Section 7: DSP Hardware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

System Requirements for LWC Connect to Learning
System Requirements for LWC Connect to Learning Run the Adobe Connect Diagnostic to see if you meet the Flash, connection, and add-in minimum requirements https://na3cps.adobeconnect.com/common/help/en/support/meeting_test.htm MINIMUM COMPUTER SYSTEM REQUIREMENTS: Windows • 1.4GHz Intel® Pentium® 4 or faster processor (or equivalent) for Microsoft® Windows® XP, Windows 7 or Windows 8 • Windows 8.1 (32-bit/64-bit), Windows 8 (32-bit/64-bit), Windows 7 (32-bit/64-bit), Windows XP • 512MB of RAM (1GB recommended) for Windows XP, Windows 7 or Windows 8 • Microsoft Internet Explorer 8, 9, 10, 11; Mozilla Firefox; Google Chrome • Adobe® Flash® Player 11.2+ Mac OS • 1.83GHz Intel Core™ Duo or faster processor • 512MB of RAM (1GB recommended) • Mac OS X 10.7.4, 10.8, 10.9 • Mozilla Firefox; Apple Safari; Google Chrome • Adobe Flash Player 11.2+ Linux • Ubuntu 12.04; Red Hat Enterprise Linux 6; OpenSuSE 12.2 • No Add-in support for Linux. Users on Linux can attend meetings in the browser. • Mozilla Firefox • Adobe Flash Player 11.2+ Mobile • Apple supported devices: iPhone 5S, iPhone 5, iPhone 4S, iPad with Retina display, iPad 3, iPad 2, iPad mini, and iPod touch (4th & 5th generations) • Apple supported OS versions summary: iOS 6 and higher • Android supported devices: Motorola DROID RAZR MAXX, Motorola Atrix, Motorola Xoom, Samsung Galaxy Tab 2 10.1, Samsung Galaxy S3 & S4, Nexus 7 tablet • Android supported OS versions summary: 2.3.4 and higher 1 ADDITIONAL REQUIREMENTS • Latest version of Adobe Flash Player installed o Download latest version at http://get.adobe.com/flashplayer/ . -

