Competitive Tendering Versus Performance-Based Negotiation in Public Transport
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Swiss Tourism in Figures 2017 Structure and Industry Data
SWISS TOURISM IN FIGURES 2017 STRUCTURE AND INDUSTRY DATA PARTNERSHIP. POLITICS. QUALITY. Edited by Swiss Tourism Federation (STF) In cooperation with GastroSuisse | Public Transport Association | Swiss Cableways | Swiss Federal Statistical Office (SFSO) | Swiss Hiking Trail Federation | Switzerland Tourism (ST) | SwitzerlandMobility Imprint Production: Béatrice Herrmann, STF | Photo: Alina Trofimova | Print: Länggass Druck AG, 3000 Bern The brochure contains the latest figures available at the time of printing. It is also obtainable on www.stv-fst.ch/stiz. Bern, July 2018 3 CONTENTS AT A GLANCE 4 LEGAL BASES 5 TOURIST REGIONS 7 Tourism – AN IMPORTANT SECTOR OF THE ECONOMY 8 TRAVEL BEHAVIOUR OF THE SWISS RESIDENT POPULATION 14 ACCOMMODATION SECTOR 16 HOTEL AND RESTAURANT INDUSTRY 29 TOURISM INFRASTRUCTURE 34 FORMAL EDUCATION 47 INTERNATIONAL 49 QUALITY PROMOTION 51 TOURISM ASSOCIATIONS AND INSTITUTIONS 55 4 AT A GLANCE CHF 46.7 billion 1 total revenue generated by Swiss tourism 27 993 km public transportation network 25 503 train stations and stops 54 911 905 air passengers 467 263 flights CHF 16.9 billion 1 gross value added 29 022 restaurants 8009 trainees CHF 16.0 billion 2 revenue from foreign tourists in Switzerland CHF 16.1 billion 2 outlays by Swiss tourists abroad 165 675 full-time equivalents 1 37 392 740 hotel overnight stays average stay = 2.0 nights 4878 hotels and health establishments 275 203 hotel beds One of the largest export industries in Switzerland 4.4 % of export revenue 1 Swiss Federal Statistical Office,A nnual indicators -

Good Practices in Multimodal Transport
Sustainable Mobility and Tourism in Sensitive Areas of the Alps and the Carpathians: GOOD-PRACTICE COLLECTION FOR MULTIMODAL TRANSPORT WP 5 | Action 5.1 Miriam L. Weiß (EURAC research) revised by Sabine Stranz (GeoSys Wirtschafts- und Regionalentwicklungs GmbH) Bolzano & Graz, 19/11/2012 Authors: Miriam L. Weiß, Filippo Favilli, Désirée Seidel, Alessandro Vinci Coordination: Thomas Streifeneder EURAC research (PP 6) Revision: Sabine Stranz, GeoSys Wirtschafts- und Regionalentwicklungs GmbH Participating project partners: Rada Pavel, CJIT Maramures – County Center for Tourism Information, Romania GOOD-PRACTICE COLLECTION FOR MULTIMODAL TRANSPORT page 2 TABLE OF CONTENTS 1 Summary ................................................................................................................................................... 6 2 Approach – Analysis – Method ............................................................................................................... 10 3 Introduction............................................................................................................................................. 17 4 Objectives ................................................................................................................................................ 18 5 Good-practice Examples.......................................................................................................................... 19 5.1 Accessibility by Public Transport .................................................................................................... -

Swiss Post Annual Report 2016
WHENEVER, WHEREVER AND HOWEVER IT SUITS ME. ANNUAL REPORT 2016 Group Business activities Communication market: Letters, newspapers, small goods, promotional mailings, solutions for business process outsourcing and innovative services in document solutions in Switzerland and internationally Logistics market: Parcel post, express and SameDay services, and e-commerce and logistics solutions within Switzerland and abroad Financial services market: Payments, savings, investments, retirement planning and financing in Switzerland as well as international payment transactions Passenger transport market: Regional, municipal and urban transport, system services and mobility solutions in Switzerland and in selected countries abroad