Bushfire Weather Climatology Dataset Version 2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MINUTES AAA VIC Division Meeting
MINUTES AAA VIC Division Meeting Wednesday 7 August 2019 08:30 – 15:30 Holiday Inn Melbourne Airport Grand Centre Room, 10-14 Centre Road, Melbourne Airport Chair: Katie Cooper Attendees & Apologies: Please see attached 1. Introduction from Victorian Chair, Apologies, Minutes and Chair’s Report (Katie Cooper) • Introduced Daniel Gall, Deputy Chair for Vic Division • Provided overview of speakers for the day. • Dinner held previous evening which was a great way to meet and network – feedback welcome on if it is something you would like to see as an ongoing event Chairman’s Report Overview – • Board and Stakeholder dinner in Canberra with various industry and political leader and influences in attendance • AAA represented at the ACI Asia Pacific Conference and World AGM in Hong Kong • AAA Pavement & Lighting Forum held in Melbourne CBD with excellent attendance and positive feedback on its value to the industry • June Board Meeting in Brisbane coinciding with Qld Div meeting and dinner • Announcement of Federal Government $100M for regional airports • For International Airports, the current revisions of the Port Operators Guide for new and redeveloping ports which puts a lot of their costs onto industry is gaining focus from those affected industry members • MOS 139 changes update • Airport Safety Week in October • National Conference in November on the Gold Coast incl Women in Airports Forum • Launch of the new Corporate Member Advisory Panel (CMAP) which will bring together a panel of corporate members to gain feedback on issues impacting the AAA and wider airport sector and chaired by the AAA Chairman Thanks to Smiths Detection as the Premium Division Meetings Partner 2. -

VFR Flight Into Dark Night Conditions and Loss of Control Involving Piper PA-28-180, VH-POJ
VFR flight into dark night Insertconditions document and loss titleof control involving Piper PA-28-180, VH-POJ Location31 km north | Date of Horsham Airport, Victoria | 15 August 2011 ATSB Transport Safety Report Investigation [InsertAviation Mode] Occurrence Occurrence Investigation Investigation XX-YYYY-####AO -2011-10 0 Final – 3 December 2013 Released in accordance with section 25 of the Transport Safety Investigation Act 2003 Publishing information Published by: Australian Transport Safety Bureau Postal address: PO Box 967, Civic Square ACT 2608 Office: 62 Northbourne Avenue Canberra, Australian Capital Territory 2601 Telephone: 1800 020 616, from overseas +61 2 6257 4150 (24 hours) Accident and incident notification: 1800 011 034 (24 hours) Facsimile: 02 6247 3117, from overseas +61 2 6247 3117 Email: [email protected] Internet: www.atsb.gov.au © Commonwealth of Australia 2013 Ownership of intellectual property rights in this publication Unless otherwise noted, copyright (and any other intellectual property rights, if any) in this publication is owned by the Commonwealth of Australia. Creative Commons licence With the exception of the Coat of Arms, ATSB logo, and photos and graphics in which a third party holds copyright, this publication is licensed under a Creative Commons Attribution 3.0 Australia licence. Creative Commons Attribution 3.0 Australia Licence is a standard form license agreement that allows you to copy, distribute, transmit and adapt this publication provided that you attribute the work. The ATSB’s preference is that you attribute this publication (and any material sourced from it) using the following wording: Source: Australian Transport Safety Bureau Copyright in material obtained from other agencies, private individuals or organisations, belongs to those agencies, individuals or organisations. -

