Pdfwm-2017-18-Tam-44286/(Sa-Ii)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
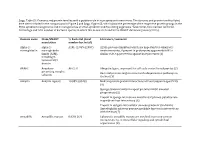
Supp. Table S2: Domains and Protein Families with a Putative Role in Host-Symbiont Interactions
Supp. Table S2: Domains and protein families with a putative role in host-symbiont interactions. The domains and protein families listed here were included in the comparisons in Figure 5 and Supp. Figure S5, which show the percentage of the respective protein groups in the Riftia symbiont metagenome and in metagenomes of other symbiotic and free-living organisms. % bacterial, total number bacterial: Percentage and total number of bacterial species in which this domain is found in the SMART database (January 2019). Domain name Pfam/SMART % bacterial (total Literature/comment annotation number bacterial) Alpha-2- alpha-2- A2M: 42.05% (2057) A2Ms: protease inhibitors which are important for eukaryotic macroglobulin macroglobulin innate immunity, if present in prokaryotes apparently fulfill a family (A2M), similar role, e.g. protection against host proteases (1) including N- terminal MG1 domain ANAPC Anaphase- APC2: 0 Ubiquitin ligase, important for cell cycle control in eukaryotes (2) promoting complex Bacterial proteins might interact with ubiquitination pathways in subunits the host (3) Ankyrin Ankyrin repeats 10.88% (8348) Mediate protein-protein interactions without sequence specificity (4) Sponge symbiont ankyrin-repeat proteins inhibit amoebal phagocytosis (5) Present in sponge microbiome metatranscriptomes, putative role in symbiont-host interactions (6) Present in obligate intracellular amoeba symbiont Candidatus Amoebophilus asiaticus genome, probable function in interactions with the host (7) Armadillo Armadillo repeats 0.83% (67) -

A Gene Co-Expression Network Model Identifies Yield-Related Vicinity
www.nature.com/scientificreports OPEN A gene co-expression network model identifes yield-related vicinity networks in Jatropha curcas Received: 7 February 2018 Accepted: 4 June 2018 shoot system Published: xx xx xxxx Nisha Govender1,2, Siju Senan1, Zeti-Azura Mohamed-Hussein2,3 & Ratnam Wickneswari1 The plant shoot system consists of reproductive organs such as inforescences, buds and fruits, and the vegetative leaves and stems. In this study, the reproductive part of the Jatropha curcas shoot system, which includes the aerial shoots, shoots bearing the inforescence and inforescence were investigated in regard to gene-to-gene interactions underpinning yield-related biological processes. An RNA-seq based sequencing of shoot tissues performed on an Illumina HiSeq. 2500 platform generated 18 transcriptomes. Using the reference genome-based mapping approach, a total of 64 361 genes was identifed in all samples and the data was annotated against the non-redundant database by the BLAST2GO Pro. Suite. After removing the outlier genes and samples, a total of 12 734 genes across 17 samples were subjected to gene co-expression network construction using petal, an R library. A gene co-expression network model built with scale-free and small-world properties extracted four vicinity networks (VNs) with putative involvement in yield-related biological processes as follow; heat stress tolerance, foral and shoot meristem diferentiation, biosynthesis of chlorophyll molecules and laticifers, cell wall metabolism and epigenetic regulations. Our VNs revealed putative key players that could be adapted in breeding strategies for J. curcas shoot system improvements. Jatropha curcas L. or the physic nut is an environmentally friendly and cost-efective feedstock for sustainable biofuel production. -

