Finite Element Earthquake City Simulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Let's Go to the Movies!
JAP130728/3 Let’s go to the movies! Visit some of the spectacular locations used for filmmaking in Japan Lights! Camera! Action! Japan has a long and proud history of filmmaking Not only from local directors such as Yasujirō Ozu; Akira Kurosawa; and Ishirō Honda (who have produced classic movies such as Tokyo Story; Seven Samurai; and Godzilla), but Japan has also been the dramatic setting for Hollywood blockbusters such as The Last Samurai (with Tom Cruise); The Wolverine (with Hugh Jackman); and the soon to be released 47 Ronin (starring Keanu Reeves). Using the silver screen as our inspiration, on this trip we immerse ourselves into the diverse scenery, cultures and traditions of this fascinating land. Trip Duration: 14 Days Grade: Basic Level Accommodation: Traditional Inns (13 nights) Price: TBC Welcome to www.ventureea.com: Venture specialises in small group travel designing activities and itineraries tailored to ensure that you get the most out of your Adventure, Expedition, or Event. Day 1: Australia to Tokyo Having arrived at Narita International Airport, we checkin to our accommodation Shigetsu Ryokan, a comfortable traditional Japanese inn located in Tokyo’s old downtown area. We will get to experience how a typical family lives in the ryokan, sleeping in the traditional style of a futon which the staff will prepare for you each night. Slippers and a yukata (Japanese bathrobe) are provided as is traditional, with the addition of modern conveniences in all the rooms including wifi, airconditioning, private bathroom facilities, minibar, TV and telephone, as well as complimentary Japanese tea. -

BURGER BULLETIN MARCH 2016 Mary O’Neill, Director Joe Valdivia, Assoc
BURGER BULLETIN MARCH 2016 Mary O’Neill, Director Joe Valdivia, Assoc. Director, Lynn Sossi, Assoc. Director 28865 Carlyle St. Inkster, MI 48141 http://www.gardencityschools.com/BurgerSchool.cfm Phone: 734-729-1830 Fax No. 734-729-1844 Burger Transition Center - Phone: 734-762-8470 Fax No. 734-762-8540 MISSION STATEMENT: Burger School for Students with Autism is committed to maximizing the potential of each student to gain independent and self-fulfillment. Through a collaborative effort, we will work in partnership with students each other, parents, community and local districts to assure that each student has the opportunity to become a happy, he althy, productive and contributing member of society. DATES TO REMEMBER My New School by Aaron Grove by Branson Bellamy Mar. 5 Lyman Family Movie; Zootopia , Canton Emagine Theater Hi fellow students of Burger! It has been Mar. 9 Transition Night; O’Leary Auditorium very nice meeting you! My name is Garden City High School Branson Bellamy. I have been living in Mar. 10 Transition Night; Burger Transition Westland for most of my life. I have had Center trouble controlling my emotions in Mar. 20 BASA Autos for Autism Meeting; previous schools, but I have been doing Albert’s on the Alley, 3:00 pm great at Burger. Mar. 25 – 31 Spring Break; No School About four weeks prior to starting Burger, I had mixed feelings. To be more precise, I was as nervous as a mouse in a cat house. At first, I was afraid I was going to get picked on, but that didn’t happen at all. -

D20: Toho Based Dungeons & Dragons
First Published: 10/09/02 Updated: 06/02/16 This article features rules for a Toho universe based Dungeons & Dragons (D&D) game. It adapts Godzilla, Mothra and characters from other science fiction and fantasy films like the Onmyoji series for the game. The rules are broken into four sections: Janjira: a Toho based setting Gods Monsters Spells and Domains Equipment Gods includes information on the god-kaiju of a Toho universe based campaign. The monsters are the various creatures of a Toho universe based game, including non-divine kaiju and monsters. Also includes rules on playing some of the more benign races. The History of Janjira The new world began with the destruction of the old one. Ten thousand years ago the nations of Janjira, who had long labored to secure their kingdoms against the trials and tribulations of the world, achieved their goal. Their greatest minds had derived wondrous technologies from the very foundations of the world, a melding of machine and magic. Where once children in remote villages grew up hungry and sick, automatons were brought to tend crops and heal their maladies. Houses in the mountains were filled with warmth during the coldest months of the year and the deadliest creatures of the wild were held in check by the awesome might of their arms. The most basic trials that had harried civilization since the beginning of time now assuaged, the people of Janjira set aside their toils and gazed out on their lands in peace. Years passed, and they forgot the struggles of their ancestors and set aside their gods, decreeing that their society had reached what must surely be perfection. -

