Bhutanese Sign Language Hand-Shaped Alphabets and Digits Detection and Recognition
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

CENDEP WP-01-2021 Deaf Refugees Critical Review-Kate Mcauliff
CENDEP Working Paper Series No 01-2021 Deaf Refugees: A critical review of the current literature Kate McAuliff Centre for Development and Emergency Practice Oxford Brookes University The CENDEP working paper series intends to present work in progress, preliminary research findings of research, reviews of literature and theoretical and methodological reflections relevant to the fields of development and emergency practice. The views expressed in the paper are only those of the independent author who retains the copyright. Comments on the papers are welcome and should be directed to the author. Author: Kate McAuliff Institutional address (of the Author): CENDEP, Oxford Brookes University Author’s email address: [email protected] Doi: https://doi.org/10.24384/cendep.WP-01-2021 Date of publication: April 2021 Centre for Development and Emergency Practice (CENDEP) School of Architecture Oxford Brookes University Oxford [email protected] © 2021 The Author(s). This open access article is distributed under a Creative Commons Attribution- NonCommercial-No Derivative Works (CC BY-NC-ND) 4.0 License. Table of Contents Abstract ............................................................................................................................................................ 4 1. Introduction ........................................................................................................................................... 5 2. Deaf Refugee Agency & Double Displacement ............................................................................. -

U.S. Ambassador to China Terry Branstad
U.S. Ambassador to China Terry Branstad On December 7, 2016, Governor Branstad announced that he had accepted the nomination from President-elect Donald Trump to serve as Ambassador of the United States to the People’s Republic of China. He was confirmed by the Senate on May 22, 2017, and was sworn in on May 24, 2017. Ambassador Terry Branstad was born, raised and educated in Iowa. A native of Leland, Branstad was elected to the Iowa House in 1972, ’74 and ’76, and elected as Iowa’s lieutenant governor in 1978. Branstad was Iowa’s longest-serving governor, from 1983 to 1999. As the state’s chief executive, he weathered some of Iowa’s worst economic turmoil, during the farm crisis of the ‘80s, while helping lead the state’s resurgence to a booming economy in the ‘90s. At the end of his tenure, Iowa enjoyed record employment, an unprecedented $900 million budget surplus, and the enactment of historic government overhauls that led to greater efficiencies in state government. As a result of Governor Branstad’s hands-on, round-the-clock approach to economic development, Iowa’s unemployment rate went from 8.5 percent when he took office to a record low 2.5 percent by the time he left in 1999. Following his four terms as governor, Branstad served as president of Des Moines University (DMU). During his 6-year tenure, he was able to grow the university into a world-class educational facility. Its graduates offer health care in all 50 states and in nearly every Iowa county. -

Zero Project Report 2019
Zero Project Report 2019 Independent Living and Political Participation 66 Innovative Practices, 10 Innovative Policies, from 41 countries International study on the implementation of the UN Convention on the Rights of Persons with Disabilities – “For a World without Barriers” Zero Project Director: Michael Fembek Authors: Thomas Butcher, Peter Charles, Loic van Cutsem, Zach Dorfman, Micha Fröhlich, Seena Garcia, Michael Fembek, Wilfried Kainz, Seema Mundackal, Paula Reid, Venice Sto.Tomas, Marina Vaughan Spitzy This publication was developed with contributions from Doris Neuwirth (coordination); Christoph Almasy (design); John Tessitore (editing); and atempo (easy language). Photos of Innovative Practices and Innovative Policies as well as photos for “Life Stories” have been provided by their respective organizations. ISBN 978-3-9504208-4-5 © Essl Foundation, January 2019. All rights reserved. First published 2019. Printed in Austria. Published in the Zero Project Report series and available for free download at www.zeroproject.org: Zero Project Report 2018: Accessibility Zero Project Report 2017: Employment Zero Project Report 2016: Education and ICT Zero Project Report 2015: Independent Living and Political Participation Disclaimers The views expressed in this publication do not necessarily reflect the views of the Essl Foundation or the Zero Project. The designations employed and the presentation of the material do not imply the expression of any opinion whatso- ever on the part of the Essl Foundation concerning the legal status of any country, territory, city, or area, or of its authorities, or concerning the delineation of its frontiers or boundaries. The composition of geographical regions and selected economic and other group- ings used in this report is based on UN Statistics (www.unstats.org), including the borders of Europe, and on the Human Development Index (hdr.undp.org). -

