Copyright © 1983, by the Author(S). All Rights Reserved
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Emerging Technologies Multi/Parallel Processing
Emerging Technologies Multi/Parallel Processing Mary C. Kulas New Computing Structures Strategic Relations Group December 1987 For Internal Use Only Copyright @ 1987 by Digital Equipment Corporation. Printed in U.S.A. The information contained herein is confidential and proprietary. It is the property of Digital Equipment Corporation and shall not be reproduced or' copied in whole or in part without written permission. This is an unpublished work protected under the Federal copyright laws. The following are trademarks of Digital Equipment Corporation, Maynard, MA 01754. DECpage LN03 This report was produced by Educational Services with DECpage and the LN03 laser printer. Contents Acknowledgments. 1 Abstract. .. 3 Executive Summary. .. 5 I. Analysis . .. 7 A. The Players . .. 9 1. Number and Status . .. 9 2. Funding. .. 10 3. Strategic Alliances. .. 11 4. Sales. .. 13 a. Revenue/Units Installed . .. 13 h. European Sales. .. 14 B. The Product. .. 15 1. CPUs. .. 15 2. Chip . .. 15 3. Bus. .. 15 4. Vector Processing . .. 16 5. Operating System . .. 16 6. Languages. .. 17 7. Third-Party Applications . .. 18 8. Pricing. .. 18 C. ~BM and Other Major Computer Companies. .. 19 D. Why Success? Why Failure? . .. 21 E. Future Directions. .. 25 II. Company/Product Profiles. .. 27 A. Multi/Parallel Processors . .. 29 1. Alliant . .. 31 2. Astronautics. .. 35 3. Concurrent . .. 37 4. Cydrome. .. 41 5. Eastman Kodak. .. 45 6. Elxsi . .. 47 Contents iii 7. Encore ............... 51 8. Flexible . ... 55 9. Floating Point Systems - M64line ................... 59 10. International Parallel ........................... 61 11. Loral .................................... 63 12. Masscomp ................................. 65 13. Meiko .................................... 67 14. Multiflow. ~ ................................ 69 15. Sequent................................... 71 B. Massively Parallel . 75 1. Ametek.................................... 77 2. Bolt Beranek & Newman Advanced Computers ........... -

Lehman Brothers Holdings
SECURITIES AND EXCHANGE COMMISSION FORM 13F-HR/A Initial quarterly Form 13F holdings report filed by institutional managers [amend] Filing Date: 2004-12-01 | Period of Report: 2004-09-30 SEC Accession No. 0000806085-04-000212 (HTML Version on secdatabase.com) FILER LEHMAN BROTHERS HOLDINGS INC Mailing Address Business Address LEHMAN BROTHERS LEHMAN BROTHERS CIK:806085| IRS No.: 133216325 | State of Incorp.:DE | Fiscal Year End: 1130 745 SEVENTH AVENUE 745 SEVENTH AVENUE Type: 13F-HR/A | Act: 34 | File No.: 028-03182 | Film No.: 041177215 NEW YORK NY 10019 NEW YORK NY 10019 SIC: 6211 Security brokers, dealers & flotation companies 2125267000 Copyright © 2012 www.secdatabase.com. All Rights Reserved. Please Consider the Environment Before Printing This Document NON-CONFIDENTIAL <TABLE> <CAPTION> TITLE OF VALUE SHRS OR SH/ PUT/ INVESTMENT OTHER VOTING AUTHORITY NAME OF ISSUER CLASS CUSIP (X$1000) PRN AMT PRN CALL DISCRETION MANAGERS SOLE SHARED NONE <S> <C> <C> <C> <C> <C> <C> -------------------------------- -------- --------- -------- ------- --- ---- ---------- -------- -------- -------- -------- ***DAIMLERCHRYSLER A.G. COMMON D1668R123 9514 227843 SH DEFINED 01 227843 0 0 ***SANOFI AVENTIS COMMON F5548N101 34013 491666 SH DEFINED 01 491666 0 0 PNM RESOURCES COMMON GKD49H100 0 50000 SH DEFINED 01 0 0 50000 PNM RESOURCES COMMON GKD49H100 0 200000 SH DEFINED 01 200000 0 0 ***ACE LTD-ORD COMMON G0070K103 9964 248616 SH DEFINED 01 0 0 248616 ***ASPEN INSURANCE HOLDINGS COMMON G05384105 3950 171680 SH DEFINED 01 171680 0 0 ***ASSURED GUARANTY -

