What Is an Archaeon and Are the Archaea Really Unique?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
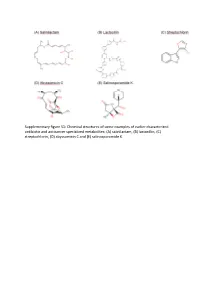
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

The Genomes of Polyextremophilic Cyanidiales Contain 1% 2 Horizontally Transferred Genes with Diverse Adaptive Functions 3 4 Alessandro W
bioRxiv preprint doi: https://doi.org/10.1101/526111; this version posted January 23, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 The genomes of polyextremophilic Cyanidiales contain 1% 2 horizontally transferred genes with diverse adaptive functions 3 4 Alessandro W. Rossoni1#, Dana C. Price2, Mark Seger3, Dagmar Lyska1, Peter Lammers3, 5 Debashish Bhattacharya4 & Andreas P.M. Weber1* 6 7 1Institute of Plant Biochemistry, Cluster of Excellence on Plant Sciences (CEPLAS), Heinrich 8 Heine University, Universitätsstraße 1, 40225 Düsseldorf, Germany 9 2Department of Plant Biology, Rutgers University, New Brunswick, NJ 08901, USA 10 3Arizona Center for Algae Technology and Innovation, Arizona State University, Mesa, AZ 11 85212, USA 12 4Department of Biochemistry and Microbiology, Rutgers University, New Brunswick, NJ 13 08901, USA 14 15 *Corresponding author: Prof. Dr. Andreas P.M. Weber, 16 e-mail: [email protected] 17 bioRxiv preprint doi: https://doi.org/10.1101/526111; this version posted January 23, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 18 Abstract 19 The role and extent of horizontal gene transfer (HGT) in eukaryotes are hotly disputed topics 20 that impact our understanding regarding the origin of metabolic processes and the role of 21 organelles in cellular evolution. -

METABOLIC EVOLUTION in GALDIERIA SULPHURARIA By
METABOLIC EVOLUTION IN GALDIERIA SULPHURARIA By CHAD M. TERNES Bachelor of Science in Botany Oklahoma State University Stillwater, Oklahoma 2009 Submitted to the Faculty of the Graduate College of the Oklahoma State University in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY May, 2015 METABOLIC EVOLUTION IN GALDIERIA SUPHURARIA Dissertation Approved: Dr. Gerald Schoenknecht Dissertation Adviser Dr. David Meinke Dr. Andrew Doust Dr. Patricia Canaan ii Name: CHAD M. TERNES Date of Degree: MAY, 2015 Title of Study: METABOLIC EVOLUTION IN GALDIERIA SULPHURARIA Major Field: PLANT SCIENCE Abstract: The thermoacidophilic, unicellular, red alga Galdieria sulphuraria possesses characteristics, including salt and heavy metal tolerance, unsurpassed by any other alga. Like most plastid bearing eukaryotes, G. sulphuraria can grow photoautotrophically. Additionally, it can also grow solely as a heterotroph, which results in the cessation of photosynthetic pigment biosynthesis. The ability to grow heterotrophically is likely correlated with G. sulphuraria ’s broad capacity for carbon metabolism, which rivals that of fungi. Annotation of the metabolic pathways encoded by the genome of G. sulphuraria revealed several pathways that are uncharacteristic for plants and algae, even red algae. Phylogenetic analyses of the enzymes underlying the metabolic pathways suggest multiple instances of horizontal gene transfer, in addition to endosymbiotic gene transfer and conservation through ancestry. Although some metabolic pathways as a whole appear to be retained through ancestry, genes encoding individual enzymes within a pathway were substituted by genes that were acquired horizontally from other domains of life. Thus, metabolic pathways in G. sulphuraria appear to be composed of a ‘metabolic patchwork’, underscored by a mosaic of genes resulting from multiple evolutionary processes. -

