Northumbria University 2. CNRS/LACITO Since the beginnings of historical linguistics, the family tree has been the most widely accepted model for representing historical relations between languages. It is even being reinvigorated by current research in computational phylogenetics (e.g. Gray et al. 2009). While this sort of representation is certainly easy to grasp, and allows for a simple, attractive account of the development of a language family, the assumptions made by the tree model are applicable in only a small number of cases. The tree model is appropriate when a speaker population undergoes successive splits, with subsequent loss of contact among subgroups. For all other scenarios, it fails to provide an accurate representation of language history (cf. Durie & Ross 1996; Pawley 1999; Heggarty et al. 2010). In particular, it is unable to deal with dialect continua, as well as language families that develop out of dialect continua (for which Ross 1988 has proposed the term "linkage"). In such cases, the scopes of innovations (in other words, their isoglosses) are not nested, but rather they persistently intersect, so that any proposed tree representation is met with abundant counterexamples. Though Ross's initial observations about linkages concerned the languages of Western Melanesia, it is clear that linkages are found in many other areas as well (such as Fiji: cf. Geraghty 1983). In this presentation, we focus on the 17 languages of the Torres and Banks islands in Vanuatu, which form a linkage (Tryon 1996, François 2011), and attempt to develop adequate representations for it. -

The Shared Lexicon of Baltic, Slavic and Germanic
THE SHARED LEXICON OF BALTIC, SLAVIC AND GERMANIC VINCENT F. VAN DER HEIJDEN ******** Thesis for the Master Comparative Indo-European Linguistics under supervision of prof.dr. A.M. Lubotsky Universiteit Leiden, 2018 Table of contents 1. Introduction 2 2. Background topics 3 2.1. Non-lexical similarities between Baltic, Slavic and Germanic 3 2.2. The Prehistory of Balto-Slavic and Germanic 3 2.2.1. Northwestern Indo-European 3 2.2.2. The Origins of Baltic, Slavic and Germanic 4 2.3. Possible substrates in Balto-Slavic and Germanic 6 2.3.1. Hunter-gatherer languages 6 2.3.2. Neolithic languages 7 2.3.3. The Corded Ware culture 7 2.3.4. Temematic 7 2.3.5. Uralic 9 2.4. Recapitulation 9 3. The shared lexicon of Baltic, Slavic and Germanic 11 3.1. Forms that belong to the shared lexicon 11 3.1.1. Baltic-Slavic-Germanic forms 11 3.1.2. Baltic-Germanic forms 19 3.1.3. Slavic-Germanic forms 24 3.2. Forms that do not belong to the shared lexicon 27 3.2.1. Indo-European forms 27 3.2.2. Forms restricted to Europe 32 3.2.3. Possible Germanic borrowings into Baltic and Slavic 40 3.2.4. Uncertain forms and invalid comparisons 42 4. Analysis 48 4.1. Morphology of the forms 49 4.2. Semantics of the forms 49 4.2.1. Natural terms 49 4.2.2. Cultural terms 50 4.3. Origin of the forms 52 5. Conclusion 54 Abbreviations 56 Bibliography 57 1 1. -

Scandinavian Word Phonology: Evidence for a Typological Cycle
Kurt Braunmüller (Hamburg University): Scandinavian word phonology: evidence for a typological cycle 1. The Germanic languages: phonological principles and drift (a) Grimm‟s and Verner‟s Law, (b) consequent placement of stress on the first sylla- ble of a word, (c) subsequent reduction of vowels in unstressed syllables (cf. Gothic /i, a, u/ or Faroese /e [< ], a/) but there are also languages with schwa (/ë/) or apocope: //. Drift: (1) Dominance of monosyllabic words with complex consonant clusters in the coda, (2) this could give rise to the origin of (simple) tone languages (e.g. in SE Jutish, cf. Braunmüller 1995b/[1987]), in Low German and some Norwegian dialects), and (3) apocope and/or schwa (quite typical for many modern Germanic languages). 2. Intervening factors In the Scandinavian languages: (I) Emergence of (new) clitics, both in the nominal and the verbal part of grammar, (II) language contact (vowel harmony, new word formation elements), (III) language cultivation and language planning; moreover: com- plex consonant (C) clusters: in the onset (1–3 Cs), in the coda (with a max. of 5 Cs). 3. Splitting up Proto-Germanic: mainly a case of vowel change? Relative continuity of the consonantal frames (exception: [Old] High German); a short paradigmatic survey of this development: (1) Gallehus (about 425 AD): ek hlewagastiR holtijaR horna tawido (where the final R still represents [z] and not [r], as it did in later times) „I Legest, son of/from Holt, made [the] horn. (2) *ek[a] hlewa stiz hultijaz hurnan tawiðón. (Proto-Germanic) (3) *ik hliugasts hulteis haúrn tawida. (Gothic) (4) *ek hlégestr hyltir horn g{e|ø}rða [táða]. -