Non-Cellulosomal Cohesin- and Dockerin-Like Modules in the Three Domains of Life Ayelet Peera, Steven P
1 Non-cellulosomal Cohesin- and Dockerin-like Modules in the Three Domains of Life Ayelet Peera, Steven P. Smithb, Edward A. Bayerc,*, Raphael Lameda and Ilya Borovoka aDepartment of Molecular Microbiology and Biotechnology, Tel Aviv University, Ramat Aviv 69978 Israel bDepartment of Biochemistry, Queen’s University Kingston Ontario Canada K7L 3N6 cDepartment of Biological Sciences, Weizmann Institute of Science, Rehovot 76100 Israel *Corresponding author: Edward A. Bayer Tel: (+972) -8-934-2373 Fax: (+972)-8-946-8256 Email: [email protected] Supplementary Table S1. Compendium of cohesins and dockerins in the three domains of life. In order to discover new putative cohesin/dockerin-containing proteins, we used sequences of all the classical cohesin and dockerin modules from C. thermocellum, C. cellulovorans, C. cellulolyticum, B. cellulosolvens and Acetivibrio cellulolyticus as well as cohesins and dockerins recently discovered in rumen bacteria, Ruminococcus albus and R. flavefaciens as BlastP queries for the main NCBI Blast server against all non- redundant protein sequences deposited in GenBank/EMBL/DDBJ databases. We also performed extensive searches using the TblastN algorithm through all publicly available microbial genome databases including those attached to the NCBI BLAST server for bacterial genomes (http://www.ncbi.nlm.nih.gov/sutils/genom_table.cgi?), as well as several additional microbial genome databases – Microbial Genomics at the DOE Joint Genome Institute (http://genome.jgi-psf.org/mic_home.html), the Rumenomics database at TIGR/JCVI (http://tigrblast.tigr.org/rumenomics/index.cgi) and Bacterial Genomes at the Sanger Centre (http://www.sanger.ac.uk/Projects/Microbes/). Once a putative cohesin or dockerin-encoding gene product was identified, gene-walking techniques were employed to analyze and locate possible cellulosome-like gene clusters. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

STACK: a Toolkit for Analysing Β-Helix Proteins
STACK: a toolkit for analysing ¯-helix proteins Master of Science Thesis (20 points) Salvatore Cappadona, Lars Diestelhorst Abstract ¯-helix proteins contain a solenoid fold consisting of repeated coils forming parallel ¯-sheets. Our goal is to formalise the intuitive notion of a ¯-helix in an objective algorithm. Our approach is based on first identifying residues stacks — linear spatial arrangements of residues with similar conformations — and then combining these elementary patterns to form ¯-coils and ¯-helices. Our algorithm has been implemented within STACK, a toolkit for analyzing ¯-helix proteins. STACK distinguishes aromatic, aliphatic and amidic stacks such as the asparagine ladder. Geometrical features are computed and stored in a relational database. These features include the axis of the ¯-helix, the stacks, the cross-sectional shape, the area of the coils and related packing information. An interface between STACK and a molecular visualisation program enables structural features to be highlighted automatically. i Contents 1 Introduction 1 2 Biological Background 2 2.1 Basic Concepts of Protein Structure ....................... 2 2.2 Secondary Structure ................................ 2 2.3 The ¯-Helix Fold .................................. 3 3 Parallel ¯-Helices 6 3.1 Introduction ..................................... 6 3.2 Nomenclature .................................... 6 3.2.1 Parallel ¯-Helix and its ¯-Sheets ..................... 6 3.2.2 Stacks ................................... 8 3.2.3 Coils ..................................... 8 3.2.4 The Core Region .............................. 8 3.3 Description of Known Structures ......................... 8 3.3.1 Helix Handedness .............................. 8 3.3.2 Right-Handed Parallel ¯-Helices ..................... 13 3.3.3 Left-Handed Parallel ¯-Helices ...................... 19 3.4 Amyloidosis .................................... 20 4 The STACK Toolkit 24 4.1 Identification of Structural Elements ....................... 24 4.1.1 Stacks ................................... -

