Arxiv:2006.11572V2 [Cs.CL] 14 Jul 2020
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

C:\#1 Work\Greek\Wwgreek\REVISED
Review Book for Luschnig, An Introduction to Ancient Greek Part Two: Lessons VII- XIV Revised, August 2007 © C. A. E. Luschnig 2007 Permission is granted to print and copy for personal/classroom use Contents Lesson VII: Participles 1 Lesson VIII: Pronouns, Perfect Active 6 Review of Pronouns 8 Lesson IX: Pronouns 11 Perfect Middle-Passive 13 Lesson X: Comparison, Aorist Passive 16 Review of Tenses and Voices 19 Lesson XI: Contract Verbs 21 Lesson XII: -MI Verbs 24 Work sheet on -:4 verbs 26 Lesson XII: Subjunctive & Optative 28 Review of Conditions 31 Lesson XIV imperatives, etc. 34 Principal Parts 35 Review 41 Protagoras selections 43 Lesson VII Participles Present Active and Middle-Passive, Future and Aorist, Active and Middle A. Summary 1. Definition: A participle shares two parts of speech. It is a verbal adjective. As an adjective it has gender, number, and case. As a verb it has tense and voice, and may take an object (in whatever case the verb takes). 2. Uses: In general there are three uses: attributive, circumstantial, and supplementary. Attributive: with the article, the participle is used as a noun or adjective. Examples: @Ê §P@<JgH, J Ð<J", Ò :X88T< PD`<@H. Circumstantial: without the article, but in agreement with a noun or pronoun (expressed or implied), whether a subject or an object in the sentence. This is an adjectival use. The circumstantial participle expresses: TIME: (when, after, while) [:", "ÛJ\6", :gJ">b] CAUSE: (since) [Jg, ñH] MANNER: (in, by) CONDITION: (if) [if the condition is negative with :Z] CONCESSION: (although) [6"\, 6"\BgD] PURPOSE: (to, in order to) future participle [ñH] GENITIVE ABSOLUTE: a noun / pronoun + a participle in the genitive form a clause which gives the circumstances of the action in the main sentence. -

Concepticon: a Resource for the Linking of Concept Lists
Concepticon: A Resource for the Linking of Concept Lists Johann-Mattis List1, Michael Cysouw2, Robert Forkel3 1CRLAO/EHESS and AIRE/UPMC, Paris, 2Forschungszentrum Deutscher Sprachatlas, Marburg, 3Max Planck Institute for the Science of Human History, Jena [email protected], [email protected], [email protected] Abstract We present an attempt to link the large amount of different concept lists which are used in the linguistic literature, ranging from Swadesh lists in historical linguistics to naming tests in clinical studies and psycholinguistics. This resource, our Concepticon, links 30 222 concept labels from 160 conceptlists to 2495 concept sets. Each concept set is given a unique identifier, a unique label, and a human-readable definition. Concept sets are further structured by defining different relations between the concepts. The resource can be used for various purposes. Serving as a rich reference for new and existing databases in diachronic and synchronic linguistics, it allows researchers a quick access to studies on semantic change, cross-linguistic polysemies, and semantic associations. Keywords: concepts, concept list, Swadesh list, naming test, word norms, cross-linguistically linked data 1. Introduction in the languages they were working on, or that they turned In 1950, Morris Swadesh (1909 – 1967) proposed the idea out to be not as stable and universal as Swadesh had claimed that certain parts of the lexicon of human languages are uni- (Matisoff, 1978; Alpher and Nash, 1999). Up to today, versal, stable over time, and rather resistant to borrowing. dozens of different concept lists have been compiled for var- As a result, he claimed that this part of the lexicon, which ious purposes. -

Principal Parts of Verbs • All Verbs Have Four Principal Parts–A Base Form, a Present Participle, a Simple Past Form, and a Past Participle
Principal Parts of Verbs • All verbs have four principal parts–a base form, a present participle, a simple past form, and a past participle. • All the verb tenses are formed from these principal parts. Click the mouse button or press the Space Bar to display the information. 1 Lesson 1-2 Principal Parts of Verbs (cont.) • You can use the base form (except the base form of be) and the past form alone as main verbs. • The present participle and the past participle, however, must always be used with one or more auxiliary verbs to function as the simple predicate. Click the mouse button or press the Space Bar to display the information. 2 Lesson 1-3 Principal Parts of Verbs (cont.) – Carpenters work. [base or present form] – Carpenters worked. [past form] – Carpenters are working. [present participle with the auxiliary verb are] – Carpenters have worked. [past participle with the auxiliary verb have] Click the mouse button or press the Space Bar to display the information. 3 Lesson 1-4 Exercise 1 Using Principal Parts of Verbs Complete each of the following sentences with the principal part of the verb that is indicated in parentheses. 1. Most plumbers _________repair hot water heaters. (base form of repair) 2. Our plumber is _________repairing the kitchen sink. (present participle of repair) 3. Last month, he _________repaired the dishwasher. (past form of repair) 4. He has _________repaired many appliances in this house. (past participle of repair) 5. He is _________enjoying his work. (present participle of enjoy) Click the mouse button or press the Space Bar to display the answers. -

