First Language Phonetic Drift During Second Language Acquisition By
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Manual for Language Test Development and Examining
Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe © Council of Europe, April 2011 The opinions expressed in this work are those of the authors and do not necessarily reflect the official policy of the Council of Europe. All correspondence concerning this publication or the reproduction or translation of all or part of the document should be addressed to the Director of Education and Languages of the Council of Europe (Language Policy Division) (F-67075 Strasbourg Cedex or [email protected]). The reproduction of extracts is authorised, except for commercial purposes, on condition that the source is quoted. Manual for Language Test Development and Examining For use with the CEFR Produced by ALTE on behalf of the Language Policy Division, Council of Europe Language Policy Division Council of Europe (Strasbourg) www.coe.int/lang Contents Foreword 5 3.4.2 Piloting, pretesting and trialling 30 Introduction 6 3.4.3 Review of items 31 1 Fundamental considerations 10 3.5 Constructing tests 32 1.1 How to define language proficiency 10 3.6 Key questions 32 1.1.1 Models of language use and competence 10 3.7 Further reading 33 1.1.2 The CEFR model of language use 10 4 Delivering tests 34 1.1.3 Operationalising the model 12 4.1 Aims of delivering tests 34 1.1.4 The Common Reference Levels of the CEFR 12 4.2 The process of delivering tests 34 1.2 Validity 14 4.2.1 Arranging venues 34 1.2.1 What is validity? 14 4.2.2 Registering test takers 35 1.2.2 Validity -

Perceptions of Different Accent
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Hana Richterová Perceptions of Different Accents of English Bachelor ’s Diploma Thesis Supervisor: PhDr. Kate řina Tomková, Ph. D. 2013 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to thank all of my American respondents who took the time and effort to take part in my research, and all of those who helped me contact them via Facebook, especially Karolina Schmid. My greatest thanks go to Mrs. Kate řina Tomková for her continuous support, willingness and inspirational remarks, which were at the very root of this thesis outline. Table of Contents 1. Introduction ................................................................................................................... 1 2. Theory ........................................................................................................................... 5 2.1 The definition of accent .......................................................................................... 5 2.2 Development of accents of English......................................................................... 6 2.3 Differences between British and American accents ................................................ 8 2.3.1 The separation of the accents ........................................................................... 8 2.3.2 Pronunciation differences .............................................................................. -

Convergence and Divergence in Language Contact Situations
Sonderforschungsbereich Mehrsprachigkeit International Colloquium on Convergence and Divergence in Language Contact Situations 18–20 October 2007 University of Hamburg Research Centre on Multilingualism Welcome On behalf of our Research Centre on Multilingualism (Sonderforschungsbereich Mehrsprachigkeit), generously supported by the German Research Foundation (Deutsche Forschungsgemeinschaft) and the University of Hamburg, we would like to welcome you all here in Hamburg. This colloquium deals with issues related to convergence and divergence in language contact situations, issues which had been rather neglected in the past but have received much more attention in recent years. Five speakers from different countries have kindly accepted our invitation to share their expertise with us by presenting their research related to the theme of this colloquium. (One colleague from the US fell seriously ill and deeply regrets not being able to join us. Unfortunately, another invited speak- er cancelled his talk only two weeks ago.) All the other presentations are re- ports from ongoing work in the (now altogether 18) research projects in our centre. We hope that the three conference days will be informative and stimulating for all of us, and that the colloquium will be remembered for both its friendly atmosphere and its lively, controversial discussions. The organising commit- tee has done its best to ensure that this meeting with renowned colleagues from abroad will be a good place to make new friends or reinforce long-stand- ing professional contacts. There will be many opportunities for doing that – during the coffee breaks and especially during the conference dinner at an ex- cellent French restaurant on Thursday evening. -