Evidentiality, Egophoricity, and Engagement
Evidentiality, egophoricity, and engagement Edited by Henrik Bergqvist Seppo Kittilä language Studies in Diversity Linguistics 30 science press Studies in Diversity Linguistics Editor: Martin Haspelmath In this series: 1. Handschuh, Corinna. A typology of 18. Paggio, Patrizia and Albert Gatt (eds.). The markedS languages. languages of Malta. 2. Rießler, Michael. Adjective attribution. 19. Seržant, Ilja A. & Alena WitzlackMakarevich 3. Klamer, Marian (ed.). The AlorPantar (eds.). Diachrony of differential argument languages: History and typology. marking. 4. Berghäll, Liisa. A grammar of Mauwake 20. Hölzl, Andreas. A typology of questions in (Papua New Guinea). Northeast Asia and beyond: An ecological 5. Wilbur, Joshua. A grammar of Pite Saami. perspective. 6. Dahl, Östen. Grammaticalization in the 21. Riesberg, Sonja, Asako Shiohara & Atsuko North: Noun phrase morphosyntax in Utsumi (eds.). Perspectives on information Scandinavian vernaculars. structure in Austronesian languages. 7. Schackow, Diana. A grammar of Yakkha. 22. Döhler, Christian. A grammar of Komnzo. 8. Liljegren, Henrik. A grammar of Palula. 23. Yakpo, Kofi. A Grammar of Pichi. 9. Shimelman, Aviva. A grammar of Yauyos Quechua. 24. Guérin Valérie (ed.). Bridging constructions. 10. Rudin, Catherine & Bryan James Gordon 25. AguilarGuevara, Ana, Julia Pozas Loyo & (eds.). Advances in the study of Siouan Violeta VázquezRojas Maldonado *eds.). languages and linguistics. Definiteness across languages. 11. Kluge, Angela. A grammar of Papuan Malay. 26. Di Garbo, Francesca, Bruno Olsson & 12. Kieviet, Paulus. A grammar of Rapa Nui. Bernhard Wälchli (eds.). Grammatical 13. Michaud, Alexis. Tone in Yongning Na: gender and linguistic complexity: Volume I: Lexical tones and morphotonology. General issues and specific studies. 14. -

Goat-Sheep-Mixed-Sign” in Lhasa - Deaf Tibetans’ Language Ideologies and Unimodal Codeswitching in Tibetan and Chinese Sign Languages, Tibet Autonomous Region, China’
Hofer, T. (2020). "Goat-Sheep-Mixed-Sign” in Lhasa - Deaf Tibetans’ Language Ideologies and Unimodal Codeswitching in Tibetan and Chinese Sign Languages, Tibet Autonomous Region, China’. In A. Kusters, M. E. Green, E. Moriarty Harrelson, & K. Snoddon (Eds.), Sign Language Ideologies in Practice (pp. 81-105). DeGruyter. https://doi.org/10.1515/9781501510090-005 Publisher's PDF, also known as Version of record License (if available): CC BY-NC-ND Link to published version (if available): 10.1515/9781501510090-005 Link to publication record in Explore Bristol Research PDF-document This is the final published version of the article (version of record). It first appeared online via DeGruyter at https://doi.org/10.1515/9781501510090-005 . Please refer to any applicable terms of use of the publisher. University of Bristol - Explore Bristol Research General rights This document is made available in accordance with publisher policies. Please cite only the published version using the reference above. Full terms of use are available: http://www.bristol.ac.uk/red/research-policy/pure/user-guides/ebr-terms/ Theresia Hofer “Goat-Sheep-Mixed-Sign” in Lhasa – Deaf Tibetans’ language ideologies and unimodal codeswitching in Tibetan and Chinese sign languages, Tibet Autonomous Region, China 1 Introduction Among Tibetan signers in Lhasa, there is a growing tendency to mix Tibetan Sign Language (TSL) and Chinese Sign Language (CSL). I have been learning TSL from deaf TSL teachers and other deaf, signing Tibetan friends since 2007, but in more recent conversations with them I have been more and more exposed to CSL. In such contexts, signing includes not only loan signs, loan blends or loan trans- lations from CSL that have been used in TSL since its emergence, such as signs for new technical inventions or scientific terms. -