Armc5 Deletion Causes Developmental Defects and Compromises T-Cell Immune Responses
ARTICLE Received 26 Jan 2016 | Accepted 4 Nov 2016 | Published 7 Feb 2017 DOI: 10.1038/ncomms13834 OPEN Armc5 deletion causes developmental defects and compromises T-cell immune responses Yan Hu 1,*, Linjiang Lao1,*, Jianning Mao1, Wei Jin1, Hongyu Luo1, Tania Charpentier2, Shijie Qi1, Junzheng Peng1, Bing Hu3, Mieczyslaw Martin Marcinkiewicz4, Alain Lamarre2 & Jiangping Wu1,5 Armadillo repeat containing 5 (ARMC5) is a cytosolic protein with no enzymatic activities. Little is known about its function and mechanisms of action, except that gene mutations are associated with risks of primary macronodular adrenal gland hyperplasia. Here we map Armc5 expression by in situ hybridization, and generate Armc5 knockout mice, which are small in body size. Armc5 knockout mice have compromised T-cell proliferation and differentiation into Th1 and Th17 cells, increased T-cell apoptosis, reduced severity of experimental autoimmune encephalitis, and defective immune responses to lymphocytic choriomeningitis virus infection. These mice also develop adrenal gland hyperplasia in old age. Yeast 2-hybrid assays identify 16 ARMC5-binding partners. Together these data indicate that ARMC5 is crucial in fetal development, T-cell function and adrenal gland growth homeostasis, and that the functions of ARMC5 probably depend on interaction with multiple signalling pathways. 1 Centre de recherche (CR), Centre hospitalier de l’Universite´ de Montre´al (CHUM), 900 Rue Saint Denis, Montre´al, Que´bec, Canada H2X 0A9. 2 Institut national de la recherche scientifique—Institut Armand-Frappier (INRS-IAF), 531 Boul. des Prairies, Laval, Que´bec, Canada H7V 1B7. 3 Anatomic Pathology, AmeriPath Central Florida, 4225 Fowler Ave. Tampa, Orlando, Florida 33617, USA. -

Comprehensive Computational Analysis of Leucine-Rich Repeat (LRR) Proteins Encoded in the Genome of the Diatom Phaeodactylum Tricornutum
Erschienen in: Marine Genomics ; 21 (2015). - S. 43-51 https://dx.doi.org/10.1016/j.margen.2015.02.007 Comprehensive computational analysis of leucine-rich repeat (LRR) proteins encoded in the genome of the diatom Phaeodactylum tricornutum Birgit Schulze ⁎, Matthias T. Buhmann 1, Carolina Río Bártulos, Peter G. Kroth Department of Biological Sciences, Universität Konstanz, 78457 Konstanz, Germany abstract We have screened the genome of the marine diatom Phaeodactylum tricornutum for gene models encoding proteins exhibiting leucine rich repeat (LRR) structures. In order to reveal the functionality of these proteins, their amino acid sequences were scanned for known domains and for homologies to other proteins. Additionally, proteins were categorized into different LRR families according to the variable sequence part of their LRR. This approach enabled us to group proteins with potentially similar functionality and to classify also LRR proteins Keywords: where no characterized homologues in other organisms exist. Most interestingly, we were able to indentify LRR several transmembrane LRR proteins, which are likely to function as receptor like molecules. However, none Receptor-like protein of them carry additional domains that are typical for mammalian or plant like receptors. Thus, the respective Adhesion protein signal recognition pathways seem to be substantially different in diatoms. Moreover, P. tricornutum encodes a RanGAP family of secreted LRR proteins likely to function as adhesion or binding proteins as part of the extracellular matrix. Additionally, intracellular LRR only proteins were divided into proteins similar to RasGTPase activators, regulators of nuclear transport, and mitotic regulation. Our approach allowed us to draw a detailed picture of the conservation and diversification of LRR proteins in the marine diatom P. -

