Accents on Trial Accent Discrimination in U.K
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Perceptions of Different Accent
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Hana Richterová Perceptions of Different Accents of English Bachelor ’s Diploma Thesis Supervisor: PhDr. Kate řina Tomková, Ph. D. 2013 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to thank all of my American respondents who took the time and effort to take part in my research, and all of those who helped me contact them via Facebook, especially Karolina Schmid. My greatest thanks go to Mrs. Kate řina Tomková for her continuous support, willingness and inspirational remarks, which were at the very root of this thesis outline. Table of Contents 1. Introduction ................................................................................................................... 1 2. Theory ........................................................................................................................... 5 2.1 The definition of accent .......................................................................................... 5 2.2 Development of accents of English......................................................................... 6 2.3 Differences between British and American accents ................................................ 8 2.3.1 The separation of the accents ........................................................................... 8 2.3.2 Pronunciation differences .............................................................................. -

The Ideology of American English As Standard English in Taiwan
Arab World English Journal (AWEJ) Volume.7 Number.4 December, 2016 Pp. 80 - 96 The Ideology of American English as Standard English in Taiwan Jackie Chang English Department, National Pingtung University Pingtung City, Taiwan Abstract English language teaching and learning in Taiwan usually refers to American English teaching and learning. Taiwan views American English as Standard English. This is a strictly perceptual and ideological issue, as attested in the language school promotional materials that comprise the research data. Critical Discourse Analysis (CDA) was employed to analyze data drawn from language school promotional materials. The results indicate that American English as Standard English (AESE) ideology is prevalent in Taiwan. American English is viewed as correct, superior and the proper English language version for Taiwanese people to compete globally. As a result, Taiwanese English language learners regard native English speakers with an American accent as having the greatest prestige and as model teachers deserving emulation. This ideology has resulted in racial and linguistic inequalities in contemporary Taiwanese society. AESE gives Taiwanese learners a restricted knowledge of English and its underlying culture. It is apparent that many Taiwanese people need tore-examine their taken-for-granted beliefs about AESE. Keywords: American English as Standard English (AESE),Critical Discourse Analysis (CDA), ideology, inequalities 80 Arab World English Journal (AWEJ) Vol.7. No. 4 December 2016 The Ideology of American English as Standard English in Taiwan Chang Introduction It is an undeniable fact that English has become the global lingua franca. However, as far as English teaching and learning are concerned, there is a prevailing belief that the world should be learning not just any English variety but rather what is termed Standard English. -

Broadcast and on Demand Bulletin Issue Number
Issue 332 of Ofcom’s Broadcast and On Demand Bulletin 3 July 2017 Issue number 332 3 July 2017 Issue 332 of Ofcom’s Broadcast and On Demand Bulletin 3 July 2017 Contents Introduction 3 Broadcast Standards cases In Breach Bumper 2 Bumper Drive Time Show Kemet Radio, 12 April 2017, 16:00 6 Videokolik TGRT EU, 20 February 2017, 13:30 8 The Reporter Tameside Radio, 4 May 2017, 19:00 10 Bollywood Bang Bang trail B4U Music, 16 March 2017, 17:25 12 Filmfare Awards SAB TV, 18 February 2017, 20:00 15 News item PTV Global, 26 February 2017, 15:00 19 Resolved The Wright Stuff Channel 5, 2 May 2017, 09:15 23 Trail for Top 10 Ariana Grande Tunes MTV, 23 May 2017, 09:40 and 10:13 25 Advertising scheduling cases In Breach Advertising minutage Takbeer TV, 8 February 2017, 18:00 27 Broadcast Licence Conditions cases In Breach Providing a service in accordance with ‘Key Commitments’ Cross Rhythms Teesside, 26 to 28 March 2017 29 Providing a service in accordance with ‘Key Commitments’ SFM, 5 April to 24 April 2017 31 Issue 332 of Ofcom’s Broadcast and On Demand Bulletin 3 July 2017 Provision of information Channel i, 2 December 2016 33 Broadcasting licensees’ late payment of licence fees Various licensees 34 Provision of information: community radio finance reports Various community radio licensees, year ending 31 December 2016 35 Broadcast Fairness and Privacy cases Not Upheld Complaint by The RAC Group Limited Watchdog, BBC1, 16 and 30 November 2016 37 Complaint by Mr Adam Heatherington Channel 4 News, Channel 4, 20 February 2017 57 Tables of cases Investigations Not in Breach 62 Complaints assessed, not investigated 63 Complaints outside of remit 72 Complaints about the BBC, not assessed 73 Investigations List 76 Issue 332 of Ofcom’s Broadcast and On Demand Bulletin 3 July 2017 Introduction Under the Communications Act 2003 (“the Act”), Ofcom has a duty to set standards for broadcast content to secure the standards objectives1. -
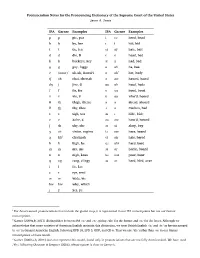
Pronunciation Notes (PDF)
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter. -

