LINKED OPEN DATA for MEMORY INSTITUTIONS: IMPLEMENTATION HANDBOOK YEAH! Project Deliverable No: 3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Soviet Housing Construction in Tartu: the Era of Mass Construction (1960 - 1991)
University of Tartu Faculty of Science and Technology Institute of Ecology and Earth Sciences Department of Geography Master thesis in human geography Soviet Housing Construction in Tartu: The Era of Mass Construction (1960 - 1991) Sille Sommer Supervisors: Michael Gentile, PhD Kadri Leetmaa, PhD Kaitsmisele lubatud: Juhendaja: /allkiri, kuupäev/ Juhendaja: /allkiri, kuupäev/ Osakonna juhataja: /allkiri, kuupäev/ Tartu 2012 Contents Introduction ......................................................................................................................................... 3 Literature review ................................................................................................................................. 5 Housing development in the socialist states .................................................................................... 5 From World War I until the 1950s .............................................................................................. 5 From the 1950s until the collapse of the Soviet Union ............................................................... 6 Socio-economic differentiations in the socialist residential areas ................................................... 8 Different types of housing ......................................................................................................... 11 The housing estates in the socialist city .................................................................................... 13 Industrial control and priority sectors .......................................................................................... -

1 Estonian University of Life Sciences Kreutzwaldi 1
ESTONIAN LANGUAGE AND CULTURE COURSE (ESTILC) 2018/2019 ORGANISING INSTITUTION ’S INFORMATION FORM NAME OF THE INSTITUTION : ESTONIAN UNIVERSITY OF LIFE SCIENCES ADDRESS : KREUTZWALDI 1, TARTU COUNTRY : ESTONIA ESTILC LANGUAGE LEVEL COURSES ORGANISED: LEVEL I (BEGINNER ) X LEVEL II (INTERMEDIATE ) NUMBER OF COURSES : 1 NUMBER OF COURSES : DATES : 08.08-24.08.2018 DATES : WEB SITE HTTPS :// WWW .EMU .EE /EN /ADMISSION S/EXCHANGE -STUDIES /ERASMUS / PLEASE NOTE THAT ALL STUDENT APPLICATIONS FOR OUR ESTILC COURSE SHOULD BE SENT BY E -MAIL TO THE FOLLOWING ADDRESS : APPLICATION DEADLINE 31.05.2018 STAFF JOB TITLE / NAME ADDRESS , TELEPHONE , FAX , E-MAIL CONTACT PERSON ESTONIAN UNIVERSITY OF LIFE SCIENCES FOR ESTILC KREUTZWALDI 56/1, 51014 TARTU /E STONIA LIISI VESKE PHONE : +372 731 3174 JOB TITLE FAX : +372 731 3037 PROGRAMME COORDINATOR E-MAIL : LIISI .V ESKE @EMU .EE ESTONIAN UNIVERSITY OF LIFE SCIENCES KREUTZWALDI 56/1, 51014 TARTU /E STONIA RESPONSIBLE PERSON FOR THE PROGRAMME PHONE : +372 731 3174 FAX : +372 731 3037 LIISI VESKE E-MAIL : LIISI .V ESKE @EMU .EE PART I: GENERAL INFORMATION • DESCRIPTION OF TOWN - SHORT HISTORY AND LOCATION 1 Tartu is the second largest city of Estonia. Tartu is located 185 kilometres to south from the capital Tallinn. Tartu is known also as the centre of Southern Estonia. The Emajõgi River, which connects the two largest lakes (Võrtsjärv and Peipsi) of Estonia, flows for the length of 10 kilometres within the city limits and adds colour to the city. As Tartu has been under control of various rulers throughout its history, there are various names for the city in different languages. -

Mitte-Tartutu
