Bachelor Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HARD REPORT' November 21, 1986 Issue # 6 (609) 654-7272 FRONTRUNNERS ERIC CLAPTON BOB GELDOF "AUGUST" "DEEP in the HEART E.C
THE HARD REPORT' November 21, 1986 Issue # 6 (609) 654-7272 FRONTRUNNERS ERIC CLAPTON BOB GELDOF "AUGUST" "DEEP IN THE HEART E.C. DELIVERS BIG ON OF NOWHERE" HIS MOST HIGHLY ANTICIPATED ALBUM OF IN TERMS OF WRITING AND ROCKING, WE'D THE EIGHTIES! CALL THIS A WORLD CLASS SURPRISE! ATLANTIC THE KINKS KATE BUSH NINNS . "THINK VISUAL" "EXPERIMENT IV" THINK THE 12" IS A BIT THE HIGH PRIESTESS ROUGH? YOU'LL FLIP OF MIND MUSIC RATES OVER "FACTORY" AND AN "A" FOR THIS "LOST AND FOUND" CEREBRAL CONCOCTION! MCA EMI JN OE HWN PE UD SD Fs RD OA My PLUS! ETTRACKS EDDIE MONEY & TIMBUK3 CHARTSTARS * HEADLINES MOST ADDED HOWARD and the FCC 1 The Kinks "Rock & Roll Cities" (MCA) 61 2 Ann Wilson "Best Man in The World" (CAP) 53 3 Bruce Hornsby "Western Skyline..." (RCA) 40 4 Peter Gabriel "Big Time" (GEFFEN) 35 McNUTT To McWKDF HOT NUMBERS ALBUMS Billy Joel "The Bridge" 46-39 (COL) YATES Back in L.A. World Party "Private. 44-38 (CHRY.) Jason/Scorchers"Still..." 37-33 (EMI) Ben Orr "The Lace" 18-14 (E/A) DEBUTS WNEW's McEWEN Stevie Ray Vaughan "Live Alive" #23(EPIC) tubes out Robert Cray "Strong Persuader" #26 (POLY) TRACKS KBC Band "America" 92-71 JOBNAPPERS Van Halen "Rock & Roll Live" 83-63 Europe "The Final Countdown" 89-78 TEXTBOOK: Smithereens "Behind the Wall..." 57-47 GREG GILLISPIE RECORD OF THE WEEK THE STEVE MILLER BAND --FOR HIS FIRST # 1 SINCE 82's "ABRACADABRA"! INSIDE... %tea' &Mai& &Mal& EtiZiraZ CiairlZif:.-.ZaW. CfMCOLZ &L -Z Cad CcIZ Cad' Ca& &Yet Cif& Ca& Ca& Cge. -
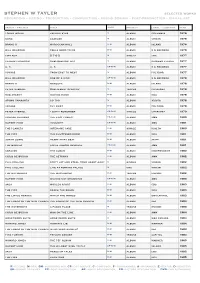
Stephen W Tayler Selected Works Recording - Mixing - Production - Composition - Sound Design - Post-Production - Visual Art
stephen w tayler selected works recording - mixing - production - composition - sound design - post-production - visual art artist - project title work project label - company year tommy bolin private eyes m album columbia 1976 gong gazeuse m album virgin 1976 brand x moroccan roll r-m album island 1976 bill bruford feels good to me r-m album e g records 1976 city boy 5 7 0 5 m single cbs 1977 claude francois quelquefois etc m album disques fleche 1977 u. k. u. k. cp-r-m album e g records 1977 voyage from east to west m album polydor 1977 bill bruford one of a kind cp-r-m album e g records 1978 brand x masques r-m album island 1978 peter gabriel 2nd album ‘scratch’ m tracks charisma 1978 rod argent moving home r-m album mca 1978 stomu yamashta go too m album arista 1978 voyage fly away r-m album polydor 1978 peter gabriel i don’t remember cp-r-m single charisma 1979 edward reekers the last forest cp-r-m album a&m 1980 rupert hine immunity cp-r-m album a&m 1981 the planets intensive care r-m single rialto 1980 the fixx the shuttered room r-m album mca 1981 jonah lewie heart skips beat r-m album stiff 1981 the models local and/or general cp-r-m album a&m 1981 caravan the album r-m album independent 1982 chris de burgh the getaway r-m album a&m 1982 phil collins don’t let her steal your heart away m single virgin 1982 phil collins live at perkins palace m vhs virgin 1982 the waterboys the waterboys r-m tracks ensign 1982 rupert hine waving not drowning cp-r-m album a&m 1983 saga worlds apart r-m album cbs 1983 the fixx reach the beach r-m album mca 1983 the little heroes watch the world r-m album emi/capitol 1983 the lords of the new church the lords of the new church r-m album irs 1983 the waterboys a pagan place m tracks ensign 1983 chris de burgh man on the line r-m album a&m 1984 honeymoon suite honeymoon suite m album wea canada 1984 howard jones human’s lib. -

