A Brief Exploration of the Development of the Japanese Writing System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Study of Old Documents of Hokkaido and Kuril Ainu
NINJAL International Symposium 2018 Approaches to Endangered Languages in Japan and Northeast Asia, August 6-8 The study of old documents of Hokkaido and Kuril Ainu: Promise and Challenges Tomomi Sato (Hokkaido U) & Anna Bugaeva (TUS/NINJAL) [email protected] [email protected]) Introduction: Ainu • AINU (isolate, North Japan, moribund) • Is the only non-Japonic lang. of Japan. • Major dialect groups : Hokkaido (moribund), Sakhalin (extinct since 1993), Kuril (extinct since the end of XIX). • Was also spoken in Tōhoku till mid XVIII. • Hokkaido Ainu dialects: Southwestern (well documented) Northeastern (less documented) • Is not used in daily conversation since the 1950s. • Ethnical Ainu: 100,000. 2 Fig. 2 Major language families in Northeast Asia (excluding Sinitic) Amuric Mongolic Tungusic Ainuic Koreanic Japonic • Ainu shares only few features with Northeast Asian languages. • Ainu is typologically “more like a morphologically reduced version of a North American language.” (Johanna Nichols p.c.). • This is due to the strongly head-marking character of Ainu (Bugaeva, to appear). Why is it important to study Ainu? • Ainu culture is widely regarded as a direct descendant of the Jōmon culture which was spread in the Japanese archipelago in the Prehistoric time from about 14,000 BC. • Ainu is the only surviving Jōmon language; there had been other Jōmon lgs too: about 300 lgs (Janhunen 2002), cf. 10 lgs (Whitman, p.c.) . • Ainu is likely to be much more typical of what languages were like in Northeast Asia several millennia ago than the picture we would get from Chinese, Japanese or Korean. • Focusing on Ainu can help us understand a period of northeast Asian history when political, cultural and linguistic units were very different to what they have been since the rise of the great historically-attested states of East Asia. -

Fungsi Ateji Dalam Lirik Lagu Pada Album Marginal #4 the Best 「Star Cluster 2」 Produksi Rejet
PARAMASASTRA Vol. 6 No. 1 - Maret 2019 p-ISSN 2355-4126 e-ISSN 2527-8754 http://journal.unesa.ac.id/index.php/paramasastra FUNGSI ATEJI DALAM LIRIK LAGU PADA ALBUM MARGINAL #4 THE BEST 「STAR CLUSTER 2」 PRODUKSI REJET Meisha Putri M.R., Agus Budi Cahyono Universitas Brawijaya, [email protected] Universitas Brawijaya, [email protected] ABSTRACT This article aimed to describe why furigana in Japanese songs often found different furigana actually with kanji below it. Data uses the album MARGINAL # 4 THE BEST 「STAR CLUSTER 2」 REJET Production. This study uses qualitative descriptive to examine the type of ateji based on Lewis's theory (2010) and its function based on the theory of Jakobson (1960). Based on analysis, writer find more contrastive ateji than denotive ateji. Fatigue function is found more than other functions. The metalingual function is found on all data. Keywords: Ateji, Furigana, semantic PENDAHULUAN Huruf bahasa Jepang dibagi menjadi 4 yang digunakan sehari-hari. Adapun huruf tersebut adalah Kanji, Hiragana, Katakana dan Romaji. Pada penulisan huruf Kanji kadang diikuti dengan furigana yang merupakan bantuan cara baca serta memaknai kanji itu sendiri karena huruf kanji kadang mempunyai cara baca yang berbeda. Selain pembubuhan dengan furigana ada juga dengan ateji. Furigana itu murni sebagai cara baca dan makna aslinya, maka ateji adalah bantuan cara baca yang dilekatkan untuk menambahkan lapisan ide maupun makna di dalam kanji itu sendiri. Ateji merupakan penulisan bahasa Jepang yang tidak mengikuti cara baca jion (cara baca kanji China) dan jikun (cara baca kanji Jepang) ataupun jigi (makna asli) bahasa Jepang tersebut (Shirose, 2012: 103). -

