19850008216.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Annual Reports of FCCSET Subcommittee Annual Trip Reports To
Annual Reports of FCCSET Subcommittee Annual trip reports to supercomputer manufacturers trace the changes in technology and in the industry, 1985-1989. FY 1986 Annual Report of the Federal Coordinating Council on Science, Engineering and Technology (FCCSET). by the FCCSET Ocnmittee. n High Performance Computing Summary During the past year, the Committee met on a regular basis to review government and industry supported programs in research, development, and application of new supercomputer technology. The Committee maintains an overview of commercial developments in the U.S. and abroad. It regularly receives briefings from Government agency sponsored R&D efforts and makes such information available, where feasible, to industry and universities. In addition, the committee coordinates agency supercomputer access programs and promotes cooperation with particular emphasis on aiding the establish- ment of new centers and new communications networks. The Committee made its annual visit to supercomputer manufacturers in August and found that substantial progress had been made by Cray Research and ETA Systems toward developing their next generations of machines. The Cray II and expanded Cray XMP series supercomputers are now being marketed commercially; the Committee was briefed on plans for the next generation of Cray machines. ETA Systems is beyond the prototype stage for the ETA-10 and planning to ship one machine this year. A ^-0 A 1^'Tr 2 The supercomputer vendors continue to have difficulty in obtaining high performance IC's from U.S. chip makers, leaving them dependent on Japanese suppliers. In some cases, the Japanese chip suppliers are the same companies, e.g., Fujitsu, that provide the strongest foreign competition in the supercomputer market. -

Emerging Technologies Multi/Parallel Processing
Emerging Technologies Multi/Parallel Processing Mary C. Kulas New Computing Structures Strategic Relations Group December 1987 For Internal Use Only Copyright @ 1987 by Digital Equipment Corporation. Printed in U.S.A. The information contained herein is confidential and proprietary. It is the property of Digital Equipment Corporation and shall not be reproduced or' copied in whole or in part without written permission. This is an unpublished work protected under the Federal copyright laws. The following are trademarks of Digital Equipment Corporation, Maynard, MA 01754. DECpage LN03 This report was produced by Educational Services with DECpage and the LN03 laser printer. Contents Acknowledgments. 1 Abstract. .. 3 Executive Summary. .. 5 I. Analysis . .. 7 A. The Players . .. 9 1. Number and Status . .. 9 2. Funding. .. 10 3. Strategic Alliances. .. 11 4. Sales. .. 13 a. Revenue/Units Installed . .. 13 h. European Sales. .. 14 B. The Product. .. 15 1. CPUs. .. 15 2. Chip . .. 15 3. Bus. .. 15 4. Vector Processing . .. 16 5. Operating System . .. 16 6. Languages. .. 17 7. Third-Party Applications . .. 18 8. Pricing. .. 18 C. ~BM and Other Major Computer Companies. .. 19 D. Why Success? Why Failure? . .. 21 E. Future Directions. .. 25 II. Company/Product Profiles. .. 27 A. Multi/Parallel Processors . .. 29 1. Alliant . .. 31 2. Astronautics. .. 35 3. Concurrent . .. 37 4. Cydrome. .. 41 5. Eastman Kodak. .. 45 6. Elxsi . .. 47 Contents iii 7. Encore ............... 51 8. Flexible . ... 55 9. Floating Point Systems - M64line ................... 59 10. International Parallel ........................... 61 11. Loral .................................... 63 12. Masscomp ................................. 65 13. Meiko .................................... 67 14. Multiflow. ~ ................................ 69 15. Sequent................................... 71 B. Massively Parallel . 75 1. Ametek.................................... 77 2. Bolt Beranek & Newman Advanced Computers ........... -