A Contrastive Study Between Rp and Ga Segmental Features
A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Submitted as one of the requirements for completing the Undergraduate Study Program at the English Education Department School of Teacher Training and Education By: AULIANISA NETASYA SALAM A320160022 DEPARTMENT OF ENGLISH EDUCATION SCHOOL OF TEACHER TRAINING AND EDUCATION MUHAMMADIYAH UNIVERSITY OF SURAKARTA 2020 A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Abstrak Penelitian ini merupakan penelitian kontrastif yang bertujuan untuk mendeskripsikan persamaan dan perbedaan ciri segmental RP dan GA. Penelitian ini menggunakan metode deskriptif-kualitatif dengan pengumpulan data dari video YouTube. Studi ini menemukan bahwa kesamaan antara bunyi segmental RP dan GA pada posisi awal, medial, dan akhir adalah [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [ d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. Bunyi serupa yang ditemukan di posisi awal dan medial adalah [ӕ], [tʃ], [dȝ], [ð], [h], [w], [j]; di posisi medial dan terakhir adalah [aɪ], [k], [ȝ], [ղ]; di posisi awal adalah [r] dan di posisi medial: [ʊ], [ʌ], [ɛ]. Kemudian perbedaan suara antara fitur segmental RP dan GA telah ditemukan pada posisi awal dan medial adalah [ͻ], [ɑ:]; pada posisi medial dan akhir adalah [ɪə], [əʊ], pada posisi awal [ʌ], [eə] sedangkan pada posisi medial adalah [ɒ], [i:], [u:], [ͻ:], [ ʊə], [t]. Kata kunci: penerima pengucapan, amerika umum, pengucapan, fonetis. Abstract This research is a contrastive study aimed to describe the similarities and the differences between RP and GA segmental features. This research used descriptive-qualitative method which collected the data from the YouTube video. The study found that the similarities between RP and GA segmental sounds in initial, medial, and final positions are [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. -

Interpreting Rising Intonation in Australian English
Interpreting rising intonation in Australian English Janet Fletcher, Deborah Loakes School of Languages and Linguistics, University of Melbourne [email protected], [email protected] Abstract some the rising tunes that are theoretically permissible within the ToBI system as applied to Australian English. It is loosely Australian English is referred to widely as a rising variety of based on a summary provided in [2]. This list can be further English due to the prevalence of rising tunes in interactive expanded to take into account downstepped !H* pitch accents discourse. Australian English subjects were required to listen or! H- phrase accents. Also included are the equivalent to a series of rising stimuli that varied in terms of pitch level English Tone categories adapted from Halliday’s [3] model of and pitch span and were asked whether they heard a question English intonation. or statement. The results showed that both rise span and pitch level of the rise elbow influenced the pattern of responses. If Table 1 Summary of rising contours, Halliday’s English both were relatively high, subjects were most likely to Tones, and ToBI annotation categories interpret the rise as a question, with fewer question responses when the rise elbow was relatively low and the pitch span High Low High/Mid- Fall- narrow. The results provide limited evidence for two simple Rise, Rise, level Rise, rises in Australian English, but also confirm a high level of Tone 2 Tone 3 Rise- phonetic gradience amongst rising tunes in this variety. Fall- Rise Index Terms: intonation, uptalk, phonetic gradience Tone 2 Tone 4 Rises with low or L*L- L*+H 1. -