PROTO-SIOUAN PHONOLOGY and GRAMMAR Robert L. Rankin, Richard T
PROTO-SIOUAN PHONOLOGY AND GRAMMAR Robert L. Rankin, Richard T. Carter and A. Wesley Jones Univ. of Kansas, Univ. of Nebraska and Univ. of Mary The intellectual work on the Comparative Siouan Dictionary is relatively complete we and now have a picture of Proto-Siouan phonology and grammar. 1 The following is our Proto-Siouan pho neme inventory with a number of explanatory comments: labial dental palatal velar glottal STOPS Preaspirates: hp ht hk Postaspirates: ph th kh Glottals: p? t? k? ? Plain: p t k FRICATIVES voiceless: s g x h glottal: s? g? x? RESONANTS sonorant: w r y obstruent: W R VOWELS oral vowels: i u e 0 a nasal vowels: i- II ACCENT: 1'1 (high vs, non-high) & (possibly IAI falling) VOWEL LENGTH: I-I (+long) PREASPIRATED VOICELESS STOPS. We treat these as units be cause they incorporate a laryngeal feature that has attached it self to the stop, and because speakers today treat the reflexes of the series as single units for purposes of syllabification and segmentability. However, in pre-Proto-Siouan it is possible that there was no preaspirated series. The preaspirates pretty clearly arose as regular allophonic variants of plain voiceless stops preceding an accented vowel. This was pointed out by Dick Carter for Ofo in 1984. Even so, we have a number of lexical sets where it appears to be necessary to reconstruct plain voiceless stops in this environment also. Therefore, by the Proto-Siouan period the distinction between plain and preaspirated stops had appar- ently been phonemicized as shown by the following cognate sets: -

'Face' in Vietnamese
Body part extensions with mặt ‘face’ in Vietnamese Annika Tjuka 1 Introduction In many languages, body part terms have multiple meanings. The word tongue, for example, refers not only to the body part but also to a landscape or object feature, as in tongue of the ocean or tongue of flame. These examples illustrate that body part terms are commonly mapped to concrete objects. In addition, body part terms can be transferred to abstract domains, including the description of emotional states (e.g., Yu 2002). The present study investigates the mapping of the body part term face to the concrete domain of objects. Expressions like mouth of the river and foot of the bed reveal the different analogies for extending human body parts to object features. In the case of mouth of the river, the body part is extended on the basis of the function of the mouth as an opening. In contrast, the expression foot of the bed refers to the part of the bed where your feet are if you lie in it. Thus, the body part is mapped according to the spatial alignment of the body part and the object. Ambiguous words challenge our understanding of how the mental lexicon is structured. Two processes could lead to the activation of a specific meaning: i) all meanings of a word are stored in one lexical entry and the relevant one is retrieved, ii) only a core meaning is stored and the other senses are generated by lexical rules (for a description of both models, see, Pustejovsky 1991). In the following qualitative analysis, I concentrate on the different meanings of the body part face and discuss the implications for its representation in the mental lexicon. -

UC Berkeley Dissertations, Department of Linguistics
UC Berkeley Dissertations, Department of Linguistics Title Constructional Morphology: The Georgian Version Permalink https://escholarship.org/uc/item/1b93p0xs Author Gurevich, Olga Publication Date 2006 eScholarship.org Powered by the California Digital Library University of California Constructional Morphology: The Georgian Version by Olga I Gurevich B.A. (University of Virginia) 2000 M.A. (University of California, Berkeley) 2002 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the GRADUATE DIVISION of the UNIVERSITY OF CALIFORNIA, BERKELEY Committee in charge: Professor Eve E. Sweetser, Co-Chair Professor James P. Blevins, Co-Chair Professor Sharon Inkelas Professor Johanna Nichols Spring 2006 The dissertation of Olga I Gurevich is approved: Co-Chair Date Co-Chair Date Date Date University of California, Berkeley Spring 2006 Constructional Morphology: The Georgian Version Copyright 2006 by Olga I Gurevich 1 Abstract Constructional Morphology: The Georgian Version by Olga I Gurevich Doctor of Philosophy in Linguistics University of California, Berkeley Professor Eve E. Sweetser, Co-Chair, Professor James P. Blevins, Co-Chair Linguistic theories can be distinguished based on how they represent the construc- tion of linguistic structures. In \bottom-up" models, meaning is carried by small linguistic units, from which the meaning of larger structures is derived. By contrast, in \top-down" models the smallest units of form need not be individually meaningful; larger structures may determine their overall meaning and the selection of their parts. Many recent developments in psycholinguistics provide empirical support for the latter view. This study combines intuitions from Construction Grammar and Word-and-Para- digm morphology to develop the framework of Constructional Morphology. -