An Introduction to Linguistic Typology
An Introduction to Linguistic Typology An Introduction to Linguistic Typology Viveka Velupillai University of Giessen John Benjamins Publishing Company Amsterdam / Philadelphia TM The paper used in this publication meets the minimum requirements of 8 the American National Standard for Information Sciences – Permanence of Paper for Printed Library Materials, ansi z39.48-1984. Library of Congress Cataloging-in-Publication Data An introduction to linguistic typology / Viveka Velupillai. â. p cm. â Includes bibliographical references and index. 1. Typology (Linguistics) 2. Linguistic universals. I. Title. P204.V45 â 2012 415--dc23 2012020909 isbn 978 90 272 1198 9 (Hb; alk. paper) isbn 978 90 272 1199 6 (Pb; alk. paper) isbn 978 90 272 7350 5 (Eb) © 2012 – John Benjamins B.V. No part of this book may be reproduced in any form, by print, photoprint, microfilm, or any other means, without written permission from the publisher. John Benjamins Publishing Company • P.O. Box 36224 • 1020 me Amsterdam • The Netherlands John Benjamins North America • P.O. Box 27519 • Philadelphia PA 19118-0519 • USA V. Velupillai: Introduction to Typology NON-PUBLIC VERSION: PLEASE DO NOT CITE OR DISSEMINATE!! ForFor AlTô VelaVela anchoranchor and and inspiration inspiration 2 Table of contents Acknowledgements xv Abbreviations xvii Abbreviations for sign language names xx Database acronyms xxi Languages cited in chapter 1 xxii 1. Introduction 1 1.1 Fast forward from the past to the present 1 1.2 The purpose of this book 3 1.3 Conventions 5 1.3.1 Some remarks on the languages cited in this book 5 1.3.2 Some remarks on the examples in this book 8 1.4 The structure of this book 10 1.5 Keywords 12 1.6 Exercises 12 Languages cited in chapter 2 14 2. -

Zero Project Report 2018
Zero Project Report 2018 Accessibility 68 Innovative Practices, 15 Innovative Policies, and 22 Social Indicators from 105 countries International study on the implementation of the UN Convention on the Rights of Persons with Disabilities – “For a World without Barriers” Zero Project Director and Chief Editor: Michael Fembek Authors: Peter Charles, Michael Fembek, Wilfried Kainz, Seema Mundackal, Amelie Saupe, Marina Vaughan-Spitzy, Alice Kahane, Caroline Wagner This publication was developed with contributions from Doris Neuwirth (coordination); Christoph Almasy (design); and John Tessitore (editing). Photos of Innovative Practices and Innovative Policies as well as photos for “Life Stories” have been provided by their respective organizations. ISBN 978-3-9504208-3-8 © Essl Foundation, January 2018. All rights reserved. First published 2018. Printed in Austria. Published in the Zero Project Report series: Zero Project Report 2017: Employment Zero Project Report 2016: Education and ICT Zero Project Report 2015: Independent Living and Political Participation Zero Project Report 2015 Austria: Selbstbestimmtes Leben und Politische Teilhabe Zero Project Report 2014: Accessibility Zero Project Report 2013: Employment Disclaimers The views expressed in this publication do not necessarily reflect the views of the Essl Foundation or the Zero Project. The designations employed and the presentation of the material do not imply the expression of any opinion whatso- ever on the part of the Essl Foundation concerning the legal status of any country, territory, city, or area, or of its authorities, or concerning the delineation of its frontiers or boundaries. The composition of geographical regions and selected economic and other group- ings used in this report is based on UN Statistics (www.unstats.org), including the borders of Europe, and on the Human Development Index (hdr.undp.org). -