Nima Elbagir: Life on the Frontline Size Matters a Provocative Look at Short-Form Content
June 2016 Nima Elbagir: Life on the frontline Size matters A provocative look at short-form content Pat Younge CEO, Sugar Films (Chair) Randel Bryan Director of Content and Strategy UK, Endemol Shine Beyond UK Adam Gee Commissioning Editor, Multi-platform and Online Video (Factual), Channel 4 Max Gogarty Daily Content Editor, BBC Three Kelly Sweeney Director of Production/Studios, Maker Studios International Andy Taylor CEO, Little Dot Studios Steve Wheen CEO, The Distillery 4 July The Hospital Club, 24 Endell Street, London WC2H 9HQ Booking: www.rts.org.uk Journal of The Royal Television Society June 2016 l Volume 53/6 From the CEO The third annual RTS/ surroundings of the Oran Mor audito- Mockridge, CEO of Virgin Media; Cathy IET Joint Public Lec- rium in Glasgow. Congratulations to Newman, Presenter of Channel 4 News; ture, held in the all the winners. and Sharon White, CEO of Ofcom. unmatched surround- Back in London, RTS Futures held Steve Burke, CEO of NBCUniversal, ings of London’s Brit- an intimate workshop in the board- will deliver the opening keynote. ish Museum, was a room here at Dorset Rise: 14 industry An early-bird rate is available for night to remember. I newbies were treated to tips on how those of you who book a place before was thrilled to see such a big turnout. to secure work in the TV sector. June 30 – just go to the RTS website: Nobel laureate Sir Paul Nurse gave a Bookings are now open for the RTS’s rts.org.uk/event/rts-london-conference-2016. -

The Phonological Study of the Speech of the Conchs, Early Inhabitants Of
Louisiana State University LSU Digital Commons LSU Historical Dissertations and Theses Graduate School 1965 The honologP ical Study of the Speech of the Conchs, Early Inhabitants of the Florida Keys, at Three Age Levels. Frank Kenneth La ban Louisiana State University and Agricultural & Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_disstheses Recommended Citation La ban, Frank Kenneth, "The honoP logical Study of the Speech of the Conchs, Early Inhabitants of the Florida Keys, at Three Age Levels." (1965). LSU Historical Dissertations and Theses. 1043. https://digitalcommons.lsu.edu/gradschool_disstheses/1043 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Historical Dissertations and Theses by an authorized administrator of LSU Digital Commons. For more information, please contact [email protected]. This dissertation has been 65-11,395 microfilmed exactly as received LA BAN, Frank Kenneth, 1930- A PHONOLOGICAL STUDY OF THE SPEECH OF THE CONCHS, EARLY INHABITANTS OF THE FLORIDA KEYS, AT THREE AGE LEVELS. Louisiana State University, Ph.D., 1965 Language and Literature, linguistics University Microfilms, Inc., Ann Arbor, Michigan A PHONOLOGICAL STUDY OF THE SPEECH OF THE CONCHS, EARLY INHABITANTS OF THE FLORIDA KEYS, AT THREE AGE LEVELS A Dissertation Submitted to the Graduate faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Speech bY v ' Frank KpLa Ban B.A., University of Kansas, 1955 M.A., University of Kansas, 1959 May, 1965 ACKNOWLEDGMENT I should like to express my sincere appreciation to Dr. -

5G TV's Game Changer?
April 2019 5G TV’s game changer? NEMI - POP NEMI (POP - UK) NEMI (POP - UK) MARK PETRIE - ORCHESTRAL MARK - ORCHESTRAL PETRIE FIND YOUR SOUND Discover high-quality, original music from renowned composers, respected singer-songwriters and successful commercial musicians. AVAILABLE FOR LICENCE AT AUDIONETWORK.COM CONTACT US TO FIND OUT MORE Rebecca Hodges [email protected] +44 (0)207 566 1441 NUTTY P - GRIME MAXIMUM IMPACT - EPIC ORCHESTRAL NEMI (POP - UK) NEMI (POP - UK) 0285-RTS-TelevisionMagAd-A4-3mmBleed.indd 7 18/02/2019 15:09 Journal of The Royal Television Society April 2019 l Volume 56/4 From the CEO It’s been an especially to all the jurors for their hard work. story of mobile media technology. stimulating few weeks I was fortunate to attend the Cardiff Also inside, Anne Dawson, the Soci- at the Society. The Creative Cities Convention, where ety’s bursaries administrator, provides glamorous RTS RTS Wales curated a terrific session in a revealing portrait of the experience Programme Awards which Kirsty Wark interviewed ITV of being a mentor and mentee. This is ceremony was an Studios’ Julian Bellamy. He delivered a an inspirational read. amazing occasion. resounding message about how much Last, but not least, I’d like thank the We had star power in abundance and creativity we are blessed with in our indefatigable Charles Byrne for his 29 well-deserved winners (full details nations and regions. achievements over two decades as are in this issue). I am delighted that we have in this Chair of RTS Republic of Ireland. There are so many people to thank issue both a report from the conven- Sadly, Charles is standing down. -