The Genome of Prasinoderma Coloniale Unveils the Existence of a Third Phylum Within Green Plants
SUPPLEMENTARY INFORMATIONARTICLES https://doi.org/10.1038/s41559-020-1221-7 In the format provided by the authors and unedited. The genome of Prasinoderma coloniale unveils the existence of a third phylum within green plants Linzhou Li1,2,13, Sibo Wang1,3,13, Hongli Wang1,4, Sunil Kumar Sahu 1, Birger Marin 5, Haoyuan Li1, Yan Xu1,4, Hongping Liang1,4, Zhen Li 6, Shifeng Cheng1, Tanja Reder5, Zehra Çebi5, Sebastian Wittek5, Morten Petersen3, Barbara Melkonian5,7, Hongli Du8, Huanming Yang1, Jian Wang1, Gane Ka-Shu Wong 1,9, Xun Xu 1,10, Xin Liu 1, Yves Van de Peer 6,11,12 ✉ , Michael Melkonian5,7 ✉ and Huan Liu 1,3 ✉ 1State Key Laboratory of Agricultural Genomics, BGI-Shenzhen, Shenzhen, China. 2Department of Biotechnology and Biomedicine, Technical University of Denmark, Lyngby, Denmark. 3Department of Biology, University of Copenhagen, Copenhagen, Denmark. 4BGI Education Center, University of Chinese Academy of Sciences, Shenzhen, China. 5Institute for Plant Sciences, Department of Biological Sciences, University of Cologne, Cologne, Germany. 6Department of Plant Biotechnology and Bioinformatics (Ghent University) and Center for Plant Systems Biology, Ghent, Belgium. 7Central Collection of Algal Cultures, Faculty of Biology, University of Duisburg-Essen, Essen, Germany. 8School of Biology and Biological Engineering, South China University of Technology, Guangzhou, China. 9Department of Biological Sciences and Department of Medicine, University of Alberta, Edmonton, Alberta, Canada. 10Guangdong Provincial Key Laboratory of Genome Read and Write, BGI-Shenzhen, Shenzhen, China. 11College of Horticulture, Nanjing Agricultural University, Nanjing, China. 12Centre for Microbial Ecology and Genomics, Department of Biochemistry, Genetics and Microbiology, University of Pretoria, Pretoria, South Africa. -

Phylogenomics Provides Robust Support for a Two-Domains Tree of Life
ARTICLES https://doi.org/10.1038/s41559-019-1040-x Phylogenomics provides robust support for a two-domains tree of life Tom A. Williams! !1*, Cymon J. Cox! !2, Peter G. Foster3, Gergely J. Szöllősi4,5,6 and T. Martin Embley7* Hypotheses about the origin of eukaryotic cells are classically framed within the context of a universal ‘tree of life’ based on conserved core genes. Vigorous ongoing debate about eukaryote origins is based on assertions that the topology of the tree of life depends on the taxa included and the choice and quality of genomic data analysed. Here we have reanalysed the evidence underpinning those claims and apply more data to the question by using supertree and coalescent methods to interrogate >3,000 gene families in archaea and eukaryotes. We find that eukaryotes consistently originate from within the archaea in a two-domains tree when due consideration is given to the fit between model and data. Our analyses support a close relation- ship between eukaryotes and Asgard archaea and identify the Heimdallarchaeota as the current best candidate for the closest archaeal relatives of the eukaryotic nuclear lineage. urrent hypotheses about eukaryotic origins generally pro- Indeed, it has previously been suggested that it is the 3D tree, rather pose at least two partners in that process: a bacterial endo- than the 2D tree, that is an artefact of long-branch attraction5,9–11, symbiont that became the mitochondrion and a host cell for both because analyses under better-fitting models have recovered C 1–4 that endosymbiosis . The identity of the host has been informed a 2D tree but also because the 3D topology is one in which the two by analyses of conserved genes for the transcription and transla- longest branches in the tree of life—the stems leading to bacteria and tion machinery that are considered essential for cellular life5. -