Collision with Terrain Involving Cessna 182, VH-KKM, 19 Km WSW Of
InsertCollision document with terrain title involving Cessna 182, VH-KKM Location19 km WSW | Date of Mount Hotham Airport, Victoria | 23 October 2013 ATSB Transport Safety Report Investigation [InsertAviation Mode] Occurrence Occurrence Investigation Investigation XX-YYYY-####AO-2013-186 Final – 16 April 2015 Cover photo: Aircraft owner Released in accordance with section 25 of the Transport Safety Investigation Act 2003 Publishing information Published by: Australian Transport Safety Bureau Postal address: PO Box 967, Civic Square ACT 2608 Office: 62 Northbourne Avenue Canberra, Australian Capital Territory 2601 Telephone: 1800 020 616, from overseas +61 2 6257 4150 (24 hours) Accident and incident notification: 1800 011 034 (24 hours) Facsimile: 02 6247 3117, from overseas +61 2 6247 3117 Email: [email protected] Internet: www.atsb.gov.au © Commonwealth of Australia 2015 Ownership of intellectual property rights in this publication Unless otherwise noted, copyright (and any other intellectual property rights, if any) in this publication is owned by the Commonwealth of Australia. Creative Commons licence With the exception of the Coat of Arms, ATSB logo, and photos and graphics in which a third party holds copyright, this publication is licensed under a Creative Commons Attribution 3.0 Australia licence. Creative Commons Attribution 3.0 Australia Licence is a standard form license agreement that allows you to copy, distribute, transmit and adapt this publication provided that you attribute the work. The ATSB’s preference is that you attribute this publication (and any material sourced from it) using the following wording: Source: Australian Transport Safety Bureau Copyright in material obtained from other agencies, private individuals or organisations, belongs to those agencies, individuals or organisations. -
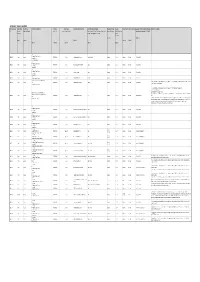
The Table of Services (PDF)
APPENDIX 1: TABLE OF SERVICES Proposed Service Contract type Availability Brief Service Description Airframe Aircraft Type Nominated Operational Base Firebombing Delivery System Passenger Carriage Fuelling Service Period Approximate timing Specimen Contract applicable Schedules Additional Information ID Primary / Absolute / Partial RW / FW Type 1 / Type 2 / Type 3 Tank / Bucket / (Bucket) / Long line bucket / Tank or Required / Optional Wet-A Hire / Wet- (in addition to Schedules 1, 2, 3,4, & 5) Secondary bucket / Tank (preferred) or Bucket B Hire / Dry Hire (Note 7) (Note 11) (Note 1) (Note 2) (Note 5) (Note 9) (Note 10) (Note 3) (Note 4) (Note 4) (Note 6) (Note 8) AAS Firefighter & Cargo Transport RW21302 Primary Absolute ROTARY WING Type 3 Moorabbin Airport, Victoria Bucket (Optional) Required Wet-B 14 weeks Dec-Mar Schedules A & B Burning (Note 14) Firebombing (optional) AAS Firefighter & Cargo Transport RW21303 Primary Absolute ROTARY WING Type 3 Ovens helibase, Victoria (Note A) Bucket Required Wet-B 14 weeks Dec-Mar Schedules A & B Firebombing Burning (Note 14) AAS Firefighter & Cargo Transport RW21304 Primary Absolute ROTARY WING Type 3 Bairnsdale, Victoria Bucket Required Wet-B 14 weeks Dec-Mar Schedules A & B Firebombing Burning (Note 14) AAS RW21305 Primary Absolute ROTARY WING Type 3 Bendigo Airport, Victoria (Bucket) Required Wet-B 14 weeks Dec-Mar Schedules B Burning (preferred) (Note 14) Airborne Information Gathering (AIG) (Note 16) This Service requires a specific configuration to support regular 'airborne information gathering' operations (Refer to Section 2.1 of Part B RW21307 Primary Absolute AAS ROTARY WING Type 3 Moorabbin Airport, Victoria (Bucket) Required Wet-B 14 weeks Dec-Mar Schedules B & C in the Invitation to Tender document). -

St Helens Aerodrome Assess Report
MCa Airstrip Feasibility Study Break O’ Day Council Municipal Management Plan December 2013 Part A Technical Planning & Facility Upgrade Reference: 233492-001 Project: St Helens Aerodrome Prepared for: Break Technical Planning and Facility Upgrade O’Day Council Report Revision: 1 16 December 2013 Document Control Record Document prepared by: Aurecon Australia Pty Ltd ABN 54 005 139 873 Aurecon Centre Level 8, 850 Collins Street Docklands VIC 3008 PO Box 23061 Docklands VIC 8012 Australia T +61 3 9975 3333 F +61 3 9975 3444 E [email protected] W aurecongroup.com A person using Aurecon documents or data accepts the risk of: a) Using the documents or data in electronic form without requesting and checking them for accuracy against the original hard copy version. b) Using the documents or data for any purpose not agreed to in writing by Aurecon. Report Title Technical Planning and Facility Upgrade Report Document ID 233492-001 Project Number 233492-001 File St Helens Aerodrome Concept Planning and Facility Upgrade Repot Rev File Path 0.docx Client Break O’Day Council Client Contact Rev Date Revision Details/Status Prepared by Author Verifier Approver 0 05 April 2013 Draft S.Oakley S.Oakley M.Glenn M. Glenn 1 16 December 2013 Final S.Oakley S.Oakley M.Glenn M. Glenn Current Revision 1 Approval Author Signature SRO Approver Signature MDG Name S.Oakley Name M. Glenn Technical Director - Title Senior Airport Engineer Title Airports Project 233492-001 | File St Helens Aerodrome Concept Planning and Facility Upgrade Repot Rev 1.docx | -