Ebook - Informations About Operating Systems Version: August 15, 2006 | Download
eBook - Informations about Operating Systems Version: August 15, 2006 | Download: www.operating-system.org AIX Internet: AIX AmigaOS Internet: AmigaOS AtheOS Internet: AtheOS BeIA Internet: BeIA BeOS Internet: BeOS BSDi Internet: BSDi CP/M Internet: CP/M Darwin Internet: Darwin EPOC Internet: EPOC FreeBSD Internet: FreeBSD HP-UX Internet: HP-UX Hurd Internet: Hurd Inferno Internet: Inferno IRIX Internet: IRIX JavaOS Internet: JavaOS LFS Internet: LFS Linspire Internet: Linspire Linux Internet: Linux MacOS Internet: MacOS Minix Internet: Minix MorphOS Internet: MorphOS MS-DOS Internet: MS-DOS MVS Internet: MVS NetBSD Internet: NetBSD NetWare Internet: NetWare Newdeal Internet: Newdeal NEXTSTEP Internet: NEXTSTEP OpenBSD Internet: OpenBSD OS/2 Internet: OS/2 Further operating systems Internet: Further operating systems PalmOS Internet: PalmOS Plan9 Internet: Plan9 QNX Internet: QNX RiscOS Internet: RiscOS Solaris Internet: Solaris SuSE Linux Internet: SuSE Linux Unicos Internet: Unicos Unix Internet: Unix Unixware Internet: Unixware Windows 2000 Internet: Windows 2000 Windows 3.11 Internet: Windows 3.11 Windows 95 Internet: Windows 95 Windows 98 Internet: Windows 98 Windows CE Internet: Windows CE Windows Family Internet: Windows Family Windows ME Internet: Windows ME Seite 1 von 138 eBook - Informations about Operating Systems Version: August 15, 2006 | Download: www.operating-system.org Windows NT 3.1 Internet: Windows NT 3.1 Windows NT 4.0 Internet: Windows NT 4.0 Windows Server 2003 Internet: Windows Server 2003 Windows Vista Internet: Windows Vista Windows XP Internet: Windows XP Apple - Company Internet: Apple - Company AT&T - Company Internet: AT&T - Company Be Inc. - Company Internet: Be Inc. - Company BSD Family Internet: BSD Family Cray Inc. -
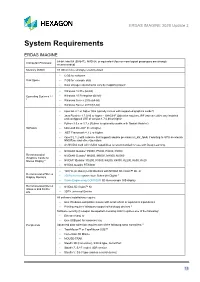
ERDAS IMAGINE 2020 Update 3
ERDAS IMAGINE 2020 Update 3 System Requirements ERDAS IMAGINE 64-bit: Intel 64 (EM64T), AMD 64, or equivalent (four or more logical processors are strongly Computer/ Processor recommended) Memory (RAM) 16 GB or more strongly recommended • 6 GB for software Disk Space • 7 GB for example data • Data storage requirements vary by mapping project1 • Windows 10 Pro (64-bit) Operating Systems 2, 3, • Windows 10 Enterprise (64-bit) 4 • Windows Server 2016 (64-bit) • Windows Server 2019 (64-bit) • OpenGL 2.1 or higher (this typically comes with supported graphics cards 5) • Java Runtime 1.7.0.80 or higher - IMAGINE Objective requires JRE and can utilize any installed and configured JRE of version 1.7.0.80 or higher • Python 3.6.x or 3.7.x (Python is optionally usable with Spatial Modeler) Software • Microsoft DirectX® 9c or higher • .NET Framework 4.7.2 or higher • OpenCL 1.2 with a device that supports double precision (cl_khr_fp64) if wanting to GPU accelerate NNDiffuse and other Operators • An NVIDIA card with CUDA capabilities is recommended for use with Deep Learning. • NVIDIA® Quadro® P6000, P5000, P4000, P2000 Recommended • NVIDIA® Quadro® M6000, M5000, M4000, M2000 Graphics Cards for Stereo Display 6 • NVIDIA® Quadro® K5200, K5000, K4200, K4000, K2200, K600, K420 • NVIDIA Quadro RTX4000 • 120 Hz (or above) LCD Monitors with NVIDIA 3D Vision™ Kit, or Recommended Stereo • 3D PluraView system from Schneider Digital 7 Display Monitors • Vision Engineering CONTOUR 3D stereoscopic GIS display Recommended Stereo • NVIDIA 3D Vision™ Kit Glasses -

Level One Benchmark Windows NT 4.0 Operating Systems V1.0.5
Level One Benchmark Windows NT 4.0 Operating Systems V1.0.5 Copyright 2003, The Center for Internet Security www.cisecurity.org Page 2 of 32 Terms of Use Agreement Background. CIS provides benchmarks, scoring tools, software, data, information, suggestions, ideas, and other services and materials from the CIS website or elsewhere (“Products”) as a public service to Internet users worldwide. Recommendations contained in the Products (“Recommendations”) result from a consensus-building process that involves many security experts and are generally generic in nature. The Recommendations are intended to provide helpful information to organizations attempting to evaluate or improve the security of their networks, systems and devices. Proper use of the Recommendations requires careful analysis and adaptation to specific user requirements. The Recommendations are not in any way intended to be a “quick fix” for anyone’s information security needs. No representations, warranties and covenants. CIS makes no representations, warranties or covenants whatsoever as to (i) the positive or negative effect of the Products or the Recommendations on the operation or the security of any particular network, computer system, network device, software, hardware, or any component of any of the foregoing or (ii) the accuracy, reliability, timeliness or completeness of any Product or Recommendation. CIS is providing the Products and the Recommendations “as is” and “as available” without representations, warranties or covenants of any kind. User agreements. By using the Products and/or the Recommendations, I and/or my organization (“we”) agree and acknowledge that: 1. No network, system, device, hardware, software or component can be made fully secure; 2. -