Toxicity, Physiological, and Ultrastructural Effects of Arsenic
International Journal of Environmental Research and Public Health Article Toxicity, Physiological, and Ultrastructural Effects of Arsenic and Cadmium on the Extremophilic Microalga Chlamydomonas acidophila Silvia Díaz 1, Patricia De Francisco 1,2, Sanna Olsson 3 , Ángeles Aguilera 2,*, Elena González-Toril 2 and Ana Martín-González 1 1 Department of Genetics, Physiology and Microbiology, Faculty of Biology, Universidad Complutense de Madrid (UCM), C/José Antonio Novais, 12, 28040 Madrid, Spain; [email protected] (S.D.); [email protected] (P.d.F.); [email protected] (A.M.-G.) 2 Astrobiology Center (INTA-CSIC), Carretera de Ajalvir km 4, Torrejón de Ardoz, 28850 Madrid, Spain; [email protected] 3 Department of Forest Ecology and Genetics, INIA Forest Research Center (INIA-CIFOR), Carretera de A Coruña km 7.5, 28040 Madrid, Spain; sanna.olsson@helsinki.fi * Correspondence: [email protected]; Tel.: +34-91-520-6434 Received: 17 December 2019; Accepted: 24 February 2020; Published: 3 March 2020 Abstract: The cytotoxicity of cadmium (Cd), arsenate (As(V)), and arsenite (As(III)) on a strain of Chlamydomonas acidophila, isolated from the Rio Tinto, an acidic environment containing high metal(l)oid concentrations, was analyzed. We used a broad array of methods to produce complementary information: cell viability and reactive oxygen species (ROS) generation measures, ultrastructural observations, transmission electron microscopy energy dispersive x-ray microanalysis (TEM–XEDS), and gene expression. This acidophilic microorganism was affected differently by the tested metal/metalloid: It showed high resistance to arsenic while Cd was the most toxic heavy metal, showing an LC50 = 1.94 µM. -

Deconstruction of Lignin: from Enzymes to Microorganisms
molecules Review Deconstruction of Lignin: From Enzymes to Microorganisms Jéssica P. Silva 1, Alonso R. P. Ticona 1 , Pedro R. V. Hamann 1, Betania F. Quirino 2 and Eliane F. Noronha 1,* 1 Enzymology Laboratory, Cell Biology Department, University of Brasilia, 70910-900 Brasília, Brazil; [email protected] (J.P.S.); [email protected] (A.R.P.T.); [email protected] (P.R.V.H.) 2 Genetics and Biotechnology Laboratory, Embrapa-Agroenergy, 70770-901 Brasília, Brazil; [email protected] * Correspondence: [email protected]; Tel.: +55-61-3307-2152 Abstract: Lignocellulosic residues are low-cost abundant feedstocks that can be used for industrial applications. However, their recalcitrance currently makes lignocellulose use limited. In natural environments, microbial communities can completely deconstruct lignocellulose by synergistic action of a set of enzymes and proteins. Microbial degradation of lignin by fungi, important lignin degraders in nature, has been intensively studied. More recently, bacteria have also been described as able to break down lignin, and to have a central role in recycling this plant polymer. Nevertheless, bacterial deconstruction of lignin has not been fully elucidated yet. Direct analysis of environmental samples using metagenomics, metatranscriptomics, and metaproteomics approaches is a powerful strategy to describe/discover enzymes, metabolic pathways, and microorganisms involved in lignin breakdown. Indeed, the use of these complementary techniques leads to a better understanding of the composition, function, and dynamics of microbial communities involved in lignin deconstruction. We focus on omics approaches and their contribution to the discovery of new enzymes and reactions that impact the development of lignin-based bioprocesses. -

Evolution of the 3-Hydroxypropionate Bicycle and Recent Transfer of Anoxygenic Photosynthesis Into the Chloroflexi
Evolution of the 3-hydroxypropionate bicycle and recent transfer of anoxygenic photosynthesis into the Chloroflexi Patrick M. Shiha,b,1, Lewis M. Wardc, and Woodward W. Fischerc,1 aFeedstocks Division, Joint BioEnergy Institute, Emeryville, CA 94608; bEnvironmental Genomics and Systems Biology Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720; and cDivision of Geological and Planetary Sciences, California Institute of Technology, Pasadena, CA 91125 Edited by Bob B. Buchanan, University of California, Berkeley, CA, and approved August 21, 2017 (received for review June 14, 2017) Various lines of evidence from both comparative biology and the provide a hard geological constraint on these analyses, the timing geologic record make it clear that the biochemical machinery for of these evolutionary events remains relative, thus highlighting anoxygenic photosynthesis was present on early Earth and provided the uncertainty in our understanding of when and how anoxy- the evolutionary stock from which oxygenic photosynthesis evolved genic photosynthesis may have originated. ca. 2.3 billion years ago. However, the taxonomic identity of these A less recognized alternative is that anoxygenic photosynthesis early anoxygenic phototrophs is uncertain, including whether or not might have been acquired in modern bacterial clades relatively they remain extant. Several phototrophic bacterial clades are thought recently. This possibility is supported by the observation that to have evolved before oxygenic photosynthesis emerged, including anoxygenic photosynthesis often sits within a derived position in the Chloroflexi, a phylum common across a wide range of modern the phyla in which it is found (3). Moreover, it is increasingly environments. Although Chloroflexi have traditionally been thought being recognized that horizontal gene transfer (HGT) has likely to be an ancient phototrophic lineage, genomics has revealed a much played a major role in the distribution of phototrophy (8–10). -

