Analyse Typologique De La Pauvreté Multidimensionnelle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Le Plan Maroc Vert
Public Disclosure Authorized Public Disclosure Authorized Changements structurels des économies rurales dans la mondialisation Programme RuralStruc - Phase II Public Disclosure Authorized Novembre 2009 Public Disclosure Authorized RuralStruc Phase II – Rapport Maroc Page 1 Le programme RuralStruc sur les « Dimensions structurelles de la libéralisation pour l’agriculture et le développement rural » est une initiative conjointe de la Banque mondiale, de la Coopération française (Agence Française de Développement, Ministère de l’Agriculture et de la Pêche, Ministère des Affaires Etrangères et Européennes, Centre de Coopération Internationale en Recherche Agronomique pour le Développement) et du Fonds International pour le Développement Agricole (FIDA). Il est géré par la Banque mondiale. D’une durée de trois ans (2006-2009), son objectif est de proposer une analyse renouvelée des processus de libéralisation et d’intégration économique, dépassant la seule dimension commerciale, et de leurs conséquences sur l’agriculture et le secteur rural des pays en développement. Il a aussi pour vocation de présenter une vision actualisée de la situation des économies rurales en termes de niveaux de richesse et de diversification. Les résultats obtenus permettront d’améliorer le débat entre partenaires nationaux et internationaux et de fournir des orientations sur les politiques destinées au secteur agricole et au monde rural. Le programme repose sur un dispositif comparatif regroupant sept pays – Mexique, Nicaragua, Maroc, Sénégal, Mali, Kenya et Madagascar – correspondant à des stades différents du processus de libéralisation et d’intégration économique. Il conduit ses travaux avec des équipes d’experts et chercheurs nationaux. Deux phases ont été retenues : une première phase d’état des lieux (2006- 2007) ; une seconde phase d’études de cas sectorielles et régionales, appuyées par des enquêtes auprès de ménages ruraux (2007-2009). -

Use of GIS for Digital Mapping and Spatial Analysis of Landfills: Case of the Settat Province in Morocco
ECOLOGICAL ENGINEERING & ENVIRONMENTAL TECHNOLOGY Ecological Engineering & Environmental Technology 2021, 22(3), 1–10 Received: 2021.03.02 https://doi.org/10.12912/27197050/134868 Accepted: 2021.03.22 ISSN 2719-7050, License CC-BY 4.0 Published: 2021.04.06 Use of GIS for Digital Mapping and Spatial Analysis of Landfills: Case of the Settat Province in Morocco Ghizlane Benezzine1*, Abdeljalil Zouhri1, Yahya Koulali2 1 Hassan First University of Settat, Faculty of Sciences and Techniques, Applied Chemistry and Environment Laboratory, Settat, Morocco 2 Hassan First University of Settat, Faculty of Sciences and Techniques, Laboratory of Biochemistry, Neurosciences, Natural Resources and Environment, Settat, Morocco * Corresponding author’s e-mail: [email protected] ABSTRACT In Morocco, the population growth and changes in consumption and production patterns are increasing the amount of generated waste, particularly household solid waste. It is estimated at 6.9 million tons per year, of which 5.5 million tons in urban areas, with a ratio of 0.76 kg/inhabitant/day (Ministry of the Interior, national portal for lo- cal authorities, National Household Waste Program). In the absence of controlled landfills, this waste negatively affects living spaces and generates health and