Intonation Systems of Mandarin and English
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Perceptions of Different Accent
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Hana Richterová Perceptions of Different Accents of English Bachelor ’s Diploma Thesis Supervisor: PhDr. Kate řina Tomková, Ph. D. 2013 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to thank all of my American respondents who took the time and effort to take part in my research, and all of those who helped me contact them via Facebook, especially Karolina Schmid. My greatest thanks go to Mrs. Kate řina Tomková for her continuous support, willingness and inspirational remarks, which were at the very root of this thesis outline. Table of Contents 1. Introduction ................................................................................................................... 1 2. Theory ........................................................................................................................... 5 2.1 The definition of accent .......................................................................................... 5 2.2 Development of accents of English......................................................................... 6 2.3 Differences between British and American accents ................................................ 8 2.3.1 The separation of the accents ........................................................................... 8 2.3.2 Pronunciation differences .............................................................................. -

The Ideology of American English As Standard English in Taiwan
Arab World English Journal (AWEJ) Volume.7 Number.4 December, 2016 Pp. 80 - 96 The Ideology of American English as Standard English in Taiwan Jackie Chang English Department, National Pingtung University Pingtung City, Taiwan Abstract English language teaching and learning in Taiwan usually refers to American English teaching and learning. Taiwan views American English as Standard English. This is a strictly perceptual and ideological issue, as attested in the language school promotional materials that comprise the research data. Critical Discourse Analysis (CDA) was employed to analyze data drawn from language school promotional materials. The results indicate that American English as Standard English (AESE) ideology is prevalent in Taiwan. American English is viewed as correct, superior and the proper English language version for Taiwanese people to compete globally. As a result, Taiwanese English language learners regard native English speakers with an American accent as having the greatest prestige and as model teachers deserving emulation. This ideology has resulted in racial and linguistic inequalities in contemporary Taiwanese society. AESE gives Taiwanese learners a restricted knowledge of English and its underlying culture. It is apparent that many Taiwanese people need tore-examine their taken-for-granted beliefs about AESE. Keywords: American English as Standard English (AESE),Critical Discourse Analysis (CDA), ideology, inequalities 80 Arab World English Journal (AWEJ) Vol.7. No. 4 December 2016 The Ideology of American English as Standard English in Taiwan Chang Introduction It is an undeniable fact that English has become the global lingua franca. However, as far as English teaching and learning are concerned, there is a prevailing belief that the world should be learning not just any English variety but rather what is termed Standard English. -
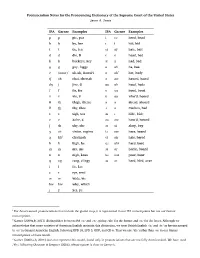
Pronunciation Notes (PDF)
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter. -

A Contrastive Study Between Rp and Ga Segmental Features
A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Submitted as one of the requirements for completing the Undergraduate Study Program at the English Education Department School of Teacher Training and Education By: AULIANISA NETASYA SALAM A320160022 DEPARTMENT OF ENGLISH EDUCATION SCHOOL OF TEACHER TRAINING AND EDUCATION MUHAMMADIYAH UNIVERSITY OF SURAKARTA 2020 A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Abstrak Penelitian ini merupakan penelitian kontrastif yang bertujuan untuk mendeskripsikan persamaan dan perbedaan ciri segmental RP dan GA. Penelitian ini menggunakan metode deskriptif-kualitatif dengan pengumpulan data dari video YouTube. Studi ini menemukan bahwa kesamaan antara bunyi segmental RP dan GA pada posisi awal, medial, dan akhir adalah [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [ d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. Bunyi serupa yang ditemukan di posisi awal dan medial adalah [ӕ], [tʃ], [dȝ], [ð], [h], [w], [j]; di posisi medial dan terakhir adalah [aɪ], [k], [ȝ], [ղ]; di posisi awal adalah [r] dan di posisi medial: [ʊ], [ʌ], [ɛ]. Kemudian perbedaan suara antara fitur segmental RP dan GA telah ditemukan pada posisi awal dan medial adalah [ͻ], [ɑ:]; pada posisi medial dan akhir adalah [ɪə], [əʊ], pada posisi awal [ʌ], [eə] sedangkan pada posisi medial adalah [ɒ], [i:], [u:], [ͻ:], [ ʊə], [t]. Kata kunci: penerima pengucapan, amerika umum, pengucapan, fonetis. Abstract This research is a contrastive study aimed to describe the similarities and the differences between RP and GA segmental features. This research used descriptive-qualitative method which collected the data from the YouTube video. The study found that the similarities between RP and GA segmental sounds in initial, medial, and final positions are [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. -