Gazetteer Service - Application Profile of the Web Feature Service Best Practice
Best Practices Document Open Geospatial Consortium Approval Date: 2012-01-30 Publication Date: 2012-02-17 External identifier of this OGC® document: http://www.opengis.net/doc/wfs-gaz-ap ® Reference number of this OGC document: OGC 11-122r1 Version 1.0 ® Category: OGC Best Practice Editors: Jeff Harrison, Panagiotis (Peter) A. Vretanos Gazetteer Service - Application Profile of the Web Feature Service Best Practice Copyright © 2012 Open Geospatial Consortium To obtain additional rights of use, visit http://www.opengeospatial.org/legal/ Warning This document defines an OGC Best Practices on a particular technology or approach related to an OGC standard. This document is not an OGC Standard and may not be referred to as an OGC Standard. This document is subject to change without notice. However, this document is an official position of the OGC membership on this particular technology topic. Document type: OGC® Best Practice Paper Document subtype: Application Profile Document stage: Approved Document language: English OGC 11-122r1 Contents Page 1 Scope ..................................................................................................................... 13 2 Conformance ......................................................................................................... 14 3 Normative references ............................................................................................ 14 4 Terms and definitions ........................................................................................... 15 5 Conventions -
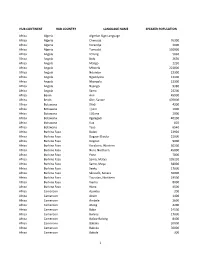
Sad List.Xlsx
HUB CONTINENT HUB COUNTRY LANGUAGE NAME SPEAKER POPULATION Africa Algeria Algerian Sign Language Africa Algeria Chenoua 76300 Africa Algeria Korandje 3000 Africa Algeria Tumzabt 150000 Africa Angola !O!ung 5630 Africa Angola Bolo 2630 Africa Angola Maligo 2230 Africa Angola Mbwela 222000 Africa Angola Ndombe 22300 Africa Angola Ngandyera 13100 Africa Angola Nkangala 22300 Africa Angola Nyengo 9380 Africa Angola Sama 24200 Africa Benin Anii 45900 Africa Benin Gbe, Saxwe 170000 Africa Botswana !Xóõ 4200 Africa Botswana ||Ani 1000 Africa Botswana ||Gana 2000 Africa Botswana Kgalagadi 40100 Africa Botswana Kua 820 Africa Botswana Tsoa 6540 Africa Burkina Faso Bolon 22920 Africa Burkina Faso Dagaari Dioula 21000 Africa Burkina Faso Dogoso 9000 Africa Burkina Faso Karaboro, Western 30200 Africa Burkina Faso Nuni, Northern 45000 Africa Burkina Faso Pana 7800 Africa Burkina Faso Samo, Matya 105230 Africa Burkina Faso Samo, Maya 38000 Africa Burkina Faso Seeku 17000 Africa Burkina Faso Sénoufo, Senara 50000 Africa Burkina Faso Toussian, Northern 19500 Africa Burkina Faso Viemo 8000 Africa Burkina Faso Wara 4500 Africa Cameroon Ajumbu 200 Africa Cameroon Akum 1400 Africa Cameroon Ambele 2600 Africa Cameroon Atong 4200 Africa Cameroon Baba 24500 Africa Cameroon Bafanji 17000 Africa Cameroon Bafaw-Balong 8400 Africa Cameroon Bakaka 30000 Africa Cameroon Bakoko 50000 Africa Cameroon Bakole 300 1 HUB CONTINENT HUB COUNTRY LANGUAGE NAME SPEAKER POPULATION Africa Cameroon Balo 2230 Africa Cameroon Bamali 10800 Africa Cameroon Bambili-Bambui 10000 Africa -

Tokyo 2010 Handbook Contents
“All authority in heaven and on earth has been given to me. Therefore go and make disciples of all nations, baptizing them in the name of the Father and of the Son and of the Holy Spirit, and teaching them to obey everything I have commanded you. And surely I am with you always, to the very end of the age.” Matthew 28 :18-20 Tokyo2010 Global Mission Consultation Handbook Copyright © 2010 by Yong J. Cho All rights reserved No part of this handbook may be reproduced in any form without written permission, except in the case of brief quotation embodied in critical articles and reviews. Edited by Yong J. Cho and David Taylor Cover designed by Hyun Kyung Jin Published by Tokyo 2010 Global Mission Consultation Planning Committee 1605 E. Elizabeth St. Pasadena, CA 91104, USA 77-3 Munjung-dong, Songpa-gu, Seoul 138-200 Korea www.Tokyo2010.org [email protected] [email protected] Not for Sale Printed in the Republic of Korea designed Ead Ewha Hong TOKYO 2010 HANDBOOK CONTENTS Declaration (Pre-consultation Draft)ּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּ5 Opening Video Scriptּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּ8 Greetingsּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּ 11 Schedule and Program Overviewּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּ 17 Plenariesּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּּ -

Guidelines on Assessment, Examination
GUIDELINES ON ASSESSMENT, EXAMINATION, PROMOTION AND TRANSITION FOR STUDENTS WITH DISABILITIES ECCD & SEN Division Department of School Education Ministry of Education Royal Government of Bhutan Published by: ECCD & SEN Division Department of School Education Ministry of Education Royal Government of Bhutan Telephone: +975-2-331981 Fax: +975-2-331903 Website: www.education.gov.bt Endorsed by Curriculum and Technical Advisory Board 5th July, 2018 held in Thimphu, Bhutan. Copyright © 2018 ECCD & SEN Division, Ministry of Education All rights reserved. No part of this publication may be reproduced in any form without prior permission from the ECCD & SEN Division, Ministry of Education. First Edition: 2018 Printed with support from UNICEF, Bhutan. Table of Contents Foreword . 1 Introduction . 2 Overview . 2 The Context of the guidelines . 2 1. Part One - Alternative Path ways/Programmes ......................................................... 7 1. 1. Extended Learning - Time ................................................................................................ 7 1. 2. Selective and functional learning programme ............................................................... 9 1. 3. Technical and Vocational Education Training (TVET) Programme: .......................11 1. 4. Adapted, Modified or Specially Designed learning programme for students who are Deaf ....................................................................................................................12 1. 5. Literacy, Numeracy and Life Skills Programme for -

Ten Year Roadmap for Inclusive and Special
Published by: ECCD & SEN Division Department of School Education Ministry of Education Royal Government of Bhutan Telephone: +975-2-331981, +975-2-325325 Fax: +975-2- 331903 Website: www.education.gov.bt Printed with support from Save The Children, Bhutan. © 2019 ECCD & SEN Division, DSE, Ministry of Education ISBN 978-9980-865-0-0 All rights reserved. No part of this publication may be reproduced in any form without prior permission from the Department of School Education, Ministry of Education Ten-Year Roadmap for Inclusive and Special Education in Bhutan 2019 ECCD & SEN DIVISION DEPARTMENT OF SCHOOL EDCUATION MINISTRY OF EDUCATION Royal Government of Bhutan Ministry of Education SECRETARY Cultivating the Grace of Mind Foreword Inclusive and special education is about ensuring that every child can participate in education and receive the support they need to reach their full potential, and as such, inclusive and special education is a priority of the Ministry of Education. In a country governed by the concept of Gross National Happiness, we value inclusion in every aspect of our society, and the best way to ensure an inclusive society for our future is to have inclusive schools and an inclusive education system now. Education for children with disabilities has already come a long way in Bhutan, and the Ministry of Education is proud to say that there are currently 18 schools with SEN programmes including two specialised institutes providing special educational services to children across the country. Our system is also changing at policy and programme level, with the development of the inclusive National Education Policy and a number of new programmes and guidelines considering the needs of children with disabilities.