To Loads of People Who Happy with This’
Bangor University Students’ Union May 2013 English Language Issue No. 232 Newspaper FREE @SerenBangor Seren.Bangor.ac.uk IRON MAN SPECIAL WHAT TO DO NEXT... INTERVIEW: LJ TAYLOR Student Summer Sessions Students’ Union organise summer activity sessions Various activities available including sports, days out and geo-caching by LJ TAYLOR tivities Development Co-ordinator at to take part in activities that may not team, making sure that everyone’s looking forward to launching this the Students’ Union. be readily accessible to them” said Mr equipment was up to scratch and that project and making the most of the new Bangor Students’ Union e project is the brainchild of the Barnard. there were no language barriers in resources that we now have available.” scheme hopes to keep Ban- Union’s activities team: AU President Strong links have been formed with the way. Quali ed coaches taught the Other planned activities include gor students active during the Emyr Bath, VP Societies and Com- the International O ce in preparation group the basics of kayaking before Geo-Caching and trips to Pu n Asummer months. munity Ash Kierans and Clubs and for the scheme which hopes to attract they toured the sheltered parts of the Island as well as a range of more Summer Sessions, which will launch Activities Development Co-ordinator International students who may be lake. traditional sports. at the end of term, will consist of a Steve Barnard. e team have worked staying in Bangor over summer and “Facilitating this activity had a fan- number of di erent activities which solidly throughout the year on in- may have less options during the qui- tastic reception, students from many will be available to any remaining stu- creasing participation and access to all eter part of the year. -

Jean-Louis Schuller / Cinematographer
JEAN-LOUIS SCHULLER / CINEMATOGRAPHER DIRECTOR OF PHOTOGRAPHY 2008 Bonobo / Dir. Jacques Molitor (35mm, Frakas Productions) X on Map / Dir. Jeff Desom (35mm Anamorphic, LUCIL Film Productions) FEATURE FILM DRAMA Elephants / Dir. Sally Pearce (D-21 HD Arri, NFTS Production) 2019 Hytte / Dir. Jean-Louis Schuller, Prod. aBahn, Les films Fauves Madrugada / Dir. Michael Pearce (S16mm, NFTS Production) 2013 Mammejong / Dir. Jacques Molitor (35mm, Lucil Films) 2009 House of Boys / Dir. Jean-Claude Schlimm (35mm, DELUX Productions) (Moroccan crew) 2007 Look what you have done to my heart / Dir. Michael Pearce (HD Video, NFTS Production) 2008 KIN / Dir. Brian Welsh (High Definition Video, A10 Film Productions) Launderette / Dir. Matti Harju (S16mm, NFTS Production) Ana / Dir. Theresa Von Eltz (S16mm, NFTS Production) ARTISTS’ FILM Flats / Dir. Ian Clark(S16mm, NFTS Productions) 2013 Playtime / Dir. Isaac Julien (HD, Isaac Julien Studio) 2006 Gemini / Dir. Jacques Molitor (DVcam/Pro35, IAD Production) The Remembered Film / Dir. Vicki Thornton (S16mm, Grand Duke Films) La chaire est tendre / Dir. Olivier Grinnaert (S16mm, IAD Production) 2012 Murder in Three Acts / Dir. Asli Çavusoglu (Video, Frieze Film) L’ouest est en aval / (S16mm, IAD Prod.) (camera operator) Entanglement II / Dir Ergin Çavusoglu (Video, Puma Films 4 Peace) 2011 Comma39 / Dir. Stuart Croft (S16mm, Royal College of Art) SHORT FILM DOCUMENTARY 2010 Find me loose me find me / Dir. Stuart Croft (HD, Royal College of Art) 2010 Jonsí “go live” tour (teaser) / Dir. Aneil Karia (HD, 59 Productions) 2009 The Stag Without a Heart / Dir. Stuart Croft (35mm, Royal College of Art) 2008 Yonder Stomp / Dir. Sean Clark (HDV, Goldsmith Productions) The Space Inbetween / Dir. -