2010-11 Victorian Floods Rainfall and Streamflow Assessment Project
Review by: 2010-11 Victorian Floods Rainfall and Streamflow Assessment Project December 2012 ISO 9001 QEC22878 SAI Global Department of Sustainability and Environment 2010-11 Victorian Floods – Rainfall and Streamflow Assessment DOCUMENT STATUS Version Doc type Reviewed by Approved by Date issued v01 Report Warwick Bishop 02/06/2012 v02 Report Michael Cawood Warwick Bishop 07/11/2012 FINAL Report Ben Tate Ben Tate 07/12/2012 PROJECT DETAILS 2010-11 Victorian Floods – Rainfall and Streamflow Project Name Assessment Client Department of Sustainability and Environment Client Project Manager Simone Wilkinson Water Technology Project Manager Ben Tate Report Authors Ben Tate Job Number 2106-01 Report Number R02 Document Name 2106R02_FINAL_2010-11_VIC_Floods.docx Cover Photo: Flooding near Kerang in January 2011 (source: www.weeklytimesnow.com.au). Copyright Water Technology Pty Ltd has produced this document in accordance with instructions from Department of Sustainability and Environment for their use only. The concepts and information contained in this document are the copyright of Water Technology Pty Ltd. Use or copying of this document in whole or in part without written permission of Water Technology Pty Ltd constitutes an infringement of copyright. Water Technology Pty Ltd does not warrant this document is definitive nor free from error and does not accept liability for any loss caused, or arising from, reliance upon the information provided herein. 15 Business Park Drive Notting Hill VIC 3168 Telephone (03) 9558 9366 Fax (03) 9558 9365 ACN No. 093 377 283 ABN No. 60 093 377 283 2106-01 / R02 FINAL - 07/12/2012 ii Department of Sustainability and Environment 2010-11 Victorian Floods – Rainfall and Streamflow Assessment GLOSSARY Annual Exceedance Refers to the probability or risk of a flood of a given size occurring or being exceeded in any given year. -
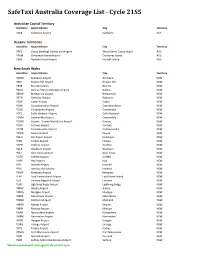
Safetaxi Australia Coverage List - Cycle 21S5
SafeTaxi Australia Coverage List - Cycle 21S5 Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER Merimbula -
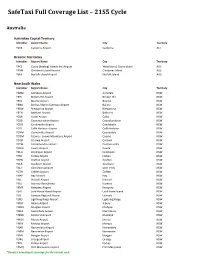
Safetaxi Full Coverage List – 21S5 Cycle
SafeTaxi Full Coverage List – 21S5 Cycle Australia Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER -

Vr6an Qrowtli Strategy
I I I I Vr6an qrowtli I I Strategy I I 1996 I I I I I I I I I I I CITY PLANNIII6 I ·~ I INTRODUCTION · "~~j~j~~~~~Njjjf I M0044244 The City of Greater Geelong Urban Growth Strategy was I prepared for Council by planning consultants Perrott Lyon . I Mathieson Pty Ltd during 1995 and 1996 to provide advice on the areas considered most suitable for urban I development to accommodate Geelong's expected growth up until the year 2020. On the most optimistic population I projections available, the consultants have catered for an I additional 71,000 persons or some 26,000 households. I In undertaking their work, the consultants have had the benefit of many background reports and information I . produceq over past years by the (former) Geelong ' . Regional Commission, together with more recent planning I studies undertaken either by or on behalf of Council (e.g. I North Eastern Area Strategic Land· Use Plan, Mt Duneed Armstrong Creek Urban Development rstudy; Residential I Lot Supply Report and Inventory of Industrial Lots). I The Urban Growth Strategy was· ·exhibited: for a 4 month period during 1996 at which time wide publicity was given I of its availability including an invitation for interested or I affected persons to make a submission. Preparation of this Strategy and its exhibition was also coordinated with I Council's Arterial Roads Study. I The exhibition comprised 8 background Discussion Papers and an overall Strategy report which were made publicly I . available at Council's Service Centres and throughout local /,.--- -- libraries. -