(52) Cont~Ol Data
C) (52) CONT~OL DATA literature and Distribution Services ~~.) 308 North Dale Street I st. Paul. Minnesota 55103 rJ 1 August 29, 1983 "r--"-....." (I ~ __ ,I Dear Customer: Attached is the third (3) catalog supplement since the 1938 catalog was published . .. .·Af ~ ~>J if-?/t~--62--- G. F. Moore, Manager Literature & Distribution Services ,~-" l)""... ...... I _._---------_._----_._----_._-------- - _......... __ ._.- - LOS CATALOG SUPPLEPtENT -- AUGUST 1988 Pub No. Rev [Page] TITLE' [ extracted from catalog entry] Bind Price + = New Publication r = Revision - = Obsolete r 15190060 [4-07] FULL SCREEN EDITOR (FSEDIT) RM (NOS 1 & 2) .......•...•.•...•••........... 12.00 r 15190118 K [4-07] NETWORK JOB ENTRY FACILITY (NJEF) IH8 (NOS 2) ........................... 5.00 r 15190129 F [4-07] NETWORK JOB ENTRY FACILITY (NJEF) RM (NOS 2) .........•.......•........... + 15190150 C [4-07] NETWORK TRANSFER FACILITY (NTF) USAGE (NOS/VE) .......................... 15.00 r 15190762 [4-07] TIELINE/NP V2 IHB (L642) (NOS 2) ........................................ 12.00 r 20489200 o [4-29] WREN II HALF-HEIGHT 5-114" DISK DRIVE ................................... + 20493400 [4-20] CDCNET DEVICE INTERFACE UNITS ........................................... + 20493600 [4-20] CDCNET ETHERNET EQUIPMENT ............................................... r 20523200 B [4-14] COMPUTER MAINTENANCE SERVICES - DEC ..................................... r 20535300 A [4-29] WREN II 5-1/4" RLL CERTIFIED ............................................ r 20537300 A [4-18] SOFTWARE -

Lehman Brothers Holdings
SECURITIES AND EXCHANGE COMMISSION FORM 13F-HR/A Initial quarterly Form 13F holdings report filed by institutional managers [amend] Filing Date: 2004-12-01 | Period of Report: 2004-09-30 SEC Accession No. 0000806085-04-000212 (HTML Version on secdatabase.com) FILER LEHMAN BROTHERS HOLDINGS INC Mailing Address Business Address LEHMAN BROTHERS LEHMAN BROTHERS CIK:806085| IRS No.: 133216325 | State of Incorp.:DE | Fiscal Year End: 1130 745 SEVENTH AVENUE 745 SEVENTH AVENUE Type: 13F-HR/A | Act: 34 | File No.: 028-03182 | Film No.: 041177215 NEW YORK NY 10019 NEW YORK NY 10019 SIC: 6211 Security brokers, dealers & flotation companies 2125267000 Copyright © 2012 www.secdatabase.com. All Rights Reserved. Please Consider the Environment Before Printing This Document NON-CONFIDENTIAL <TABLE> <CAPTION> TITLE OF VALUE SHRS OR SH/ PUT/ INVESTMENT OTHER VOTING AUTHORITY NAME OF ISSUER CLASS CUSIP (X$1000) PRN AMT PRN CALL DISCRETION MANAGERS SOLE SHARED NONE <S> <C> <C> <C> <C> <C> <C> -------------------------------- -------- --------- -------- ------- --- ---- ---------- -------- -------- -------- -------- ***DAIMLERCHRYSLER A.G. COMMON D1668R123 9514 227843 SH DEFINED 01 227843 0 0 ***SANOFI AVENTIS COMMON F5548N101 34013 491666 SH DEFINED 01 491666 0 0 PNM RESOURCES COMMON GKD49H100 0 50000 SH DEFINED 01 0 0 50000 PNM RESOURCES COMMON GKD49H100 0 200000 SH DEFINED 01 200000 0 0 ***ACE LTD-ORD COMMON G0070K103 9964 248616 SH DEFINED 01 0 0 248616 ***ASPEN INSURANCE HOLDINGS COMMON G05384105 3950 171680 SH DEFINED 01 171680 0 0 ***ASSURED GUARANTY -