Godzilla and the Japanese After World War II: from a Scapegoat of the Americans to a Saviour of the Japanese
Godzilla and the Japanese after World War II: From a scapegoat of the Americans to a saviour of the Japanese Yoshiko Ikeda Ritsumeikan University Abstract. This paper examines how five Godzilla films illuminate the complicated relationship between Japan and the United States over the use of nuclear weapons. The United States dropped the first atomic bombs on Japan and created the first nuclear monster film, The Beast from 20,000 Fathoms (1953), which inspired the Godzilla series. The popularity of these Godzilla films derives from skilfully grappling with the political, social and cultural problems created by the use of nuclear weapons and science/technology, both inside Japan and in relations between Japan and the United States. This paper takes a historical perspective and shows how the Godzilla characters reflect these attitudes across time, moving from a scapegoat for the Americans to a saviour of the Japanese. Gojira (Godzilla) series An ancient monster, deformed by a series of nuclear bomb tests and expelled from his natural habitat, lands in Tokyo and starts destroying Japanese cities. Given the name Godzilla, he destroys these symbols of civilisation as if seeking revenge on humankind for creating such technology. Gojira,1 produced and released by Toho Studio, was a breakthrough hit in Japan in 1954.2 It was followed by 29 Japanese sequels and two American versions of the Japanese films, Godzilla, King of the Monsters (1956) and Godzilla 1985: The Legend is Reborn (1984). Gojira was Japan’s first export film and the series appealed to both Japanese and foreign audiences. Over the past 50 years, Godzilla has transformed in shape and character, playing various roles in the stories. -

Mystery Science Theater 3000
17 EQUIPMENT for RIFFING: ADVANCED TEXT-ReadiNG Tactics AND PolYVALENT CONstraiNts IN MYSTERY SCIENCE THeater 3000 M ATT F OY N ORTHERN I OWA A REA C OMMUNITY C OLLEGE Since the dawn of the mediated spectacle—from film Channel/Comedy Central (1988-1996) and the Sci-Fi and television and into the postmodern age of intensifying Channel (1997-1999), also spawning a 1996 feature the- media saturation and convergence—popular culture has atrical film. MST3K carved out such a legacy that it was been both creator and reflector of social reality; it seems named as one of TIME Magazine’s 100 best TV shows of there is no longer an objective social reality we can access all time—gushed TIME, “This basic-cable masterpiece without mediation.1 Our capacity for decoding mediated raised talking back to the TV into an art form” (Poniewozik reality is inextricable from our ability to make sense of 2007). TV Guide twice anointed MST3K among the top the social world. Debates over audience agency and the twenty-five cult shows of all time.MST3K earned a Pea- roles mediated texts play in the lives of readers have been body Award in 1993, as well as Emmy, CableACE, and at the center of a long-running debate among Critical, Saturn Award nominations. The show remains popular in Cultural, and Rhetorical Studies scholars, among them home media and cultural practice well into the 21st century. Michel de Certeau, Celeste Michelle Condit, John Fiske, MST3K is primarily known for introducing the art of Stuart Hall, and Henry Jenkins, whose contributions to movie riffing into the cultural lexicon. -