An Introduction to Morphos
An Introduction to MorphOS Updated to include features to version 1.4.5 May 14, 2005 MorphOS 1.4 This presentation gives an overview of MorphOS and the features that are present in the MorphOS 1.4 shipping product. For a fully comprehensive list please see the "Full Features list" which can be found at: www.PegasosPPC.com Why MorphOS? Modern Operating Systems are powerful, flexible and stable tools. For the most part, if you know how to look after them, they do their job reasonably well. But, they are just tools to do a job. They've lost their spark, they're boring. A long time ago computers were fun, it is this background that MorphOS came from and this is what MorphOS is for, making computers fun again. What is MorphOS? MorphOS is a fully featured desktop Operating System for PowerPC CPUs. It is small, highly responsive and has very low hardware requirements. The overall structure of MorphOS is based on a new modern kernel called Quark and a structure divided into a series of "boxes". This system allows different OS APIs to be used along side one another but isolates them so one cannot compromise the other. To make sure there is plenty of software to begin with the majority of development to date has been based on the A- BOX. In the future the more advanced Q-Box shall be added. Compatibility The A-Box is an entire PowerPC native OS layer which includes source and binary compatibility with software for the Commodore A500 / A1200 etc. -

Low Power Asynchronous Digital Signal Processing
LOW POWER ASYNCHRONOUS DIGITAL SIGNAL PROCESSING A thesis submitted to the University of Manchester for the degree of Doctor of Philosophy in the Faculty of Science & Engineering October 2000 Michael John George Lewis Department of Computer Science 1 Contents Chapter 1: Introduction ....................................................................................14 Digital Signal Processing ...............................................................................15 Evolution of digital signal processors ....................................................17 Architectural features of modern DSPs .........................................................19 High performance multiplier circuits .....................................................20 Memory architecture ..............................................................................21 Data address generation .........................................................................21 Loop management ..................................................................................23 Numerical precision, overflows and rounding .......................................24 Architecture of the GSM Mobile Phone System ...........................................25 Channel equalization ..............................................................................28 Error correction and Viterbi decoding ...................................................29 Speech transcoding ................................................................................31 Half-rate and enhanced -

State Inconsistency Issues in Local Area Network-Based Distributed Kernels
State inconsistency issues in local area network-based distributed kernels K. Ravindran & Samuel T. Chanson Technical Report 85-7 August 1985 ABSTRACT State inconsistency is an inherent problem m distributed computing systems (DCS) because of the high degree of autonomy of the executing entities and the inherent delays and errors in communicating events among them. Thus any reliable DCS should provide means to recover from such errors. This paper discusses the state inconsistency issues and their solution techniques in local area network based distri buted kernels. In particular, we deal with state inconsistencies due to i) failures of processes, machines and/or the network, ii) packet losses, iii) new machines joining or exiting from the network, and iv) processes or hosts migrating from one machine to another in the network. The solutions presented are mostly provided within the ker nel itself and are transparent to the applications. I' State inconsistency issues in local area network-based distributed kernels 1.0 Introduction As local area network ( LAN ) technologies move out of the laboratory and into the market place interests in LAN-based distributed computing systems ( LDCS ) have become widespread. Several experimental LAN-based distributed kernels have been built in the last few years including the V-system (3), Rochester's Intelligent Gateway (6], PORT [9], Accent (7], SHOSHIN [11], DEMOS(13) and Eden [18] . These distributed ker nels manage objects which may physically reside on different machines. The executing entities in such systems exhibit a high degree of autonomy but may interact with one another from time to time. Thus a state change in one entity may cause the state of one or more other entities to change. -