MitteMitte-Tarttuu Mitte-Tartu Mitte-Tartu TOPOFON Koostanud ja toimetanud Sven Vabar Kujundanud Mari Ainso Pildistanud Kaja Pae Mitte-Tartu tänab: Eesti Kultuurkapitali, Tartu Kultuurkapitali, kirjandusfestivali Prima Vista ja Eesti Kirjanike Liidu Tartu osakonda © Autorid Topofon, 2012 Tartu ISBN 978-9949-30-404-2 Trükkinud AS Ecoprint Sisukord Sven Vabar Eessõna 6 Anti Saar Ernst 16 Berk Vaher Baltijos Cirkas 28 Joanna Ellmann maa-alused väljad 38 Maarja Pärtna 48 Kaja Pae 10π 58 Aare Pilv Servad 74 Tanel Rander Odessa või São Paulo? 90 Meelis Friedenthal Kass 100 Lauri Pilter Rälby ja Tarby 114 c: Teekond põllule 132 Erkki Luuk NÕIUTUD X 142 Tanel Rander Jõgi ja jõerahvas 156 Kiwa t-st 168 Mehis Heinsaar Kuusteist vaikuse aastat 190 Sven Vabar Tartu kaks lagendikku 200 Sven Vabar Tänavakunstnikud 212 Jaak Tomberg Faddei Bulgarini kümme soont 234 andreas w blade runner : jooksja mõõgateral 288 Mehis Heinsaar Ta on valmis ja ootel 302 5 Sven Vabar Eessõna Werneri kohvik, kevad/sügis-hooajaline Toomemägi, kirjanduslik Kar- lova, Supilinn oma aguliromantikaga. Neist kohtadest käesolevas raa- matus juttu ei tule. See kõik on Tartu. Mitte-Tartu on mujal. Hiinalinn oma hämara, postmilitaristliku elanikkonnaga ja määratu garaaživo- hanguga sealsamas kõrval. Raadi lennuväli. Annelinn. Aardla-kandi tühermaad ja Võru maantee äärsed põllupealsed uusarendused. Luhad. Ühe Turu tänava autopesula külge ehitatud igavikuline hamburgeri- putka, kus on tunda Jumala ligiolekut. Küütri tänava metroopeatus. Emajõgi küll, aga pigem jõepõhja muda ühes kõige seal leiduvaga. Supilinn küll, aga üks hoopis teistsugune Supilinn. Tõsi, piir Tartu ja Mitte-Tartu vahel on kohati hämar ja hägune nagu Mitte-Tartu isegi. Humanitaarteadustes tähistab „mitte-koht“ tavaliselt prantsuse antropoloogi Marc Augé poolt kasutusele võetud terminit. -

Programme Handbook 1
Tartu, Estonia 8 - 10 August 2017 Programme handbook 1 Contents Programme ............................................................................................................................................. 2 Abstracts ................................................................................................................................................. 6 Invited speakers .................................................................................................................................. 6 Participants ....................................................................................................................................... 17 Practical information ............................................................................................................................ 38 Directions .............................................................................................................................................. 44 Contacts of local organizers .................................................................................................................. 46 Maps of Tartu ........................................................................................................................................ 47 Programme Monday, August 7th 16:00 – 20:00 Registration of participants Estonian Biocentre, Riia 23b 20:00 – 22:00 Welcome reception & BBQ Vilde Ja Vine restaurant, Vallikraavi 4 Tuesday, August 8th 08:45 – 09:35 Registration of participants Estonian Biocentre, Riia 23b 9:35 -

Sõprade Sõit” on Tartu Linna Ja Linnaümbruse Kergliiklusteedel Toimuv Ühine Spordisõit Valitud Tempogruppides, Kas 32Km Või 54Km Pikkusel Rajal