Alternative Titles Index
VHD Index - 02 9/29/04 4:43 PM Page 715 Alternative Titles Index While it's true that we couldn't include every Asian cult flick in this slim little vol- ume—heck, there's dozens being dug out of vaults and slapped onto video as you read this—the one you're looking for just might be in here under a title you didn't know about. Most of these films have been released under more than one title, and while we've done our best to use the one that's most likely to be familiar, that doesn't guarantee you aren't trying to find Crippled Avengers and don't know we've got it as The Return of the 5 Deadly Venoms. And so, we've gathered as many alternative titles as we can find, including their original language title(s), and arranged them in alphabetical order in this index to help you out. Remember, English language articles ("a", "an", "the") are ignored in the sort, but foreign articles are NOT ignored. Hey, my Japanese is a little rusty, and some languages just don't have articles. A Fei Zheng Chuan Aau Chin Adventure of Gargan- Ai Shang Wo Ba An Zhan See Days of Being Wild See Running out of tuas See Gimme Gimme See Running out of (1990) Time (1999) See War of the Gargan- (2001) Time (1999) tuas (1966) A Foo Aau Chin 2 Ai Yu Cheng An Zhan 2 See A Fighter’s Blues See Running out of Adventure of Shaolin See A War Named See Running out of (2000) Time 2 (2001) See Five Elements of Desire (2000) Time 2 (2001) Kung Fu (1978) A Gai Waak Ang Kwong Ang Aau Dut Air Battle of the Big See Project A (1983) Kwong Ying Ji Dut See The Longest Nite The Adventures of Cha- Monsters: Gamera vs. -

Cyclopaedia 18 – Kaiju Overview Articles
Cyclopaedia 18 – Kaiju By T.R. Knight (InnRoads Ministries * Article Series) Overview Who are the biggest of the Kaijū derives from the Japanese for "strange big? beast" but in more common vernacular these are giant monster stories. Giant monsters Some debate which are the greatest of the attacking cities (especially Tokyo), the Kaiju. The top quartet are easy to choose military defending the city, giant monsters (Gamera, Godzilla, King Kong, and Mothra). fighting each other, and secret societies or The most commonly discussed and with the aliens betting involved. These were all most screen time include… trademarks of the kaiju genre. • Destroyah Gojira (translated as Godzilla in the US) • Gamera receives credit for being the first ever kaiju • Godzilla film. Released in 1954, it is considered the • King Ghidorah first kaiju film but it is not the first giant • King Kong monster movie. King Kong and The Beast • MechaGodzilla from 20,000 Fathoms were hits in the US and • Mothra Japan, so Gojira was the Japanese cinematic • Rodan response to those popular films. Tomoyuki Tanaka of Toho Studios combined the Following are sources of information Hollywood giant monster concept with the pertaining to Kaiju to assist prospective growing fear of atomic weapons in Japan. game masters, game designers, writers, and The movie was a huge success in Japan, storytellers in knowing where to start their spawning the kaiju movie genre. The movie research. was so popular in Japan it was brought to the US as Godzilla, King of Monsters. Articles In the US, the Create Double Feature matinee and Mystery Science Theater 3000 developed Godzilla: why the Japanese original is no a massive following for these kaiju movies joke from Japan. -