Order Form Full
PUNK ARTIST TITLE LABEL RETAIL 100 DEMONS 100 DEMONS DEATHWISH INC RM90.00 4-SKINS A FISTFUL OF 4-SKINS RADIATION RM125.00 4-SKINS LOW LIFE RADIATION RM114.00 400 BLOWS SICKNESS & HEALTH ORIGINAL RECORD RM117.00 45 GRAVE SLEEP IN SAFETY (GREEN VINYL) REAL GONE RM142.00 999 DEATH IN SOHO PH RECORDS RM125.00 999 THE BIGGEST PRIZE IN SPORT (200 GR) DRASTIC PLASTIC RM121.00 999 THE BIGGEST PRIZE IN SPORT (GREEN) DRASTIC PLASTIC RM121.00 999 YOU US IT! COMBAT ROCK RM120.00 A WILHELM SCREAM PARTYCRASHER NO IDEA RM96.00 A.F.I. ANSWER THAT AND STAY FASHIONABLE NITRO RM119.00 A.F.I. BLACK SAILS IN THE SUNSET NITRO RM119.00 A.F.I. SHUT YOUR MOUTH AND OPEN YOUR EYES NITRO RM119.00 A.F.I. VERY PROUD OF YA NITRO RM119.00 ABEST ASYLUM (WHITE VINYL) THIS CHARMING MAN RM98.00 ACCUSED, THE ARCHIVE TAPES UNREST RECORDS RM108.00 ACCUSED, THE BAKED TAPES UNREST RECORDS RM98.00 ACCUSED, THE NASTY CUTS (1991-1993) UNREST RM98.00 ACCUSED, THE OH MARTHA! UNREST RECORDS RM93.00 ACCUSED, THE RETURN OF MARTHA SPLATTERHEAD (EARA UNREST RECORDS RM98.00 ACCUSED, THE RETURN OF MARTHA SPLATTERHEAD (SUBC UNREST RECORDS RM98.00 ACHTUNGS, THE WELCOME TO HELL GOING UNDEGROUND RM96.00 ACID BABY JESUS ACID BABY JESUS SLOVENLY RM94.00 ACIDEZ BEER DRINKERS SURVIVORS UNREST RM98.00 ACIDEZ DON'T ASK FOR PERMISSION UNREST RM98.00 ADICTS, THE AND IT WAS SO! (WHITE VINYL) NUCLEAR BLAST RM127.00 ADICTS, THE TWENTY SEVEN DAILY RECORDS RM120.00 ADOLESCENTS ADOLESCENTS FRONTIER RM97.00 ADOLESCENTS BRATS IN BATTALIONS NICKEL & DIME RM96.00 ADOLESCENTS LA VENDETTA FRONTIER RM95.00 ADOLESCENTS -

Pop Goes the Opera!! Reviews 2 the STUDENT Thursday, 8Th March 1984 News
8.3.84 20p ..___ Edinburgh University Student Newspape..---- .. Inside Art College revolt more drugs ... and pop goes the opera!! reviews 2 THE STUDENT Thursday, 8th March 1984 News . .. News ... News . .. News . .. News ... New Anti- Apartheid demonstration NEWS ,N BRIEF This Monday lunchtime comment on this action as being from the national newspapers and his home country. "provocative on behalf of the local radio stations. The EU A-AS The Conservatives' President saw a group of members Tories" have awarded themselves a major Andrew: " I wasn't here last week I Better Baths and supporters of There was great confusion as to victory for this as they have gained was in Chesterfield" Ryland, PORTOBELLO BATHS are to Edinburgh University's whether or not this mysterious a lot o f unexpected (and free) emerged briefly to defend the get a £155,000 facelift. A gym/ publicity. Through this they hope Anti-Apartheid Society Consul was going to attend his choice of speaker. Not one of the training room Is being built within luncheon appointment, with the they have achieved at least one of FCS favours apartheid, he said, the 86-year-old building, and· holding a demonstration differing factions having varied their aims for this week. they had wanted to hear Mr other Improvements will ensure outside Teviot Row stories. The Conservative group The first being to c reate an Volshenk speak and ~sk him a few better energy conservation. This Is awareness in th e public of the evils Union. They were maintained throughout that the questions. good news for the 100-odd engagement had been cancelled a of apartheid; secondly, they want Another student, Zimbabwean pensioners who, among others, sounding-off about an fortnight ago, as the event had to c lear up any misconceptions David Geddes, backed him up. -