FEI COMPANY 5350 NE Dawson Creek Drive Hillsboro, Oregon 97124-5793
FEI COMPANY 5350 NE Dawson Creek Drive Hillsboro, Oregon 97124-5793 NOTICE OF ANNUAL MEETING OF SHAREHOLDERS To Be Held On May 7, 2015 To the Shareholders of FEI Company: Notice is hereby given that the Annual Meeting of Shareholders of FEI Company, an Oregon corporation, will be held on Thursday, May 7, 2015, at 9:00 a.m. local time, at our corporate headquarters located at 5350 NE Dawson Creek Drive, Hillsboro, Oregon 97124-5793. The purposes of the annual meeting will be: 1. To elect members of FEI's Board of Directors to serve for the following year and until their successors are duly elected and qualified; 2. To consider and vote on a proposal to amend FEI's 1995 Stock Incentive Plan to increase the number of shares of our common stock reserved for issuance under the plan by 250,000 shares; 3. To consider and vote on a proposal to amend FEI's Employee Share Purchase Plan to increase the number of shares of our common stock reserved for issuance under the plan by 250,000 shares; 4. To approve, on an advisory basis, the appointment of KPMG LLP as FEI's independent registered public accounting firm for the year ending December 31, 2015; 5. To approve, on an advisory basis, FEI's executive compensation; and 6. To transact such other business as may properly come before the meeting or at any and all postponements or adjournments of the meeting. Only shareholders of record at the close of business on March 2, 2015 and their proxies will be entitled to vote at the annual meeting and any adjournment or postponement of the meeting. -
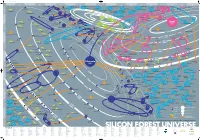
Silicon Forest Universe
15239 Poster 9/16/02 1:03 PM Page 1 AB CDE FGH I JKL M N O P Q R S Pearlsoft COMSAT General Integrated Systems Ashwood Group '85 Qualis Design fka CPU International Nel-Tech Development '98 Qsent '01 Briefsmart.com '00 Relyent TrueDisk Trivium Systems '80 '74 '99 '90 Gearbeat '81 Relational Systems Galois 3DLand Teradyne in 2001 '85 '00 '98 Solution Logic SwiftView Imagenation '89 Metro One IronSpire '84 Smart Mediary Systems Connections 13 Telecommunications WireX GenRad in 1996 '00 CyberOptics E-Core Salu Logiplex '79 MyHealthBank Semiconductor Cotelligent Technologies Fujitsu America Barco Metheus '77 '99 Group Knowledge fka United Data Biotronik Timlick & Associates in 1999 Gadget Labs Adaptive Solutions Wave International Processing Cascade Laser '98 Webridge Axis Clinical Software Mitron Basicon '91 GemStone fka Servio Logic Source Services '83 Integra Telecom Accredo FaxBack Polyserve Metheus Intersolv Babcock & Jenkins Electro '79 Informedics Scientific Sliceware Graphic Software Systems Industries IBM 12 in 1999 Atlas Telecom 1944 Sequent Computer ProSight Credence in 2001 19 ADC Kentrox '78 Oracle '69 Merant Datricon 60s Informix Systems FEI Sage Software fka Polytron MKTX 197 Mikros Nike 0s Etec Systems '63 19 Sentrol in 1995 Intel 80s SEH America Teseda Oregon Graduate Institute Flight Dynamics 1976 '97 1990 Purchasing Solutions Fluence ~ Relcom Vidco Mushroom Resources Cunningham & Cunningham '99 Myteam.com Praegitzer Industries Integrated Measurement Systems Zicon Digital World Lucy.Com Nonbox in 2001 ATEQ 11 Software Access -

Technology Transfer Joint Hearing