The Emergence of Hausa As a National Lingua Franca in Niger
Ahmed Draia University – Adrar Université Ahmed Draia Adrar-Algérie Faculty of Letters and Languages Department of English Letters and Language A Research Paper Submitted in Partial Fulfilment of the Requirements for a Master’s Degree in Linguistics and Didactics The Emergence of Hausa as a National Lingua Franca in Niger Presented by: Supervised by: Moussa Yacouba Abdoul Aziz Pr. Bachir Bouhania Academic Year: 2015-2016 Abstract The present research investigates the causes behind the emergence of Hausa as a national lingua franca in Niger. Precisely, the research seeks to answer the question as to why Hausa has become a lingua franca in Niger. To answer this question, a sociolinguistic approach of language spread or expansion has been adopted to see whether it applies to the Hausa language. It has been found that the emergence of Hausa as a lingua franca is mainly attributed to geo-historical reasons such as the rise of Hausa states in the fifteenth century, the continuous processes of migration in the seventeenth century which resulted in cultural and linguistic assimilation, territorial expansion brought about by the spread of Islam in the nineteenth century, and the establishment of long-distance trade by the Hausa diaspora. Moreover, the status of Hausa as a lingua franca has recently been maintained by socio- cultural factors represented by the growing use of the language for commercial and cultural purposes as well as its significance in education and media. These findings arguably support the sociolinguistic view regarding the impact of society on language expansion, that the widespread use of language is highly determined by social factors. -

Native American Languages, Indigenous Languages of the Native Peoples of North, Middle, and South America
Native American Languages, indigenous languages of the native peoples of North, Middle, and South America. The precise number of languages originally spoken cannot be known, since many disappeared before they were documented. In North America, around 300 distinct, mutually unintelligible languages were spoken when Europeans arrived. Of those, 187 survive today, but few will continue far into the 21st century, since children are no longer learning the vast majority of these. In Middle America (Mexico and Central America) about 300 languages have been identified, of which about 140 are still spoken. South American languages have been the least studied. Around 1500 languages are known to have been spoken, but only about 350 are still in use. These, too are disappearing rapidly. Classification A major task facing scholars of Native American languages is their classification into language families. (A language family consists of all languages that have evolved from a single ancestral language, as English, German, French, Russian, Greek, Armenian, Hindi, and others have all evolved from Proto-Indo-European.) Because of the vast number of languages spoken in the Americas, and the gaps in our information about many of them, the task of classifying these languages is a challenging one. In 1891, Major John Wesley Powell proposed that the languages of North America constituted 58 independent families, mainly on the basis of superficial vocabulary resemblances. At the same time Daniel Brinton posited 80 families for South America. These two schemes form the basis of subsequent classifications. In 1929 Edward Sapir tentatively proposed grouping these families into superstocks, 6 in North America and 15 in Middle America. -
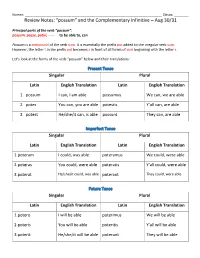
“Possum” and the Complementary Infinitive – Aug 30/31
Nomen: ____________________________________________________________________________ Classis: ________ Review Notes: “possum” and the Complementary Infinitive – Aug 30/31 Principal parts of the verb “possum”: possum, posse, potui, ----- to be able to, can Possum is a compound of the verb sum. It is essentially the prefix pot added to the irregular verb sum. However, the letter t in the prefix pot becomes s in front of all forms of sum beginning with the letter s. Let’s look at the forms of the verb “possum” below and their translations: Present Tense Singular Plural Latin English Translation Latin English Translation 1. possum I can, I am able possumus We can, we are able 2. potes You can, you are able potestis Y’all can, are able 3. potest He/she/it can, is able possunt They can, are able Imperfect Tense Singular Plural Latin English Translation Latin English Translation 1.poteram I could, was able poteramus We could, were able 2.poteras You could, were able poteratis Y’all could, were able 3.poterat He/she/it could, was able poterant They could, were able Future Tense Singular Plural Latin English Translation Latin English Translation 1.potero I will be able poterimus We will be able 2.poteris You will be able poteritis Y’all will be able 3.poterit He/she/it will be able poterunt They will be able So what about the perfect, pluperfect, and future perfect forms of the verb “possum”? These tenses are regular, meaning possum follows the normal rules. Let’s look at them. Start by rewriting your principal parts of the verb: Possum, posse, potui, ------ to be able to, can Just like all other verbs, switch to the 3rd principal part when you want to work in the perfect, pluperfect, and future perfect tenses. -