environmental problems. The province of Settat, which is affected by this scourge, inefficiently manages this household waste as in other regions, thus requiring improvement with the involvement of the actors concerned. This work involves the creation of a cartographic database of household waste in the province of Settat using a Geographic Information System (GIS). The analysis of the maps made, the observation of photos of existing landfills, and a diagnosis of the landfills in the Settat province have shown a direct negative impact on the different vital axes. -

Pauvrete, Developpement Humain
ROYAUME DU MAROC HAUT COMMISSARIAT AU PLAN PAUVRETE, DEVELOPPEMENT HUMAIN ET DEVELOPPEMENT SOCIAL AU MAROC Données cartographiques et statistiques Septembre 2004 Remerciements La présente cartographie de la pauvreté, du développement humain et du développement social est le résultat d’un travail d’équipe. Elle a été élaborée par un groupe de spécialistes du Haut Commissariat au Plan (Observatoire des conditions de vie de la population), formé de Mme Ikira D . (Statisticienne) et MM. Douidich M. (Statisticien-économiste), Ezzrari J. (Economiste), Nekrache H. (Statisticien- démographe) et Soudi K. (Statisticien-démographe). Qu’ils en soient vivement remerciés. Mes remerciements vont aussi à MM. Benkasmi M. et Teto A. d’avoir participé aux travaux préparatoires de cette étude, et à Mr Peter Lanjouw, fondateur de la cartographie de la pauvreté, d’avoir été en contact permanent avec l’ensemble de ces spécialistes. SOMMAIRE Ahmed LAHLIMI ALAMI Haut Commissaire au Plan 2 SOMMAIRE Page Partie I : PRESENTATION GENERALE I. Approche de la pauvreté, de la vulnérabilité et de l’inégalité 1.1. Concepts et mesures 1.2. Indicateurs de la pauvreté et de la vulnérabilité au Maroc II. Objectifs et consistance des indices communaux de développement humain et de développement social 2.1. Objectifs 2.2. Consistance et mesure de l’indice communal de développement humain 2.3. Consistance et mesure de l’indice communal de développement social III. Cartographie de la pauvreté, du développement humain et du développement social IV. Niveaux et évolution de la pauvreté, du développement humain et du développement social 4.1. Niveaux et évolution de la pauvreté 4.2. -
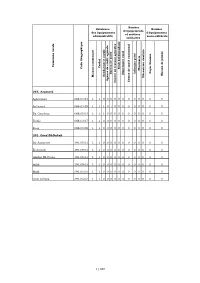
M a Is O N C O M M U N a Le C a Ïd a T G E N D a Rm E Rie Ro Y a Le A
Nombre Existence Nombre d'équipements des équipements d'équipements et services administratifs socio-culturels sanitaires Commune rurale Caïdat Code Géographique Souk Souk hebdomadaire Pharmacie Foyer féminin Infirmier privé Bureau deBureau poste Maison de jeunes Dispensaire rural Maison communale Mécanicien dentiste Gendarmerie royale Agence de crédit agricole Centre de santé communal Centre de travaux agricoles 066. Aousserd Aghouinite 066.03.03 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Aousserd 066.03.05 1 1 1 0 1 0 0 0 0 0 0 0 0 0 Bir Gandouz 066.05.03 1 1 1 0 0 0 0 0 0 0 0 0 0 0 Tichla 066.03.07 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Zoug 066.03.09 1 1 0 0 0 0 0 0 0 0 0 0 0 0 391. Oued Ed-Dahab Bir Anzarane 391.05.01 1 1 0 0 0 0 0 0 0 0 0 0 0 0 El Argoub 391.09.01 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Gleibat EL Foula 391.05.03 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Imlili 391.09.03 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Mijik 391.05.05 1 1 0 0 0 0 0 0 0 0 0 0 0 0 Oum Dreyga 391.05.07 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1/160 La commune Nombre d'établissements est Réseaux d'enseignement et de accessible d'infrastructure formation par Commune rurale Train Lycée Collège Autocar de développement ? Grand taxi Autre moyen Réseau d'électricité Réseau d'eau potable Ecole primaire satellite Ecole primaire centrale professionnelle publique Ecole coranique ou Msid Réseau d'assainissement La commune dispose-t-elle d'un plan Ecole primaire autonome Etablissement de formation 066. -