TECHNOLOGY TRANSFER JOINT HEARING BEFORE THE COMMITTEE ON SCIENCE AND TECHNOLOGY HOUSE OF REPRESENTATIVES AND THE SUBCOMMITTEE ON ENERGY RESEARCH AND DEVELOPMENT OF THE COMMITTEE ON ENERGY AND NATURAL RESOURCES U.S. SENATE NINETY-NINTH CONGRESS SECOND SESSION SEPTEMBER 4, 1986 [No. 161] Printed for the use of the Committee on Science and Technology, and the Committee on Energy and Natural Resources, U.S. Senate U.S. GOVERNMENT PRINTING OFFICE 67-150 0 WASHINGTON : 1987 For sale by the Superintendent of Documents, Congressional Sales Office US. Government Printing Office, Washington, DC 20402 rX K ' .., ;.- .,,... COMMITTEE ON SCIENCE AND TECHNOLOGY DON FUQUA, Florida, Chairman ROBERT A. ROE, New Jersey MANUEL LUJAN, JR., New Mexico* GEORGE E. BROWN, JH., California ROBERT S. WALKER, Pennsylvania JAMES H. SCHEUER, New York F. JAMES SENSENBRENNER, JR., MARILYN LLOYD, Tennessee Wisconsin TIMOTHY <E. WIRTH, Colorado CLAUDINE SCHNEIDER, Rhode Island DOUG WALGREN, Pennsylvania SHERWOOD L. BOEHLERT, New York DAN GLICKMAN, Kansas TOM LEWIS, Florida ROBERT A. YOUNG, Missouri DON RTTTER, Pennsylvania HAROLD L. VOLKMER, Missouri SID W. MORRISON, Washington BILL NELSON, Florida RON PACKARD, California STAN LUNDINE, New York JAN MEYERS, Kansas RALPH M. HALL, Texas ROBERT C. SMITH, New Hampshire DAVE McCURDY, Oklahoma PAUL B. HENRY, Michigan NORMAN Y. MINETA, California HARRIS W. FAWELL, Illinois BUDDY MACKAY, Florida" WILLIAM W. COBEY, JR., North Carolina TIM VALENTINE, North Carolina JOE BARTON, Texas HARRY M. REID, Nevada D. FRENCH SLAUGHTER, JR., Virginia ROBERT G. TORRICELLI, New Jersey DAVID S. MONSON, Utah RICK BOUCHER, Virginia TERRY BRUCE, Illinois RICHARD H. STALLINGS, Idaho BART GORDON, Tennessee JAMES A. TRAFICANT, JR., Ohio JIM CHAPMAN, Texas HAROLD P. -

Lehman Brothers Holdings
SECURITIES AND EXCHANGE COMMISSION FORM 13F-HR/A Initial quarterly Form 13F holdings report filed by institutional managers [amend] Filing Date: 2005-02-17 | Period of Report: 2004-12-31 SEC Accession No. 0000806085-05-000044 (HTML Version on secdatabase.com) FILER LEHMAN BROTHERS HOLDINGS INC Mailing Address Business Address LEHMAN BROTHERS LEHMAN BROTHERS CIK:806085| IRS No.: 133216325 | State of Incorp.:DE | Fiscal Year End: 1130 745 SEVENTH AVENUE 745 SEVENTH AVENUE Type: 13F-HR/A | Act: 34 | File No.: 028-03182 | Film No.: 05624078 NEW YORK NY 10019 NEW YORK NY 10019 SIC: 6211 Security brokers, dealers & flotation companies 2125267000 Copyright © 2012 www.secdatabase.com. All Rights Reserved. Please Consider the Environment Before Printing This Document <TABLE> <CAPTION> TITLE OF VALUE SHRS OR SH/ PUT/ INVESTMENT OTHER VOTING AUTHORITY NAME OF ISSUER CLASS CUSIP (X$1000) PRN AMT PRN CALL DISCRETION MANAGERS SOLE SHARED NONE <S> <C> <C> <C> <C> <C> <C> -------------------------------- -------- --------- -------- ------- --- ---- ---------- -------- -------- -------- -------- ***DAIMLERCHRYSLER A.G. COMMON D1668R123 226 4707 SH DEFINED 01 4707 0 0 ***DEUTSCHE BANK AG COMMON D18190898 397 4463 SH DEFINED 01 4463 0 0 ***ACE LTD-ORD COMMON G0070K103 6966 162834 SH DEFINED 01 0 0 162834 ***AMDOCS LIMITED COMMON G02602103 547 20661 SH DEFINED 01 0 0 20661 ***ARCH CAPITAL GROUP LTD COMMON G0450A105 230 5957 SH DEFINED 01 5957 0 0 ***ARLINGTON TANKERS LTD COMMON G04899103 1038 45250 SH DEFINED 01 45250 0 0 ***ASPEN INSURANCE HOLDINGS COMMON -

Portland Tribune