Indo-European: History, Families & Origins
Indo-European: History, Families & Origins 1 Historical Linguistics Early observations pointed to language relatedness: The Sanscrit language, whatever by its antiquity, is of a wonderful structure; more perfect than the Greek, more copious than the Latin, and more exquisitely refined than either, yet bearing to both of them a stronger affinity, both in the roots of verbs and in the forms of grammar, than could possibly have been produced by accident; so strong indeed, that no philologer could examine them all three, without believing them to have sprung from some common source, which, perhaps, no longer exists .... Sir William Jones -- Presidential Discourse at the February 2, 1786 meeting of the Asiatic Society 2 Darwin & Historical Linguistics Darwin's On The Origin of Species published in 1859 German biologist Ernst Haeckel persuades his friend - philologist August Schleicher, to read it Schleicher (and generations of historical linguists) apply evolutionary principle to comparative/historical linguistics 3 Test The Methodology Ferdinand de Saussure (1857-1913) used the comparative method to predict that a certain group of sounds had to have existed in Indo-European 20 years later, when Hittite texts were discovered, Saussure's laryngeals were attested! 4 Indo-European Family 5 Indo-European Homeland 6 Family Branching 7 Earliest Attestation of IE Daughter Languages Anatolian 17th c. B.C.E Indo-Aryan (Sanskrit) 15th c. B.C.E Greek 13th c. B.C.E. Iranian (Avestan / Old Persian) 7th c. B.C.E / 6th c. B.C.E. Italic 6th c. B.C.E Tocharian 6th c. B.C.E Germanic 1st c. -

Concepts and Methods of Historical Linguistics-The Germanic Family Of
CURSO 2016 - 2017 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS Tutor: Carlos Hernández Simón Sir William Jones, Jacob Grimm and Karl Verner from Lisa Minnick 2011: “Let them eat metaphors, Part 1: Order from Chaos and the Indo-European Hypothesis” Functional Shift https://functionalshift.wordpress.com/2011/10/09/metaphors1/ [retrieved February 17, 2017] CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS HISTORICAL AND COMPARATIVE LINGUISTICS AIMS OF STUDY 1) Language change and stability 2) Reconstruction of earlier stages of languages 3) Discovery and implementation of research methodologies Theodora Bynon (1981) 1) Grammars that result from the study of different time spans in the evolution of a language 2) Contrast them with the description of other related languages 3) Linguistic variation cannot be separated from sociological and geographical factors 3 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS ORIGINS • Renaissance: Contrastive studies of Greek and Latin • Nineteenth Century: Sanskrit 1) Acknowledgement of linguistic change 2) Development of the Comparative Method • Robert Beekes (1995) 1) The Greeks 2) Languages Change • R. Lawrence Trask (1996) 1) 6000-8000 years 2) Historical linguist as a kind of archaeologist 4 CONCEPTS AND METHODS OF HISTORICAL LINGUISTICS THE COMPARATIVE METHOD • Sir William Jones (1786): Greek, Sanskrit and Latin • Reconstruction of Proto-Indo-European • Regular principle of phonological change 1) The Neogrammarians 2) Grimm´s Law (1822) and Verner’s Law (1875) 3) Laryngeal Theory : Ferdinand de Saussure (1879) • Two steps: 1) Isolation of a set of cognates: Latin: decem; Greek: deca; Sanskrit: daśa; Gothic: taihun 2) Phonological correspondences extracted: 1. Latin d; Greek d; Sanskrit d; Gothic t 2. Latin e; Greek e; Sanskrit a; Gothic ai 3. -
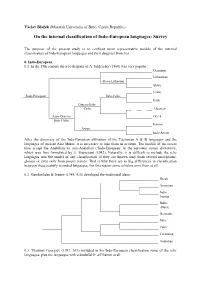
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

CHAPTER SEVENTEEN History of the German Language 1 Indo
CHAPTER SEVENTEEN History of the German Language 1 Indo-European and Germanic Background Indo-European Background It has already been mentioned in this course that German and English are related languages. Two languages can be related to each other in much the same way that two people can be related to each other. If two people share a common ancestor, say their mother or their great-grandfather, then they are genetically related. Similarly, German and English are genetically related because they share a common ancestor, a language which was spoken in what is now northern Germany sometime before the Angles and the Saxons migrated to England. We do not have written records of this language, unfortunately, but we have a good idea of what it must have looked and sounded like. We have arrived at our conclusions as to what it looked and sounded like by comparing the sounds of words and morphemes in earlier written stages of English and German (and Dutch) and in modern-day English and German dialects. As a result of the comparisons we are able to reconstruct what the original language, called a proto-language, must have been like. This particular proto-language is usually referred to as Proto-West Germanic. The method of reconstruction based on comparison is called the comparative method. If faced with two languages the comparative method can tell us one of three things: 1) the two languages are related in that both are descended from a common ancestor, e.g. German and English, 2) the two are related in that one is the ancestor of the other, e.g. -

Putting Frisian Names on the Map
GEGN.2/2021/68/CRP.68 15 March 2021 English United Nations Group of Experts on Geographical Names Second session New York, 3 – 7 May 2021 Item 12 of the provisional agenda * Geographical names as culture, heritage and identity, including indigenous, minority and regional languages and multilingual issues Putting Frisian names on the map Submitted by the Netherlands** * GEGN.2/2021/1 ** Prepared by Jasper Hogerwerf, Kadaster GEGN.2/2021/68/CRP.68 Introduction Dutch is the national language of the Netherlands. It has official status throughout the Kingdom of the Netherlands. In addition, there are several other recognized languages. Papiamentu (or Papiamento) and English are formally used in the Caribbean parts of the Kingdom, while Low-Saxon and Limburgish are recognized as non-standardized regional languages, and Yiddish and Sinte Romani as non-territorial minority languages in the European part of the Kingdom. The Dutch Sign Language is formally recognized as well. The largest minority language is (West) Frisian or Frysk, an official language in the province of Friesland (Fryslân). Frisian is a West Germanic language closely related to the Saterland Frisian and North Frisian languages spoken in Germany. The Frisian languages as a group are closer related to English than to Dutch or German. Frisian is spoken as a mother tongue by about 55% of the population in the province of Friesland, which translates to some 350,000 native speakers. In many rural areas a large majority speaks Frisian, while most cities have a Dutch-speaking majority. A standardized Frisian orthography was established in 1879 and reformed in 1945, 1980 and 2015.