The Digital Signal Processor Derby
SEMICONDUCTORS The newest breeds trade off speed, energy consumption, and cost to vie for The an ever bigger piece of the action Digital Signal Processor BY JENNIFER EYRE Derby Berkeley Design Technology Inc. pplications that use digital signal-processing purpose processors typically lack these specialized features and chips are flourishing, buoyed by increasing per- are not as efficient at executing DSP algorithms. formance and falling prices. Concurrently, the For any processor, the faster its clock rate or the greater the market has expanded enormously, to an esti- amount of work performed in each clock cycle, the faster it can mated US $6 billion in 2000. Vendors abound. complete DSP tasks. Higher levels of parallelism, meaning the AMany newcomers have entered the market, while established ability to perform multiple operations at the same time, have companies compete for market share by creating ever more a direct effect on a processor’s speed, assuming that its clock novel, efficient, and higher-performing architectures. The rate does not decrease commensurately. The combination of range of digital signal-processing (DSP) architectures available more parallelism and faster clock speeds has increased the is unprecedented. speed of DSP processors since their commercial introduction In addition to expanding competition among DSP proces- in the early 1980s. A high-end DSP processor available in sor vendors, a new threat is coming from general-purpose 2000 from Texas Instruments Inc., Dallas, for example, is processors with DSP enhancements. So, DSP vendors have roughly 250 times as fast as the fastest processor the company begun to adapt their architectures to stave off the outsiders. -

OMAP-L137 C6000 DSP+ARM Processor
Product Sample & Technical Tools & Support & Folder Buy Documents Software Community OMAP-L137 www.ti.com SPRS563F –SEPTEMBER 2008–REVISED FEBRUARY 2013 OMAP-L137 Low-Power Applications Processor Check for Samples: OMAP-L137 1 OMAP-L137 Low-Power Applications Processor 1.1 Features 1234 • Highlights – 8K-Byte RAM (Vector Table) – Dual Core SoC – 64K-Byte ROM • 375/456-MHz ARM926EJ-S™ RISC MPU • C674x Instruction Set Features • 375/456-MHz C674x VLIW DSP – Superset of the C67x+™ and C64x+™ ISAs – TMS320C674x Fixed/Floating-Point VLIW – Up to 3648/2736 C674x MIPS/MFLOPS DSP Core – Byte-Addressable (8-/16-/32-/64-Bit Data) – Enhanced Direct-Memory-Access Controller – 8-Bit Overflow Protection 3 (EDMA3) – Bit-Field Extract, Set, Clear – 128K-Byte RAM Shared Memory – Normalization, Saturation, Bit-Counting – Two External Memory Interfaces – Compact 16-Bit Instructions – Three Configurable 16550 type UART • C674x Two Level Cache Memory Architecture Modules – 32K-Byte L1P Program RAM/Cache – LCD Controller – 32K-Byte L1D Data RAM/Cache – Two Serial Peripheral Interfaces (SPI) – 256K-Byte L2 Unified Mapped RAM/Cache – Multimedia Card (MMC)/Secure Digital (SD) – Flexible RAM/Cache Partition (L1 and L2) – Two Master/Slave Inter-Integrated Circuit • Enhanced Direct-Memory-Access Controller 3 – One Host-Port Interface (HPI) (EDMA3): – USB 1.1 OHCI (Host) With Integrated PHY – 2 Transfer Controllers (USB1) – 32 Independent DMA Channels • Applications – 8 Quick DMA Channels – Industrial Diagnostics – Programmable Transfer Burst Size – Test and measurement -

Stormc 3 User Manual English
Projektverwaltung N 5 StormC The professional choice Users manual ANSI C/C++ Development- system for the Amiga StormC User Manual 1 N COPYRIGHT Copyright STORMC C/C++ DEVELOPMENT SYSTEM Software and manual (c) 1995-1999 HAAGE & PARTNER Computer GmbH Authors: All rights reserved. This manual and the accompanying Jochen Becher software are copyrighted. They may not be reproduced in Editor any form (whether partically or in whole) by any means of Project Manager procedure, sent, multiplied and/or spread or be translated Debugger into another language. Profiler HAAGE & PARTNER assumes no responsibility for damage, Libraries caused by or resulting from malfunction of the program, Librarian faulty copies or error in the manual are to be led back. ScreenManager Wizard.Library Jens Gelhar ANSI C Compiler C++ Compiler PPC-Frontend pOS-Compiler Michael Rock Optimizing Linker Patcher FD2PRAGMA PPC-Backend Copyrights and trademarks: Markus Nerding Amiga is a registered trademark of its owner. Jeroen T. Vermeulen Amiga, AmigaDOS, Kickstart and Workbench are trade- Wouter van Oortmerssen marks. Peter-Frans Hollants Georges Goncalves SAS and SAS / C are registered trademarks of the SAS Insti- Kersten Emmrich tute Inc. Manual Translation The designation of products which are not from the HAAGE Peter (dreamy) Traskalik & PARTNER COMPUTER GmbH serves information purpo- Hartwig Haage ses exclusively and presents no trademark abuse. Graphics 2 StormC - the professional choice Licensee agreement N LICENSEE AGREEMENT 1 In general (1) Object of this contract is the use of computer programs from the HAAGE & PART- NER COMPUTER GmbH, including the manual as well as other pertinent, written material, subsequently summed up as the product. -