LOOK FOR INVITATIONS TO BID AND PUBLIC NOTICES STARTING ON PAGE 14 FEBRUARY 23, 2016 FEBRUARY EXPORT-IMPORT BANK CREATING Business U.S. JOBS Tribune BY JOHN M. VINCENT TEKTRONIX WEFUNDER TURNS 70 TAKES AMTRAK CENTRAL METRO EASTSIDE: INNOVATORS R2SHOP2 #3: THE SOCIETY INSIDE HOTEL 2 BUSINESS TRIBUNE Tuesday, February 23, 2016 5,000 LOCAL STORIES every month and GROWING! Beaverton Business Tribune Canby Clackamas Estacada Forest Grove Gresham—TuesdayGresham Tuesday Gresham—FridayGresham—Friday Hillsboro King City Lake Oswego Oswego Madras Ashton Eaton talks track, life GETTING IT DONE World decathlon champion has new goals in mind — SEE SPORTS, B10 Blazers forward Ed Davis fl ies under the radar — SEE SPORTS, B10 PortlandTribune PortlandTribune THURSDAY, DECEMBER 10, 2015 • TWICE CHOSEN THE NATION’S BEST NONDAILY PAPER • PORTLANDTRIBUNE.COM • PUBLISHED TUESDAY AND THURSDAY THURSDAY, DECEMBER 17, 2015 • TWICE CHOSEN THE NATION’S BEST NONDAILY PAPER • PORTLANDTRIBUNE.COM • PUBLISHED TUESDAY AND THURSDAY The Portland Development Commission’s East Portlanders push Trang Lam discusses Lents redevelopment prospects outside Working back on gentrifi cation Class Acupuncture. landlord decided to sell the build- children. They wound up living in a Lents, starting As residents face more ing, so she’s living in an RV in her cramped hotel room for two months. to see new evictions, community tries brother’s backyard. Anna Litvinenko, her husband and vitality from “Now I’m fi nding that I might have their four children got evicted from urban renewal, to hold its ground to move out of the city limits just to their three-bedroom apartment in East is one of the survive,” says the Portland school em- Portland in October. -

Research in Nonlinear Structural and Solid Mechanics
Supplement to NASA Conference Publication 2147 Research in Nonlinear Structural and Solid Mechanics ' Keynote address and panel discussion presented at a symposium held at Washington, D.C., October 6-8, 1980 NASA Supplement to NASA Conference Publication 2147 Research in Nonlinear Structural and Solid Mechanics Compiled by Harvey G. McComb, Jr. NASA Langley Research Center Ahmed K. Noor The George Washington University Joint Institute for Advancement of Flight Sciences NASA Langley Research Center Keynote address and panel discussion presented at a symposium sponsored by NASA Langley Research Center, Hampton, Virginia, and The George Washington University, Washington, D.C., in cooperation with the National Science Foundation, the American Society of Civil Engineers, and the American Society of Mechanical Engineers, and held at Washington, D.C., October 6-8, 1980 NASA National Aeronautics and Space Administration Scientific and Technical Information Branch 1981 FOREWORD A symposium on Computational Methods in Nonlinear Structural and Solid Mechanics was held in Washington, D.C., on October 6-8, 1980. NASA Langley Research Center and The George Washington University sponsored the symposium in cooperation with the National Science Foundation, the American Society of Civil Engineers, and the American Society of Mechanical Engineers. The purpose of the symposium was to provide a forum for communicating recent and projected advances in applied mechanics, numerical analysis, computer hardware and engineering software, and their impact on modeling and solution techniques in nonlinear structural and solid mechanics. The fields covered by the symposium are rapidly changing and are strongly impacted by current and projected advances in computer hardware. To foster effective development of the technology, therefore, an expert in computer hard- ware was invited to communicate in a keynote address his perceptions on new computing systems and their impact on computation. -

A Decade of Semiconductor Companies—1988 Edition to Keep Clients Informed of These New and Emerging Companies
