Ultra-Large Last-Level Cache (UL3C) of Phase Change Memory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 3 Semiconductor Memories
Chapter 3 Semiconductor Memories Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Introduction Random Access Memories Content Addressable Memories Read Only Memories Flash Memories Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 2 Overview of Memory Types Semiconductor Memories Read/Write Memory or Random Access Memory (RAM) Read Only Memory (ROM) Random Access Non-Random Access Memory (RAM) Memory (RAM) •Mask (Fuse) ROM •Programmable ROM (PROM) •Erasable PROM (EPROM) •Static RAM (SRAM) •FIFO/LIFO •Electrically EPROM (EEPROM) •Dynamic RAM (DRAM) •Shift Register •Flash Memory •Register File •Content Addressable •Ferroelectric RAM (FRAM) Memory (CAM) •Magnetic RAM (MRAM) Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 3 Memory Elements – Memory Architecture Memory elements may be divided into the following categories Random access memory Serial access memory Content addressable memory Memory architecture 2m+k bits row decoder row decoder 2n-k words row decoder row decoder column decoder k column mux, n-bit address sense amp, 2m-bit data I/Os write buffers Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 4 1-D Memory Architecture S0 S0 Word0 Word0 S1 S1 Word1 Word1 S2 S2 Word2 Word2 A0 S3 S3 A1 Decoder Ak-1 Sn-2 Storage Sn-2 Wordn-2 element Wordn-2 Sn-1 Sn-1 Wordn-1 Wordn-1 m-bit m-bit Input/Output Input/Output n select signals are reduced n select signals: S0-Sn-1 to k address signals: A0-Ak-1 Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 5 Memory Architecture S0 Word0 Wordi-1 S1 A0 A1 Ak-1 Row Decoder Sn-1 Wordni-1 A 0 Column Decoder Aj-1 Sense Amplifier Read/Write Circuit m-bit Input/Output Advanced Reliable Systems (ARES) Lab. -

Class Notes Class: IX Topic: INPUT, OUTPUT, MEMORY and STORAGE DEVICES of a COMPUTER SYSTEM Subject: INFORMATION TECHNOLOGY
Class Notes Class: IX Topic: INPUT, OUTPUT, MEMORY AND STORAGE DEVICES OF A COMPUTER SYSTEM Subject: INFORMATION TECHNOLOGY Q1. A collection of eight bits is called BYTE Q2. Which of the following is an example of non-volatile memory? a) ROM b)RAM c) LSI d) VLSI Q3. Which of the following is unit of measurement used with computer system? a) Byte b) Megabyte c) Gigabyte d) All of the above Q4. Which of the following statement is false? a) Secondary storage in non-volatile. b) Primary storage is volatile. c) When the computer is turned off, data and instructions stored in primary storage are erased. d) None of the above. Q5. The secondary storage devices can only store data but they cannot perform a) Arithmetic operation b) Logic operation c) Fetch operation d) Either of above Q6. Which of the following does not represent an I/O device a) Speaker which beep b) Plotter C) Joystick d) ALU Q7. Which of the following is a correct definition of volatile memory? a) It loses its content at high temperatures. b) It is to be kept in airtight boxes. c) It loses its contents on failure of power supply d) It does not lose its contents on failure of power supply Q8. One thousand byte represent a a) Megabyte b) Gigabyte c) Kilobyte d) None of these Q9.What does a storage unit provide? a) A place to show data b) A place to store currently worked on information b) A place to store information Q10. What are four basic components of a computer? a) Input devices, Output devices, printing and typing b) Input devices, processing unit, storage and Output devices c) Input devices, CPU, Output devices and RAM Q11. -