FEI COMPANY 5350 NE Dawson Creek Drive Hillsboro, Oregon 97124-5793
FEI COMPANY 5350 NE Dawson Creek Drive Hillsboro, Oregon 97124-5793 NOTICE OF ANNUAL MEETING OF SHAREHOLDERS To Be Held On May 7, 2015 To the Shareholders of FEI Company: Notice is hereby given that the Annual Meeting of Shareholders of FEI Company, an Oregon corporation, will be held on Thursday, May 7, 2015, at 9:00 a.m. local time, at our corporate headquarters located at 5350 NE Dawson Creek Drive, Hillsboro, Oregon 97124-5793. The purposes of the annual meeting will be: 1. To elect members of FEI's Board of Directors to serve for the following year and until their successors are duly elected and qualified; 2. To consider and vote on a proposal to amend FEI's 1995 Stock Incentive Plan to increase the number of shares of our common stock reserved for issuance under the plan by 250,000 shares; 3. To consider and vote on a proposal to amend FEI's Employee Share Purchase Plan to increase the number of shares of our common stock reserved for issuance under the plan by 250,000 shares; 4. To approve, on an advisory basis, the appointment of KPMG LLP as FEI's independent registered public accounting firm for the year ending December 31, 2015; 5. To approve, on an advisory basis, FEI's executive compensation; and 6. To transact such other business as may properly come before the meeting or at any and all postponements or adjournments of the meeting. Only shareholders of record at the close of business on March 2, 2015 and their proxies will be entitled to vote at the annual meeting and any adjournment or postponement of the meeting. -

Frontiers of Supercomputing
by B. L. Buzbee, N. Metropolis, and D. H. Sharp scientists two years to do may be reduced to needed for rapid progress. two months of effort. When this happens. Before presenting highlights of the con- practice in many fields of science and tech- ference we will review in more depth the nology will be revolutionized. importance of supercomputing and the These radical changes would also have a trends in computer performance that form needs. Electronic computers were developed, large and rapid impact on the nation’s econ- the background for the conference dis- in fact, during and after World War 11 to omy and security. The skill and effectiveness cussions. meet the need for numerical simulation in the with which supercomputers can be used to design of nuclear weapons, aircraft, and design new and more economical civilian The Importance of Supercomputers conventional ordnance. Today. the avail- aircraft will determine whether there is em.. ability of supercomputers ten thousand times ployrnent in Seattle or in a foreign city. The term “supercomputer” refers to the faster than the first electronic devices is Computer-aided design of automobiles is most powerful scientific computer available having a profound impact on all branches of already playing an important role in De- at a given time. The power of a computer is science and engineering—from astrophysics troit’s effort to recapture its position in the measured by its speed, storage capacity to elementary particle physics. from fusion automobile market. The speed and accuracy (memory). and precision. Today’s com- energy research to automobile design. -

