Perception of Vicentino's 31-Tone Tuning System
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

An Adaptive Tuning System for MIDI Pianos
David Løberg Code Groven.Max: School of Music Western Michigan University Kalamazoo, MI 49008 USA An Adaptive Tuning [email protected] System for MIDI Pianos Groven.Max is a real-time program for mapping a renstemningsautomat, an electronic interface be- performance on a standard keyboard instrument to tween the manual and the pipes with a kind of arti- a nonstandard dynamic tuning system. It was origi- ficial intelligence that automatically adjusts the nally conceived for use with acoustic MIDI pianos, tuning dynamically during performance. This fea- but it is applicable to any tunable instrument that ture overcomes the historic limitation of the stan- accepts MIDI input. Written as a patch in the MIDI dard piano keyboard by allowing free modulation programming environment Max (available from while still preserving just-tuned intervals in www.cycling74.com), the adaptive tuning logic is all keys. modeled after a system developed by Norwegian Keyboard tunings are compromises arising from composer Eivind Groven as part of a series of just the intersection of multiple—sometimes oppos- intonation keyboard instruments begun in the ing—influences: acoustic ideals, harmonic flexibil- 1930s (Groven 1968). The patch was first used as ity, and physical constraints (to name but three). part of the Groven Piano, a digital network of Ya- Using a standard twelve-key piano keyboard, the maha Disklavier pianos, which premiered in Oslo, historical problem has been that any fixed tuning Norway, as part of the Groven Centennial in 2001 in just intonation (i.e., with acoustically pure tri- (see Figure 1). The present version of Groven.Max ads) will be limited to essentially one key. -

MTO 20.2: Wild, Vicentino's 31-Tone Compositional Theory
Volume 20, Number 2, June 2014 Copyright © 2014 Society for Music Theory Genus, Species and Mode in Vicentino’s 31-tone Compositional Theory Jonathan Wild NOTE: The examples for the (text-only) PDF version of this item are available online at: http://www.mtosmt.org/issues/mto.14.20.2/mto.14.20.2.wild.php KEYWORDS: Vicentino, enharmonicism, chromaticism, sixteenth century, tuning, genus, species, mode ABSTRACT: This article explores the pitch structures developed by Nicola Vicentino in his 1555 treatise L’Antica musica ridotta alla moderna prattica . I examine the rationale for his background gamut of 31 pitch classes, and document the relationships among his accounts of the genera, species, and modes, and between his and earlier accounts. Specially recorded and retuned audio examples illustrate some of the surviving enharmonic and chromatic musical passages. Received February 2014 Table of Contents Introduction [1] Tuning [4] The Archicembalo [8] Genus [10] Enharmonic division of the whole tone [13] Species [15] Mode [28] Composing in the genera [32] Conclusion [35] Introduction [1] In his treatise of 1555, L’Antica musica ridotta alla moderna prattica (henceforth L’Antica musica ), the theorist and composer Nicola Vicentino describes a tuning system comprising thirty-one tones to the octave, and presents several excerpts from compositions intended to be sung in that tuning. (1) The rich compositional theory he develops in the treatise, in concert with the few surviving musical passages, offers a tantalizing glimpse of an alternative pathway for musical development, one whose radically augmented pitch materials make possible a vast range of novel melodic gestures and harmonic successions. -

Intervals and Transposition
CHAPTER 3 Intervals and Transposition Interval Augmented and Simple Intervals TOPICS Octave Diminished Intervals Tuning Systems Unison Enharmonic Intervals Melodic Intervals Perfect, Major, and Minor Tritone Harmonic Intervals Intervals Inversion of Intervals Transposition Consonance and Dissonance Compound Intervals IMPORTANT Tone combinations are classifi ed in music with names that identify the pitch relationships. CONCEPTS Learning to recognize these combinations by both eye and ear is a skill fundamental to basic musicianship. Although many different tone combinations occur in music, the most basic pairing of pitches is the interval. An interval is the relationship in pitch between two tones. Intervals are named by the Intervals number of diatonic notes (notes with different letter names) that can be contained within them. For example, the whole step G to A contains only two diatonic notes (G and A) and is called a second. Figure 3.1 & ww w w Second 1 – 2 The following fi gure shows all the numbers within an octave used to identify intervals: Figure 3.2 w w & w w w w 1ww w2w w3 w4 w5 w6 w7 w8 Notice that the interval numbers shown in Figure 3.2 correspond to the scale degree numbers for the major scale. 55 3711_ben01877_Ch03pp55-72.indd 55 4/10/08 3:57:29 PM The term octave refers to the number 8, its interval number. Figure 3.3 w œ œ w & œ œ œ œ Octavew =2345678=œ1 œ w8 The interval numbered “1” (two notes of the same pitch) is called a unison. Figure 3.4 & 1 =w Unisonw The intervals that include the tonic (keynote) and the fourth and fi fth scale degrees of a Perfect, Major, and major scale are called perfect. -