1988 y DataQuest Do Not Remove A. Decade of Semiconductor Companies 1988 Edition Components Division TABLE OF CONTENTS Page I. Introduction 1 II. Venture Capital 11 III. Strategic Alliances 15 IV. Product Analysis 56 Emerging Technology Companies 56 Analog ICs 56 ASICs 58 Digital Signal Processing 59 Discrete Semiconductors 60 Gallium Arsenide 60 Memory 62 Microcomponents 64 Optoelectronics 65 Telecommunication ICs 65 Other Products 66 Bubble Memory 67 V. Company Profiles (139) 69 A&D Co., Ltd. 69 Acrian Inc. 71 ACTEL Corporation 74 Acumos, Inc. 77 Adaptec, Inc. 79 Advanced Linear Devices, Inc. 84 Advanced Microelectronic Products, Inc. 87 Advanced Power Technology, Inc. 89 Alliance Semiconductor 92 Altera Corporation 94 ANADIGICS, Inc. 100 Applied Micro Circuits Corporation 103 Asahi Kasei Microsystems Co., Ltd. 108 Aspen Semiconductor Corporation 111 ATMEL Corporation 113 Austek Microsystems Pty. Ltd. 116 Barvon Research, Inc. 119 Bipolar Integrated Technology 122 Brooktree Corporation 126 California Devices, Ihc. 131 California Micro Devices Corporation 135 Calmos Systems, Inc. 140 © 1988 Dataquest Incorporated June TABLE OF CONTENTS (Continued) Pagg Company Profiles (Continued) Calogic Corporation 144 Catalyst Semiconductor, Inc. 146 Celeritek, Inc. ISO Chartered Semiconductor Pte Ltd. 153 Chips and Technologies, Inc. 155 Cirrus Logic, Inc. 162 Conductus Inc. 166 Cree Research Inc. 167 Crystal Semiconductor Corporation 169 Custom Arrays Corporation 174 Custom Silicon Inc. 177 Cypress Semiconductor Corporation 181 Dallas Semiconductor Corporation 188 Dolphin Integration SA 194 Elantec, Inc. 196 Electronic Technology Corporation 200 Epitaxx Inc. 202 European Silicon Structures 205 Exel Microelectronics Inc. 209 G-2 Incorporated 212 GAIN Electronics 215 Gazelle Microcircuits, Inc. 218 Genesis Microchip Inc. -

19850008216.Pdf
/ 17/,45C,4Z-/_Z,,m<_o NASA Contractor Report 172500 ICASE REPORT NO. 85-1 NASA-CR-172500 i 19850008216 . i + . J ICASE z- SOLUTION OF PARTIAL DIFFERENTIAL EQUATIONS ON VECTOR AND PARALLEL COMPUTERS James M. Ortega Robert G. Volgt Fo_ _F,_ERENCE Contract Nos. NASI-17070 and NASI-17130 _O_YOB£TAgE_rBO_r_mP_O_ January 1985 INSTITUTE FOR COMPUTER APPLICATIONS IN SCIENCE AND ENGINEERING NASA Langley Research Center, Hampton, Virginia 23665 Operated by the Universities Space Research Association LIBIItttlY _! .. /i o National Aeronautics and Space Administration LANGLEYRESEARCHCENTER LIBRARY,NA_SA Langley Research Center HAMPTON,VIRGINIA Hampton,Virginia23665 SOLUTION OF PARTIAL DIFFERENTIAL EQUATIONS ON VECTOR AND PARALLEL COMPUTERS James M. Ortega University of Virginia Robert G. Voigt Institute for Computer Applications in Science and Engineering ABSTRACT In this paper we review the present status of numerical methods for partial differential equations on vector and parallel computers. A discussion of the relevant aspects of these computers and a brief review of their development is included, with par- ticular attention paid to those characteristics that influence algorithm selecUon. Both direct and iteraUve methods are given for elliptic equations as well as explicit and impli- cit methods for initial-boundary value problems. The intent is to point out attractive methods as well as areas where this class of computer architecture cannot be fully utilized because of either hardware restricUons or the lack of adequate algorithms. A brief dis- cussion of application areas utilizing these computers is included. Research of the first author was supported in part by the National Aeronautics and .Space Administration under NASA Grant NAG-I-46. -

EPRI Journal 1988 No. 7