VHSIC and ETA10
VHSIC and The First CMOS and Only Cryogenically Cooled Super Computer David Bondurant Former Honeywell Solid State Electronics Division VHSIC System Applications Manager ETA10 Supercomputer at MET Office - UK’s National Weather Forecasting Service Sources • “Very High Speed Integrated Circuits (VHSIC) Final Program Report 1980-1990, VHSIC Program Office”, Office of the Under Secretary of Defense for Acquisition, Deputy Director, Defense Research and Engineering for Research and Advanced Technology, September 30, 1990 • Carlson, Sullivan, Bach, and Resnick, “The ETA10 Liquid-Nitrogen-Cooled Supercomputer System”, IEEE Transactions on Electron Devices, Vol. 36, No. 8, August 1989. • Cummings and Chase, “High Density Packaging for Supercomputers” • Tony Vacca, “First Hand: The First CMOS And The Only Cryogenically Cooled Supercomputer”, ethw.org • Robert Peglar, “The ETA Era or How to (Mis-)Manage a Company According to Control Data Corp.”, April 17, 1990 Background • I graduated from Missouri S&T in May 1971 • My first job was at Control Data Corporation, the leading Supercomputer Company • I worked in Memory Development • CDC 7600 was in production, 8600 (Cray 1) was in development by Seymour Cray in Chippewa Falls, WI • Star 100 Vector Processor was in Development in Arden Hills • I was assigned to the development of the first DRAM Memory Module for a CDC Supercomputer • I designed the DRAM Module Tester Using ECL Logic Control Data Corporation Arden Hills • First DRAM Module was 4Kx32 using 128 1K DRAM Development Center - June 1971 Chips -
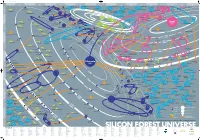
Silicon Forest Universe
15239 Poster 9/16/02 1:03 PM Page 1 AB CDE FGH I JKL M N O P Q R S Pearlsoft COMSAT General Integrated Systems Ashwood Group '85 Qualis Design fka CPU International Nel-Tech Development '98 Qsent '01 Briefsmart.com '00 Relyent TrueDisk Trivium Systems '80 '74 '99 '90 Gearbeat '81 Relational Systems Galois 3DLand Teradyne in 2001 '85 '00 '98 Solution Logic SwiftView Imagenation '89 Metro One IronSpire '84 Smart Mediary Systems Connections 13 Telecommunications WireX GenRad in 1996 '00 CyberOptics E-Core Salu Logiplex '79 MyHealthBank Semiconductor Cotelligent Technologies Fujitsu America Barco Metheus '77 '99 Group Knowledge fka United Data Biotronik Timlick & Associates in 1999 Gadget Labs Adaptive Solutions Wave International Processing Cascade Laser '98 Webridge Axis Clinical Software Mitron Basicon '91 GemStone fka Servio Logic Source Services '83 Integra Telecom Accredo FaxBack Polyserve Metheus Intersolv Babcock & Jenkins Electro '79 Informedics Scientific Sliceware Graphic Software Systems Industries IBM 12 in 1999 Atlas Telecom 1944 Sequent Computer ProSight Credence in 2001 19 ADC Kentrox '78 Oracle '69 Merant Datricon 60s Informix Systems FEI Sage Software fka Polytron MKTX 197 Mikros Nike 0s Etec Systems '63 19 Sentrol in 1995 Intel 80s SEH America Teseda Oregon Graduate Institute Flight Dynamics 1976 '97 1990 Purchasing Solutions Fluence ~ Relcom Vidco Mushroom Resources Cunningham & Cunningham '99 Myteam.com Praegitzer Industries Integrated Measurement Systems Zicon Digital World Lucy.Com Nonbox in 2001 ATEQ 11 Software Access -

Technology Transfer Joint Hearing