Télécharger Le Document
CARTOGRAPHIE DU DÉVELOPPEMENT LOCAL MULTIDIMENSIONNEL NIVEAU ET DÉFICITS www.ondh.ma SOMMAIRE Résumé 6 Présentation 7 1. Approche méthodologique 8 1.1. Portée et lecture de l’IDLM 8 1.2. Fiabilité de l’IDLM 9 2. Développement, niveaux et sources de déficit 10 2.1. Cartographie du développement régional 11 2.2. Cartographie du développement provincial 13 2.3. Développement communal, état de lieux et disparité 16 3. L’IDLM, un outil de ciblage des programmes sociaux 19 3.1 Causes du déficit en développement, l’éducation et le niveau de vie en tête 20 3.2. Profil des communes à développement local faible 24 Conclusion 26 Annexes 27 Annexe 1 : Fiabilité de l’indice de développement local multidimensionnel (IDLM) 29 Annexe 2 : Consistance et méthode de calcul de l’indice de développement local 30 multidimensionnel Annexe 3 : Cartographie des niveaux de développement local 35 Annexes Communal 38 Cartographie du développement communal-2014 41 5 RÉSUMÉ La résorption ciblée des déficits socio-économiques à l’échelle locale (province et commune) requiert, à l’instar de l’intégration et la cohésion des territoires, le recours à une cartographie du développement au sens multidimensionnel du terme, conjuguée à celle des causes structurelles de son éventuel retard. Cette étude livre à cet effet une cartographie communale du développement et de ses sources assimilées à l’éducation, la santé, le niveau de vie, l’activité économique, l’habitat et les services sociaux, à partir de la base de données «Indicateurs du RGPH 2014» (HCP, 2017). Cette cartographie du développement et de ses dimensions montre clairement que : - La pauvreté matérielle voire monétaire est certes associée au développement humain, mais elle ne permet pas, à elle seule, d’identifier les communes sous l’emprise d’autres facettes de pauvreté. -

Pris En Application Du Dahir Portant Loi N° 1-74-338 Du 24 Joumada II 1394 (15 Juillet 1974) Relatif À L’Organisation Judiciaire (B.O
Décret n° 2-74-498 (25 joumada II 1394) pris en application du dahir portant loi n° 1-74-338 du 24 joumada II 1394 (15 juillet 1974) relatif à l’organisation judiciaire (B.O. 17 juillet 1974) Décret n° 2-74-498 (25 joumada II 1394) pris en application du dahir portant loi n° 1-74-338 du 24 joumada II 1394 (15 juillet 1974) relatif à l’organisation judiciaire (B.O. 17 juillet 1974) Décret n° 2-74-498 (25 joumada II 1394) pris en application du dahir portant loi n° 1-74-338 du 24 joumada II 1394 (15 juillet 1974) relatif à l’organisation judiciaire Bulletin Officiel du 17 juillet 1974 Vu le dahir portant loi n° 1-74-338 du 24 joumada II 1394 (15 juillet 1974) fixant l’organisation judiciaire du Royaume ; Après examen par le Conseil des ministres réuni le 11 joumada II 1394 (2 juillet et 1974). Article Premier : L’organisation judiciaire comporte un certain nombre de juridictions dont le siège et le ressort sont fixés conformément au tableau annexé (1). Cours d’appel et tribunaux de première instance Tableau annexé au décret 2-74-498 tel qu’abrog. et rempl. par le n° 2-96-467 20 nov. 1996- 8 rejeb 1417 : BO 2 janv. 1997, p 3 tel que mod. par le décret 2-99-832 du 28 septembre 1999-17 joumada II 1420 ; par le Décret n° 2-00-732 du 2 novembre 2000 – 5 chaabane 1421- B.O du 16 novembre 2000 et par le décret n° 2-02-6 du 17 juillet 2002-6 joumada I 1423 (B.O du 15 août 2002, décret n° 2-03-884 du 4 mai 2004 – 14 rabii I 1425 ; B.O. -

06. Presentation Aclimas.Pdf
Adaptation to Climate Change of the Mediterranean Agricultural Systems ACLIMAS www.aclimas.eu SWIM (Sustainable Water Integrated Management) - Demonstration Project – Water and Climate Change "European Neighborhood and Partnership (ENP) financial co-operation with Mediterranean countries" Funded by Implemented by Mladen Todorović, CIHEAM-IAMB 4th SWIM-SM Steering Committee and SWIM Demos Coordination Meeting, Barcelona - Spain, 15-16 December 2014 OVERALL OBJECTIVE: to bring a durable improvement in the agricultural water management and a broader socio-economic development in target areas in the context of adaptation to climate change, increasing water scarcity, and desertification risk. TARGET AREAS AND CROPS Aleppo Plateau, Syria Khmese Melanah (wheat, (Wilaya of Ain Defla), barley) Algeria (wheat, barley) Bekaa Valley, Lebanon Chaouia Ourdigha , Northern Tunisia, (wheat, Morocco Tunisia barley) (wheat, barley, (wheat, barley, chickpea, lentil, chickpea, forage legume) faba bean ) Irbid, Country Region Name of the target areas Jordan Morocco Chaouia Ourdigha Oulad Said, Sidi El Aidi, Tamadroust, Berrechid, (wheat, Ain Nzagh, Sidi Mohamed Ben Rahal West Nubaria, barley, Tunisia North-Eastern Tunisia, Capbon, Manouba, Saida, Mhamedia, Grombalia, Egypt legumes) South-Eastern Tunisia Médenine Governorate (chick pea, Egypt Western Nubaria Entelak, Tiba faba bean) Jordan Irbid Governorate Bani Kananeh, Bani Obaid, Quasbat Irbid, Al-Ramtha Lebanon Bekaa Valley El Hermel, Baalbeck, Zahle, West Bekaa Algeria Wilaya of Ain Defla Khmese Melanah -

Presentación De Powerpoint
Marrakech, 1 December 2015 Aclimas achievements Demonstration and implementation trials COMPARATIVE PERFORMANCE OF WHEAT AND ALTERNATIVE CROPS IN MEDITERRANEAN AGRICULTURAL SYSTEMS Nicolas Gualano, Roxana Savin, Hassan Ouabbou, Gustavo A. Slafer Morocco Introduction Likely Rainfed dominated by < sustainability Mediterranean Cereals (wheat < soil fertility agricultural systems and barley) in > pests pressure monoculture < water & nutrient use efficiency Alternative crops < yield performance than Food legumes & Canola cereals · Farmers are reluctant to include them in crop rotation. · Area grown with these crops in the region is still very small. Crops rotation (traditional cereals & alternative crops) Morocco Location: Chaouia Ourdigha region, Central Morocco (31°15’N, 07°30’W). Morocco Morocco First growing season (2012-2013): Comparison of wheat with alternative crops Three durum wheat varieties (Carioca, Marzak, Vitrico), canola, and food legumes (lentil, chickpea, and vicia) grown at Sidi el Aidi experimental station and farmer’s fields (some species) at ‘high’ N fertilization rate (150 kgN ha-1 of total soil N availability). Rainfed conditions. Second growing season (2013-2014): Effect of the preceding crop on wheat performance Same 3 durum wheat varieties cropped at Sidi el Aidi experimental station, and farmer’s fields, over all different previous crops (including themselves) and under two contrasting N fertilization rates (50 and 174 kgN ha-1 of total soil N availability). Rainfed conditions. ACLIMAS Morocco 2012-2013 Season Morocco Genotype Site Crop species cultivar Experimental design Demonstration Sidi el Aidi Durum wheat Carioca Rainfed. Large field plots Trial experimental (Triticum durum L.) Marzak (20x45m), conducted under station Vitrico zero-tillage and following Canola (Brassica napus L.) Seven typical agronomic management Lentil (Lens culinaris Bakria in the region. -

Brochure Dirasset Intl.Pdf
Groupe de bureaux d’études pluridisciplinaires Dirasset, Dirasset International, Dirasset Conseil 11, Rue Salah El Guermedi - Montfleury - 1008 unisT - Tunisie Téléphone : (216 71) 392 526 / 399 555 Fax : (216.71) 399 556 e-mail : dirasset.international @ gmail.com Tuni sie Site web : http://www.dirasset.com.tn Maroc Dirasset, Dirasset International, Dirasset Conseil constituent un • Industrie, technopoles : études d’opportunité de création de Groupe de bureaux d’études spécialisé dans les domainesAlgérie de zones industrielles, de zones franches, de technopôles l’économie et de l’aménagement (article 461 du code des sociétés • Décentralisation, gouvernance, institutions : appui à la décen- commerciales). Structures indépendantes de tout organisme public tralisation, à l’organisation des collectivités locales, études sur les Mauritanie ou privé, notre Groupe a été créé à partir de Mali1980. capacités et les attributions des collectivités régionales et locales Niger DOMAINES DE SPECIALISATION Tchad• Cartographie, SIG, Observatoires : élaboration de Systèmes Sénégal d’Information Géographique, plans-guide de villes, cartes routières • Aménagement du territoire : Schémas d’AménagementBurkina du Faso Guinée Guinée et touristiques, atlas, recueils cartographiques Territoire de pays, de régions,Bissau agglomérations, programmesBénin de Côte développement régional et de développementd’Ivoire rural intégré, NOS PARTENAIRES PROFESSIONNELS • Développement durable : études d’impact sur lesTogo milieux Cameroun Tout au long de son activité, notre -

Code Géographique Du Maroc
Région: OUED ED-DAHAB-LAGOUIRA |_0_|_1_| Province ou Cercle Commune ou Arrondissement Préfecture Libellé Code Libellé Code Libellé Code Lagouira (M) 066.01.03 Aghouinite 066.03.03 Aousserd 066.03.05 Aousserd 066 Aousserd 066.03 Tichla 066.03.07 Zoug 066.03.09 Bir Gandouz 066.05 Bir Gandouz 066.05.03 Dakhla (M) 391.01.01 Bir Anzarane 391.05.01 Gleibat El Foula 391.05.03 Oued-Ed- Bir Anzarane 391.05 391 Mijik 391.05.05 Dahab Oum Dreyga 391.05.07 El Argoub 391.09.01 El Argoub 391.09 Imlili 391.09.03 Région:LAAYOUNE-BOUJDOUR-SAKIA EL HAMRA |_0_|_2_| Province ou Cercle Commune ou Arrondissement Préfecture Libellé Code Libellé Code Libellé Code Boujdour (M) 121.01.01 Gueltat Zemmour 121.03.01 Boujdour 121 Jraifia 121.03 Jraifia 121.03.03 Lamssid 121.03.05 El Marsa (M) 321.01.01 Laayoune (M) 321.01.03 Tarfaya (M) 321.01.05 Boukraa 321.03.01 Laayoune 321.03 Dcheira 321.03.03 Laayoune 321 Foum El Oued 321.03.05 Akhfennir 321.05.01 Daoura 321.05.03 Tarfaya 321.05 El Hagounia 321.05.05 Tah 321.05.07 Région: GUELMIM-ES-SEMARA |_0_|_3_| Province ou Cercle Commune ou Arrondissement Préfecture Libellé Code Libellé Code Libellé Code Assa (M) 071.01.01 Zag (M) 071.01.03 Aouint Lahna 071.03.01 Assa-Zag 071 Assa 071.03 Aouint Yghomane 071.03.03 Touizgui 071.03.05 Al Mahbass 071.05.01 Zag 071.05 Labouirat 071.05.03 Es-semara (M) 221.01.01 Amgala 221.03.01 Haouza 221.03.03 Es-Semara 221 Es-Semara 221.03 Jdiriya 221.03.05 Sidi Ahmed Laarouss 221.03.07 Tifariti 221.03.09 Bouizakarne (M) 261.01.01 Guelmim (M) 261.01.03 Aday 261.03.01 Ait Boufoulen 261.03.03 Amtdi -

Pour Contreseing : Le Ministre De L'intérieur LE Chef Du
2 4 - 4 ) PORTANT " ROYAUME Du MAROC PROJET DE DECRET N ° ...... ......DU ...... ....( CREATION DE CERCLES ET DE CArDATS. MIN1STERE DE L'INTERIEUR LE Chef du Gouvernement, Vu le dahir n° 1-59-351 du ler joumada II 1379 (2 décembre 1959) relatif à la division administrative du Royaume, tel qu'il a été modifié et complété; Vu le décret n° 2-08-520 du 28 chaoual 1429 (28 octobre 2008) fixant la liste des cercles, des caïdats et des communes urbaines et rurales du Royaume ainsi que le nombre de conseillers à élire dans chaque commune, tel qu'il a été modifié et complété ; Sur proposition du ministre de l'intérieur ; Après délibération en Conseil du gouvernement, réuni le Pour contreseing : DECRETE : : La liste des cercles et des caïdats Le ministre de l'intérieur ARTICLE PREMIER annexée au décret susvisé n° 2-08-520 du 28 chaoual 1429 (28 octobre 2008) est modifiée conformément à la liste Signé : Mo HASSAD annexée au présent décret. ARTICLE 2: Le ministre de l'intérieur est chargé de l'exécution du présent décret qui sera publié au Bulletin officiel. Fait à Rabat, le Le Chef du Gouvernement Signé : ABDEL-ILAH BENKIRAN - 1 4 - 4 2 7 Liste modifiant la liste des cercles et des caklats annexée au décret n ° 2.08.520 du 28 chaoual 1429 (28 octobre 2008), tel qu'il a été modifié et complété Caïdats Communes Préfectures et Provinces . Cercles TINGHIR BOUMALNE - DADES TINGHIR TOUDGHA TAGI IZOUTE ALNIF ALNIF ALNIF M'SSICI H'SSYIA I-I'SSYIA ASSOUL TAOUNATE KARIA BA MOIIAMED CHRAGA CHRAGA BNI RAMER BNI SNOUS- FECHTALA MOULAY ABDELKRIM BNI SNOUS MOULAY -

Swim-Aclimas Athens Mt.Pdf
Adaptation to Climate Change of the Mediterranean Agricultural Systems ACLIMAS SWIM (Sustainable Water Integrated Management) - Demonstration Project – Water and Climate Change "European Neighborhood and Partnership (ENP) financial co-operation with Mediterranean countries" Mladen Todorović, CIHEAM-IAMB +1 3d SWIM Coordination Meeting, Athens, 11 October 2013 OVERALL OBJECTIVE: to bring a durable improvement in the agricultural water management and a broader socio-economic development in target areas in the context of adaptation to climate change, increasing water scarcity, and desertification risk. TARGET AREAS AND CROPS Aleppo Plateau, Syria Khmese Melanah (wheat, (Wilaya of Ain Defla), barley) Algeria (wheat, barley) Bekaa Valley, Lebanon Chaouia Ourdigha , Northern Tunisia, (wheat, Morocco Tunisia barley) (wheat, barley, (wheat, barley, chickpea, lentil, chickpea, forage legume) faba bean ) Irbid, Country Region Name of the target areas Jordan Morocco Chaouia Ourdigha Oulad Said, Sidi El Aidi, Tamadroust, Berrechid, (wheat, Ain Nzagh, Sidi Mohamed Ben Rahal West Nubaria, barley, Tunisia North-Eastern Tunisia, Capbon, Manouba, Saida, Mhamedia, Grombalia, Egypt legumes) South-Eastern Tunisia Médenine Governorate (chick pea, Egypt Western Nubaria Entelak, Tiba faba bean) Jordan Irbid Governorate Bani Kananeh, Bani Obaid, Quasbat Irbid, Al-Ramtha Lebanon Bekaa Valley El Hermel, Baalbeck, Zahle, West Bekaa Algeria Wilaya of Ain Defla Khmese Melanah Specific Objectives • To improve the initial conditions (local offices, stations, and demonstration