*Not to Scale Meet the Panel
Lawyers vs Kaiju *Not to Scale Meet the Panel Monte Cooper Jeraline Singh Edwards Joshua Gilliland Megan Hitchcock Matt Weinhold Does your Homeowner’s insurance cover being stepped on? Can Local Governments Recover Emergency costs? Public Expenditures Made in the Performance of Governmental Functions ARE NOT Recoverable! Is King Kong protected by the Endangered Species Act? Lawyers in the Mist A species is “endangered” if it is “in danger of extinction throughout all or a significant portion of its range.” 16 U.S. CODE § 1532(6). A species is “threatened” if it is “likely to become an endangered species within the foreseeable future throughout all or a significant portion of its range.” Id. § 1532(20); Conservation Force, Inc. v. Jewell, 733 F.3d 1200, 1202 (D.C. Cir. 2013). A species is considered “endangered” because of “natural or manmade factors affecting its continued existence.” 16 USCS § 1533(a)(1)(E). Is King Kong Protected by the Convention on International Trade in Protected Species (CITES)? CITES is a multi-lateral treaty originally negotiated among 80 countries in Washington DC in 1973 Subjects international trade in specimens of selected species to certain export and import controls As of 2018, 183 states and the European Union have become parties to the Convention Roughly 5,000 species of animals and 29,000 species of plants are protected by CITES Western Gorillas are specifically listed as subject to CITES BUT … King Kong in all incarnations is a new primate species, called Megaprimatus kong in 2005… King Kong Is a Critically Endangered Species When in New York … 1933 – Bad Things Happen to Kong in New York 1976 – Clearly, the Passage of the Environmental 2005 – The White House Still Does Not Species Act Did Not Help … Believe that Kong Needs Protection… Unfortunately for Kong, Skull Island Is Not a U.S. -
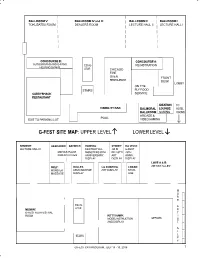
G-Fest Site Map: Upper Level Lower Level
BALLROOM V: BALLROOM IV and III: BALLROOM II: BALLROOM I: TOKUSATSU ROOM DEALERS ROOM LECTURE HALL II LECTURE HALL I CONCOURSE B: CONCOURSE A: AUTOGRAPHS AND G-FANS ESCAL- REGISTRATION HELPING G-FANS ATOR CHICAGO FIRE OVEN FRONT RESTAURANT DESK LOBBY ON THE STAIRS FLY FOOD CADDYSHACK SERVICE RESTAURANT IDEATION TO VISIBILITY BAR BALMORAL LOUNGE: HOTEL BALLROOM: GAMING ROOMS ARCADE & POOL EXIT TO PARKING LOT VIDEOGAMING G-FEST SITE MAP: UPPER LEVEL LOWER LEVEL KENNEDY: HEATHROW GATWICK HANEDA: SYDNEY DA VINCI: LECTURE HALL III DESTROY ALL JOHN G-FEST MINYA’S PLACE MONSTERS 50TH BELLOTTI 25TH KIDS ACTIVITIES ANNIVERSARY ART ANNIV. DISPLAY DISPLAY DISPLAY LOVE A & B: ORLY: DULLES: LA GUARDIA: LOGAN: ARTIST ALLEY MONSTER KEIZO MURASE ART DISPLAY STOR- MASSAGE DISPLAY AGE M O R E ESCAL- A ATOR MIDWAY: R G-FEST FILM FESTIVAL T ROOM KITTY HAWK: I MODEL INSTRUCTION OFFICES S AND DISPLAY T A L L STAIRS E Y G-FEST XXV PROGRAM, JULY 13 - 15, 2018 7 FRIDAY, JULY 13, 2018 SESSIONS SESSIONS SESSIONS GAMING FILM MODEL ARTISTS MECHA-G TOKUSATSU DEALERS OTHER FESTIVAL THREAD ALLEY ARCADE SESSIONS ROOM BALLROOM 1 BALLROOM 2 KENNEDY IDEATION MIDWAY KITTY HAWK LOVE A&B BALMORAL BALLROOM 5 BLRM 3 & 4 9:00 AFTER THE BOOM 50th REGISTRA- Anniversary TION (all day) OPENS 10:00 GENERAL MINYA’S Display KAIJU FILMS, GAMING PLACE Room open DOJO STYLE OPENS AT for drop-off, Alaena Gavins then viewing 10:00 AM in 11:00 HEATHROW & G-FEST KAIJU DESTROY COSTUMING GATWICK. ORIENTATION ASSAULT ALL PANEL Coloring and SESSION: TOURNEY DRAGONS Sean crafts for young J.D. -

GAMERA, GODZILLA, and PREDATOR Disclaimer
GAMERA, GODZILLA, AND PREDATOR Disclaimer . I acknowledge inspiration and instruction from various companies, Web sites, forums, and individuals . BUT: I want to make it clear that I am not representing any of those forums, companies, Web sites, or individuals . Furthermore: None of these organizations have reviewed or approved of the content of this presentation, nor have they reviewed or approved of the costumes I am presenting, or the techniques and materials I will be demonstrating Disclaimer (part 2) . The construction techniques and finished products have not been reviewed for quality, integrity, or suitability by any of the organizations named Disclaimed Parties . The Hunter’s Lair . MarsCon . The Monster Makers . The D.O.O.M. Squad . SparkFun Electronics . CONvergence Events . Smooth-On Inc. Inc. Plastics International . Dragon*Con . Toho Company Ltd. Carl and Diana Reis . Daiei Film Daniels . Tandy Leather Factory . 20th Century Fox . Stan Winston Studios Why I need a disclaimer . “Stevie Wonder going passed on horseback, should be able to see that someone wearing a forums apparel looks like they are a official representative of that forum. Which to be honest is alittle daft/cheaky unless asked to do so. “ Gamera (CONvergence 2007) Gamera (CONvergence 2007) Gamera . My first “real”, serious costume, even though I had made hall costumes of various quality . I made a latex mask by making a clay sculpture, then molding it in Ultracal 30 and slush-casting latex into the mold . Outer shell is made from Sintra plastic, covered with vinyl scales . Hands and feet are also latex, using the same techniques . Arms, legs, and inner shell are made from vinyl (which really trapped the heat) Gamera . -