Consonance and Dissonance in Visual Music Bill Alves Harvey Mudd College
Claremont Colleges Scholarship @ Claremont All HMC Faculty Publications and Research HMC Faculty Scholarship 8-1-2012 Consonance and Dissonance in Visual Music Bill Alves Harvey Mudd College Recommended Citation Bill Alves (2012). Consonance and Dissonance in Visual Music. Organised Sound, 17, pp 114-119 doi:10.1017/ S1355771812000039 This Article is brought to you for free and open access by the HMC Faculty Scholarship at Scholarship @ Claremont. It has been accepted for inclusion in All HMC Faculty Publications and Research by an authorized administrator of Scholarship @ Claremont. For more information, please contact [email protected]. Organised Sound http://journals.cambridge.org/OSO Additional services for Organised Sound: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here Consonance and Dissonance in Visual Music Bill Alves Organised Sound / Volume 17 / Issue 02 / August 2012, pp 114 - 119 DOI: 10.1017/S1355771812000039, Published online: 19 July 2012 Link to this article: http://journals.cambridge.org/abstract_S1355771812000039 How to cite this article: Bill Alves (2012). Consonance and Dissonance in Visual Music. Organised Sound, 17, pp 114-119 doi:10.1017/ S1355771812000039 Request Permissions : Click here Downloaded from http://journals.cambridge.org/OSO, IP address: 134.173.130.244 on 24 Jul 2014 Consonance and Dissonance in Visual Music BILL ALVES Harvey Mudd College, The Claremont Colleges, 301 Platt Blvd, Claremont CA 91711 USA E-mail: [email protected] The concepts of consonance and dissonance broadly Plato found the harmony of the world in the Pythag- understood can provide structural models for creators of orean whole numbers and their ratios, abstract ideals visual music. -

The Devil's Interval by Jerry Tachoir
Sound Enhanced Hear the music example in the Members Only section of the PAS Web site at www.pas.org The Devil’s Interval BY JERRY TACHOIR he natural progression from consonance to dissonance and ii7 chords. In other words, Dm7 to G7 can now be A-flat m7 to resolution helps make music interesting and satisfying. G7, and both can resolve to either a C or a G-flat. Using the TMusic would be extremely bland without the use of disso- other dominant chord, D-flat (with the basic ii7 to V7 of A-flat nance. Imagine a world of parallel thirds and sixths and no dis- m7 to D-flat 7), we can substitute the other relative ii7 chord, sonance/resolution. creating the progression Dm7 to D-flat 7 which, again, can re- The prime interval requiring resolution is the tritone—an solve to either a C or a G-flat. augmented 4th or diminished 5th. Known in the early church Here are all the possibilities (Note: enharmonic spellings as the “Devil’s interval,” tritones were actually prohibited in of- were used to simplify the spelling of some chords—e.g., B in- ficial church music. Imagine Bach’s struggle to take music stead of C-flat): through its normal progression of tonic, subdominant, domi- nant, and back to tonic without the use of this interval. Dm7 G7 C Dm7 G7 Gb The tritone is the characteristic interval of all dominant bw chords, created by the “guide tones,” or the 3rd and 7th. The 4 ˙ ˙ w ˙ ˙ tritone interval can be resolved in two types of contrary motion: &4˙ ˙ w ˙ ˙ bbw one in which both notes move in by half steps, and one in which ˙ ˙ w ˙ ˙ b w both notes move out by half steps. -

The Unexpected Number Theory and Algebra of Musical Tuning Systems Or, Several Ways to Compute the Numbers 5,7,12,19,22,31,41,53, and 72
The Unexpected Number Theory and Algebra of Musical Tuning Systems or, Several Ways to Compute the Numbers 5,7,12,19,22,31,41,53, and 72 Matthew Hawthorn \Music is the pleasure the human soul experiences from counting without being aware that it is counting." -Gottfried Wilhelm von Leibniz (1646-1716) \All musicians are subconsciously mathematicians." -Thelonius Monk (1917-1982) 1 Physics In order to have music, we must have sound. In order to have sound, we must have something vibrating. Wherever there is something virbrating, there is the wave equation, be it in 1, 2, or more dimensions. The solutions to the wave equation for any given object (string, reed, metal bar, drumhead, vocal cords, etc.) with given boundary conditions can be expressed as a superposition of discrete partials, modes of vibration of which there are generally infinitely many, each with a characteristic frequency. The partials and their frequencies can be found as eigenvectors, resp. eigenvalues of the Laplace operator acting on the space of displacement functions on the object. Taken together, these frequen- cies comprise the spectrum of the object, and their relative intensities determine what in musical terms we call timbre. Something very nice occurs when our object is roughly one-dimensional (e.g. a string): the partial frequencies become harmonic. This is where, aptly, the better part of harmony traditionally takes place. For a spectrum to be harmonic means that it is comprised of a fundamental frequency, say f, and all whole number multiples of that frequency: f; 2f; 3f; 4f; : : : It is here also that number theory slips in the back door. -