KEY SONGS and We’Ll Tell Everyone Else
Cover-15.03.13_cover template 12/03/13 09:49 Page 1 11 9 776669 776136 THE BUSINESS OF MUSIC www.musicweek.com 15.03.13 £5.15 40 million albums sold worldwide 8 million albums sold in the UK Project1_Layout 1 12/03/2013 10:07 Page 1 Multiple Grammy Award winner to release sixth studio album ahead of his ten sold out dates in June at the O2 Arena ‘To Be Loved’ 15/04/2013 ‘It’s A Beautiful Day’ 08/04/2013 Radio Added to Heart, Radio 2, Magic, Smooth, Real, BBC Locals Highest New Entry and Highest Mover in Airplay Number 6 in Airplay Chart TV March BBC Breakfast Video Exclusive 25/03 ‘It’s A Beautiful Day’ Video In Rotation 30/03 Ant & Dec Saturday Night Takeaway 12/04 Graham Norton Interview And Performance June 1 Hour ITV Special Expected TV Audience of 16 million, with further TVs to be announced Press Covers and features across the national press Online Over 5.5 million likes on Facebook Over 1 million followers on Twitter Over 250 million views on YouTube Live 10 Consecutive Dates At London’s O2 Arena 30th June • 1st July • 3rd July • 4th July 5thSOLD July OUT • 7thSOLD July OUT • 8thSOLD July OUT • 10thSOLD July OUT 12thSOLD July OUT • 13thSOLD July OUT SOLD OUT SOLD OUT SOLD OUT SOLD OUT Marketing Nationwide Poster Campaign Nationwide TV Advertising Campaign www.michaelbuble.com 01 MARCH15 Cover_v5_cover template 12/03/13 13:51 Page 1 11 9 776669 776136 THE BUSINESS OF MUSIC www.musicweek.com 15.03.13 £5.15 ANALYSIS PROFILE FEATURE 12 15 18 The story of physical and digital Music Week talks to the team How the US genre is entertainment retail in 2012, behind much-loved Sheffield crossing borders ahead of with new figures from ERA venue The Leadmill London’s C2C festival Pet Shop Boys leave Parlophone NEW ALBUM COMING IN JUNE G WORLDWIDE DEAL SIGNED WITH KOBALT LABEL SERVICES TALENT can say they have worked with I BY TIM INGHAM any artist for 28 years, but Parlophone have and we are very et Shop Boys have left proud of that. -

Warner and Sony Set for Battle
01 15FEB Cover_v3_cover template 12/02/13 17:38 Page 1 07 9 776669 776136 THE BUSINESS OF MUSIC www.musicweek.com 15.02.13 £5.15 NEWS BIG INTERVIEW ANALYSIS 05 12 27 The legendary Sir George UK bosses Jason Iley and Mike Music Week talks to pop Martin accepts his MPG Smith discuss a promising year songwriting golden boy Outstanding Contribution Award ahead for the Universal label Wayne Hector Warner and Sony set for battle PARLOPHONE BUYOUT WILL DRAMATICALLY CLOSE THE GAP BETWEEN RIVAL MAJOR LABELS ANALYSIS market headed by Universal with I BY PAUL WILLIAMS a 35.0% share and Sony second with 20.8%. arner’s £487m buyout However, had Warner W of Parlophone Label controlled the artists and Group (PLG) will put repertoire coming from PLG in it within touching distance of 2011 and 2012 it would have Sony as Universal’s biggest rival claimed around 17.5% of the in the UK. albums market, just one and a That’s according to exclusive half percentage points behind Music Week research, which Sony, while it would have been suggests the addition of around the same distance behind repertoire from the likes of Sony on singles with a market Coldplay, David Guetta and Pink share of about 19.5%. Floyd will sharply narrow the On the albums side, the most market share race for second obvious powerful addition to its place. However, Universal could ranks will be Coldplay whose end up being 80% or more ahead Mylo Xyloto was EMI’s second of both rival players. -