II SOPRADE~ SOIT~ 1.OKTOOBER2017 32KM/54KM RULLSUUSKADE JA UISKUDEGA ~ .. - - , TOUKE- JA JALGRATASTEGA UMBER TERVE TARTU www.SuusaAkadeemia.ee MIS ON SOPRADE~ SOIT~ “II Terve Tartu Sõprade Sõit” on Tartu linna ja linnaümbruse kergliiklusteedel toimuv ühine spordisõit valitud tempogruppides, kas 32km või 54km pikkusel rajal. Osaleda võib rullsuuskade-, rulluiskude-, tõukeratta- või jalgrattaga. Ühisstart sõidule on 1.oktoobril 2017 kell 11:00 Tartu kesklinnas. Tegemist ei ole võistlusega, vaid ühissõiduga, kuid osalejad saavad teada oma distantsi läbimise aja. Raja pikkus on valikuliselt, kas 32km või 54km ning valida saab järgnevate tempogruppide vahel: 32KM TEMPO SOOVITUSLIKULT Rahulik ~10km/h rullsuusk Mõõdukas ~12km/h rullsuusk, -uisk, (tõuke)ratas 54KM Rahulik ~12km/h rullsuusk, tõukeratas Mõõdukas ~15km/h rullsuusk, -uisk, (tõuke)ratas Kiire ~20-25km/h rulluisk ja jalgratas II SOPRADE~ SOIT~ www.SuusaAkadeemia.ee RADA 32KM/54KM II VAHI 14km START ja FINIŠ: KÜÜNI TÄNAV III I LOUNAKAS IHASTE 14km IV 14km ROPKA 12km KM I IHASTE RING 14km: KESKLINN - ANNELINN - LOHKVA - IHASTE - A.LE COQ SPORT 54 II VAHI 14km ANNE KANAL - ROOSI - ERM - VAHI - KVISSENTALI - TÜ SPORDIHALL III LÕUNAKESKUS 14km: SUPILINN - TOOMEMÄGI- LÕUNAKESKUS - RAUDTEE - TAMME STAADION IV ROPKA 12km: RAUDTEE - RINGTEE - VANGLA - SIILI - SÕPRUSE - ANNE KANAL - FINIŠ KM I IHASTE RING 14km: KESKLINN - ANNELINN - LOHKVA - IHASTE - A.LE COQ SPORT 32 II VAHI 14km ANNE KANAL - ROOSI - ERM - VAHI - KVISSENTALI - TÜ SPORDIHALL III LÕUNAKESKUS 4km: SUPILINN - JAKOBI MÄGI - FINIŠ www.SuusaAkadeemia.ee OSALEJALE PARKIMINE Kasutada turuhoone, Vabaduse tn, Poe tn, Tartu Kaubamaja, Ülikooli tn parkimisalasid START JA PAKIHOID Start “II Terve Tartu Sõprade Sõidule” on 1.oktoobril 2017 kell 11:00. -
![Urban Energy Planning in Tartu [PLEEC Report D4.2 / Tartu] Große, Juliane; Groth, Niels Boje; Fertner, Christian; Tamm, Jaanus; Alev, Kaspar](https://docslib.b-cdn.net/cover/3273/urban-energy-planning-in-tartu-pleec-report-d4-2-tartu-gro%C3%9Fe-juliane-groth-niels-boje-fertner-christian-tamm-jaanus-alev-kaspar-1533273.webp)
Urban Energy Planning in Tartu [PLEEC Report D4.2 / Tartu] Große, Juliane; Groth, Niels Boje; Fertner, Christian; Tamm, Jaanus; Alev, Kaspar
Urban energy planning in Tartu [PLEEC Report D4.2 / Tartu] Große, Juliane; Groth, Niels Boje; Fertner, Christian; Tamm, Jaanus; Alev, Kaspar Publication date: 2015 Document version Publisher's PDF, also known as Version of record Citation for published version (APA): Große, J., Groth, N. B., Fertner, C., Tamm, J., & Alev, K. (2015). Urban energy planning in Tartu: [PLEEC Report D4.2 / Tartu]. EU-FP7 project PLEEC. http://pleecproject.eu/results/documents/viewdownload/131-work- package-4/579-d4-2-urban-energy-planning-in-tartu.html Download date: 29. Sep. 2021 Deliverable 4.2 / Tartu Urban energy planning in Tartu 20 January 2015 Juliane Große (UCPH) Niels Boje Groth (UCPH) Christian Fertner (UCPH) Jaanus Tamm (City of Tartu) Kaspar Alev (City of Tartu) Abstract Main aim of report The purpose of Deliverable 4.2 is to give an overview of urban en‐ ergy planning in the 6 PLEEC partner cities. The 6 reports il‐ lustrate how cities deal with dif‐ ferent challenges of the urban energy transformation from a structural perspective including issues of urban governance and spatial planning. The 6 reports will provide input for the follow‐ WP4 location in PLEEC project ing cross‐thematic report (D4.3). Target group The main addressee is the WP4‐team (universities and cities) who will work on the cross‐ thematic report (D4.3). The reports will also support a learning process between the cities. Further, they are relevant for a wider group of PLEEC partners to discuss the relationship between the three pillars (technology, structure, behaviour) in each of the cities. Main findings/conclusions The Estonian planning system allots the main responsibilities for planning activities to the local level, whereas the regional level (county) is rather weak. -