Interpreting Rising Intonation in Australian English
Interpreting rising intonation in Australian English Janet Fletcher, Deborah Loakes School of Languages and Linguistics, University of Melbourne [email protected], [email protected] Abstract some the rising tunes that are theoretically permissible within the ToBI system as applied to Australian English. It is loosely Australian English is referred to widely as a rising variety of based on a summary provided in [2]. This list can be further English due to the prevalence of rising tunes in interactive expanded to take into account downstepped !H* pitch accents discourse. Australian English subjects were required to listen or! H- phrase accents. Also included are the equivalent to a series of rising stimuli that varied in terms of pitch level English Tone categories adapted from Halliday’s [3] model of and pitch span and were asked whether they heard a question English intonation. or statement. The results showed that both rise span and pitch level of the rise elbow influenced the pattern of responses. If Table 1 Summary of rising contours, Halliday’s English both were relatively high, subjects were most likely to Tones, and ToBI annotation categories interpret the rise as a question, with fewer question responses when the rise elbow was relatively low and the pitch span High Low High/Mid- Fall- narrow. The results provide limited evidence for two simple Rise, Rise, level Rise, rises in Australian English, but also confirm a high level of Tone 2 Tone 3 Rise- phonetic gradience amongst rising tunes in this variety. Fall- Rise Index Terms: intonation, uptalk, phonetic gradience Tone 2 Tone 4 Rises with low or L*L- L*+H 1. -

The Phonological Study of the Speech of the Conchs, Early Inhabitants Of
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1965 The honologP ical Study of the Speech of the Conchs, Early Inhabitants of the Florida Keys, at Three Age Levels. Frank Kenneth La ban Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Recommended Citation La ban, Frank Kenneth, "The honoP logical Study of the Speech of the Conchs, Early Inhabitants of the Florida Keys, at Three Age Levels." (1965). LSU Historical Dissertations and Theses. 1043. https://digitalcommons.lsu.edu/gradschool_disstheses/1043 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. This dissertation has been 65-11,395 microfilmed exactly as received LA BAN, Frank Kenneth, 1930- A PHONOLOGICAL STUDY OF THE SPEECH OF THE CONCHS, EARLY INHABITANTS OF THE FLORIDA KEYS, AT THREE AGE LEVELS. Louisiana State University, Ph.D., 1965 Language and Literature, linguistics University Microfilms, Inc., Ann Arbor, Michigan A PHONOLOGICAL STUDY OF THE SPEECH OF THE CONCHS, EARLY INHABITANTS OF THE FLORIDA KEYS, AT THREE AGE LEVELS A Dissertation Submitted to the Graduate faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Speech bY v ' Frank KpLa Ban B.A., University of Kansas, 1955 M.A., University of Kansas, 1959 May, 1965 ACKNOWLEDGMENT I should like to express my sincere appreciation to Dr. -