Whole Day Download the Hansard Record of the Entire Day in PDF Format. PDF File, 0.98
Thursday Volume 624 30 March 2017 No. 135 HOUSE OF COMMONS OFFICIAL REPORT PARLIAMENTARY DEBATES (HANSARD) Thursday 30 March 2017 © Parliamentary Copyright House of Commons 2017 This publication may be reproduced under the terms of the Open Parliament licence, which is published at www.parliament.uk/site-information/copyright/. 379 30 MARCH 2017 380 Sir Desmond Swayne (New Forest West) (Con): How House of Commons important is it to make arrangements for the worst-case scenario, just to show how serious our negotiating Thursday 30 March 2017 intent is? Chris Grayling: My right hon. Friend will not be The House met at half-past Nine o’clock surprised to learn that the Government of course take steps to prepare for all eventualities, but we enter the negotiations with good faith and the intention to secure PRAYERS a deal, because we believe very strongly that that is in everybody’s interests, both here in the United Kingdom [MR SPEAKER in the Chair] and across the European Union. Tom Brake (Carshalton and Wallington) (LD): Will BUSINESS BEFORE QUESTIONS the Secretary of State confirm that the worst-case scenario is no arrangement at all, that airlines have to schedule ELECTORAL COMMISSION 12 to 18 months in advance, and that he therefore has to resolve the issue within the next six months? The VICE-CHAMBERLAIN OF THE HOUSEHOLD reported to the House, That the Address of 13th March, praying Chris Grayling: I never speculate on these things, but that Her Majesty will appoint Professor Elan Closs I have had detailed discussions with the aviation industry Stephens as an Electoral Commissioner with effect from over the past few weeks. -

English As Native Language). B/ ESL (English As Second Language
Introduction 1. Key concepts in the description of English. a/ ENL (English as Native Language). b/ ESL (English as Second Language). c/ EFL (English as Foreign Language). d/ EIL (English as International Language). e/ ELF (English as Lingua Franca). Standard English 1. Standard language: the norm and the prestige variety spoken by those in power; codified in grammar books and dictionaries; used in government, law, education, science, and literature. 2.Inferior social status is reflected by the inferior variety of language used. 3. Prescriptive language rules and the role of change. Broadening the standard? 4. Standard English: a variety spoken by the educated in London; accent not involved in it, but only grammar and vocabulary; a variety taught to EFL students. 5. Standard English: not a style or register, but a social dialect. a/ Father was exceedingly fatigued subsequent to his extensive peregrinations. b/ Dad was very tired after his lengthy journey. c/ The old man was bloody knackered after his long trip. 6. New Englishes, e.g. American or Australian English: standard or non-standard? 7. Non-standard varieties of British English: regional dialects and rural dialects, e.g. Estuary English, Brummie, Cockney, Geordie, Scouse, London Jamaican, etc. 8. Non-standard American English: speech of Southerners, New Yorkers, African Americans, Mexican Americans, etc. 9. Find the non-standard part of each of the American English sentences below and rewrite it as standard. They play their stereo softer anymore. For a time, things looked badly, but they are better now. Somebody rung the doorbell. They put dynamite in the old hotel and blowed it up. -

American Regional Dialects - an Overview
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OTHES 'Y'ALL COME BACK NOW, Y'HEAR!?' LANGUAGE ATTITUDES IN THE UNITED STATES TOWARDS SOUTHERN AMERICAN ENGLISH DIPLOMARBEIT ZUR ERLANGUNG DES MAGISTERTITELS DER PHILOSOPHIE EINGEREICHT AN DER GEISTESWISSENSCHAFTLICHEN FAKULTÄT DER UNIVERSITÄT WIEN VON BARBARA SOUKUP BETREUER: PROF. HERBERT SCHENDL WIEN, IM MAI 2000 2 TABLE OF CONTENTS PREFACE ............................................................................................................................. 4 INTRODUCTION ................................................................................................................... 6 PART I: FRAMEWORKS ........................................................................................................ 7 1. CONTEXTUAL FRAMEWORK: LANGUAGE VARIATION IN THE USA ................................. 8 1.1. American Regional Dialects - an Overview ........................................................... 8 1.2. Southern American English ................................................................................. 20 1.2.1. General Features ............................................................................................ 20 1.2.2. 'East Tennessee Talk' ..................................................................................... 27 1.3. 'Standard American English' ................................................................................ 32 2. THEORETICAL FRAMEWORK: LANGUAGE ATTITUDES ..................................................