The Perceivable Landscape a Theoretical-Methodological Approach to Landscape
THE PERCEIVABLE LANDSCAPE A THEORETICAL-METHODOLOGICAL APPROACH TO LANDSCAPE TAJUTAV MAASTIK TEOREETILIS-METODOLOOGILINE KÄSITLUS MAASTIKUST NELE NUTT A Thesis for applying for the degree of Doctor of Philosophy in Landscape Architecture Väitekiri filosoofiadoktori kraadi taotlemiseks maastikuarhitektuuri erialal Tartu 2017 Eesti Maaülikooli doktoritööd Doctoral Theses of the Estonian University of Life Sciences THE PERCEIVABLE LANDSCAPE A THEORETICAL-METHODOLOGICAL APPROACH TO LANDSCAPE TAJUTAV MAASTIK TEOREETILIS-METODOLOOGILINE KÄSITLUS MAASTIKUST NELE NUTT A Thesis for applying for the degree of Doctor of Philosophy in Landscape Architecture Väitekiri filosoofiadoktori kraadi taotlemiseks maastikuarhitektuuri erialal Tartu 2017 Institute of Agricultural and Environmental Sciences Estonian University of Life Sciences According to the verdict No 6-14/3-8 of April 28, 2017, the Doctoral Commitee for Environmental Sciences and Applied Biology of the Estonian University of Life Sciences has accepted the thesis for the defence of the degree of Doctor of Philosophy in Landscape Architecture. Opponent: Kati Lindström, PhD KTH Royal Institute of Technology, Sweden Pre-opponent: Prof Lilian Hansar, PhD Estonian Academy of Arts, Estonia Supervisors: Prof Juhan Maiste, PhD University of Tartu, Estonia Prof Zenia Kotval, PhD Michigan State University, USA Tallinn University of Technology Tartu College, Estonia Consultant: Prof Kalev Sepp, PhD Estonian University of Life Sciences, Estonia Defence of the thesis: Estonian University of Life Sciences, room Kreutzwaldi St. 5-1A5, Tartu on June 15, 2017, at 11:15 a.m. The English text in the thesis has been revised by Juta Ristsoo and the Estonian by Jane Tiidelepp. © Nele Nutt 2017 ISSN 2382-7076 ISBN 978-9949-569-79-3 (publication) ISBN 978-9949-569-80-9 (PDF) 4 CONTENTS LIST OF ORIGINAL PUBLICATIONS .................................................6 FOREWORD .................................................................................................8 1. -

A Selection of Master Theses from 20131
ESTONIAN URBANISTS' REVIEW 14 IN ACADEMY IN ACADEMY The column "In Academy" gathers a selection of master theses on urban issues defended in spring 2013. In addition to urban studies, urban governance and architecture, urban issues are relevant for study programs from varied fields, both humanities and sciences – therefore we don't dare to claim that the list is in any way complete. But it is certain that our job market will be opened to a quite impressive number of people who are thinking about cities. Following our intuition we chose some authors to give a closer overview of their thesis. The following texts are seeds, first insights to the works and themes. A SELECTION OF MASTER THESES FROM 20131 1. titles in University of Tallinn Estonian Academy of Arts English as used by the authors. URBAN GOVERNANCE URBAN STUDIES Epp Vahtramäe. Socio-cultural impacts of former indus- Siri Emert. Public Art and the Public. Public Art trial area revitalization on the surrounding urban space: in the context of ECoC the case of Telliskivi Loomelinnak Regina Viljasaar. Initiative “Mustamäe synthesis”: Mart Uusjärv. Changes and Social Impacts Arising from Systemic change through collaborative planning High-Rise Buildings in the Tallinn Maakri District Ulla Männi. Facing Fears in Tallinn Airi Purge. The importance of public transport travel experience in assuring city region mobility: the case of Kaija-Luisa Kurik. Critical Approach to Temporary Urban- Tartu–Koidula–Tartu passenger railway line ism, Temporary Use and the Idea of Temporary in a City SOCIOLOGY Sander Tint. Re-framing Soodevahe, re-framing urban agriculture Liisa Müürsepp. -