Language Development Language Development
Language Development rom their very first cries, human beings communicate with the world around them. Infants communicate through sounds (crying and cooing) and through body lan- guage (pointing and other gestures). However, sometime between 8 and 18 months Fof age, a major developmental milestone occurs when infants begin to use words to speak. Words are symbolic representations; that is, when a child says “table,” we understand that the word represents the object. Language can be defined as a system of symbols that is used to communicate. Although language is used to communicate with others, we may also talk to ourselves and use words in our thinking. The words we use can influence the way we think about and understand our experiences. After defining some basic aspects of language that we use throughout the chapter, we describe some of the theories that are used to explain the amazing process by which we Language9 A system of understand and produce language. We then look at the brain’s role in processing and pro- symbols that is used to ducing language. After a description of the stages of language development—from a baby’s communicate with others or first cries through the slang used by teenagers—we look at the topic of bilingualism. We in our thinking. examine how learning to speak more than one language affects a child’s language develop- ment and how our educational system is trying to accommodate the increasing number of bilingual children in the classroom. Finally, we end the chapter with information about disorders that can interfere with children’s language development. -

Sports in French Culture
Sporting Frenchness: Nationality, Race, and Gender at Play by Rebecca W. Wines A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Romance Languages and Literatures: French) in the University of Michigan 2010 Doctoral Committee: Associate Professor Jarrod L. Hayes, Chair Professor Frieda Ekotto Professor Andrei S. Markovits Professor Peggy McCracken © Rebecca W. Wines 2010 Acknowledgements I would like to thank Jarrod Hayes, the chair of my committee, for his enthusiasm about my project, his suggestions for writing, and his careful editing; Peggy McCracken, for her ideas and attentive readings; the rest of my committee for their input; and the family, friends, and professors who have cheered me on both to and in this endeavor. Many, many thanks to my father, William A. Wines, for his unfailing belief in me, his support, and his exhortations to write. Yes, Dad, I ran for the roses! Thanks are also due to the Team Completion writing group—Christina Chang, Andrea Dewees, Sebastian Ferarri, and Vera Flaig—without whose assistance and constancy I could not have churned out these pages nor considerably revised them. Go Team! Finally, a thank you to all the coaches and teammates who stuck with me, pushed me physically and mentally, and befriended me over the years, both in soccer and in rugby. Thanks also to my fellow fans; and to the friends who I dragged to watch matches, thanks for your patience and smiles. ii Table of Contents Acknowledgements ii Abstract iv Introduction: Un coup de -

Modeling Language Variation and Universals: a Survey on Typological Linguistics for Natural Language Processing
Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing Edoardo Ponti, Helen O ’Horan, Yevgeni Berzak, Ivan Vulic, Roi Reichart, Thierry Poibeau, Ekaterina Shutova, Anna Korhonen To cite this version: Edoardo Ponti, Helen O ’Horan, Yevgeni Berzak, Ivan Vulic, Roi Reichart, et al.. Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing. 2018. hal-01856176 HAL Id: hal-01856176 https://hal.archives-ouvertes.fr/hal-01856176 Preprint submitted on 9 Aug 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing Edoardo Maria Ponti∗ Helen O’Horan∗∗ LTL, University of Cambridge LTL, University of Cambridge Yevgeni Berzaky Ivan Vuli´cz Department of Brain and Cognitive LTL, University of Cambridge Sciences, MIT Roi Reichart§ Thierry Poibeau# Faculty of Industrial Engineering and LATTICE Lab, CNRS and ENS/PSL and Management, Technion - IIT Univ. Sorbonne nouvelle/USPC Ekaterina Shutova** Anna Korhonenyy ILLC, University of Amsterdam LTL, University of Cambridge Understanding cross-lingual variation is essential for the development of effective multilingual natural language processing (NLP) applications. -