Our performance in 2016 Key figures 2016 Strategic goal Operating income CHF million 8,188 – Operating profit (EBIT) CHF million 704 700 – 900 Group profit CHF million 558 – Equity CHF million 4,881 – Degree of internal financing – investments Percent 100 100 Addressed letters In millions 2,089 – Parcels In millions 122 – Avg. PostFinance customer assets CHF billion 119 – PostBus passengers (Switzerland) In millions 152 – Customer satisfaction Index (scale of 0 – 100) 80 ≥ 78 Headcount Full-time equivalents 43,485 – Employee commitment Index (scale of 0 – 100) 82 > 80 1 CO2 efficiency improvement since 2010 Percent 16 10 1 Target for 2016. Organization chart Swiss Post Ltd as at 31 December 2016 Chairman of the Board of Directors Urs Schwaller Group Audit Martina Zehnder CEO Susanne Ruoff * Communication Corporate Center -

Swiss Tourism in Figures 2018 Structure and Industry Data
SWISS TOURISM IN FIGURES 2018 STRUCTURE AND INDUSTRY DATA PARTNERSHIP. POLITICS. QUALITY. Edited by Swiss Tourism Federation (STF) In cooperation with GastroSuisse | Public Transport Association | Swiss Cableways | Swiss Federal Statistical Office (SFSO) | Swiss Hiking Trail Federation | Switzerland Tourism (ST) | SwitzerlandMobility Imprint Production: Martina Bieler, STF | Photo: Silvaplana/GR (© @anneeeck, Les Others) | Print: Länggass Druck AG, 3000 Bern The brochure contains the latest figures available at the time of printing. It is also obtainable on www.stv-fst.ch/stiz. Bern, July 2019 3 CONTENTS AT A GLANCE 4 LEGAL BASES 5 TOURIST REGIONS 7 Tourism – AN IMPORTANT SECTOR OF THE ECONOMY 8 TRAVEL BEHAVIOUR OF THE SWISS RESIDENT POPULATION 14 ACCOMMODATION SECTOR 16 HOTEL AND RESTAURANT INDUSTRY 29 TOURISM INFRASTRUCTURE 34 FORMAL EDUCATION 47 INTERNATIONAL 49 QUALITY PROMOTION 51 TOURISM ASSOCIATIONS AND INSTITUTIONS 55 4 AT A GLANCE CHF 44.7 billion 1 total revenue generated by Swiss tourism 28 555 km public transportation network 25 497 train stations and stops 57 554 795 air passengers 471 872 flights CHF 18.7 billion 1 gross value added 28 985 hotel and restaurant establishments 7845 trainees CHF 16.6 billion 2 revenue from foreign tourists in Switzerland CHF 17.9 billion 2 outlays by Swiss tourists abroad 175 489 full-time equivalents 1 38 806 777 hotel overnight stays average stay = 2.0 nights 4765 hotels and health establishments 274 792 hotel beds One of the largest export industries in Switzerland 4.4 % of export revenue -

Swiss Tourism in Figures 2016 Structure and Industry Data
SWISS TOURISM IN FIGURES 2016 STRUCTURE AND INDUSTRY DATA PARTNERSHIP. POLITICS. QUALITY. Edited by Swiss Tourism Federation (STF) In cooperation with GastroSuisse | Public Transport Association | Swiss Cableways | Swiss Federal Statistical Office (SFSO) | Swiss Hiking Trail Federation | Switzerland Tourism (ST) | SwitzerlandMobility Imprint Production: Béatrice Herrmann, STF | Photo: Matthias Nutt, Lobhornhütte | Print: Länggass Druck AG, 3000 Bern The brochure contains the latest figures available at the time of printing. It is also obtainable on www.stv-fst.ch. Bern, July 2017 3 CONTENTS AT A GLANCE 4 LEGAL BASES 5 TOURIST REGIONS 7 Tourism – AN IMPORTANT SECTOR OF THE ECONOMY 8 TRAVEL BEHAVIOUR OF THE SWISS RESIDENT POPULATION 14 ACCOMMODATION SECTOR 16 HOTEL AND RESTAURANT INDUSTRY 29 TOURISM INFRASTRUCTURE 34 FORMAL EDUCATION 47 INTERNATIONAL 49 QUALITY PROMOTION 51 TOURISM ASSOCIATIONS AND INSTITUTIONS 55 4 AT A GLANCE CHF 44.8 billion 1 total revenue generated by Swiss tourism 28 425 km public transportation network 24 012 train stations and stops 51 865 546 air passengers 468 226 flights CHF 16.4 billion 1 gross value added 29 072 restaurants 8266 trainees CHF 16.0 billion 2 revenue from foreign tourists in Switzerland CHF 16.3 billion 2 outlays by Swiss tourists abroad 163 750 full-time equivalents 1 35 532 576 hotel overnight stays average stay = 2.0 nights 4949 hotels and health establishments 271 710 hotel beds One of the largest export industries in Switzerland 4.7 % of export revenue 1 Swiss Federal Statistical Office,A -
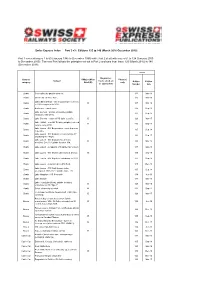
Swiss Express Index Part 3 V3 : Editions 125 to 140 (March 2016-December 2019)