Insights Into Archaeal Evolution and Symbiosis from the Genomes of a Nanoarchaeon and Its Inferred Crenarchaeal Host from Obsidian Pool, Yellowstone National Park
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Microbiology Publications and Other Works Microbiology 4-22-2013 Insights into archaeal evolution and symbiosis from the genomes of a nanoarchaeon and its inferred crenarchaeal host from Obsidian Pool, Yellowstone National Park Mircea Podar University of Tennessee - Knoxville, [email protected] Kira S. Makarova National Institutes of Health David E. Graham University of Tennessee - Knoxville, [email protected] Yuri I. Wolf National Institutes of Health Eugene V. Koonin National Institutes of Health See next page for additional authors Follow this and additional works at: https://trace.tennessee.edu/utk_micrpubs Part of the Microbiology Commons Recommended Citation Biology Direct 2013, 8:9 doi:10.1186/1745-6150-8-9 This Article is brought to you for free and open access by the Microbiology at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Microbiology Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Authors Mircea Podar, Kira S. Makarova, David E. Graham, Yuri I. Wolf, Eugene V. Koonin, and Anna-Louise Reysenbach This article is available at TRACE: Tennessee Research and Creative Exchange: https://trace.tennessee.edu/ utk_micrpubs/44 Podar et al. Biology Direct 2013, 8:9 http://www.biology-direct.com/content/8/1/9 RESEARCH Open Access Insights into archaeal evolution and symbiosis from the genomes of a nanoarchaeon and its inferred crenarchaeal host from Obsidian Pool, Yellowstone National Park Mircea Podar1,2*, Kira S Makarova3, David E Graham1,2, Yuri I Wolf3, Eugene V Koonin3 and Anna-Louise Reysenbach4 Abstract Background: A single cultured marine organism, Nanoarchaeum equitans, represents the Nanoarchaeota branch of symbiotic Archaea, with a highly reduced genome and unusual features such as multiple split genes. -

Novel Insights Into the Thaumarchaeota in the Deepest Oceans: Their Metabolism and Potential Adaptation Mechanisms
Zhong et al. Microbiome (2020) 8:78 https://doi.org/10.1186/s40168-020-00849-2 RESEARCH Open Access Novel insights into the Thaumarchaeota in the deepest oceans: their metabolism and potential adaptation mechanisms Haohui Zhong1,2, Laura Lehtovirta-Morley3, Jiwen Liu1,2, Yanfen Zheng1, Heyu Lin1, Delei Song1, Jonathan D. Todd3, Jiwei Tian4 and Xiao-Hua Zhang1,2,5* Abstract Background: Marine Group I (MGI) Thaumarchaeota, which play key roles in the global biogeochemical cycling of nitrogen and carbon (ammonia oxidizers), thrive in the aphotic deep sea with massive populations. Recent studies have revealed that MGI Thaumarchaeota were present in the deepest part of oceans—the hadal zone (depth > 6000 m, consisting almost entirely of trenches), with the predominant phylotype being distinct from that in the “shallower” deep sea. However, little is known about the metabolism and distribution of these ammonia oxidizers in the hadal water. Results: In this study, metagenomic data were obtained from 0–10,500 m deep seawater samples from the Mariana Trench. The distribution patterns of Thaumarchaeota derived from metagenomics and 16S rRNA gene sequencing were in line with that reported in previous studies: abundance of Thaumarchaeota peaked in bathypelagic zone (depth 1000–4000 m) and the predominant clade shifted in the hadal zone. Several metagenome-assembled thaumarchaeotal genomes were recovered, including a near-complete one representing the dominant hadal phylotype of MGI. Using comparative genomics, we predict that unexpected genes involved in bioenergetics, including two distinct ATP synthase genes (predicted to be coupled with H+ and Na+ respectively), and genes horizontally transferred from other extremophiles, such as those encoding putative di-myo-inositol-phosphate (DIP) synthases, might significantly contribute to the success of this hadal clade under the extreme condition. -