Landscapes of Korean and Korean American Biblical Interpretation
BIBLICAL INTERPRETATION AMERICAN AND KOREAN LANDSCAPES OF KOREAN International Voices in Biblical Studies In this first of its kind collection of Korean and Korean American Landscapes of Korean biblical interpretation, essays by established and emerging scholars reflect a range of historical, textual, feminist, sociological, theological, and postcolonial readings. Contributors draw upon ancient contexts and Korean American and even recent events in South Korea to shed light on familiar passages such as King Manasseh read through the Sewol Ferry Tragedy, David and Bathsheba’s narrative as the backdrop to the prohibition against Biblical Interpretation adultery, rereading the virtuous women in Proverbs 31:10–31 through a Korean woman’s experience, visualizing the Demilitarized Zone (DMZ) and demarcations in Galatians, and introducing the extrabiblical story of Eve and Norea, her daughter, through story (re)telling. This volume of essays introduces Korean and Korean American biblical interpretation to scholars and students interested in both traditional and contemporary contextual interpretations. Exile as Forced Migration JOHN AHN is AssociateThe Prophets Professor Speak of Hebrew on Forced Bible Migration at Howard University ThusSchool Says of Divinity.the LORD: He Essays is the on author the Former of and Latter Prophets in (2010) Honor ofand Robert coeditor R. Wilson of (2015) and (2009). Ahn Electronic open access edition (ISBN 978-0-88414-379-6) available at http://ivbs.sbl-site.org/home.aspx Edited by John Ahn LANDSCAPES OF KOREAN AND KOREAN AMERICAN BIBLICAL INTERPRETATION INTERNATIONAL VOICES IN BIBLICAL STUDIES Jione Havea Jin Young Choi Musa W. Dube David Joy Nasili Vaka’uta Gerald O. West Number 10 LANDSCAPES OF KOREAN AND KOREAN AMERICAN BIBLICAL INTERPRETATION Edited by John Ahn Atlanta Copyright © 2019 by SBL Press All rights reserved. -

The Ideology of American English As Standard English in Taiwan
Arab World English Journal (AWEJ) Volume.7 Number.4 December, 2016 Pp. 80 - 96 The Ideology of American English as Standard English in Taiwan Jackie Chang English Department, National Pingtung University Pingtung City, Taiwan Abstract English language teaching and learning in Taiwan usually refers to American English teaching and learning. Taiwan views American English as Standard English. This is a strictly perceptual and ideological issue, as attested in the language school promotional materials that comprise the research data. Critical Discourse Analysis (CDA) was employed to analyze data drawn from language school promotional materials. The results indicate that American English as Standard English (AESE) ideology is prevalent in Taiwan. American English is viewed as correct, superior and the proper English language version for Taiwanese people to compete globally. As a result, Taiwanese English language learners regard native English speakers with an American accent as having the greatest prestige and as model teachers deserving emulation. This ideology has resulted in racial and linguistic inequalities in contemporary Taiwanese society. AESE gives Taiwanese learners a restricted knowledge of English and its underlying culture. It is apparent that many Taiwanese people need tore-examine their taken-for-granted beliefs about AESE. Keywords: American English as Standard English (AESE),Critical Discourse Analysis (CDA), ideology, inequalities 80 Arab World English Journal (AWEJ) Vol.7. No. 4 December 2016 The Ideology of American English as Standard English in Taiwan Chang Introduction It is an undeniable fact that English has become the global lingua franca. However, as far as English teaching and learning are concerned, there is a prevailing belief that the world should be learning not just any English variety but rather what is termed Standard English. -

Essentials of Language Typology
Lívia Körtvélyessy Essentials of Language Typology KOŠICE 2017 © Lívia Körtvélyessy, Katedra anglistiky a amerikanistiky, Filozofická fakulta UPJŠ v Košiciach Recenzenti: Doc. PhDr. Edita Kominarecová, PhD. Doc. Slávka Tomaščíková, PhD. Elektronický vysokoškolský učebný text pre Filozofickú fakultu UPJŠ v Košiciach. Všetky práva vyhradené. Toto dielo ani jeho žiadnu časť nemožno reprodukovať,ukladať do informačných systémov alebo inak rozširovať bez súhlasu majiteľov práv. Za odbornú a jazykovú stánku tejto publikácie zodpovedá autor. Rukopis prešiel redakčnou a jazykovou úpravou. Jazyková úprava: Steve Pepper Vydavateľ: Univerzita Pavla Jozefa Šafárika v Košiciach Umiestnenie: http://unibook.upjs.sk Dostupné od: február 2017 ISBN: 978-80-8152-480-6 Table of Contents Table of Contents i List of Figures iv List of Tables v List of Abbreviations vi Preface vii CHAPTER 1 What is language typology? 1 Tasks 10 Summary 13 CHAPTER 2 The forerunners of language typology 14 Rasmus Rask (1787 - 1832) 14 Franz Bopp (1791 – 1867) 15 Jacob Grimm (1785 - 1863) 15 A.W. Schlegel (1767 - 1845) and F. W. Schlegel (1772 - 1829) 17 Wilhelm von Humboldt (1767 – 1835) 17 August Schleicher 18 Neogrammarians (Junggrammatiker) 19 The name for a new linguistic field 20 Tasks 21 Summary 22 CHAPTER 3 Genealogical classification of languages 23 Tasks 28 Summary 32 CHAPTER 4 Phonological typology 33 Consonants and vowels 34 Syllables 36 Prosodic features 36 Tasks 38 Summary 40 CHAPTER 5 Morphological typology 41 Morphological classification of languages (holistic -