SKIVLISTA 4-2019 Hello Music Lovers, the Following Items Will Be Sold on Open Auction Which Means You Can Ask About Leading Bids by Phone Or Mail
AUCTION – AUKTION SKIVLISTA 4-2019 Hello music lovers, The following items will be sold on open auction which means you can ask about leading bids by phone or mail. Please send your starting bids by mail, phone or post before the last day of auction. Vi kör en auktion till i alla fall. Men klart är att jag kunde dra ned en hel del på upplagan av de tryckta listorna då ni Auction deadline is Monday, September 30, 2019 at 22.00 / 10 PM Central börjar bli sorgligt få som hör av er. Någon enstaka person har hört av sig och meddelat att inga skivlistor längre European time (20.00 / 8 PM UTC/GMT) önskas men i de flesta fall är det bara helt plötsligt tyst. STOPPDATUM ALLTSÅ MÅNDAGEN DEN 30 SEPTEMBER 2019 KL. 22.00 SVENSK SOMMARTID. Många av er har fått mina skivlistor väldigt länge, sedan långt innan datorernas tid. Då tog det betydligt längre tid eftersom varje lista måste knackas fram på skrivmaskin. Jag tycker själv att det är betydligt trevligare att få en tryckt 7" SINGLES/EPs FOR AUCTION skivlista i brevlådan i stället för att handla på nätet. Det blir också en naturlig kontakt i samband med telefonsamtalen där ofta allt möjligt dryftas utöver skivbeställningar och att kolla bud. På sitt sätt är det ju en social Minimum bid (M.B.) is SEK 50 / US$ 8 / € 6,- / £ 5 unless otherwise noted . samvaro som det aldrig kan bli genom att handla på nätet. Min.bud 50 kr om ej annat anges. Det kan inte hjälpas att jag ibland blir orolig över vad som kan ha hänt när gamla kunder inte längre hör av sig. -

Rock Album Discography Last Up-Date: September 27Th, 2021
Rock Album Discography Last up-date: September 27th, 2021 Rock Album Discography “Music was my first love, and it will be my last” was the first line of the virteous song “Music” on the album “Rebel”, which was produced by Alan Parson, sung by John Miles, and released I n 1976. From my point of view, there is no other citation, which more properly expresses the emotional impact of music to human beings. People come and go, but music remains forever, since acoustic waves are not bound to matter like monuments, paintings, or sculptures. In contrast, music as sound in general is transmitted by matter vibrations and can be reproduced independent of space and time. In this way, music is able to connect humans from the earliest high cultures to people of our present societies all over the world. Music is indeed a universal language and likely not restricted to our planetary society. The importance of music to the human society is also underlined by the Voyager mission: Both Voyager spacecrafts, which were launched at August 20th and September 05th, 1977, are bound for the stars, now, after their visits to the outer planets of our solar system (mission status: https://voyager.jpl.nasa.gov/mission/status/). They carry a gold- plated copper phonograph record, which comprises 90 minutes of music selected from all cultures next to sounds, spoken messages, and images from our planet Earth. There is rather little hope that any extraterrestrial form of life will ever come along the Voyager spacecrafts. But if this is yet going to happen they are likely able to understand the sound of music from these records at least. -