Bartholomew Collection of Unpublished Materials SIL International - Mexico Branch
Language and Culture Archives Bartholomew Collection of Unpublished Materials SIL International - Mexico Branch © SIL International NOTICE This document is part of the archive of unpublished language data created by members of the Mexico Branch of SIL International. While it does not meet SIL standards for publication, it is shared “as is” under the Creative Commons Attribution- NonCommercial-ShareAlike license (http://creativecommons.org/licenses/by-nc- sa/4.0/) to make the content available to the language community and to researchers. SIL International claims copyright to the analysis and presentation of the data contained in this document, but not to the authorship of the original vernacular language content. AVISO Este documento forma parte del archivo de datos lingüísticos inéditos creados por miembros de la filial de SIL International en México. Aunque no cumple con las normas de publicación de SIL, se presenta aquí tal cual de acuerdo con la licencia "Creative Commons Atribución-NoComercial-CompartirIgual" (http://creativecommons.org/licenses/by-nc- sa/4.0/) para que esté accesible a la comunidad y a los investigadores. Los derechos reservados por SIL International abarcan el análisis y la presentación de los datos incluidos en este documento, pero no abarcan los derechos de autor del contenido original en la lengua indígena. Non-modal voicing as morphemic features in Íénná, Mazatec of Mazatlán Villa de Flores1, 2 R. David Klint SIL International 1 Introduction Mazatec is a Mexican language with 12-20 variants spoken in the La Cañada area of Oaxaca. Many variants show asymmetries in the laryngeally modified consonants of the phonemic inventory. Specifically, the laryngeally modified consonants in the phonemic inventory of Íénná, Mazatec of Mazatlán Villa de Flores, ISO 639-3 = vmz, mazateco del suroeste (INALI 2016), are asymmetric. -

Modeling and Encoding Traditional Wordlists for Machine Applications
Modeling and Encoding Traditional Wordlists for Machine Applications Shakthi Poornima Jeff Good Department of Linguistics Department of Linguistics University at Buffalo University at Buffalo Buffalo, NY USA Buffalo, NY USA [email protected] [email protected] Abstract Clearly, descriptive linguistic resources can be This paper describes work being done on of potential value not just to traditional linguis- the modeling and encoding of a legacy re- tics, but also to computational linguistics. The source, the traditional descriptive wordlist, difficulty, however, is that the kinds of resources in ways that make its data accessible to produced in the course of linguistic description NLP applications. We describe an abstract are typically not easily exploitable in NLP appli- model for traditional wordlist entries and cations. Nevertheless, in the last decade or so, then provide an instantiation of the model it has become widely recognized that the devel- in RDF/XML which makes clear the re- opment of new digital methods for encoding lan- lationship between our wordlist database guage data can, in principle, not only help descrip- and interlingua approaches aimed towards tive linguists to work more effectively but also al- machine translation, and which also al- low them, with relatively little extra effort, to pro- lows for straightforward interoperation duce resources which can be straightforwardly re- with data from full lexicons. purposed for, among other things, NLP (Simons et al., 2004; Farrar and Lewis, 2007). 1 Introduction Despite this, it has proven difficult to create When looking at the relationship between NLP significant electronic descriptive resources due to and linguistics, it is typical to focus on the dif- the complex and specific problems inevitably as- ferent approaches taken with respect to issues sociated with the conversion of legacy data. -

Download Download
The Southern Algonquians and Their Neighbours DAVID H. PENTLAND University of Manitoba INTRODUCTION At least fifty named Indian groups are known to have lived in the area south of the Mason-Dixon line and north of the Creek and the other Muskogean tribes. The exact number and the specific names vary from one source to another, but all agree that there were many different tribes in Maryland, Virginia and the Carolinas during the colonial period. Most also agree that these fifty or more tribes all spoke languages that can be assigned to just three language families: Algonquian, Iroquoian, and Siouan. In the case of a few favoured groups there is little room for debate. It is certain that the Powhatan spoke an Algonquian language, that the Tuscarora and Cherokee are Iroquoians, and that the Catawba speak a Siouan language. In other cases the linguistic material cannot be positively linked to one particular political group. There are several vocabularies of an Algonquian language that are labelled Nanticoke, but Ives Goddard (1978:73) has pointed out that Murray collected his "Nanticoke" vocabulary at the Choptank village on the Eastern Shore, and Heckeweld- er's vocabularies were collected from refugees living in Ontario. Should the language be called Nanticoke, Choptank, or something else? And if it is Nanticoke, did the Choptank speak the same language, a different dialect, a different Algonquian language, or some completely unrelated language? The basic problem, of course, is the lack of reliable linguistic data from most of this region. But there are additional complications. It is known that some Indians were bilingual or multilingual (cf.