1 Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding English Non-Count Nouns and Indefinite Articles
Understanding English non-count nouns and indefinite articles Takehiro Tsuchida Digital Hollywood University December 20, 2010 Introduction English nouns are said to be categorised into several groups according to certain criteria. Among such classifications is the division of count nouns and non-count nouns. While count nouns have such features as plural forms and ability to take the indefinite article a/an, non-count nouns are generally considered to be simply the opposite. The actual usage of nouns is, however, not so straightforward. Nouns which are usually regarded as uncountable sometimes take the indefinite article and it seems fairly difficult for even native speakers of English to expound the mechanism working in such cases. In particular, it seems to be fairly peculiar that the noun phrase (NP) whose head is the abstract „non-count‟ noun knowledge often takes the indefinite article a/an and makes such phrase as a good knowledge of Greek. The aim of this paper is to find out reasonable answers to the question of why these phrases occur in English grammar and thereby to help native speakers/teachers of English and non-native teachers alike to better instruct their students in 1 the complexity and profundity of English count/non-count dichotomy and actual usage of indefinite articles. This report will first examine the essential qualities of non-count nouns and indefinite articles by reviewing linguistic literature. Then, I shall conduct some research using the British National Corpus (BNC), focusing on statistical and semantic analyses, before finally certain conclusions based on both theoretical and actual observations are drawn. -
Count Vs Noncount Nouns
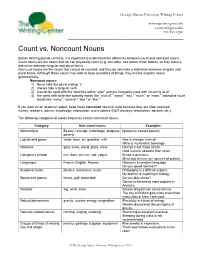
George Mason University Writing Center writingcenter.gmu.edu The [email protected] Writing Center 703.993.1200 Count vs. Noncount Nouns Before forming plurals correctly, it is important to understand the difference between count and noncount nouns. Count nouns are the nouns that we can physically count (e.g. one table, two tables, three tables), so they make a distinction between singular and plural forms. Noncount nouns are the nouns that cannot be counted, and they do not make a distinction between singular and plural forms. Although these nouns may refer to large quantities of things, they act like singular nouns grammatically. Noncount nouns: 1) Never take the plural ending “s” 2) Always take a singular verb 3) Cannot be used with the indefinite article “a/an” and are frequently used with no article at all 4) Are used with collective quantity words like “a lot of,” “some,” “any,” “much,” or “more,” instead of count words like “many,” “several,” “two,” or “few.” If you work on an academic paper, keep these noncount nouns in mind because they are often misused: money, research, advice, knowledge, information, and evidence (NOT moneys, researches, advices, etc.). The following categories of words frequently contain noncount nouns: Category Non-count nouns Examples Abstractions Beauty, revenge, knowledge, progress, Ignorance causes poverty. poverty Liquids and gases water, beer, air, gasoline, milk Gas is cheaper than oil. Wine is my favorite beverage. Materials gold, silver, wood, glass, sand He had a will made of iron. Gold is more valuable than silver. Categories of food rice, flour, cheese, salt, yogurt Bread is delicious. -

The “Person” Category in the Zamuco Languages. a Diachronic Perspective
On rare typological features of the Zamucoan languages, in the framework of the Chaco linguistic area Pier Marco Bertinetto Luca Ciucci Scuola Normale Superiore di Pisa The Zamucoan family Ayoreo ca. 4500 speakers Old Zamuco (a.k.a. Ancient Zamuco) spoken in the XVIII century, extinct Chamacoco (Ɨbɨtoso, Tomarâho) ca. 1800 speakers The Zamucoan family The first stable contact with Zamucoan populations took place in the early 18th century in the reduction of San Ignacio de Samuco. The Jesuit Ignace Chomé wrote a grammar of Old Zamuco (Arte de la lengua zamuca). The Chamacoco established friendly relationships by the end of the 19th century. The Ayoreos surrended rather late (towards the middle of the last century); there are still a few nomadic small bands in Northern Paraguay. The Zamucoan family Main typological features -Fusional structure -Word order features: - SVO - Genitive+Noun - Noun + Adjective Zamucoan typologically rare features Nominal tripartition Radical tenselessness Nominal aspect Affix order in Chamacoco 3 plural Gender + classifiers 1 person ø-marking in Ayoreo realis Traces of conjunct / disjunct system in Old Zamuco Greater plural and clusivity Para-hypotaxis Nominal tripartition Radical tenselessness Nominal aspect Affix order in Chamacoco 3 plural Gender + classifiers 1 person ø-marking in Ayoreo realis Traces of conjunct / disjunct system in Old Zamuco Greater plural and clusivity Para-hypotaxis Nominal tripartition All Zamucoan languages present a morphological tripartition in their nominals. The base-form (BF) is typically used for predication. The singular-BF is (Ayoreo & Old Zamuco) or used to be (Cham.) the basis for any morphological operation. The full-form (FF) occurs in argumental position. -

About Pronouns
About pronouns Halldór Ármann Sigurðsson Lund University Abstract This essay claims that pronouns are constructed as syntactic relations rather than as discrete feature bundles or items. The discussion is set within the framework of a minimalist Context-linked Grammar, where phases contain silent but active edge features, edge linkers, including speaker and hearer features. An NP is phi- computed in relation to these linkers, the so established relation being input to context scanning (yielding reference). Essentially, syntax must see to it that event participant roles link to speech act roles, by participant linking (a subcase of context linking, a central computational property of natural language). Edge linkers are syntactic features–not operators–and can be shifted, as in indexical shift and other Kaplanian monster phenomena, commonly under control. The essay also develops a new analysis of inclusiveness and of the different status of different phi-features in grammar. The approach pursued differs from Distributed Morphology in drawing a sharp line between (internal) syntax and (PF) externalization, syntax constructing relations–the externalization process building and expressing items. Keywords: Edge linkers, pronouns, speaker, phi-features, context linking, context scanning, indexical shift, inclusiveness, bound variables 1. Introduction* Indexical or deictic items include personal pronouns (I, you, she, etc.), demonstrative pronouns (this, that, etc.), and certain local and temporal adverbials and adjectives (here, now, presently, etc.). In the influential Kaplanian approach (Kaplan 1989), indexicals are assumed to have a fixed reference in a fixed context of a specific speech act or speech event. Schlenker (2003:29) refers to this leading idea as the fixity thesis, stating it as follows: Fixity Thesis (a corollary of Direct Reference): The semantic value of an indexical is fixed solely by the context of the actual speech act, and cannot be affected by any logical operators. -

Syntactic Variation in English Quantified Noun Phrases with All, Whole, Both and Half
Syntactic variation in English quantified noun phrases with all, whole, both and half Acta Wexionensia Nr 38/2004 Humaniora Syntactic variation in English quantified noun phrases with all, whole, both and half Maria Estling Vannestål Växjö University Press Abstract Estling Vannestål, Maria, 2004. Syntactic variation in English quantified noun phrases with all, whole, both and half, Acta Wexionensia nr 38/2004. ISSN: 1404-4307, ISBN: 91-7636-406-2. Written in English. The overall aim of the present study is to investigate syntactic variation in certain Present-day English noun phrase types including the quantifiers all, whole, both and half (e.g. a half hour vs. half an hour). More specific research questions concerns the overall frequency distribution of the variants, how they are distrib- uted across regions and media and what linguistic factors influence the choice of variant. The study is based on corpus material comprising three newspapers from 1995 (The Independent, The New York Times and The Sydney Morning Herald) and two spoken corpora (the dialogue component of the BNC and the Longman Spoken American Corpus). The book presents a number of previously not discussed issues with respect to all, whole, both and half. The study of distribution shows that one form often predominated greatly over the other(s) and that there were several cases of re- gional variation. A number of linguistic factors further seem to be involved for each of the variables analysed, such as the syntactic function of the noun phrase and the presence of certain elements in the NP or its near co-text. -

A First Order Semantic Approach to Adjectival Inference
A first order semantic approach to adjectival inference Marilisa Amoia Claire gardent INRIA/Universite´ de Nancy 1 & CNRS/Loria University of the Saarland Campus Scientifique BP 239 Saarbrucken,¨ Germany 54506 Vandoeuvre-les-Nancy, France [email protected] [email protected] Abstract der automated reasoners that could be put to use to reason about the meaning of higher-order formulae. As shown in the formal semantics litera- In this paper, we present a semantics for adjec- ture, adjectives can display very different tives that adopts an ontologically promiscuous ap- inferential patterns depending on whether proach and thereby supports first order inference for they are intersective, privative, subsective all types of adjectives including extensional ones. or plain non subsective. Moreover, many Indeed, traditional semantic classifications of ad- of these classes are often described using jectives such as (?; ?; ?) subdivide adjectives second order constructs. In this paper, we into two classes namely extensional vs. intensional adopt Hobbs’s ontologically promiscuous adjectives, the latter grouping together adjectives approach and present a first order treatment which intuitively denote functions from properties of adjective semantics which opens the way to properties i.e., second order objects. for a sophisticated treatment of adjectival We present a compositional semantics for ad- inference. The approach was implemented jectives which both (i) defines a first order repre- and tested using first order automated rea- sentation and (ii) integrates interactions with other soners. sources of linguistic information such as lexical se- mantics and morpho-derivational relations. We then 1 Introduction show that the proposed semantics correctly predicts As has often been observed, not all of natural lan- the inferential patterns observed to hold of the var- guage meaning can be represented by first order ious adjective subclasses identified in the literature logic. -