Ultra-G-Fest! Official Program Book
OFFICIAL PROGRAM BOOK SEE: AKIRA TAKARADA LINDA MILLER BIN FURUYA HIROKO SAKURAI HIROSHI SAGAE YOSHIKAZU ISHII SOJIRO UCHINO AUGUST RAGONE CARL CRAIG ROBERT SCOTT FIELD ULTRA-G-FEST! G-FEST XXIII PROGRAM, JULY 15 - 17, 2016 G-FEST XXIII PROGRAM, JULY 15 - 17, 2016 TABLE OF WELCOME! As I complete the assembling of CONTENTS this program booklet, the largest yet in G- FEST history, I am amazed at the depth and variety of all that our annual gathering of Godzilla fans offers. For starters, it seems to Welcome...................................................................3 me that the programming schedule is so packed with interesting sessions that it will be difficult to choose which ones to attend Special guests and presenters.........................4, 5 and which ones to miss. Like the program book, the list of people participating in the convention in an Map of G-FEST rooms..........................................6 “official” capacity is the largest ever. This tells me that more people are seeing G-FEST as not just a place to The Dealer Room...................................................7 have fun and take in what’s on offer, but also to offer something themselves. Becoming a participant in the many activities that take place over the weekend is an excellent way to make the experience Daily schedule of events................................8 - 10 even better and more memorable. And of course, there are many, many things to do. G-FEST is distinguished from most other shows in that, while shopping for Descriptions of informational sessions.......11- 13 collectibles and obtaining autographs are important for many attendees, they are balanced by several other equally strong facets. -
Saint Patrick Vs. Godzilla
JAPAN, 1974. ONE ORGANIZATION, THE SPECIAL SCIENCE PATROL, STANDS READY TO DEFEND THE HOMELAND FROM DANGERS THAT WOULD MENACE JAPAN AND ALL MANKIND. RETURN WITH US TO THAT AGE OF GLORY AS WE REVIEW ONE OF THE SSP’S GREATEST CASES OF ALL TIME AS QUIRK BOOKS PRESENTS: SAINT PATRICK VS. GODZILLA into hot water again, much like the time we had CHAPTER 1: to rescue him from the boiling lava pit of the THE THREAT FROM BEYOND THE ROOM subterraneoids during the Case of the Missing PROFESSOR LOLLIPOP could not understand Mole People. His great intellect is matched by an why no one would take him seriously. Here he was, incredible tendency to blunder into inconvenient Japan’s top scientist, presenting important trouble.” Not unlike a certain junior agent of the research at the Big Science National Symposium, Special Science Patrol, Tananaka thought to and none of his colleagues himself but did not say. “What certain agent of the appreciated what he had AS FAR AS TANANAKA discovered. “In conclusion,” he Special Science Patrol?” asked WAS CONCERNED, THE concluded, “The islands of Tananaka’s partner, because it BOY HAD THE Japan and Ireland were once a turned out Tananaka had spoken PERSONALITY OF A single continent, split apart by an his thought out loud after all. I unimaginable force. And the HADDOCK. have to stop doing that, thought residual power of that cataclysm remains locked Tananaka, adding aloud, “Did I beneath the earth like the layer of mustard within say that out loud as well?” this corned beef sandwich!” He jabbed the “Say what out loud?” queried SSP agent Jimmy sandwich at the audience for emphasis, only to Jacko, who was Tananaka’s partner and a have a fleck of mustard fly out and strike him in the constant source of irritation.