Armadillo Repeat Proteins: Beyond the Animal Kingdom Coates, Juliet
University of Birmingham Armadillo repeat proteins: beyond the animal kingdom Coates, Juliet DOI: 10.1016/S0962-8924(03)00167-3 Document Version Early version, also known as pre-print Citation for published version (Harvard): Coates, J 2003, 'Armadillo repeat proteins: beyond the animal kingdom', Trends in Cell Biology, vol. 13, no. 9, pp. 463-471. https://doi.org/10.1016/S0962-8924(03)00167-3 Link to publication on Research at Birmingham portal General rights Unless a licence is specified above, all rights (including copyright and moral rights) in this document are retained by the authors and/or the copyright holders. The express permission of the copyright holder must be obtained for any use of this material other than for purposes permitted by law. •Users may freely distribute the URL that is used to identify this publication. •Users may download and/or print one copy of the publication from the University of Birmingham research portal for the purpose of private study or non-commercial research. •User may use extracts from the document in line with the concept of ‘fair dealing’ under the Copyright, Designs and Patents Act 1988 (?) •Users may not further distribute the material nor use it for the purposes of commercial gain. Where a licence is displayed above, please note the terms and conditions of the licence govern your use of this document. When citing, please reference the published version. Take down policy While the University of Birmingham exercises care and attention in making items available there are rare occasions when an item has been uploaded in error or has been deemed to be commercially or otherwise sensitive. -

Rigid Fusions of Designed Helical Repeat Binding Proteins Efficiently
www.nature.com/scientificreports OPEN Rigid fusions of designed helical repeat binding proteins efciently protect a binding surface from crystal contacts Patrick Ernst1, Annemarie Honegger1, Floor van der Valk1, Christina Ewald1,2, Peer R. E. Mittl1 & Andreas Plückthun1* Designed armadillo repeat proteins (dArmRPs) bind extended peptides in a modular way. The consensus version recognises alternating arginines and lysines, with one dipeptide per repeat. For generating new binding specifcities, the rapid and robust analysis by crystallography is key. Yet, we have previously found that crystal contacts can strongly infuence this analysis, by displacing the peptide and potentially distorting the overall geometry of the scafold. Therefore, we now used protein design to minimise these efects and expand the previously described concept of shared helices to rigidly connect dArmRPs and designed ankyrin repeat proteins (DARPins), which serve as a crystallisation chaperone. To shield the peptide-binding surface from crystal contacts, we rigidly fused two DARPins to the N- and C-terminal repeat of the dArmRP and linked the two DARPins by a disulfde bond. In this ring-like structure, peptide binding, on the inside of the ring, is very regular and undistorted, highlighting the truly modular binding mode. Thus, protein design was utilised to construct a well crystallising scafold that prevents interference from crystal contacts with peptide binding and maintains the equilibrium structure of the dArmRP. Rigid DARPin-dArmRPs fusions will also be useful when chimeric binding proteins with predefned geometries are required. Designed Armadillo repeat proteins (dArmRPs) bind to elongated peptide sequences and may eventually com- plement classical detection antibodies (a review on alternative binding scafolds can be found in ref.1, their use in therapeutics is reviewed in ref.2). -

ST Proteins, a New Family of Plant Tandem Repeat Proteins with A
Albornos et al. BMC Plant Biology 2012, 12:207 http://www.biomedcentral.com/1471-2229/12/207 RESEARCH ARTICLE Open Access ST proteins, a new family of plant tandem repeat proteins with a DUF2775 domain mainly found in Fabaceae and Asteraceae Lucía Albornos, Ignacio Martín, Rebeca Iglesias, Teresa Jiménez, Emilia Labrador and Berta Dopico* Abstract Background: Many proteins with tandem repeats in their sequence have been described and classified according to the length of the repeats: I) Repeats of short oligopeptides (from 2 to 20 amino acids), including structural cell wall proteins and arabinogalactan proteins. II) Repeats that range in length from 20 to 40 residues, including proteins with a well-established three-dimensional structure often involved in mediating protein-protein interactions. (III) Longer repeats in the order of 100 amino acids that constitute structurally and functionally independent units. Here we analyse ShooT specific (ST) proteins, a family of proteins with tandem repeats of unknown function that were first found in Leguminosae, and their possible similarities to other proteins with tandem repeats. Results: ST protein sequences were only found in dicotyledonous plants, limited to several plant families, mainly the Fabaceae and the Asteraceae. ST mRNAs accumulate mainly in the roots and under biotic interactions. Most ST proteins have one or several Domain(s) of Unknown Function 2775 (DUF2775). All deduced ST proteins have a signal peptide, indicating that these proteins enter the secretory pathway, and the mature proteins have tandem repeat oligopeptides that share a hexapeptide (E/D)FEPRP followed by 4 partially conserved amino acids, which could determine a putative N-glycosylation signal, and a fully conserved tyrosine. -