A Set-Based Semantics for Obviation and Animacy
A set-based semantics for obviation and animacy Christopher Hammerly – University of Minnesota Preprint Draft 1.0 – March 22nd, 2021 Abstract This paper provides an analysis of the semantics of obviation and animacy through a case study of Ojibwe (Central Algonquian). I develop a lattice-based characterization of possi- ble person, obviation, and animacy categories, showing that the addition of two binary features, [±Proximate] and [±Animate], captures the six-way distinction of Ojibwe. These features denote first-order predicates formed from subsets of an ontology of person primitives, with composition and interpretation defined by (i) the functional sequence of the nominal spine, (ii) the denotation of feature values, and (iii) the theory of contrastive interpretations. I show that alternative ac- counts based in lattice actions or feature geometries cannot capture the partition of Ojibwe, and offer extensions of the proposed system to noun classification in Zapotec, Romance, and Bantu. Keywords: obviation, animacy, person, noun classification, gender, '-features 1 Introduction Languages show constrained, but rich, variation in how categories related to person are distin- guished and conflated. At the core of all person systems is the possibility to refer to the author of an utterance, the addressee, and various non-participants — all languages, and indeed all humans, appear to have access to these fundamental concepts. The major point of variation is how these concepts are accessed, encoded, and manipulated by the grammar. The view taken in this paper is that the author, addressee, and others are PRIMITIVES of a mental ontology that is manipulated and accessed by morphosyntactic FEATURES. These features, in turn, give rise to CATEGORIES that allow reference to the primitives. -

Number and Adjectives : the Case of Activity and Quality Nominals Delphine Beauseroy, Marie-Laurence Knittel
Number and adjectives : the case of activity and quality nominals Delphine Beauseroy, Marie-Laurence Knittel To cite this version: Delphine Beauseroy, Marie-Laurence Knittel. Number and adjectives : the case of activity and quality nominals. 2012. hal-00418040v2 HAL Id: hal-00418040 https://hal.archives-ouvertes.fr/hal-00418040v2 Preprint submitted on 11 Jun 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. 1 NUMBER AND ADJECTIVES: THE CASE OF FRENCH ACTIVITY AND QUALITY NOMINALS 1. INTRODUCTION This article is dedicated to the examination of the role of Number with regards to adjective distribution in French. We focus on two kinds of abstract nouns: activity nominals and quality nominals. Both display particular behaviours with regards to adjective distribution: activity nominals need to appear as count nouns to be modified by qualifying adjectives; concerning quality nominals, they are frequently introduced by the indefinite un(e) instead of the partitive article (du / de la) when modified. Our analysis of adjectives is based on the idea that they can have two uses, which correlate with syntactic and semantic restrictions and are distinguishable on semantic grounds. Adjectives are understood either as taxonomic, i.e. -

Cross-Linguistic Evidence for Semantic Countability1
Eun-Joo Kwak 55 Journal of Universal Language 15-2 September 2014, 55-76 Cross-Linguistic Evidence for Semantic Countability1 2 Eun-Joo Kwak Sejong University, Korea Abstract Countability and plurality (or singularity) are basically marked in syntax or morphology, and languages adopt different strategies in the mass-count distinction and number marking: plural marking, unmarked number marking, singularization, and different uses of classifiers. Diverse patterns of grammatical strategies are observed with cross-linguistic data in this study. Based on this, it is concluded that although countability is not solely determined by the semantic properties of nouns, it is much more affected by semantics than it appears. Moreover, semantic features of nouns are useful to account for apparent idiosyncratic behaviors of nouns and sentences. Keywords: countability, plurality, countability shift, individuation, animacy, classifier * This work is supported by the Sejong University Research Grant of 2013. Eun-Joo Kwak Department of English Language and Literature, Sejong University, Seoul, Korea Phone: +82-2-3408-3633; Email: [email protected] Received August 14, 2014; Revised September 3, 2014; Accepted September 10, 2014. 56 Cross-Linguistic Evidence for Semantic Countability 1. Introduction The state of affairs in the real world may be delivered in a different way depending on the grammatical properties of languages. Nominal countability makes part of grammatical differences cross-linguistically, marked in various ways: plural (or singular) morphemes for nouns or verbs, distinct uses of determiners, and the occurrences of classifiers. Apparently, countability and plurality are mainly marked in syntax and morphology, so they may be understood as having less connection to the semantic features of nouns. -