Workbench December 2002 Issue 187
Workbench December 2002 Issue 187 December 2002 Workbench 1 Editorial Happy Christmas everyone, This month we have articles covering the Elbox Trojan Horse code fiasco. Editor Tony Mulvihill Thankfully Elbox have fixed their little indiscretion. We have a rather long 0415 161 271 article covering MorphOS. If you’ve been confused about MorphOS then this [email protected] article should clear the air on Amiga OS 4’s closest competitor. We also have Contributions the final in my Future Tech series, meeting pics from October/November and Contributions can be soft copy (on floppy½ disk) or all the current Ami news. hard copy. It will be returned if requested and Don’t forget this months meeting is December the 8th, one week earlier than accompanied with a self- addressed envelope. usual. So until next year, have a happy Christmas and a great start to the new The editor of the Amiga Users Group Inc. newsletter year from all the AUG committee. Cheers :-) Workbench retains the right Tony Mulvihill to edit contributions for clarity and length. over 30 units were sold by Anything Send contributions to: Amiga Users Group Amiga, most of which were the G4 P.O. Box 2389 Seaford Victoria 3198 version. [email protected] Advertising This Months Meeting Advertising space is free for members to sell private December 8th 2002 items or services. Version 2 of Amiga Quake has been For information on commercial rates, contact: released. This version supports 68k, Tony Mulvihill PPC and MorphOS. 0415 161 2721 [email protected] Last Months Meeting November 17th 2002 I’ll be demonstrating the 68k version Deadlines Workbench is published Latest news and info. -

Thich Nhat Hanh, Tulku Thondup, and Others
BRANCHES OF LIGHT ! 2 ! FALL - WINTER • 2011 - 12 ! YES,YES, LIFE!LIFE! -MAYMAY WWEE BBEE JJOINEDOINED IINN TTHEHE GGREATREAT HHEARTEART ! l CONTENTS ELCOME to our latest ANYEN HAS OFFERED a 5 Upcoming Banyen Events Wissue of Branches of Breal “gathering of the 6 New Music Light! You’ll find here 223 ways” since 1970, and we 7 New Videos BRANCHES OF LIGHT reviews of new books, continue to morph and 8 Art, Creativity & Music News & Reviews from 8 Poetry, Writing & Stories Banyen Books and Sound music, videos, audios— learn how best we can serve 10 Yoga & the Hindu Traditions gems among the latest new the deep learnings and 12 Buddhism & Zen ISSUE 39 Fall-Winter-Spring 2011-2012 releases in all our fields, earth-loving harmony we 15 Tibetan Buddhism 17 Taoism & Chi Energetics Publisher & Editor from healing arts, new sci- humans need as we mature 17 BodyMind Healing Kolin Lymworth ence, body-mind explo- into a sustainable, responsi- 18 Healing Energies / Herbs Managing Editor & Production ration, ecology and com- ble planetary stewardship. Michael Bertrand 20 Bodywork & Movement munity... to angels, new 21 Food, Nutrition & Healing Design Laura Duncan Good Look Graphics economics, gardening, AY YOU FIND HERE the 22 Inspiration & Empowerment Cover Fiona Gamiet Articulate Design alchemy and metaphysics, Mresources to nourish 23 Psychology, Therapy & Dreams 24 Midlife & ElderWisdom On the Cover shamanism, the spiritual your journey. Reviews here 25 Jungian & Depth Psychology Flowers from Lizanne’s garden... 25 Mythology & Symbolism a rainbow over Bowen Island... traditions of the world, and are just the waves atop an 26 Meditation conscious evolution.