Coursework Declaration and Feedback Form
Coursework Declaration and Feedback Form The Student should complete and sign this part Student Student Number: Name: Programme of Study (e.g. MSc in Electronics and Electrical Engineering): Course Code: ENG5059P Course Name: MSc Project Name of Name of First Supervisor: Second Supervisor: Title of Project: Declaration of Originality and Submission Information I affirm that this submission is all my own work in accordance with the University of Glasgow Regulations and the School of Engineering E N G 5 0 5 9 P requirements Signed (Student) : Date of Submission : Feedback from Lecturer to Student – to be completed by Lecturer or Demonstrator Grade Awarded: Feedback (as appropriate to the coursework which was assessed): Lecturer/Demonstrator: Date returned to the Teaching Office: Whole Genome Analysis of Nitrifying Bacteria in Construction and the Built Environment Student Name: Kaung Sett Student ID: 2603933 Supervisor Name: Dr Umer Zeeshan Ijaz Co-supervisor Name: Dr Ciara Keating August 2021 A thesis submitted in partial FulFilment oF the requirements For the degree oF MASTER OF SCIENCE IN CIVIL ENGINEERING ACKNOWLEDGEMENT First and foremost, the author would like to acknowledge his supervisors, Dr. Umer Zeeshan Ijaz and Dr Ciara Keating, for giving him this opportunity and their invaluable technological ideas, thoroughly bioinformatics and environmental concepts for this project during its preparation, analysis and giving their supervision on his project. Next, the author desires to express his deepest gratitude to University of Glasgow for providing this opportunity to improve his knowledge and skills. Then, the author deeply appreciated to his parents for their continuous love, financial support, and encouragement throughout his entire life. -

Alternative Strategies of Nutrient Acquisition and Energy Conservation Map to the Biogeography of Marine Ammonia- Oxidizing Archaea
The ISME Journal (2020) 14:2595–2609 https://doi.org/10.1038/s41396-020-0710-7 ARTICLE Alternative strategies of nutrient acquisition and energy conservation map to the biogeography of marine ammonia- oxidizing archaea 1 2,3 2,3 4 5 6 Wei Qin ● Yue Zheng ● Feng Zhao ● Yulin Wang ● Hidetoshi Urakawa ● Willm Martens-Habbena ● 7 8 9 10 11 12 Haodong Liu ● Xiaowu Huang ● Xinxu Zhang ● Tatsunori Nakagawa ● Daniel R. Mende ● Annette Bollmann ● 13 14 15 16 17 10 Baozhan Wang ● Yao Zhang ● Shady A. Amin ● Jeppe L. Nielsen ● Koji Mori ● Reiji Takahashi ● 1 18 11 9 19,8 E. Virginia Armbrust ● Mari-K.H. Winkler ● Edward F. DeLong ● Meng Li ● Po-Heng Lee ● 20,21,22 7 4 18 1 Jizhong Zhou ● Chuanlun Zhang ● Tong Zhang ● David A. Stahl ● Anitra E. Ingalls Received: 15 February 2020 / Revised: 16 June 2020 / Accepted: 25 June 2020 / Published online: 7 July 2020 © The Author(s) 2020. This article is published with open access Abstract Ammonia-oxidizing archaea (AOA) are among the most abundant and ubiquitous microorganisms in the ocean, exerting primary control on nitrification and nitrogen oxides emission. Although united by a common physiology of 1234567890();,: 1234567890();,: chemoautotrophic growth on ammonia, a corresponding high genomic and habitat variability suggests tremendous adaptive capacity. Here, we compared 44 diverse AOA genomes, 37 from species cultivated from samples collected across diverse geographic locations and seven assembled from metagenomic sequences from the mesopelagic to hadopelagic zones of the deep ocean. Comparative analysis identified seven major marine AOA genotypic groups having gene content correlated with their distinctive biogeographies.