Global Evaluation of Biofuel Potential from Microalgae
Utah State University DigitalCommons@USU All Graduate Theses and Dissertations Graduate Studies 5-2014 Global Evaluation of Biofuel Potential from Microalgae Jeffrey W. Moody Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/etd Part of the Mechanical Engineering Commons Recommended Citation Moody, Jeffrey W., "Global Evaluation of Biofuel Potential from Microalgae" (2014). All Graduate Theses and Dissertations. 2070. https://digitalcommons.usu.edu/etd/2070 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Theses and Dissertations by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. GLOBAL EVALUATION OF BIOFUEL POTENTIAL FROM MICROALGAE by Jeffrey W. Moody A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in Mechanical Engineering Approved: Dr. Jason Quinn Dr. Byard Wood Major Professor Committee Member Dr. Rees Fullmer Dr. Mark McLellan Committee Member Vice President for Research and Dean of the School of Graduate Studies UTAH STATE UNIVERSITY Logan, Utah 2014 ii Copyright © Jeffrey Moody 2014 All Rights Reserved iii ABSTRACT Global Evaluation of Biofuel Potential from Microalgae by Jeffrey W. Moody, Master of Science Utah State University, 2014 Major Professor: Dr. Jason C. Quinn Department: Mechanical and Aerospace Engineering Traditional terrestrial crops are currently being utilized as a feedstock for biofuels but resource requirements and low yields limit the sustainability and scalability. Comparatively, next generation feedstocks, such as microalgae, have inherent advantages such as higher solar energy efficiencies, larger lipid fractions, utilization of waste carbon dioxide, and cultivation on poor quality land. -

Working Paper 3
Working paper 3 The Immediate Future- Towards the Year 2000 Strategic Planning Division, MPE Ministry for Planning and Environment January 1990 711.3 09945 URB WP3 coPY ~ -. Working paper 3 . The Immediate Future- Towards the Year 2000 . Strategic Plam1i~g Division, MPE · Ministry fo·r Planning and Environment January 1990. ·Contents Foreword (i) Summary (iii) Growth Projections and Infrastructure in Victoria 1 1. State Overview 1 2. Metropolitan Melbourne· 5 3. Major Provincial Centres 17 .. Gee long 17 Ballarat 22. Bendigo 26 Shepparton · 30 Wodonga 34 Latrobe Valley 38 References 43 Maps· 1· Key to Maps 2-13· 4 2-"-7 Metropolitan 11-16 8 Gee long 18 9 Ballarat 23 10 Bendigo 27 11 Shepparton 31 12 Wodonga 35 13 Latrobe Valley 39 Tables 1. Projected population growth 1988 - 2001 for 3 metropolitan Melb~mrne and provincial centres. 2. Comparison of projected population growth 6 1988 ~ 2001 for growth areas in metropolitan Melbourne. 3. Major services works likely to be required in metropolitan fringe ar~as.in the p~riod to 1998. / DISCLAIMER: The views presented in this working paper do not represent the official position of the Victorian Government or agencies involved in the strategic studies. (i) Foreword In August 1988 the. Victorian government· released Victori.a - Trading on Achievement. This document ·is · a synthesis of numerous state agencies' research and policy development, which sets out the basis for preparing . a long-term urbanjregional planning framework· for the. State's future growth. It. also identifies Victoria's significant strengths that can· be. capitalised upon to ensure the continued growth . -

Supplementary Material Table S1. List and Coordinates of Bureau Of
Supplementary Material Table S1. List and coordinates of Bureau of Meteorology weather stations used to determine ambient temperature. Coordinates Weather station name (Latitude, longitude oC) Ararat Prison 37.27, 142.98 Bairnsdale Airport 37.88, 147.57 Ballarat Aerodome 37.51, 143.79 Benalla Airport 36.55, 145.99 Bendigo Airport 36.74, 144.33 Breakwater (Geelong Racecourse) 38.17, 144.38 Bundoora 37.72, 145.04 Castlemaine Prison 37.08, 144.24 Coldstream 37.72, 145.41 Cranbourne Botanic Gardens 38.13, 145.26 East Sale 38.11, 147.13 Essendon Airport 37.73, 144.91 Frankston Aws 38.15, 145.12 Hamilton Airport 37.65, 142.06 Laverton RAAF 37.86, 144.76 Maryborough 37.06, 143.73 Melbourne Airport 37.67, 144.83 Mildura Airport 34.24, 142.09 Moorabbin Airport 37.98, 145.09 Mortlake racecourse 38.07, 142.77 Morwell 38.21, 146.47 Rutherglen Research 36.10, 146.51 Scoresby Research Institute 37.87, 145.26 Sheoaks 37.91, 144.13 Shepparton Airport 36.43, 145.39 Swan Hill Aerodome 35.38, 143.54 Tatura Inst Sustainable Ag 36.44, 145.27 Viewbank 37.74, 145.09 Warrnambool Airport 38.29, 142.43 Wonthaggi 38.61, 145.59 Yarrawonga 36.03, 146.03 Table S2. Ambient NO2 and PM2.5 in Greater Melbourne compared with the rest of Victoria for births occurring in Victoria between 1 March 2012 and 31 Dec 2015. Greater Melbourne Rest of Victoria Mean Median Q25, Q75 Mean Median Q25, Q75 Ambient NO2 concentration (ppb) 6.6 6.3 4.6, 8.2 3.6 3.2 2.5, 4.1 Ambient PM2.5 concentration (µg/m3) 7.0 7.1 6.5, 7.7 6.9 7.1 6.0, 7.9 Table S3.