The Era of Expeditious Nanoram-Based Computers Enhancement of Operating System Performance in Nanotechnology Environment
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 13, Number 1 (2018) pp. 375-384 © Research India Publications. http://www.ripublication.com The Era of Expeditious NanoRAM-Based Computers Enhancement of Operating System Performance in Nanotechnology Environment Mona Nabil ElGohary PH.D Student, Computer Science Department Faculty of Computers and Information, Helwan University, Cairo, Egypt. 1ORCID: 0000-0002-1996-4673 Dr. Wessam ElBehaidy Assistant Professor, Computer Science Department, Faculty of Computers and Information, Helwan University, Cairo, Egypt. Ass. Prof. Hala Abdel-Galil Associative Professor, Computer Science Department Faculty of Computers and Information, Helwan University, Cairo, Egypt. Prof. Dr. Mostafa-Sami M. Mostafa Professor of Computer Science Faculty of Computers and Information, Helwan University, Cairo, Egypt. Abstract They announced that by 2018 will produce the first NanoRAM. The availability of a new generation of memory that is 1000 times faster than traditional DDRAM which can deliver This new NanoRam has many excellent properties that would terabytes of storage capacity, and consumes very little power, make an excellent replacement for the current DDRAM: being has the potential to change the future of the computer’s non-volatile, its large capacity, high speed read / write cycles. operating system. This paper studies the different changes that All the properties are introduced in the next section. will arise on the operating system functions; memory By replacing this NanoRAM instead of DDRAM in the CPU, management and job scheduling (especially context switch) this will affect the functionality of the operating system; such when integrating NanoRAM into the computer system. It is as main memory management, virtual memory, job scheduling, also looking forward to evaluating the possible enhancements secondary storage management; and thus the efficiency of the of computer’s performance with NanoRAM. -
Section 10 Flash Technology
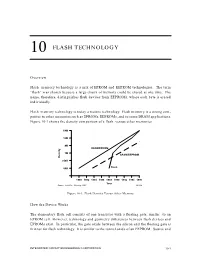
10 FLASH TECHNOLOGY Overview Flash memory technology is a mix of EPROM and EEPROM technologies. The term “flash” was chosen because a large chunk of memory could be erased at one time. The name, therefore, distinguishes flash devices from EEPROMs, where each byte is erased individually. Flash memory technology is today a mature technology. Flash memory is a strong com- petitor to other memories such as EPROMs, EEPROMs, and to some DRAM applications. Figure 10-1 shows the density comparison of a flash versus other memories. 64M 16M 4M DRAM/EPROM 1M SRAM/EEPROM Density 256K Flash 64K 1980 1982 1984 1986 1988 1990 1992 1994 1996 Year Source: Intel/ICE, "Memory 1996" 18613A Figure 10-1. Flash Density Versus Other Memory How the Device Works The elementary flash cell consists of one transistor with a floating gate, similar to an EPROM cell. However, technology and geometry differences between flash devices and EPROMs exist. In particular, the gate oxide between the silicon and the floating gate is thinner for flash technology. It is similar to the tunnel oxide of an EEPROM. Source and INTEGRATED CIRCUIT ENGINEERING CORPORATION 10-1 Flash Technology drain diffusions are also different. Figure 10-2 shows a comparison between a flash cell and an EPROM cell with the same technology complexity. Due to thinner gate oxide, the flash device will be more difficult to process. CMOS Flash Cell CMOS EPROM Cell Mag. 10,000x Mag. 10,000x Flash Memory Cell – Larger transistor – Thinner floating gate – Thinner oxide (100-200Å) Photos by ICE 17561A Figure 10-2. -

Let's Talk About Storage & Recovery Methods for Non-Volatile Memory
Let’s Talk About Storage & Recovery Methods for Non-Volatile Memory Database Systems Joy Arulraj Andrew Pavlo Subramanya R. Dulloor [email protected] [email protected] [email protected] Carnegie Mellon University Carnegie Mellon University Intel Labs ABSTRACT of power, the DBMS must write that data to a non-volatile device, The advent of non-volatile memory (NVM) will fundamentally such as a SSD or HDD. Such devices only support slow, bulk data change the dichotomy between memory and durable storage in transfers as blocks. Contrast this with volatile DRAM, where a database management systems (DBMSs). These new NVM devices DBMS can quickly read and write a single byte from these devices, are almost as fast as DRAM, but all writes to it are potentially but all data is lost once power is lost. persistent even after power loss. Existing DBMSs are unable to take In addition, there are inherent physical limitations that prevent full advantage of this technology because their internal architectures DRAM from scaling to capacities beyond today’s levels [46]. Using are predicated on the assumption that memory is volatile. With a large amount of DRAM also consumes a lot of energy since it NVM, many of the components of legacy DBMSs are unnecessary requires periodic refreshing to preserve data even if it is not actively and will degrade the performance of data intensive applications. used. Studies have shown that DRAM consumes about 40% of the To better understand these issues, we implemented three engines overall power consumed by a server [42]. in a modular DBMS testbed that are based on different storage Although flash-based SSDs have better storage capacities and use management architectures: (1) in-place updates, (2) copy-on-write less energy than DRAM, they have other issues that make them less updates, and (3) log-structured updates. -

Error Detection and Correction Methods for Memories Used in System-On-Chip Designs
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 – 8958, Volume-8, Issue-2S2, January 2019 Error Detection and Correction Methods for Memories used in System-on-Chip Designs Gunduru Swathi Lakshmi, Neelima K, C. Subhas ABSTRACT— Memory is the basic necessity in any SoC Static Random Access Memory (SRAM): It design. Memories are classified into single port memory and consists of a latch or flipflop to store each bit of multiport memory. Multiport memory has ability to source more memory and it does not required any refresh efficient execution of operation and high speed performance operation. SRAM is mostly used in cache memory when compared to single port. Testing of semiconductor memories is increasing because of high density of current in the and in hand-held devices. It has advantages like chips. Due to increase in embedded on chip memory and memory high speed and low power consumption. It has density, the number of faults grow exponentially. Error detection drawback like complex structure and expensive. works on concept of redundancy where extra bits are added for So, it is not used for high capacity applications. original data to detect the error bits. Error correction is done in Read Only Memory (ROM): It is a non-volatile memory. two forms: one is receiver itself corrects the data and other is It can only access data but cannot modify data. It is of low receiver sends the error bits to sender through feedback. Error detection and correction can be done in two ways. One is Single cost. Some applications of ROM are scanners, ID cards, Fax bit and other is multiple bit. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