Facing the Facts of Fake: a Distributional Semantics and Corpus Annotation Approach Bert Cappelle, Pascal Denis, Mikaela Keller
Facing the facts of fake: a distributional semantics and corpus annotation approach Bert Cappelle, Pascal Denis, Mikaela Keller To cite this version: Bert Cappelle, Pascal Denis, Mikaela Keller. Facing the facts of fake: a distributional semantics and corpus annotation approach. Yearbook of the German Cognitive Linguistics Association, De Gruyter, 2018, 6 (9-42). hal-01959609 HAL Id: hal-01959609 https://hal.archives-ouvertes.fr/hal-01959609 Submitted on 18 Dec 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Facing the facts of fake: a distributional semantics and corpus annotation approach Bert Cappelle, Pascal Denis and Mikaela Keller Université de Lille, Inria Lille Nord Europe Fake is often considered the textbook example of a so-called ‘privative’ adjective, one which, in other words, allows the proposition that ‘(a) fake x is not (an) x’. This study tests the hypothesis that the contexts of an adjective-noun combination are more different from the contexts of the noun when the adjective is such a ‘privative’ one than when it is an ordinary (subsective) one. We here use ‘embeddings’, that is, dense vector representations based on word co-occurrences in a large corpus, which in our study is the entire English Wikipedia as it was in 2013. -

3 Types of Anaphors
3 Types of anaphors Moving from the definition and characteristics of anaphors to the types of ana- phors, this chapter will detail the nomenclature of anaphor types established for this book. In general, anaphors can be categorised according to: their form; the type of relationship to their antecedent; the form of their antecedents; the position of anaphors and antecedents, i.e. intrasentential or intersentential; and other features (cf. Mitkov 2002: 8-17). The procedure adopted here is to catego- rise anaphors according to their form. It should be stressed that the types dis- tinguished in this book are not universal categories, so the proposed classifica- tion is not the only possible solution. For instance, personal, possessive and re- flexive pronouns can be seen as three types or as one type. With the latter, the three pronoun classes are subsumed under the term “central pronouns”, as it is adopted here. Linguistic classifications of anaphors can be found in two established gram- mar books, namely in Quirk et al.’s A Comprehensive Grammar of the English Language (2012: 865) and in The Cambridge Grammar of the English Language (Stirling & Huddleston 2010: 1449-1564). Quirk et al. include a chapter of pro- forms and here distinguish between coreference and substitution. However, they do not take anaphors as their starting point of categorisation. Additionally, Stirling & Huddleston do not consider anaphors on their own but together with deixis. As a result, anaphoric noun phrases with a definite article, for example, are not included in both categorisations. Furthermore, Schubert (2012: 31-55) presents a text-linguistic view, of which anaphors are part, but his classification is similarly unsuitable because it does not focus on the anaphoric items specifi- cally. -

English 4 Using Clear and Coherent Sentences Employing Grammatical Structures Second Quarter - Week 2
Department of Education English 4 Using Clear and Coherent Sentences employing Grammatical Structures Second Quarter - Week 2 Adelinda D. Dollesin Writer Hilario G. Canasa Dr. Ma. Myra E. Namit Validators Ivy M. Romano Ada T. Tagle Cecilia Theresa C. Claudel Dr. Ma. Theresa C. Dela Rosa Dr. Ma. Carmen D. Solayao Dr. Shella C. Navarro Quality Assurance Team Schools Division Office – Muntinlupa City Student Center for Life Skills Bldg., Centennial Ave., Brgy. Tunasan, Muntinlupa City (02) 8805-9935 / (02) 8805-9940 1 This module was designed to help you master the use of clear and coherent sentences employing appropriate grammatical structures (Kinds of Nouns: Count and Mass, Possessive and Collective Nouns) After going through this module, you are expected to: 1. Define and identify the kinds of nouns: mass and count nouns, possessive and collective nouns; and 2. Classify and use kinds of nouns (mass and count nouns, possessive and collective nouns) in simple sentence. A. Directions: Encircle the letter of the correct answer. 1. Linda will buy juice and chicken from the store. Which of the following words is a mass noun? A. chicken C. Linda B. juice D. store 2. Nena will use the long spoon for halo-halo. Which of the following is a count noun? A. Long C. use B. spoon D. will 3. They put sugar in the jar. What is the count noun in the sentence? A. jar C. sugar B. put D. they 4. Hera added rice in a bowl. Which is the mass noun in the sentence? A. bowl C. Hera B.