Kirjanduslinn Tartu Kaart
Emajõe 29. Kirjandusega seotud paigad Sündmused ja projektid Raamatukogud Raamatupoed 33. 1. Tartu Kirjanduse Maja (Vanemuise 19): Kirjandusfestival Prima Vista: 25. Tartu Oskar Lutsu nimelise Tartu Lõunakeskuse Apollo Kirjanduslinna keskus, kus tegutsevad Eesti mai alguses üle terve linna Kroonuaia sild linnaraamatukogu keskkogu Ringtee 75 Kirjanike Liidu Tartu osakond, Eesti Kirjanduse Kompanii 3/5 E–P 10–21 Rahvusvaheline interdistsiplinaarne festival Oa E–R 9–20, L 10–16 [email protected] Selts, kirjastus Ilmamaa, ajakiri Värske Rõhk, 11. raamatupood Utoopia ning kultuuribaar Arhiiv; „Hullunud Tartu“: igal aastal novembris [email protected] tel 633 6020 (E–R 9–17) Herne tel 736 1380 Narva mnt. 2. Kohvik Werner (Ülikooli 11): üks Eesti vanemaid Luuleprõmmude sari TarSlämm: septembrist 34. Tartu Kaubamaja Apollo kohvikuid, millest kujunes töötegemis- ja ajaveetmis- aprillini kord kuus neljapäeviti kultuuribaaris Arhiiv 26. Linnaraamatukogu Annelinna harukogu Riia 1 paik paljudele Eesti haritlastele, teiste seas luuletaja Kaunase pst 23 E–L 9–21, P 10–19 Vene kirjanduse ja kultuuri nädal: sügiseti E–R 9–20, L 10–16 [email protected] Artur Alliksaarele. On tegevuspaigaks ka Madis Kõivu Vabaduse sild näidendis "Lõputu kohvijoomine"; Tartu linnaraamatukogus tel 746 1040 tel 633 6020 (E-R 9–17) Botaanikaaed Kroonuaia Kirjanduslikud teisipäevad: sügisest kevadeni 27. Linnaraamatukogu Karlova-Ropka harukogu 35. Tasku Keskuse Rahva Raamat 3. Ülikooli kohvik (Ülikooli 20): Tartu spontaanse Mäe kirjanduselu keskus 1960. ja 1970. aastatel. Tartu Kirjanduse Majas Tehase 16 Turu 2 Sissekäigu ees asuv mälestuskivi tähistab Eesti E–R 10–19, L 10–16 E–L 10–21, P 10–18 vanima, 1631 rajatud trükikoja asukohta; Tartu Linnaraamatukogu kirjanduskohvik: [email protected] [email protected] iga kuu viimasel neljapäeval tel 730 8473 tel 671 3659 Kloostri 4. -

From Slumming to Gentrification
RISEN FROM THE DEAD: FROM SLUMMING TO GENTRIFICATION Mart HIOB Nele NUTT Sulev NURME Fransesco DE LUCA Mart HIOB (corresponding author) Lecturer, Department of Landscape Architecture, Tallinn University of Technology, Tartu College, Estonia Abstract Tel.: 0037-2-501.4767 Political tides are evident in most community E-mail: [email protected] development practices. Sometimes it hinders good planning while at other times it aides development, Nele NUTT and sometimes the unintended consequences Lecturer, Department of Landscape Architecture, of politics preserve neighborhoods for a long Tallinn University of Technology, Tartu College, Estonia time, allowing for a totally different development outcome. This article is a detailed case study of Sulev NURME one such neighborhood. This neighborhood, known Lecturer, Department of Landscape Architecture, as Supilinn, in Tartu Estonia was a rundown area Tallinn University of Technology, Tartu College, Estonia slated for total demolition during Soviet occupation. Due to the lack of finances and low priorities, the Fransesco DE LUCA former communist regime abandoned the idea of Lecturer, Department of Landscape Architecture, demolition and left the neighborhood to deteriorate Tallinn University of Technology, Tartu College, Estonia further. Two decades later, Supilinn is a bustling community where young and old, rich and poor, existing and new, all co-exist. A community left to die has resurrected itself through bottom up planning and citizen initiatives to become one of the preferred places to live, so much so that the neighborhood now faces the threat of gentrification with social displacement and complete renewal. The authors, all active members in this neighborhood, have lived and worked there for a while. -