AXP Internal 2-Apr-20 1
2-Apr-20 AXP Internal 1 2-Apr-20 AXP Internal 2 2-Apr-20 AXP Internal 3 2-Apr-20 AXP Internal 4 2-Apr-20 AXP Internal 5 2-Apr-20 AXP Internal 6 Class 6 Subject: Computer Science Title of the Book: IT Planet Petabyte Chapter 2: Computer Memory GENERAL INSTRUCTIONS: • Exercises to be written in the book. • Assignment questions to be done in ruled sheets. • You Tube link is for the explanation of Primary and Secondary Memory. YouTube Link: ➢ https://youtu.be/aOgvgHiazQA INTRODUCTION: ➢ Computer can store a large amount of data safely in their memory for future use. ➢ A computer’s memory is measured either in Bits or Bytes. ➢ The memory of a computer is divided into two categories: Primary Memory, Secondary Memory. ➢ There are two types of Primary Memory: ROM and RAM. ➢ Cache Memory is used to store program and instructions that are frequently used. EXPLANATION: Computer Memory: Memory plays a very important role in a computer. It is the basic unit where data and instructions are stored temporarily. Memory usually consists of one or more chips on the mother board, or you can say it consists of electronic components that store instructions waiting to be executed by the processor, data needed by those instructions, and the results of processing the data. Memory Units: Computer memory is measured in bits and bytes. A bit is the smallest unit of information that a computer can process and store. A group of 4 bits is known as nibble, and a group of 8 bits is called byte. -

Embedded DRAM
Embedded DRAM Raviprasad Kuloor Semiconductor Research and Development Centre, Bangalore IBM Systems and Technology Group DRAM Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example References Slide 1 Acknowledgement • John Barth, IBM SRDC for most of the slides content • Madabusi Govindarajan • Subramanian S. Iyer • Many Others Slide 2 Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example Slide 3 Memory Classification revisited Slide 4 Motivation for a memory hierarchy – infinite memory Memory store Processor Infinitely fast Infinitely large Cycles per Instruction Number of processor clock cycles (CPI) = required per instruction CPI[ ∞ cache] Finite memory speed Memory store Processor Finite speed Infinite size CPI = CPI[∞ cache] + FCP Finite cache penalty Locality of reference – spatial and temporal Temporal If you access something now you’ll need it again soon e.g: Loops Spatial If you accessed something you’ll also need its neighbor e.g: Arrays Exploit this to divide memory into hierarchy Hit L2 L1 (Slow) Processor Miss (Fast) Hit Register Cache size impacts cycles-per-instruction Access rate reduces Slower memory is sufficient Cache size impacts cycles-per-instruction For a 5GHz -

MSP430 Flash Memory Characteristics (Rev. B)
Application Report SLAA334B–September 2006–Revised August 2018 MSP430 Flash Memory Characteristics ........................................................................................................................ MSP430 Applications ABSTRACT Flash memory is a widely used, reliable, and flexible nonvolatile memory to store software code and data in a microcontroller. Failing to handle the flash according to data-sheet specifications can result in unreliable operation of the application. This application report explains the physics behind these specifications and also gives recommendations for the correct management of flash memory on MSP430™ microcontrollers (MCUs). All examples are based on the flash memory used in the MSP430F1xx, MSP430F2xx, and MSP430F4xx microcontroller families. Contents 1 Flash Memory ................................................................................................................ 2 2 Simplified Flash Memory Cell .............................................................................................. 2 3 Flash Memory Parameters ................................................................................................. 3 3.1 Data Retention ...................................................................................................... 3 3.2 Flash Endurance.................................................................................................... 5 3.3 Cumulative Program Time......................................................................................... 5 4 -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory -

Computer Conservation Society
Issue Number 88 Winter 2019/20 Computer Conservation Society Aims and Objectives The Computer Conservation Society (CCS) is a co-operative venture between BCS, The Chartered Institute for IT; the Science Museum of London; and the Science and Industry Museum (SIM) in Manchester. The CCS was constituted in September 1989 as a Specialist Group of the British Computer Society. It is thus covered by the Royal Charter and charitable status of BCS. The objects of the Computer Conservation Society (“Society”) are: To promote the conservation, restoration and reconstruction of historic computing systems and to identify existing computing systems which may need to be archived in the future; To develop awareness of the importance of historic computing systems; To develop expertise in the conservation, restoration and reconstruction of historic computing systems; To represent the interests of the Society with other bodies; To promote the study of historic computing systems, their use and the history of the computer industry; To publish information of relevance to these objectives for the information of Society members and the wider public. Membership is open to anyone interested in computer conservation and the history of computing. The CCS is funded and supported by a grant from BCS and from donations. There are a number of active projects on specific computer restorations and early computer technologies and software. Younger people are especially encouraged to take part in order to achieve skills transfer. The CCS also enjoys a close relationship with the National Museum of Computing. Resurrection The Journal of the Computer Conservation Society ISSN 0958-7403 Number 88 Winter 2019/20 Contents Society Activity 2 News Round-Up 9 The Data Curator 10 Paul Cockshott From Tea Shops to Computer Company: The Improbable 15 Story of LEO John Aeberhard Book Review: Early Computing in Britain Ferranti Ltd.