Cubase Pro Plug-In Reference 10.5.20
Plug-in Reference Cristina Bachmann, Heiko Bischoff, Lillie Harris, Christina Kaboth, Insa Mingers, Matthias Obrecht, Sabine Pfeifer, Benjamin Schütte, Marita Sladek This PDF provides improved access for vision-impaired users. Please note that due to the complexity and number of images in this document, it is not possible to include text descriptions of images. The information in this document is subject to change without notice and does not represent a commitment on the part of Steinberg Media Technologies GmbH. The software described by this document is subject to a License Agreement and may not be copied to other media except as specifically allowed in the License Agreement. No part of this publication may be copied, reproduced, or otherwise transmitted or recorded, for any purpose, without prior written permission by Steinberg Media Technologies GmbH. Registered licensees of the product described herein may print one copy of this document for their personal use. All product and company names are ™ or ® trademarks of their respective owners. For more information, please visit www.steinberg.net/trademarks. © Steinberg Media Technologies GmbH, 2020. All rights reserved. Cubase Pro_10.5.20_en-US_2020-05-26 Table of Contents 4 Included Effect Plug-ins 4 Ambisonics Plug-ins 5 Delay Plug-ins 22 Distortion Plug-ins 46 Dynamics Plug-ins 70 EQ Plug-ins 79 Filter Plug-ins 85 Mastering Plug-ins 85 Modulation Plug-ins 100 Network Plug-ins 101 Other Plug-ins 103 Pitch Shift Plug-ins 106 Reverb Plug-ins 121 Spatial + Panner Plug-ins 123 Surround -
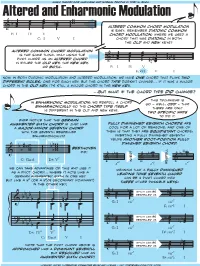
Altered and Enharmonic Modulation
Altered andmusic Enharmonictheory for musicians and normal people Modulation by toby w. rush œ œ w b œ œ œ nœ w Altered common chord modulation & œ œ is easy: remember diatonic common F: I IV V chord modulation, where we used a C: I V I chord that was diatonic in both the old and new keys? altered common chord modulation is the same thing, only using the œ œ pivot chord as an altered chord & b œ œ œ #nw in either the old key, the new key, œ # #œ w or both. F: I IV V n œ E: bVI V I Now, in both diatonic modulation and altered modulation, we have one chord that plays two different roles, one for each key. But the chord type doesn’t change... if it was a major chord in the old key, it’s still a major chord in the new key. ...but...but whatwhat ifif thethe chordchord typetype did change? this technique is in enharmonic modulation, we respell a chord so — well, odd — that so the enharmonically chord type itself there are only is different in the old and new keys. two specific ways to do it. ever notice that the german augmented sixth chord is just like fully diminished seventh chords are a major-minor seventh chord cool for a lot of reasons, and one of with the seventh respelled them is that they are equidistant chords: enharmonically? inverting a fully diminshed seventh yields another root-position fully dimished seventh chord. # w bw beethoven b ww b w did! & b w bw bw bww b ∫w 7 b w C: Ger.6 D : V b w b w w b & w7 invert & 6 & 7 a° a°5 respell c° we can take advantage of this and use it meaning that a fully diminished as a pivot chord.. -

The Consecutive-Semitone Constraint on Scalar Structure: a Link Between Impressionism and Jazz1
The Consecutive-Semitone Constraint on Scalar Structure: A Link Between Impressionism and Jazz1 Dmitri Tymoczko The diatonic scale, considered as a subset of the twelve chromatic pitch classes, possesses some remarkable mathematical properties. It is, for example, a "deep scale," containing each of the six diatonic intervals a unique number of times; it represents a "maximally even" division of the octave into seven nearly-equal parts; it is capable of participating in a "maximally smooth" cycle of transpositions that differ only by the shift of a single pitch by a single semitone; and it has "Myhill's property," in the sense that every distinct two-note diatonic interval (e.g., a third) comes in exactly two distinct chromatic varieties (e.g., major and minor). Many theorists have used these properties to describe and even explain the role of the diatonic scale in traditional tonal music.2 Tonal music, however, is not exclusively diatonic, and the two nondiatonic minor scales possess none of the properties mentioned above. Thus, to the extent that we emphasize the mathematical uniqueness of the diatonic scale, we must downplay the musical significance of the other scales, for example by treating the melodic and harmonic minor scales merely as modifications of the natural minor. The difficulty is compounded when we consider the music of the late-nineteenth and twentieth centuries, in which composers expanded their musical vocabularies to include new scales (for instance, the whole-tone and the octatonic) which again shared few of the diatonic scale's interesting characteristics. This suggests that many of the features *I would like to thank David Lewin, John Thow, and Robert Wason for their assistance in preparing this article. -