Polygram 1983-1992
AUSTRALIAN RECORD LABELS PolyGram 7”, 12” singles & LP’s 1983 to 1992 COMPILED BY MICHAEL DE LOOPER © BIG THREE PUBLICATIONS, MAY 2019 POLYGRAM 7”, 12” SINGLES & LP’S, 1983–1992 POLYGRAM PRODUCT GUIDE –1 = 12” SINGLES, LP’S –2 = CD SINGLES, CD’S (NOT LISTED) –3 = VHS VIDEO (NOT LISTED) –4 = CASSETTE SINGLES, CASSETTES (NOT LISTED) –7 = 7” SINGLES 370, 377—WINDHAM HILL 370 111-1 TEARS OF JOY TUCK & PATTI 1.90 377 008-1 LOVE WARRIORS TUCK & PATTI 1.90 390–397—A & M 390 419-7 LOVE SCARED / LOVE SCARED PART II (LET’S TALK IT OVER) LANCE ELLINGTON 3.91 390 460-7 STONE COLD SOBER / THE RETURN OF MAGGIE BROWN DEL AMITRI 7.90 390 462-7 THE MESSAGE IS LOVE (2 VERSIONS) ARTHUR BAKER 3.90 390 462-1 THE MESSAGE IS LOVE (2 VERSIONS) / THE MESSAGE IS CLUB ARTHUR BAKER 3.90 390 466-7 DIAMOND IN THE DARK / LAST NIGHT CHRIS DE BURGH 6.90 390 471-7 LOVE TOGETHER (2 VERSIONS) L.A. MIX 7.90 390 471-1 LOVE TOGETHER (2 VERSIONS) L.A. MIX 7.90 390 472-7 PERFECT VIEW / WE NEVER MET THE GRACES 3.90 390 474-7 NOTHING EVER HAPPENS / NO HOLDING ON DEL AMITRI 4.90 390 474-1 NOTHING EVER HAPPENS / NO HOLDING ON / SLOWLY, IT’S COMING BACK DEL AMITRI 5.90 390 475-7 I’M A BELIEVER / NO WAY OUT GIANT 6.90 390 476-7 INSIDE OUT / BACK TO WHERE WE STARTED GUN 4.90 390 477-7 WITH A LITTLE LOVE / WINDOW PEOPLE SAM BROWN 4.90 390 477-1 WITH A LITTLE LOVE / WINDOW PEOPLE / DOLLY MIXTURE SAM BROWN 4.90 390 480-7 A CHANGE IS GONNA COME / MY BLOOD THE NEVILLE BROTHERS 3.90 390 484-1 SUPER LOVER (2 VERSIONS) / WHEN WILL I SEE YOU AGAIN BARRY WHITE 6.90 390 486-7 TWO TO MAKE IT RIGHT -

Tom Cochrane – Take It Home Colin James – Hearts on Fire NE-YO – Non-Fiction
Tom Cochrane – Take It Home Colin James – Hearts on Fire NE-YO – Non-Fiction New Releases From Classics And Jazz Inside!!! And more… UNI15-05 UNIVERSAL MUSIC 2450 Victoria Park Ave., Suite 1, Willowdale, Ontario M2J 5H3 Phone: (416) 718.4000 *Artwork shown may not be final Tuesday, December 16, 2014 Dear Commercial Partner, Please be advised that, effective February 9th, 2015 Universal Music Canada will convert titles posted to http://www.umcreleasebooks.ca to JSP ($10.98 NEDP) pricing. All orders placed prior to February 9th, 2015 will attract the old price and all orders placed post February 9th, 2015 will attract the new JSP pricing. **Please note normal terms will not apply to this new price tier.** Please contact your local Universal Music Canada representative, should you have any questions. Cher Partenaire Commercial, Nous vous avisons qu’à compter du 9 février 2015, Universal Music Canada convertira les titres indiqués sur http://www.umcreleasebooks.ca au code de prix JSP ($10.98 NEPD). Toutes commandes envoyées avant le 9 février 2015 auront le vieux prix de vente alors que les commandes envoyées après le 9 février 2015 auront le nouveau prix de vente JSP. ** Veuillez prendre note que nos Termes Normaux ne s’appliqueront pas à ce nouveau code de prix. ** N’hésitez pas à contacter votre représentant de Universal Music Canada local si vous avez des questions. Regards/Sincèrement, Adam Abbasakoor Vice President, Commercial Affairs Universal Music Canada [email protected] UNIVERSAL MUSIC CANADA NEW RELEASE Artist/Title: DIANA KRALL / WALLFLOWER (Standard CD) Cat. #: B002098902 Price Code: SP Order Due: Jan.