Swiss Express Index Part 3 v3 : Editions 125 to 140 (March 2016-December 2019) Part 1 covered issues 1 to 60 (January 1985 to December 1999) while Part 2 dealt with issues 61 to 124 (January 2000 to December 2015). This new Part follows the principles set out in Part 2 and runs from Issue 125 (March 2016) to 140 (December 2019). Issue Diagram(s) - General If Major (M) or Photo(s) Subject track, stock etc category Brief (B) only Edition Edition as appropriate Number date Boats Commuting by paddle steamer. 133 Mar-18 Boats DS St Urs on River Aare 125 Mar-16 Lakes Brienz/Thun - rise in passenger numbers Boats B 137 Mar-19 in 2018 compared to 2017. Boats Bodensee Train Ferries 139 Sep-19 Lake Geneva - parade of (mostly) paddle Boats 127 Sep-16 steamers, May 2016. Boats Lake Geneva - return of PS Italie to traffic. B 129 Mar-17 Lake Hallwil - new MV Delphin (dolphin) entered Boats B 135 Sep-18 service June 2018. Lake Luzern - MV Bürgenstock - new ship now Boats 135 Sep-18 in service. Lake Luzern - MV Diamant in service May 17 Boats 131 Sep-17 (replacing the "Rigi"). Lake Luzern - MV Diamant holed in an Boats B 133 Mar-18 accident, Dec.18. Update in Issue 134. Boats Lake Luzern - scrapping of freighter MV Luzern 137 Mar-19 Boats Lake Luzern - MV Mythen damaged at Gersau. B 135 Sep-18 Boats Lake Luzern - MV Rigi to be withdrawn in 2017. 127 Sep-16 Boats Lake Luzern - A quick trip on MV Rütli. -

Annual Report 2011 We Move People, Goods, Money and Information – in a Reliable, Value-Enhancing and Sustainable Way
Better support Tailor-made Everything you need A Perfectly coordinated More impact Reliability on an international scale A first-class range of services for our customers Annual Report 2011 We move people, goods, money and information – in a reliable, value-enhancing and sustainable way Group Business Communication market Letters, newspapers, promotional mailings, information solutions and data management in Switzerland, in the crossborder market and activities internationally Logistics market Parcels, express services and logistics solutions within Switzerland and abroad Retail fi nancial market Payments, savings, investments, retirement planning and fi nancing in Switzerland as well as international payment transactions Public passenger transport Regional, municipal and urban transport plus system management in Switzerland and in selected countries abroad. Performance Key fi gure 2011 Strategic goal 2011 Operating income CHF million 8,599 – Group profi t CHF million 904 700 – 800 Equity CHF million 4,879 – Degree of internal fi nancing Percent 100 – Addressed letters Number in millions 2,334 – Parcels Number in millions 107 – Customer deposits (PostFinance) CHF billion 88.1 – No. PostBus passengers (Switzerland) Millions 124 – Customer satisfaction Index (scale of 0– 100) 79 ≥ 75 Employees Full-time equivalents 44,348 – Employee commitment Index (scale of 0– 100) 83 > 80 * CO2 emissions saved per year t CO2 equivalent 3,115 – 15,000 *by end of 2013 Organisation Chairman of the Board of Directors Peter Hasler Internal Auditing Martina Zehnder -
Zeeus Ebus Report #2 | Ebus Report Zeeus
ZeEUS in brief Scope Testing electrification solutions at the heart of the urban bus system network through live urban demonstrations and facilitating the market uptake of electric buses in Europe. Duration Nov 2013 – April 2018 [ 54 Months ] ZeEUS Budget 22.5m EUR [ 13.5 EU Funding ] Coordinator UITP, the International Association of Public Transport eBus Report #2 An updated overview of electric buses in Europe Partners An updated overview of electric buses in Europe electric of overview An updated | Stockholm Public Transport ZeEUS eBus Report #2 eBus Report ZeEUS www.zeeus.eu The ZeEUS project is coordinated by UITP. ZeEUS is co-funded by the European Commission under the 7th Research & Innovation Framework Programme, Mobility & Transport Directorate General under grant agreement n° 605485. The ZeEUS project has been launched by the European Commission in the frame of the European Green Vehicle and Smart Cities & Communities. ZeEUS eBus Report #2 An updated overview of electric buses in Europe FOREWORD TO ZEEUS REPORT 2017 Profound changes in how we enjoy mobility are under way. Traditional approaches are being trans- formed through shared mobility services and easier shifts between transport modes. Technology and societal needs continue to drive change. Digitalisation, automation and alternative energy sources are challenging traditional features and creating new opportunities linked with resource efficiency and the collaborative and circular economy. However, such changes can also be disruptive. While they create new jobs, they can also make others obsolete. They call for new skills, good working conditions and need anticipation, adaptation and investment. Transport needs to develop along a more sustainable path. -
FINANCIAL REPORT 2018 About This Financial Report
SWISS POST IS RIGHT HERE. FOR EVERYONE. FINANCIAL REPORT 2018 About this Financial Report Structure of annual reporting documents The Swiss Post annual reporting documents for 2018 consist of: – Swiss Post Annual Report – Swiss Post Financial Report (this document, consisting of the management report and corporate governance section as well as the annual financial statements for the Group, Swiss Post Ltd and PostFinance Ltd) – PostFinance Ltd Annual Report – Sustainability Report (report in accordance with the Global Reporting Initiative guidelines) – Annual Report key figures True-to-scale representation of figures in charts Charts are shown to scale to present a true and fair view. 20 mm is equivalent to one billion francs. Percentages in charts are standardized as follows: Horizontal: 75 mm is equivalent to 100 percent. Vertical: 40 mm is equivalent to 100 percent. Key for charts and tables Current year Previous year Positive effect on result Negative effect on result Languages This Financial Report is available in English, German, French and Italian. The German version is authoritative. Ordering Electronic versions of the annual reporting documents are available at www.swisspost.ch/annualreport. The Annual Report and Financial Report are also available in printed form. Forward-looking statements This report contains forward-looking statements. They are based on current management estimates and projections, and on the information currently available to management. Forward-looking statements are not intended as guarantees of future performance and results, which remain dependent on many different factors; they are subject to a variety of risks and uncertainties, and are based on assumptions that may not prove accurate. -
Financial Report 2019 (PDF)
Swiss Post is right here. For everyone. Financial Report 2019 About this Financial Report Forward-looking statements This report contains forward-looking statements. They are based on current management estimates and projections, and on the information currently available to management. Forward-looking statements are not intended as guarantees of future performance and results, which remain dependent on many different factors; they are subject to a variety of risks and uncertainties, and are based on assumptions that may not prove accurate. Annual reporting structure The Swiss Post annual reporting documents for 2019 consist of: – Swiss Post Annual Report – Swiss Post Financial Report (this document, consisting of the management report and corporate governance section as well as the annual financial statements for the Group, Swiss Post Ltd and PostFinance Ltd) – PostFinance Ltd Annual Report – Sustainability Report (report in accordance with the Global Reporting Initiative guidelines) – Annual Report key figures Ordering Electronic versions of the annual reporting documents are available at www.swisspost.ch/annualreport. The Annual Report and Financial Report are also available in printed form. True-to-scale representation of figures in charts Charts are shown to scale to present a true and fair view. 20 mm is equivalent to one billion francs. Percentages in charts are standardized as follows: Horizontal: 75 mm is equivalent to 100 percent. Vertical: 40 mm is equivalent to 100 percent. Key for charts and tables Current year Previous year Positive effect on result Negative effect on result Plan or goal If the figures shown are not comparable with the more recent figures (e.g. due to a change in method or change in the scope of consolidation), this is shown as follows: Non-comparable prior-year figure Non-comparable difference with positive effect on result Non-comparable difference with negative effect on result Languages This Financial Report is available in English, German, French and Italian. -
Download Brochure
Summary. Editorial 3 In the heart of Europe 4 Valais statistics 5 Valais industry statistics 6 Food production 8 Automobile and aviation industry 10 Well-being and beauty 12 Cleantech 14 Energy 16 Construction machinery 18 Precision mechanics 20 Microtechnology 22 Pharmaceuticals, chemistry and biotechnology 24 Health and medtech 26 Information and communication technology (ICT) 28 Innovation, research and development 30 Valais. An experience without limits. 32 The Valais brand 33 Partners 34 List of companies 35 Valais, land of industry! Situated in the heart of the Alps in a breath- taking natural setting that alternates be- tween green plains and deep snow, Valais is also notable for its flourishing industry which combines cutting-edge technologies and innovative competence centres. From family-run SMEs to budding start-ups and large international groups, Valais stands out by offering ideal conditions for indus- try and technology, which marks it out as a canton of excellence and quality. Driven by the dynamic which runs through the can- ton, the industries of Valais are combining their forces on joint projects. This brochure represents another step towards strength- ening cooperation within Valais industries. You’ll see Valais in a new light - a Valais of great diversity and remarkable expertise. Christophe Darbellay Cantonal Councillor Head of the Department of Economy and Education 3 Denmark Sweden Latvia In the heart of Europe. Lithuania Russia Belarus Russia Ireland Denmark Sweden the United Kingdom the Netherlands Poland Germany Belgium Latvia Lithuania Czech Russia Republic Luxembourg Belarus Ukraine Russia Ireland Kaz. the United Kingdom the Netherlands Poland Austria Germany Lichtenstein Moldova Belgium France Switzerland Hungary Czech A strategic position Republic Slovenia Luxembourg Ukraine Roumanie on the north-southKaz. -

Facts and Figures As at 31 December 2016 Portrait
Facts and figures As at 31 December 2016 Portrait PostBus is the market leader in public bus transport in Switzerland. With over 4,000 members of staff (including drivers employed by PostBus operators) and around 2,250 vehicles, PostBus carries approximately 152 million passengers per year. The company has 72 million francs of equity capital. The hallmarks of PostBus – the three-tone horn and the yellow Postbuses – are part of Switzerland’s cultural identity. The PostBus brand embodies reliability, security and trust. Increasingly, it also represents innovative, sustainable public transport. PostBus is a leading provider of system management functionality in public transport. Around 150 PostBus operators cover a considerable proportion of the kilometres travelled in Switzer- land, as well as carrying out the important task of establishing a strong position for the company among the public. Swiss Post is the sole owner of PostBus. The foreign companies CarPostal France and PostAuto Liechtenstein Anstalt, as well as the bike-sharing service PubliBike AG, all be- long to PostBus Switzerland Ltd. History The first stage in the founding of PostBus dates back to the creation of a horse-drawn postal network in 1849. Its last remaining representative – the legendary Gotthardpost – is still in circulation to this day on the Gotthard pass road, to the great delight of many visitors. The first scheduled automobile mail route was introduced between Berne and Detligen in 1906. Since then, the route network in Switzerland has been continual- ly expanded. PostBus transported more than 100 million passengers for the first time in 2003. It took its first steps abroad in the Principality of Liechtenstein in 2001, and in Dole, France, in 2004.