Chapter 28.5, the Diminished Seventh Chord in Modulation
598 THE COMPLETE MUSICIAN F. Write a progression in D minor in which the closing D tonic sounds more like a dominant than a tonic. (Hint: A Picardy third alone does not imply a reciprocal process.) G. Write a progression inC major that opens with a plagal progression, tonicizes E~ major, and closes in E~ major with a different plagal progression. The Diminished Seventh Chord and Enharmonic Modulation Beginning in the eighteenth century, composers used the diminished seventh chord both as a powerful goal-oriented applied chord and as a dramatic signpost. For example, a strategically placed diminished seventh chord could underscore a particularly emotional image from the text of a song. A vivid and painful example is heard in the last moment of Schubert's "Erlking." Immediately before we learn of the fate of the sick child ("and in [the father's] arms, the child ..."), the previous 145 measures of frantic, wildly galloping music come to a halt. The fermata that marks this moment, and which seems to last forever, is accompanied by a single sustained diminished seventh, underscoring this crucial moment (Example 28.8). We learn immediately thereafter that in spite of his valiant attempts to rush his sick son home by horseback, the father was too late: The child was dead. EXAMPLE 28.8 Schubert, "Erlkonig," D. 328 Even before the time of Bach, composers also used the diminished seventh chord to create tonal ambiguity. Ambiguity is possible because the chord in any of its inversions partitions the octave into four minor thirds (using enharmonicism). For example, given the diminished seventh chord in Example 28.9A, its three inversions produce no new intervals. -

Enharmonic Paradoxes in Classical, Neoclassical, and Popular Music By
Enharmonic Paradoxes in Classical, Neoclassical, and Popular Music by Haley Britt Beverburg Reale A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Music: Theory) in The University of Michigan 2011 Doctoral Committee: Associate Professor Ramon Satyendra, Chair Professor Walter T. Everett Professor Kevin E. Korsyn Professor Herbert Graves Winful Associate Professor Wayne C. Petty © Haley Britt Beverburg Reale 2011 Dedication36B To my husband ii Acknowledgements37B I could not have completed this dissertation without the support of numerous people. I would especially like to thank my adviser, Ramon Satyendra, for his encouragement and boundless optimism through the whole process. He never failed to receive my ideas with enthusiasm and give me the confidence to pursue them, and his wide-ranging knowledge and helpful suggestions sparked many bursts of creativity over the past several years. I would also like to thank the other members of my dissertation committee— Kevin Korsyn, Wayne Petty, Walter Everett, and Herbert Winful—for their advice and support. Their expertise in diverse subjects was invaluable to me, and they were always willing and able to answer my many questions. I also had the privilege of working with and being inspired by many other faculty members at the University of Michigan. Special thanks to Karen Fournier for being a sounding board for many of my research ideas and for being a great listener. Additionally, I would like to acknowledge the Rackham School of Graduate Studies, especially Dean Steven M. Whiting, for financial support throughout my time at the University of Michigan. The teaching assistantships, fellowships, and travel grants for presenting at conferences gave me the means to pursue my research. -

Musical Tuning Systems As a Form of Expression
Musical Tuning Systems as a Form of Expression Project Team: Lewis Cook [email protected] Benjamin M’Sadoques [email protected] Project Advisor Professor Wilson Wong Department of Computer Science This report represents the work of WPI undergraduate students submitted to the faculty as evidence of completion of a degree requirement. WPI routinely publishes these reports on its website without editorial or peer review. For more information about the projects program at WPI, please see http://www.wpi.edu/academics/ugradstudies/project- learning.html Abstract Many cultures and time periods throughout history have used a myriad of different practices to tune their instruments, perform, and create music. However, most musicians in the western world will only experience 12-tone equal temperament a represented by the keys on a piano. We want musicians to recognize that choosing a tuning system is a form of musical expression. The goal of this project was to help musicians of any skill-level experience, perform, and create music involving tuning systems. We created software to allow musicians to experiment and implement alternative tuning systems into their own music. ii Table of Contents Abstract ................................................................................................................................... ii Table of Figures .................................................................................................................... vii 1 Introduction ........................................................................................................................