Uhm Phd 9506222 R.Pdf
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UM! films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent UJWD the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adverselyaffect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-band comer and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. U·M·I University Microfilms tnternauonat A Bell & Howell tntorrnatron Company 300 North Zeeb Road. Ann Arbor. M148106-1346 USA 313/761-4700 800:521·0600 Order Number 9506222 The linguistic and psycholinguistic nature of kanji: Do kanji represent and trigger only meanings? Matsunaga, Sachiko, Ph.D. University of Hawaii, 1994 Copyright @1994 by Matsunaga, Sachiko. -

Man'yogana.Pdf (574.0Kb)
Bulletin of the School of Oriental and African Studies http://journals.cambridge.org/BSO Additional services for Bulletin of the School of Oriental and African Studies: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here The origin of man'yogana John R. BENTLEY Bulletin of the School of Oriental and African Studies / Volume 64 / Issue 01 / February 2001, pp 59 73 DOI: 10.1017/S0041977X01000040, Published online: 18 April 2001 Link to this article: http://journals.cambridge.org/abstract_S0041977X01000040 How to cite this article: John R. BENTLEY (2001). The origin of man'yogana. Bulletin of the School of Oriental and African Studies, 64, pp 5973 doi:10.1017/S0041977X01000040 Request Permissions : Click here Downloaded from http://journals.cambridge.org/BSO, IP address: 131.156.159.213 on 05 Mar 2013 The origin of man'yo:gana1 . Northern Illinois University 1. Introduction2 The origin of man'yo:gana, the phonetic writing system used by the Japanese who originally had no script, is shrouded in mystery and myth. There is even a tradition that prior to the importation of Chinese script, the Japanese had a native script of their own, known as jindai moji ( , age of the gods script). Christopher Seeley (1991: 3) suggests that by the late thirteenth century, Shoku nihongi, a compilation of various earlier commentaries on Nihon shoki (Japan's first official historical record, 720 ..), circulated the idea that Yamato3 had written script from the age of the gods, a mythical period when the deity Susanoo was believed by the Japanese court to have composed Japan's first poem, and the Sun goddess declared her son would rule the land below. -

SUPPORTING the CHINESE, JAPANESE, and KOREAN LANGUAGES in the OPENVMS OPERATING SYSTEM by Michael M. T. Yau ABSTRACT the Asian L
SUPPORTING THE CHINESE, JAPANESE, AND KOREAN LANGUAGES IN THE OPENVMS OPERATING SYSTEM By Michael M. T. Yau ABSTRACT The Asian language versions of the OpenVMS operating system allow Asian-speaking users to interact with the OpenVMS system in their native languages and provide a platform for developing Asian applications. Since the OpenVMS variants must be able to handle multibyte character sets, the requirements for the internal representation, input, and output differ considerably from those for the standard English version. A review of the Japanese, Chinese, and Korean writing systems and character set standards provides the context for a discussion of the features of the Asian OpenVMS variants. The localization approach adopted in developing these Asian variants was shaped by business and engineering constraints; issues related to this approach are presented. INTRODUCTION The OpenVMS operating system was designed in an era when English was the only language supported in computer systems. The Digital Command Language (DCL) commands and utilities, system help and message texts, run-time libraries and system services, and names of system objects such as file names and user names all assume English text encoded in the 7-bit American Standard Code for Information Interchange (ASCII) character set. As Digital's business began to expand into markets where common end users are non-English speaking, the requirement for the OpenVMS system to support languages other than English became inevitable. In contrast to the migration to support single-byte, 8-bit European characters, OpenVMS localization efforts to support the Asian languages, namely Japanese, Chinese, and Korean, must deal with a more complex issue, i.e., the handling of multibyte character sets. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