July 2016 World Orienteering Championships 2017 Tartu
BULLETIN 2 July 2016 World Orienteering Championships 2017 Tartu - Estonia 30.06.-07.07.2017 WELCOME TO ESTONIA! I am glad to welcome you to Estonia to attend the World Orienteering Championships in Tartu. I would encourage you to discover more of the cosiest country and our p rettiest countryside with only 1.3 million inhabitants and 45 thousand squre kilometres of land. Some call Estonia the smartest country as it produces more start-ups per capita than any other country in Europe. Our small country has become the best in e-democracy and e-government, being the first in the world to introduce online political voting. Needless to say, there is a WiFi-net that covers nearly all of the territory. Estonians have an identity card that allows us to access over 1,000 public services online, like healthcare and paying taxes. Being one of the most digitally advanced nations in the world, we decided to start the e-residency project and letting people from around the world become digital residents of Estonia online. Here you can start a new company online fastest, just in under 20 minutes. We love innovation but we value our roots. Estonians have one of the biggest collections of folk songs in the world, with written records of 133,000 folk songs. Our capital Tallinn is the best preserved medieval city in Northern Eu- rope. You might say Estonia is also the greenest country as forests cover about 50% of the territory, or around 2 million hectares. It is one of the most sparsely populated countries in Europe, but there are over 2,000 islands, 1,000 lakes and 7,000 rivers. -
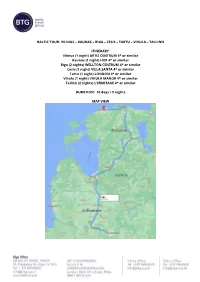
Riga – Cesis – Tartu – Vihula – Tallinn
BALTIC TOUR: VILNIUS – KAUNAS – RIGA – CESIS – TARTU – VIHULA – TALLINN ITINERARY: Vilnius (1 night) ARTIS CENTRUM 4* or similar Kaunas (1 night) HOF 4* or similar Riga (2 nights) WELLTON CENTRUM 4* or similar Cesis (1 night) VILLA SANTA 4* or similar Tartu (1 night) LONDON 4* or similar Vihula (1 night) VIHULA MANOR 4* or similar Tallinn (2 nights) L’ERMITAGE 4* or similar DURATION: 10 days / 9 nights MAP VIEW Period: season 2021 Package price per person in DBL/TWIN room: 500 EUR Price per person in SGL room: 920 EUR Price includes accommodation 9 nights including breakfast Rent a car offer: 450 EUR Skoda Fabia or similar (Car group B) Rental duration: 10 days Basic cover: - Local Tax (TAX) - Collision Damage Waiver* (CDW) - Theft Protection (TP) - Airport/city/other surcharge - One way fee - Unlimited Mileage/Km's Day 1: Vilnius Arrival in Vilnius. Optional transfer or rent a car in Vilnius airport. Private car with driver 26 EUR Overnight at the hotel. Day 2: Vilnius – Trakai – Kaunas (100 km) Breakfast at the hotel Optional: Vilnius Sightseeing tour (3 hours) Vilnius Old Town is located on the left bank of the Neris River south of Castle Hill, developed over the centuries absorbed the various cultural trends and today recognized by UNESCO as the largest historic architectural complex in Eastern Europe. In the old town you can see the Gediminas Castle. Today, tourists can explore the west tower, the remains of the ramparts and the castle itself. Near the castle is the Cathedral Square, where you can see the hero of Vilnius - Grand Duke Gediminas.