'Design of Armadillo Repeat Protein Scaffolds'
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2008 Design of armadillo repeat protein scaffolds Parmeggiani, F Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-4818 Dissertation Published Version Originally published at: Parmeggiani, F. Design of armadillo repeat protein scaffolds. 2008, University of Zurich, Faculty of Medicine. Design of Armadillo Repeat Protein Scaffolds Dissertation zur Erlangung der naturwissenschaftlichen Doktorwürde (Dr. sc. nat.) vorgelegt der Mathematisch-naturwissenschaftlichen Fakultät der Universität Zürich von Fabio Parmeggiani aus Italien Promotionskomitee Prof. Dr. Andreas Plückthun (Leitung der Dissertation) Prof. Dr. Markus Grütter Prof. Dr. Donald Hilvert Zürich, 2008 To my grandfather, who showed me the essence of curiosity “It is easy to add more of the same to old knowledge, but it is difficult to explain the new” Benno Müller-Hill Table of Contents 1 Table of contents Summary 3 Chapter 1: Peptide binders 7 Part I: Peptide binders 8 Modular interaction domains as natural peptide binders 9 SH2 domains 10 PTB domains 10 PDZ domains 12 14-3-3 domains 12 SH3 domains 12 WW domains 12 Peptide recognition by major histocompatibility complexes 13 Repeat proteins targeting peptides 15 Armadillo repeat proteins 16 Tetratricopeptide repeat proteins (TPR) 16 Beta propellers 16 Peptide binding by antibodies 18 Alternative scaffolds: a new approach to peptide binding 20 Part -
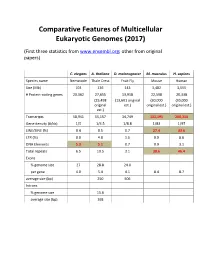
Comparative Features of Multicellular Eukaryotic Genomes (2017)
Comparative Features of Multicellular Eukaryotic Genomes (2017) (First three statistics from www.ensembl.org; other from original papers) C. elegans A. thaliana D. melanogaster M. musculus H. sapiens Species name Nematode Thale Cress Fruit Fly Mouse Human Size (Mb) 103 136 143 3,482 3,555 # Protein-coding genes 20,362 27,655 13,918 22,598 20,338 (25,498 (13,601 original (30,000 (30,000 original est.) original est.) original est.) est.) Transcripts 58,941 55,157 34,749 131,195 200,310 Gene density (#/kb) 1/5 1/4.5 1/8.8 1/83 1/97 LINE/SINE (%) 0.4 0.5 0.7 27.4 33.6 LTR (%) 0.0 4.8 1.5 9.9 8.6 DNA Elements 5.3 5.1 0.7 0.9 3.1 Total repeats 6.5 10.5 3.1 38.6 46.4 Exons % genome size 27 28.8 24.0 per gene 4.0 5.4 4.1 8.4 8.7 average size (bp) 250 506 Introns % genome size 15.6 average size (bp) 168 Arabidopsis Chromosome Structures Sorghum Whole Genome Details Characterizing the Proteome The Protein World • Sequencing has defined o Many, many proteins • How can we use this data to: o Define genes in new genomes o Look for evolutionarily related genes o Follow evolution of genes ▪ Mixing of domains to create new proteins o Uncover important subsets of genes that ▪ That deep phylogenies • Plants vs. animals • Placental vs. non-placental animals • Monocots vs. dicots plants • Common nomenclature needed o Ensure consistency of interpretations InterPro (http://www.ebi.ac.uk/interpro/) Classification of Protein Families • Intergrated documentation resource for protein super families, families, domains and functional sites o Mitchell AL, Attwood TK, Babbitt PC, et al.