The Twentieth-Century Secularization of the Sinograph in Vietnam, and Its Demotion from the Cosmological to the Aesthetic
Journal of World Literature 1 (2016) 275–293 brill.com/jwl The Twentieth-Century Secularization of the Sinograph in Vietnam, and its Demotion from the Cosmological to the Aesthetic John Duong Phan* Rutgers University [email protected] Abstract This article examines David Damrosch’s notion of “scriptworlds”—spheres of cultural and intellectual transfusion, defined by a shared script—as it pertains to early mod- ern Vietnam’s abandonment of sinographic writing in favor of a latinized alphabet. The Vietnamese case demonstrates a surprisingly rapid readjustment of deeply held attitudes concerning the nature of writing, in the wake of the alphabet’s meteoric suc- cesses. The fluidity of “language ethics” in early modern Vietnam (a society that had long since developed vernacular writing out of an earlier experience of diglossic liter- acy) suggests that the durability of a “scriptworld” depends on the nature and history of literacy in the societies under question. Keywords Vietnamese literature – Vietnamese philology – Chinese philology – script reform – language reform – early modern East Asia/Southeast Asia Introduction In 1919, the French-installed emperor Khải Định permanently dismantled Viet- nam’s civil service examinations, and with them, an entire system of political * I would like to thank Wynn Wilcox, Nguyễn Tuấn Cường, Tuna Artun, and Jack Chia for their valuable help and input. All errors are my own. © koninklijke brill nv, leiden, 2016 | doi: 10.1163/24056480-00102010 Downloaded from Brill.com09/25/2021 07:54:41AM via free access 276 phan selection based on proficiency in Literary Sinitic.1 That same year, using a con- troversial latinized alphabet called Quốc Ngữ (lit. -
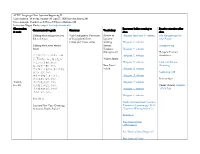
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -
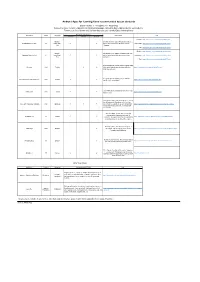
Android Apps for Learning Kana Recommended by Our Students
Android Apps for learning Kana recommended by our students [Kana column: H = Hiragana, K = Katakana] Below are some recommendations for Kana learning apps, ranked in descending order by our students. Please try a few of these and find one that suits your needs. Enjoy learning Kana! Recommended Points App Name Kana Language Description Link Listening Writing Quizzes English: https://nihongo-e-na.com/android/jpn/id739.html English, Developed by the Japan Foundation and uses Hiragana Memory Hint H Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id746.html Thai Hiragana. Thai: https://nihongo-e-na.com/android/eng/id773.html English: https://nihongo-e-na.com/android/eng/id743.html English, Developed by the Japan Foundation and uses Katakana Memory Hint K Indonesian, 〇 〇 picture mnemonics to help you memorize Indonesian: https://nihongo-e-na.com/android/eng/id747.html Thai Katakana. Thai: https://nihongo-e-na.com/android/eng/id775.html A holistic app that can be used to master Kana Obenkyo H&K English 〇 〇 fully, and eventually also for other skills like https://nihongo-e-na.com/android/eng/id602.html Kanji and grammar. A very integrated quizzing system with five Kana (Hiragana and Katakana) H&K English 〇 〇 https://nihongo-e-na.com/android/jpn/id626.html varieties of tests available. Uses SRS (Spatial Repetition System) to help Kana Town H&K English 〇 〇 https://nihongo-e-na.com/android/eng/id845.html build memory. Although the app is entirely in Japanese, it only has Hiragana and Katakana so the interface Free Learn Japanese Hiragana H&K Japanese 〇 〇 〇 does not pose a problem as such. -

Chinese Script Generation Panel Document
Chinese Script Generation Panel Document Proposal for the Generation Panel for the Chinese Script Label Generation Ruleset for the Root Zone 1. General Information Chinese script is the logograms used in the writing of Chinese and some other Asian languages. They are called Hanzi in Chinese, Kanji in Japanese and Hanja in Korean. Since the Hanzi unification in the Qin dynasty (221-207 B.C.), the most important change in the Chinese Hanzi occurred in the middle of the 20th century when more than two thousand Simplified characters were introduced as official forms in Mainland China. As a result, the Chinese language has two writing systems: Simplified Chinese (SC) and Traditional Chinese (TC). Both systems are expressed using different subsets under the Unicode definition of the same Han script. The two writing systems use SC and TC respectively while sharing a large common “unchanged” Hanzi subset that occupies around 60% in contemporary use. The common “unchanged” Hanzi subset enables a simplified Chinese user to understand texts written in traditional Chinese with little difficulty and vice versa. The Hanzi in SC and TC have the same meaning and the same pronunciation and are typical variants. The Japanese kanji were adopted for recording the Japanese language from the 5th century AD. Chinese words borrowed into Japanese could be written with Chinese characters, while Japanese words could be written using the character for a Chinese word of similar meaning. Finally, in Japanese, all three scripts (kanji, and the hiragana and katakana syllabaries) are used as main scripts. The Chinese script spread to Korea together with Buddhism from the 2nd century BC to the 5th century AD.