Dative Overmarking in Basque: Evidence of Spanish-Basque Convergence
Dative Overmarking in Basque: Evidence of Spanish-Basque Convergence Jennifer Austin University of New Jersey, Rutgers. [email protected] Abstract This paper investigates a recent change in the grammar of spoken Basque which results in the substitution of dative case and agreement for absolutive case and agreement in marking animate, specific direct objects. I argue that this pattern of use is due to convergence between the feature matrix of the functional category AGR in Spanish and Basque. In contrast to previous studies which point to interface areas as the locus of syntactic convergence, I argue that this is a change affecting the core grammar of Basque. Furthermore, I suggest that the appearance of this case marking pattern in spoken Basque is probably attributable to recent changes in the demographics of Basque speakers and that its use is related to the degree of proficiency in each language of adult bilingual speakers. Laburpena Lan honetan euskara mintzatuaren gramatikan gertatu berri den aldaketa bat ikertzen da, hain zuzen ere, kasu datiboa eta aditz komunztaduraren ordezkapena kasu absolutiboa eta aditz komunztaduraren ordez objektu zuzenak --animatuak eta zehatzak—markatzen direnean. Nire iritziz, erabilera hori gazteleraz eta euskaraz dagoen AGR delako kategori funtzionalaren ezaugarri taulen bateratzeari zor zaio. Aurreko ikerketa batzuetan hizkuntza arteko ukipen eremuak bateratze sintaktikoaren gunetzat jotzen badira ere, nire iritziz aldaketa horrek euskararen gramatika oinarrizkoari eragiten dio. Areago, esango nuke kasu marka erabilera hori, ziurrenik, euskal hiztunen artean gertatu berri diren aldaketa demografikoen ondorioz agertzen dela euskara mintzatuan eta hiztun elebidun helduek hizkuntza bakoitzean daukaten gaitasun mailari lotuta dagoela. Keywods: Bilingualism, syntactic convergence, language contact. -

Exploring Material Culture Distributions in the Upper Sepik and Central New Guinea
Gender, mobility and population history: exploring material culture distributions in the Upper Sepik and Central New Guinea by Andrew Fyfe, BA (Hons) Thesis submitted for the Degree of Doctor of Philosophy in The Discipline of Geographical and Environmental Studies The University of Adelaide November 2008 …..These practices, then, and others which I will speak of later, were borrowed by the Greeks from Egypt. This is not the case, however, with the Greek custom of making images of Hermes with the phallus erect; it was the Athenians who took this from the Pelasgians, and from the Athenians the custom spread to the rest of Greece. For just at the time when the Athenians were assuming Hellenic nationality, the Pelasgians joined them, and thus first came to be regarded as Greeks. Anyone will know what I mean if he is familiar with the mysteries of the Cabiri-rites which the men of Samothrace learned from the Pelasgians, who lived in that island before they moved to Attica, and communicated the mysteries to the Athenians. This will show that the Athenians were the first Greeks to make statues of Hermes with the erect phallus, and that they learned the practice from the Pelasgians…… Herodotus c.430 BC ii Table of contents Acknowledgements vii List of figures viii List of tables xi List of Appendices xii Abstract xiv Declaration xvi Section One 1. Introduction 2 1.1 The Upper Sepik-Central New Guinea Project 2 1.2 Lapita and the exploration of relationships between language and culture in Melanesia 3 1.3 The quantification of relationships between material culture and language on New Guinea’s north coast 6 1.4 Thesis objectives 9 2. -
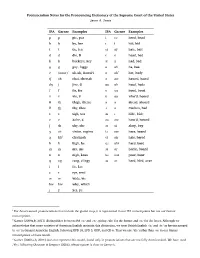
Pronunciation Notes (PDF)
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter.