Open-Source Multi-Speaker Corpora of the English Accents in the British
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Perceptions of Different Accent
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Hana Richterová Perceptions of Different Accents of English Bachelor ’s Diploma Thesis Supervisor: PhDr. Kate řina Tomková, Ph. D. 2013 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to thank all of my American respondents who took the time and effort to take part in my research, and all of those who helped me contact them via Facebook, especially Karolina Schmid. My greatest thanks go to Mrs. Kate řina Tomková for her continuous support, willingness and inspirational remarks, which were at the very root of this thesis outline. Table of Contents 1. Introduction ................................................................................................................... 1 2. Theory ........................................................................................................................... 5 2.1 The definition of accent .......................................................................................... 5 2.2 Development of accents of English......................................................................... 6 2.3 Differences between British and American accents ................................................ 8 2.3.1 The separation of the accents ........................................................................... 8 2.3.2 Pronunciation differences .............................................................................. -

Welsh Language Technology Action Plan Progress Report 2020 Welsh Language Technology Action Plan: Progress Report 2020
Welsh language technology action plan Progress report 2020 Welsh language technology action plan: Progress report 2020 Audience All those interested in ensuring that the Welsh language thrives digitally. Overview This report reviews progress with work packages of the Welsh Government’s Welsh language technology action plan between its October 2018 publication and the end of 2020. The Welsh language technology action plan derives from the Welsh Government’s strategy Cymraeg 2050: A million Welsh speakers (2017). Its aim is to plan technological developments to ensure that the Welsh language can be used in a wide variety of contexts, be that by using voice, keyboard or other means of human-computer interaction. Action required For information. Further information Enquiries about this document should be directed to: Welsh Language Division Welsh Government Cathays Park Cardiff CF10 3NQ e-mail: [email protected] @cymraeg Facebook/Cymraeg Additional copies This document can be accessed from gov.wales Related documents Prosperity for All: the national strategy (2017); Education in Wales: Our national mission, Action plan 2017–21 (2017); Cymraeg 2050: A million Welsh speakers (2017); Cymraeg 2050: A million Welsh speakers, Work programme 2017–21 (2017); Welsh language technology action plan (2018); Welsh-language Technology and Digital Media Action Plan (2013); Technology, Websites and Software: Welsh Language Considerations (Welsh Language Commissioner, 2016) Mae’r ddogfen yma hefyd ar gael yn Gymraeg. This document is also available in Welsh. -

Influence of Liverpool Welsh on Lenition in Liverpool English
Influence of Liverpool Welsh on Lenition in Liverpool English Hannah Paton The purpose of this research was to provide evidence for the Welsh language having an influence on the Liverpool accent with a specific focus on the lenition and aspiration of voiceless plosives. Lenition and aspiration of the speech of participants from Liverpool and North Wales were determined using an acoustic software. The data suggested lenition did occur in the speech of the Welsh participants. However, lenition seemed to be trending amongst people in Liverpool as plosives were lenited a stage further than previous research suggests. Conclusions may be drawn to highlight an influence of the Welsh language on lenition in Liverpool. Keywords: lenition, Liverpool, sociophonetics, Wales, Welsh language 1 Introduction The use of aspirated voiceless plosives is a common feature in British accents of English (Ashby & Maidment 2005). However, the aspiration of voiceless plosives in a word-final position is normally not audible and if it is medial, it takes on the characteristics of other syllables in the word (Roach, 2000). Some accents of English exaggerate the aspiration of the voiceless plosives /p, t, k/ although this is not generally found in most Northern English accents of English (Wells 1982). There are only two English accents of English that have been found to do this through previous research. These are London and Liverpool English (Trudgill, Hughes & Watt 2005). Due to the influence of London English on Estuary English, this feature can be heard in the South West of England. Most accents of English that do have this feature have some interference from another language that heavily aspirates voiceless plosives such as Irish, Welsh, Singaporean or African-American English (Wells, 1982). -

Kupni Smlouva.Pdf
KUPNÍ SMLOUVA Č. UKFFS/0267/2020 uzavřená dle ustanovení § 2430 a násl. zákona č. 89/2012 Sb., občanský zákoník, ve znění pozdějších předpisů, (dále jen „OZ“) mezi smluvními stranami Univerzita Karlova, Filozofická fakulta sídlo: náměstí Jana Palacha 1/2, 116 38 Praha 1 zastoupena: doc. PhDr. Michalem Pullmannem, Ph.D., děkanem IČO: 00216208 DIČ: CZ00216208 bankovní spojení: Komerční banka, a.s., Praha 1 č. ú.: kontaktní osoba: +420 221 619 248, e‐mail: interní číslo zakázky: na straně jedné (dále jen „kupující“) a Kuba Libri s.r.o. sídlo/místo podnikání: Ruská 972/94, 100 00 Praha 10 ‐ Vršovice zápis v obchodním rejstříku: vedeném Městským soudem v Praze, odd. C, vložka 204178 zastoupena: MUDr. Janem Švecem, jednatelem společnosti IČO: 29149177 DIČ: CZ29149177 bankovní spojení: Komerční banka, a.s. č. ú.: 107‐407821021 0 kontaktní osoba: MUDr. Jan Švec, 6 959 563, e‐mail: jan.svec@kubal na straně druhé (dále jen „prodávající“) Článek I Úvodní ustanovení 1.1. Tato smlouva se uzavírá na základě výsledků zadávacího řízení na dodávky, vyhlášeného kupujícím, jako zadavatelem, pod názvem „Výzva č. 15: FF UK ‐ nákup knih pro projekt KREAS“ (dále jen „veřejná zakázka“ nebo „zakázka“) v rámci zavedeného Dynamického nákupního systému pro nákup knih pro projekt KREAS v období 2018 ‐ 2022 a v souladu se zadávací dokumentací a nabídkou prodávajícího podanou v rámci shora uvedeného zadávacího řízení. 1.2. Touto smlouvou se prodávající zavazuje na svůj náklad, na svou odpovědnost a v dohodnuté době dodat kupujícímu knihy (dále jen „zboží“), které jsou blíže specifikované v Příloze č. 1 Specifikace dodávky (dále jen „Příloha č. -

The Ideology of American English As Standard English in Taiwan
Arab World English Journal (AWEJ) Volume.7 Number.4 December, 2016 Pp. 80 - 96 The Ideology of American English as Standard English in Taiwan Jackie Chang English Department, National Pingtung University Pingtung City, Taiwan Abstract English language teaching and learning in Taiwan usually refers to American English teaching and learning. Taiwan views American English as Standard English. This is a strictly perceptual and ideological issue, as attested in the language school promotional materials that comprise the research data. Critical Discourse Analysis (CDA) was employed to analyze data drawn from language school promotional materials. The results indicate that American English as Standard English (AESE) ideology is prevalent in Taiwan. American English is viewed as correct, superior and the proper English language version for Taiwanese people to compete globally. As a result, Taiwanese English language learners regard native English speakers with an American accent as having the greatest prestige and as model teachers deserving emulation. This ideology has resulted in racial and linguistic inequalities in contemporary Taiwanese society. AESE gives Taiwanese learners a restricted knowledge of English and its underlying culture. It is apparent that many Taiwanese people need tore-examine their taken-for-granted beliefs about AESE. Keywords: American English as Standard English (AESE),Critical Discourse Analysis (CDA), ideology, inequalities 80 Arab World English Journal (AWEJ) Vol.7. No. 4 December 2016 The Ideology of American English as Standard English in Taiwan Chang Introduction It is an undeniable fact that English has become the global lingua franca. However, as far as English teaching and learning are concerned, there is a prevailing belief that the world should be learning not just any English variety but rather what is termed Standard English. -

Who Identifies As Welsh? National
November 2014 DYNAMICS OF DIVERSITY: EVIDENCE FROM THE 2011 CENSUS ESRC Centre on Dynamics of Ethnicity (CoDE) Who identifies asWelsh? National identities and ethnicity in Wales Summary • In Wales, 1.8 million people identify only as Welsh (58% of • People born in Wales are more likely to report only a Welsh the population) and 218,000 identify as Welsh and British national identity (76%). People born in Oceania and North (7% of the population). America and the Caribbean are more likely to report only a Welsh national identity (14% and 10% respectively) than • Mixed ethnic groups are more likely to identify with only people born in England (8%). a Welsh national identity than all other ethnic minority groups, with the highest proportion being amongst the White and Black Caribbean (59%) group. Introduction Since devolution, the Welsh Government has sought to • Mixed groups are more likely to identify only as Welsh support a common Welsh national identity through the ‘One (47%) than mixed groups in England (46%) and Scotland Wales’ strategy. This has included, for example, strengthening (37%) identify as English or Scottish only. the place of ‘Wales in the World’ and continued support for 1 • The ethnic groups in Wales most likely to identify only as the Welsh language. The inclusion of a question on national British are Bangladeshi (64%), Pakistani (56%) and Black identity in the 2011 Census provides us with an opportunity Caribbean (41%). to examine how people living in Wales describe themselves. The Census shows that 58% of people living in Wales identify • Welsh only national identity is reported more for younger only as Welsh and a further 7% identify as Welsh and British.2 people aged 0 to 17 than those aged 18 or older. -
Pronunciation Notes (PDF)
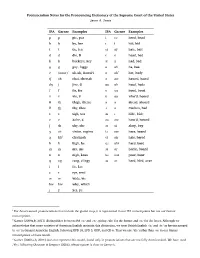
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter. -

A Contrastive Study Between Rp and Ga Segmental Features
A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Submitted as one of the requirements for completing the Undergraduate Study Program at the English Education Department School of Teacher Training and Education By: AULIANISA NETASYA SALAM A320160022 DEPARTMENT OF ENGLISH EDUCATION SCHOOL OF TEACHER TRAINING AND EDUCATION MUHAMMADIYAH UNIVERSITY OF SURAKARTA 2020 A CONTRASTIVE STUDY BETWEEN RP AND GA SEGMENTAL FEATURES Abstrak Penelitian ini merupakan penelitian kontrastif yang bertujuan untuk mendeskripsikan persamaan dan perbedaan ciri segmental RP dan GA. Penelitian ini menggunakan metode deskriptif-kualitatif dengan pengumpulan data dari video YouTube. Studi ini menemukan bahwa kesamaan antara bunyi segmental RP dan GA pada posisi awal, medial, dan akhir adalah [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [ d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. Bunyi serupa yang ditemukan di posisi awal dan medial adalah [ӕ], [tʃ], [dȝ], [ð], [h], [w], [j]; di posisi medial dan terakhir adalah [aɪ], [k], [ȝ], [ղ]; di posisi awal adalah [r] dan di posisi medial: [ʊ], [ʌ], [ɛ]. Kemudian perbedaan suara antara fitur segmental RP dan GA telah ditemukan pada posisi awal dan medial adalah [ͻ], [ɑ:]; pada posisi medial dan akhir adalah [ɪə], [əʊ], pada posisi awal [ʌ], [eə] sedangkan pada posisi medial adalah [ɒ], [i:], [u:], [ͻ:], [ ʊə], [t]. Kata kunci: penerima pengucapan, amerika umum, pengucapan, fonetis. Abstract This research is a contrastive study aimed to describe the similarities and the differences between RP and GA segmental features. This research used descriptive-qualitative method which collected the data from the YouTube video. The study found that the similarities between RP and GA segmental sounds in initial, medial, and final positions are [ɪ], [ə], [eɪ], [ͻɪ], [p], [b], [t], [d], [tʃ], [θ], [g], [f], [v], [s], [z], [ʃ], [m], [n], [l]. -

Uva-DARE (Digital Academic Repository)
UvA-DARE (Digital Academic Repository) Accents, attitudes and Scouse influence in North Wales English Cremer, M. Publication date 2007 Published in Toegepaste Taalwetenschap in Artikelen Link to publication Citation for published version (APA): Cremer, M. (2007). Accents, attitudes and Scouse influence in North Wales English. Toegepaste Taalwetenschap in Artikelen, 77, 33-43. http://www.anela.nl/index.php?option=com_content&task=view&id=148#cremer General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:30 Sep 2021 ACCENTS, ATTITUDES AND SCOUSE INFLUENCE IN NORTH WALES ENGLISH M. Cremer, ACLC, Universiteit van Amsterdam 1 Introduction Regarding the sociolinguistic situation in Wales, one can say that centuries of Anglicisation brought about by political, commercial and educational forces have not only left Wales with a new language, but have also left the Welsh with an inferiority complex. -

History of English Language (Eng1c03)
School of Distance Education HISTORY OF ENGLISH LANGUAGE (ENG1C03) STUDY MATERIAL I SEMESTER CORE COURSE MA ENGLISH (2019 Admission ONWARDS) UNIVERSITY OF CALICUT SCHOOL OF DISTANCE EDUCATION Calicut University P.O, Malappuram Kerala, India 673 635. 190003 History of English Language Page 1 School of Distance Education UNIVERSITY OF CALICUT SCHOOL OF DISTANCE EDUCATION STUDY MATERIAL FIRST SEMESTER MA ENGLISH (2019 ADMISSION) CORE COURSE : ENG1C03 : HISTORY OF ENGLISH LANGUAGE Prepared by : 1. Smt.Smitha N, Assistant Professor on Contract (English) School of Distance Education, University of Calicut. 2. Prof. P P John (Retd.), St.Joseph’s College, Devagiri. Scrutinized by : Dr.Aparna Ashok, Assistant Professor on Contract, Dept. of English, University of Calicut. History of English Language Page 2 School of Distance Education CONTENTS 1 Section : A 6 2 Section : B 45 3 Section : C 58 History of English Language Page 3 School of Distance Education Introduction As English Literature learners, we must know the evolution of this language over the past fifteen hundred years or more. This course offers an overview of the History of English Language from its origin to the present. This SLM will have three sections: Section A briefly considers the early development of English Language and major historical events that had been made changes in its course. Section B takes up the changes that have taken place in English through Foreign invasions in 17th, 18th, and 19th centuries, besides it discusses the contribution of major writers to enrich this language. In the Section C, we trace out the evolution of standard English and the significance of English in this globalized world where technology reigns. -
Information About Welsh Speech 1
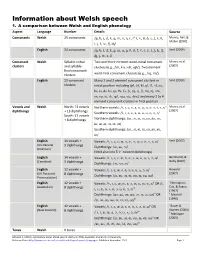
Information about Welsh speech 1. A comparison between Welsh and English phonology Aspect Language Number Details Source Consonants Welsh 25 consonants /p, b, t,̪ d,̪ k, ɡ, m, n̪, ŋ, r, rh,̥ f, v, θ, ð, s, ʃ, x, h, Munro, Ball, & Müller (2007) ɬ, j, l, w, ʧ, ʤ/ English 24 consonants /p, b, t, d, k, ɡ, m, n, ŋ, θ, ð, f, v, s, z, ʃ, ʒ, h, ʧ, Smit (2004) ʤ, j, w, ɹ, l/ Consonant Welsh Syllable‐initial Two and three element word‐initial consonant Munro et al. (2007) clusters and syllable‐ clusters (e.g., /sb, kn, sdr, sɡl/). Two element final consonant clusters word‐final consonant clusters (e.g., /sɡ, rn/). English 23 consonant Many 2 and 3 element consonant clusters in Smit (2004) clusters initial position including /pl, bl, kl, ɡl, fl, sl, pɹ, bɹ, tɹ, dɹ, kɹ, ɡɹ, θɹ, fɹ, ʃɹ, pj, tj, fj, mj, nj, sm, sn, sp, st, sk, spl, spɹ, stɹ, skw/ and many 2 to 4 element consonant clusters in final position Vowels and Welsh North: 13 vowels Northern vowels: /i, ɪ, e, ɛ, a, ɑ, u, ʊ, o, ɔ, ɨ, ᵻ, ə/ Munro et al. diphthongs + 13 diphthongs (2007) Southern vowels: /i, ɪ, e, ɛ, a, ɑ, u, ʊ, o, ɔ, ə/ South: 11 vowels + 8 diphthongs Northern diphthongs: /aɪ , ɔɪ, əɪ, ɪʊ, ɛʊ, aʊ, əʊ, ɨʊ, aᵻ, ɑᵻ, ɔᵻ, ʊᵻ, əᵻ/ Southern diphthongs: /aɪ , ɔɪ, əɪ, ɪʊ, ɛʊ, aʊ, əʊ, ʊɪ/ English 14 vowels + Vowels: /i, ɪ, e, ɛ, æ, ə, ɚ, ɝ, u, ʊ, o, ʌ, ɔ, ɑ/ Smit (2007) (US‐General 3 diphthongs Diphthongs: /a , a , / American) ɪ ʊ ɔɪ (Smit also lists 5 ‘r’‐colored diphthongs) English 14 vowels + Vowels: /i, ɪ, e, ɛ, æ, ə, ɚ, ɝ, ʉ, ʊ, o, ʌ, ɔ, ɑ/ Bernhardt, & (Canadian) 3 diphthongs Deby -

The Realisation of Stress in Welsh English
ICPhS XVII Regular Session Hong Kong, 17-21 August 2011 THE REALISATION OF STRESS IN WELSH ENGLISH Kelly Webb University of Bangor, UK [email protected] ABSTRACT Later studies [1] have shown that the realisation of stress in English is more complicated than just F0 Primary lexical stress is realised differently in movement and syllable duration. Amplitude can play English and Welsh. English lexical stress involves a more important role depending on how it is greater vowel duration in the associated syllable, measured, as can the location of the word in the whereas Welsh involves the shortening of the vowel sentence, i.e. if the word is in prenuclear, nuclear, or associated with the stressed syllable and the postnuclear position. lengthening of the immediately following consonant. It is certainly true that none of these features exist Some accounts have suggested that Welsh English in isolation, and that all play a part in the realisation also features this long post-stress consonant. and perception of lexical stress in English. However, This study examined the realisation of primary Cutler states that F0 movement and greater syllable lexical stress in Welsh English by comparing it to duration “are the most strongly related and the least Welsh and Standard Southern British English controversial” [4] (p.269), and it is the latter of these (SSBE). The results show that the long post-stress two which is of the greatest concern to this study (as consonant duration in Welsh English is similar to explained further below), particularly segment Welsh. duration within the stressed syllable.