English As Native Language). B/ ESL (English As Second Language
Introduction 1. Key concepts in the description of English. a/ ENL (English as Native Language). b/ ESL (English as Second Language). c/ EFL (English as Foreign Language). d/ EIL (English as International Language). e/ ELF (English as Lingua Franca). Standard English 1. Standard language: the norm and the prestige variety spoken by those in power; codified in grammar books and dictionaries; used in government, law, education, science, and literature. 2.Inferior social status is reflected by the inferior variety of language used. 3. Prescriptive language rules and the role of change. Broadening the standard? 4. Standard English: a variety spoken by the educated in London; accent not involved in it, but only grammar and vocabulary; a variety taught to EFL students. 5. Standard English: not a style or register, but a social dialect. a/ Father was exceedingly fatigued subsequent to his extensive peregrinations. b/ Dad was very tired after his lengthy journey. c/ The old man was bloody knackered after his long trip. 6. New Englishes, e.g. American or Australian English: standard or non-standard? 7. Non-standard varieties of British English: regional dialects and rural dialects, e.g. Estuary English, Brummie, Cockney, Geordie, Scouse, London Jamaican, etc. 8. Non-standard American English: speech of Southerners, New Yorkers, African Americans, Mexican Americans, etc. 9. Find the non-standard part of each of the American English sentences below and rewrite it as standard. They play their stereo softer anymore. For a time, things looked badly, but they are better now. Somebody rung the doorbell. They put dynamite in the old hotel and blowed it up. -

American Regional Dialects - an Overview
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OTHES 'Y'ALL COME BACK NOW, Y'HEAR!?' LANGUAGE ATTITUDES IN THE UNITED STATES TOWARDS SOUTHERN AMERICAN ENGLISH DIPLOMARBEIT ZUR ERLANGUNG DES MAGISTERTITELS DER PHILOSOPHIE EINGEREICHT AN DER GEISTESWISSENSCHAFTLICHEN FAKULTÄT DER UNIVERSITÄT WIEN VON BARBARA SOUKUP BETREUER: PROF. HERBERT SCHENDL WIEN, IM MAI 2000 2 TABLE OF CONTENTS PREFACE ............................................................................................................................. 4 INTRODUCTION ................................................................................................................... 6 PART I: FRAMEWORKS ........................................................................................................ 7 1. CONTEXTUAL FRAMEWORK: LANGUAGE VARIATION IN THE USA ................................. 8 1.1. American Regional Dialects - an Overview ........................................................... 8 1.2. Southern American English ................................................................................. 20 1.2.1. General Features ............................................................................................ 20 1.2.2. 'East Tennessee Talk' ..................................................................................... 27 1.3. 'Standard American English' ................................................................................ 32 2. THEORETICAL FRAMEWORK: LANGUAGE ATTITUDES .................................................. -

First Language Phonetic Drift During Second Language Acquisition By
First Language Phonetic Drift During Second Language Acquisition by Charles Bond Chang A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Keith Johnson, Chair Professor Susanne Gahl Professor Sharon Inkelas Professor Carla Hudson Kam Fall 2010 First Language Phonetic Drift During Second Language Acquisition ⃝c 2010 by Charles Bond Chang 1 Abstract First Language Phonetic Drift During Second Language Acquisition by Charles Bond Chang Doctor of Philosophy in Linguistics University of California, Berkeley Professor Keith Johnson, Chair Despite abundant evidence of malleability in speech production, previous studies of the effects of late second-language learning on first-language production have been limited to advanced learners. This dissertation examines these effects in novice learn- ers, finding that experience in a second language rapidly, and possibly inexorably, af- fects production of the native language. In a longitudinal study of Korean acquisition, native English-speaking adult learners (n = 19) produced the same English words at weekly intervals over the course of intensive elementary Korean classes. Results of two acoustic case studies indicate that experience with Korean rapidly influences the production of English, and that the effect is one of assimilation to phonetic properties of Korean. In case study 1, experience with Korean stop types is found to influence the production of English stop types in terms of voice onset time (VOT) and/or fundamental frequency (f0) onset as early as the second week of Korean classes, re- sulting in the lengthening of VOT in English voiceless stops (in approximation to the longer VOT of the perceptually similar Korean aspirated stops) and the raising of f0 onset following English voiced and voiceless stops (in approximation to the higher f0 levels of Korean). -

Regional Variation in Fundamental Frequency of American English Vowels
Original Paper Phonetica 2018;75:273–309 Received: December 12, 2016 DOI: 10.1159/000484610 Accepted after revision: October 4, 2017 Published online: April 11, 2018 Regional Variation in Fundamental Frequency of American English Vowels Ewa Jacewicz Robert Allen Fox Department of Speech and Hearing Science, Ohio State University, Columbus, OH, USA Abstract We examined whether the fundamental frequency (f0) of vowels is influenced by regional variation, aiming to (1) establish how the relationship between vowel height and f0 (“intrinsic f0”) is utilized in regional vowel systems and (2) deter- mine whether regional varieties differ in their implementation of the effects of phonetic context on f0 variations. An extended set of acoustic measures explored f0 in vowels in isolated tokens (experiment 1) and in connected speech (experi- ment 2) from 36 women representing 3 different varieties of American English. Regional differences were found in f0 shape in isolated tokens, in the magnitude of intrinsic f0 difference between high and low vowels, in the nature of f0 contours in stressed vowels, and in the completion of f0 contours in the context of coda voicing. Regional varieties utilize f0 control in vowels in different ways, including regional f0 ranges and variation in f0 shape. © 2018 S. Karger AG, Basel Introduction Acoustic characteristics of American English vowels have been studied sys- tematically since Peterson and Barney (1952), with formant patterns and spectral dynamics being the primary focus of investigation (e.g., Fox and Jacewicz, -

A Dialogue Act Analysis of Rises in Australian English Map Task Dialogues
A Dialogue Act Analysis of Rises in Australian English Map Task Dialogues Janet Fletcher, Roger Wales*, Lesley Stirling, & Ilana Mushin** Department of Linguistics and Applied Linguistics, University of Melbourne * Faculty of Humanities and Social Sciences, La Trobe University **Department of Linguistics, University of Sydney [email protected] true high rise, which starts relatively high in a speaker s Abstract range and continues to rise to the end of the intonational Uptalk or rising intonation is a distinctive feature of phrase, is functionally and phonetically different from the Australian English. The distribution and discourse high rise which starts relatively low in a speaker s range functions of simple and complex rising tunes were and rises to a level comparable to the true high rise. The examined in a corpus of Australian English map task first variant is associated with yes/no questions whereas dialogues. Dialogue acts (classified using DAMSL) the second variant is realized with statements. Figure 1 corresponding to information requests were consistently shows a schematized representation of these two rises. realized as high-onset high rises whereas low-onset high Complex rises in Australian English may also rises corresponded to a wider range of forward-looking represent another potential source of dialectal difference communicative functions, such as statements and action with SSBE or General American English. Impressionistic directives, but were rarely associated with information analysis suggests that fall-rise tunes have at least two requests. Two kinds of fall-rise tunes were also observed: variants in Australian English. These two variants are low-range and high-range fall-rise. -

A Phonetic Analysis of the English Spoken by Mexican Children in the Elementary Schools of Arizona
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1940 A Phonetic Analysis of the English Spoken by Mexican Children in the Elementary Schools of Arizona. Klonda Lynn Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Part of the Speech and Rhetorical Studies Commons Recommended Citation Lynn, Klonda, "A Phonetic Analysis of the English Spoken by Mexican Children in the Elementary Schools of Arizona." (1940). LSU Historical Dissertations and Theses. 7832. https://digitalcommons.lsu.edu/gradschool_disstheses/7832 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. MANUSCRIPT THESES Unpublished theses submitted for the master’s and doctor’s degrees and deposited in the Louisiana State University Library are available for inspection* Use of any thesis is limited by the rights of the author* Bibliographical references may be noted, but passage^ may not be copied unless the author has given permission# Credit must be given in subsequent written or published work# A library which borrows this thesis for use by its clientele l®t|tideted to make sure that the borrower is aware of the above LOUISIANA. STATE UNIVERSITY LIBRARY A PHONETIC ANALYSIS OF THE ENGLISH spoken by Mexican children in THE ELEMENTARY SCHOOLS OF ARIZONA A Thesis Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Speech *>y Klonda Lynn B.A., North Dakota, 1920.