TECHNOLOGY TRANSFER JOINT HEARING BEFORE THE COMMITTEE ON SCIENCE AND TECHNOLOGY HOUSE OF REPRESENTATIVES AND THE SUBCOMMITTEE ON ENERGY RESEARCH AND DEVELOPMENT OF THE COMMITTEE ON ENERGY AND NATURAL RESOURCES U.S. SENATE NINETY-NINTH CONGRESS SECOND SESSION SEPTEMBER 4, 1986 [No. 161] Printed for the use of the Committee on Science and Technology, and the Committee on Energy and Natural Resources, U.S. Senate U.S. GOVERNMENT PRINTING OFFICE 67-150 0 WASHINGTON : 1987 For sale by the Superintendent of Documents, Congressional Sales Office US. Government Printing Office, Washington, DC 20402 rX K ' .., ;.- .,,... COMMITTEE ON SCIENCE AND TECHNOLOGY DON FUQUA, Florida, Chairman ROBERT A. ROE, New Jersey MANUEL LUJAN, JR., New Mexico* GEORGE E. BROWN, JH., California ROBERT S. WALKER, Pennsylvania JAMES H. SCHEUER, New York F. JAMES SENSENBRENNER, JR., MARILYN LLOYD, Tennessee Wisconsin TIMOTHY <E. WIRTH, Colorado CLAUDINE SCHNEIDER, Rhode Island DOUG WALGREN, Pennsylvania SHERWOOD L. BOEHLERT, New York DAN GLICKMAN, Kansas TOM LEWIS, Florida ROBERT A. YOUNG, Missouri DON RTTTER, Pennsylvania HAROLD L. VOLKMER, Missouri SID W. MORRISON, Washington BILL NELSON, Florida RON PACKARD, California STAN LUNDINE, New York JAN MEYERS, Kansas RALPH M. HALL, Texas ROBERT C. SMITH, New Hampshire DAVE McCURDY, Oklahoma PAUL B. HENRY, Michigan NORMAN Y. MINETA, California HARRIS W. FAWELL, Illinois BUDDY MACKAY, Florida" WILLIAM W. COBEY, JR., North Carolina TIM VALENTINE, North Carolina JOE BARTON, Texas HARRY M. REID, Nevada D. FRENCH SLAUGHTER, JR., Virginia ROBERT G. TORRICELLI, New Jersey DAVID S. MONSON, Utah RICK BOUCHER, Virginia TERRY BRUCE, Illinois RICHARD H. STALLINGS, Idaho BART GORDON, Tennessee JAMES A. TRAFICANT, JR., Ohio JIM CHAPMAN, Texas HAROLD P. -

Lehman Brothers Holdings
SECURITIES AND EXCHANGE COMMISSION FORM 13F-HR/A Initial quarterly Form 13F holdings report filed by institutional managers [amend] Filing Date: 2005-02-17 | Period of Report: 2004-12-31 SEC Accession No. 0000806085-05-000044 (HTML Version on secdatabase.com) FILER LEHMAN BROTHERS HOLDINGS INC Mailing Address Business Address LEHMAN BROTHERS LEHMAN BROTHERS CIK:806085| IRS No.: 133216325 | State of Incorp.:DE | Fiscal Year End: 1130 745 SEVENTH AVENUE 745 SEVENTH AVENUE Type: 13F-HR/A | Act: 34 | File No.: 028-03182 | Film No.: 05624078 NEW YORK NY 10019 NEW YORK NY 10019 SIC: 6211 Security brokers, dealers & flotation companies 2125267000 Copyright © 2012 www.secdatabase.com. All Rights Reserved. Please Consider the Environment Before Printing This Document <TABLE> <CAPTION> TITLE OF VALUE SHRS OR SH/ PUT/ INVESTMENT OTHER VOTING AUTHORITY NAME OF ISSUER CLASS CUSIP (X$1000) PRN AMT PRN CALL DISCRETION MANAGERS SOLE SHARED NONE <S> <C> <C> <C> <C> <C> <C> -------------------------------- -------- --------- -------- ------- --- ---- ---------- -------- -------- -------- -------- ***DAIMLERCHRYSLER A.G. COMMON D1668R123 226 4707 SH DEFINED 01 4707 0 0 ***DEUTSCHE BANK AG COMMON D18190898 397 4463 SH DEFINED 01 4463 0 0 ***ACE LTD-ORD COMMON G0070K103 6966 162834 SH DEFINED 01 0 0 162834 ***AMDOCS LIMITED COMMON G02602103 547 20661 SH DEFINED 01 0 0 20661 ***ARCH CAPITAL GROUP LTD COMMON G0450A105 230 5957 SH DEFINED 01 5957 0 0 ***ARLINGTON TANKERS LTD COMMON G04899103 1038 45250 SH DEFINED 01 45250 0 0 ***ASPEN INSURANCE HOLDINGS COMMON -

Portland Tribune
LOOK FOR INVITATIONS TO BID AND PUBLIC NOTICES STARTING ON PAGE 14 FEBRUARY 23, 2016 FEBRUARY EXPORT-IMPORT BANK CREATING Business U.S. JOBS Tribune BY JOHN M. VINCENT TEKTRONIX WEFUNDER TURNS 70 TAKES AMTRAK CENTRAL METRO EASTSIDE: INNOVATORS R2SHOP2 #3: THE SOCIETY INSIDE HOTEL 2 BUSINESS TRIBUNE Tuesday, February 23, 2016 5,000 LOCAL STORIES every month and GROWING! Beaverton Business Tribune Canby Clackamas Estacada Forest Grove Gresham—TuesdayGresham Tuesday Gresham—FridayGresham—Friday Hillsboro King City Lake Oswego Oswego Madras Ashton Eaton talks track, life GETTING IT DONE World decathlon champion has new goals in mind — SEE SPORTS, B10 Blazers forward Ed Davis fl ies under the radar — SEE SPORTS, B10 PortlandTribune PortlandTribune THURSDAY, DECEMBER 10, 2015 • TWICE CHOSEN THE NATION’S BEST NONDAILY PAPER • PORTLANDTRIBUNE.COM • PUBLISHED TUESDAY AND THURSDAY THURSDAY, DECEMBER 17, 2015 • TWICE CHOSEN THE NATION’S BEST NONDAILY PAPER • PORTLANDTRIBUNE.COM • PUBLISHED TUESDAY AND THURSDAY The Portland Development Commission’s East Portlanders push Trang Lam discusses Lents redevelopment prospects outside Working back on gentrifi cation Class Acupuncture. landlord decided to sell the build- children. They wound up living in a Lents, starting As residents face more ing, so she’s living in an RV in her cramped hotel room for two months. to see new evictions, community tries brother’s backyard. Anna Litvinenko, her husband and vitality from “Now I’m fi nding that I might have their four children got evicted from urban renewal, to hold its ground to move out of the city limits just to their three-bedroom apartment in East is one of the survive,” says the Portland school em- Portland in October. -

Research in Nonlinear Structural and Solid Mechanics
Supplement to NASA Conference Publication 2147 Research in Nonlinear Structural and Solid Mechanics ' Keynote address and panel discussion presented at a symposium held at Washington, D.C., October 6-8, 1980 NASA Supplement to NASA Conference Publication 2147 Research in Nonlinear Structural and Solid Mechanics Compiled by Harvey G. McComb, Jr. NASA Langley Research Center Ahmed K. Noor The George Washington University Joint Institute for Advancement of Flight Sciences NASA Langley Research Center Keynote address and panel discussion presented at a symposium sponsored by NASA Langley Research Center, Hampton, Virginia, and The George Washington University, Washington, D.C., in cooperation with the National Science Foundation, the American Society of Civil Engineers, and the American Society of Mechanical Engineers, and held at Washington, D.C., October 6-8, 1980 NASA National Aeronautics and Space Administration Scientific and Technical Information Branch 1981 FOREWORD A symposium on Computational Methods in Nonlinear Structural and Solid Mechanics was held in Washington, D.C., on October 6-8, 1980. NASA Langley Research Center and The George Washington University sponsored the symposium in cooperation with the National Science Foundation, the American Society of Civil Engineers, and the American Society of Mechanical Engineers. The purpose of the symposium was to provide a forum for communicating recent and projected advances in applied mechanics, numerical analysis, computer hardware and engineering software, and their impact on modeling and solution techniques in nonlinear structural and solid mechanics. The fields covered by the symposium are rapidly changing and are strongly impacted by current and projected advances in computer hardware. To foster effective development of the technology, therefore, an expert in computer hard- ware was invited to communicate in a keynote address his perceptions on new computing systems and their impact on computation.