EPRI JOURNAL is published eight times each year (January/February, March, April/May, June, July/August, September, October/November, and December) by the Electric Power Research Institute. EPRI was founded in 1972 by the nation's electric utilities to develop and manage a technology program for improving electric power production, distribution, and utilization. EPRI JOURNAL Staff and Contributors Brent Barker, Editor in Chief David Dietrich, Managing Editor Ralph Whitaker, Feature Editor Taylor Moore, Senior Feature Writer David Boutacoff, Feature Writer Eugene Robinson, Technical Editor Mary Ann Garneau, Production Editor Jean Smith, Program Secretary Richard G. Claeys, Director Corporate Communications Division Graphics Consultant: Frank A. Rodriquez © 1988 by Electric Power Research Institute, Inc. Permission to reprint is granted by EPRI, provided credit to the EPRI JOURNAL is given. Information on bulk reprints available on request. Electric Power Research Institute, EPRI, and EPRI JOURNAL are registered service marks or trade marks of Electric Power Research Institute, Inc. Address correspondence to: Editor in Chief EPRI JOURNAL Electric Power Research Institute P.O. Box 10412 Palo Alto, California 94303 Please include the code number on your mailing label with correspondence concerning subscriptions. Cover: The incredible number-crunching capabilities of supercomputers have allowed scientists to mathematically model complex systems and processes that eluded them in earlier decades. Researchers hope that new supercomputing concepts will open possibilities for real-time control of the nation's highly interconnected power networks. (Photo: Topographical seismic modeling, courtesy Floating Point Systems.) EDITORIAL The Supercomputer Challenge The emergence of a new generation of supercomputers is challenging some long-held beliefs in the electric power industry concerning the suitability of meeting utility needs with large number-crunching machines. -

CASCADE MICROTECH, INC. (Exact Name of Registrant As Specified in Its Charter)
8VhXVYZB^XgdiZX]!>cX# '%%.6ccjVaGZedgi TO OUR SHAREHOLDERS: Good-Die (KGD) in high volume. Pyramid Probes provide unique and Business conditions in 2009 continued to be a challenge for the compelling technical advantages in high-growth smart phone and RF global economy and the semiconductor industry as a whole. For wireless applications, as well as set the standard for multi-site RF testing example, capital expenditures, a major indicator for the industry, were to produce best cost-of-test. By focusing on expanding our relationships down 40% in 2009 compared to 2008, according to IC Insights. Cascade with key market leaders, we gain insights into new addressable markets, Microtech’s results reflect this in one sense; however, we positioned resulting in new design wins. We are also reinforcing our technology ourselves for emerging from the recession with an excellent market leadership position by working closely with our customers to achieve presence and balance sheet. Revenues were $53.5 million, down 30% their aggressive RF performance and cost-of-test goals. year over year. Revenues in the fourth quarter of 2009 actually increased Investment in our test sockets product line is positioning Cascade by 11% from the third quarter of 2009, and indicated a continued trend Microtech for future growth. Considerable achievements have been of recovery in the market. The net loss for 2009 was $7.6 million, which made in developing production processes, which allow us to was also an improvement over 2008. dramatically shorten lead times and improve