Understanding the Design Tradeoffs for Cooperative Streaming Multicast
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unsorted Bookmarks Unsorted Bookmarks > Plugins
Downloaded from: justpaste.it/mybookmarks Unsorted Bookmarks Unsorted Bookmarks > Unsorted Academic Earth | Online Courses | Plugins Bookmarks Academic Video Lectures > Cricket Revolution - A Multiplayer PC WP Profiles | Nick Momrik | Cricket Game Profile storytelling Add-ons for Firefox WP Profiles | automattic | Profile WineHQ - Run Windows applications WP Profiles | Alex M. on Linux, BSD, Solaris and Mac OS X (Viper007Bond) | Profile Storybird - News pygame - python game WordPress › Yet Another Collaborative development Related Posts Plugin « storytelling PCSX2 Playstation 2 emulator - News WordPress Plugins The Online Sizzled Core - Internet, Web 2.0, Community Technology for Writers - Sizlopedia Unsorted Bookmarks > Writing.Com Shahan's World Protagonize: Google AdWords: Keyword Tool bookmarksBackup+notes collaborative Google Analytics | Official Website story & Online Contextual Advertising and My Bookmarks creative Behavioral Marketing Services Paste HTML: free anonymous fiction writing W3Schools Online Web Tutorials HTML hosting community Linkbucks.com - Make money when justpaste.it - publish text and people leave your website! share with friends Pay Per Click Advertising - In Text textsnip - Keep your text & code Ads for Websites by Infolinks formatting safe from IM and Squidoo : Welcome to Squidoo Email Digital Products Retailer: Affiliate Pen - Simple Online Publishing Program & Sell Online - ClickBank TextLinkAds | The Leader in Text Link Search Engine Optimization Tribal Fusion Traffic Junky Ad Broker - Online Internet Marketing Services whos.amung.us Diigo - Web Highlighter and Sticky Notes, Online Bookmarking and Annotation, Personal Learning Network. PhysOrg.com - Science News, Technology, Physics, Nanotechnology, Space Science, Earth Science, Medicine reddit.com: what's new online! Blogging Discussion, Tips & Tricks – Blogussion Knol - a unit of knowledge: share what you know, publish your expertise. -

20Entrepreneurial Journalism
Journalism: New Challenges Karen Fowler-Watt and Stuart Allan (eds) Journalism: New Challenges Edited by: Karen Fowler-Watt and Stuart Allan Published by: Centre for Journalism & Communication Research Bournemouth University BIC Subject Classification Codes: GTC Communication Studies JFD Media Studies KNTD Radio and television industry KNTJ Press and journalism JNM Higher and further education, tertiary education First published 2013, this version 1.02 ISBN: 978-1-910042-01-4 [paperback] ISBN: 978-1-910042-00-7 [ebook-PDF] ISBN: 978-1-910042-02-1 [ebook-epub] http://microsites.bournemouth.ac.uk/cjcr/ Copyright © 2013 Acknowledgements Our first thank you is to the contributors who made Journalism: New Challenges possible, not least for so generously sharing their expertise, insights and enthusiasm for this approach to academic e-publishing. This endeavour was supported by the Centre for Journalism and Communication Research (CJCR), here in the Media School at Bournemouth University, UK. With regard to the production and distribution of this book, we are grateful to Einar Thorsen and Ann Luce for their stellar efforts. They would like to thank, in turn, Carrie Ka Mok for setting its design and layout, and Ana Alania for contributing ideas for the cover. Many thanks as well to Mary Evans, Emma Scattergood and Chindu Sreedharan for their helpful sugges- tions on how to develop this publishing venture. Karen Fowler-Watt and Stuart Allan, editors Table of contents Introduction i Karen Fowler-Watt and Stuart Allan Section One: New Directions -

HET- Nets 2010
Performance Modelling and Evaluation of Heterogeneous Networks PROCEEDINGS OF 6 TH WORKING INTERNATIONAL CONFERENCE HET- NETs 2010 EDITOR Tadeusz Czachórski Gliwice 2009 PUBLISHED BY Institute of Theoretical and Applied Informatics of the Polish Academy of Sciences Bałtycka 5, 44-100 Gliwice, POLAND www.iitis.gliwice.pl TECHNICAL PROGRAM COMMITTEE Tulin Atmaca, France Demetres Kouvatsos, UK Simonetta Balsamo, Italy Udo Krieger, Germany Andrzej Bartoszewicz, Poland Józef Lubacz, Poland Monique Becker, France Wojciech Molisz, Poland Wojciech Burakowski, Poland Andrzej R. Pach, Poland Leszek Borzemski, Poland António Pacheco, Portugal Jalel Ben-Otman, France Michele Pagano, Italy Vicente Casares-Giner, Spain Zdzisław Papir, Poland Ram Chakka, India Ferhan Pekergin, France Tadeusz Czachórski, Poland Nihal Pekergin, France Tien Do, Hungary Michał Pióro, Poland Peter Emstad, Norway Adrian Popescu, Sweden Markus Fiedler, Sweden David Remondo-Bueno, Spain Jean Michele Fourneau, France Werner Sandmann, Germany Erol Gelenbe, UK Maciej Stasiak, Poland Adam Grzech, Poland Zhili Sun, UK Andrzej Grzywak, Poland Nigel Thomas, UK Peter Harrison, UK Phuoc Tran-Gia, Germany Andrzej Jajszczyk, Poland Tereza Vazao, Portugal Wojciech Kabaciński, Poland Krzysztof Walkowiak, Poland Sylwester Kaczmarek, Poland Sabine Wittevrongel, Belgium Andrzej Kasprzak, Poland Józef Woźniak, Poland Jerzy Konorski, Poland ORGANIZING COMMITTEE Chair: Krzysztof Grochla [email protected], Phone: +48 32 231 73 19 ext 218; Fax: +48 32 231 70 26 Joanna Domańska Sławomir Nowak Cover designed by Krzysztof Grochla ISBN: 978-83-926054-4-7 CONTENTS Keynote Talks Erol Gelenbe: Steps towards self-aware networks ................................................ 9 Michał Pióro: On the notion of max-min fairness and its applications in network design ...................................................................................................... 11 Vincente Casares-Giner: Mobility models for mobility management .................. -

Domicil40! 1969 – 2009 Jazz World Music Avantgarde in Dortmund Impressum Mitglieder Inhalt
1 domicil40! 1969 – 2009 jazz world music avantgarde in dortmund impressum mitglieder inhalt 40 Jahre domicil – Die Jubiläumszeitung Aktive Mitglieder 3 grußworte domicil Dortmund e.V. Christoph Aderholz, Gürcan Alev, Susann Bach, Maryam Hansastraße 7 – 11, 44137 Dortmund Baghery, Heinz-Joachim Bahr, Michael Batt, Michael Rainer 4 wie alles anfing 26 dienstleister domicil Berger, Karin Blöcher, Stefan Blohm, Jesper Boenke, Ralph Vorstand Udo Wagener (1. Vorsitzender) parallele welten 29 Brix, Ute Brüggemann, Jürgen Brunsing, Franziska Burkhard, 7 mal tacheles Telefon 0231 – 862 90 30 (Büro gGmbH) Dorothea Dannert, Aysun Demir, Karl-Heinz Deyer, Maksim www.domicil-dortmund.de 8 bühne frei für‘s ehrenamt 30 shake your booty, baby Diagilew, Nicola Dornseifer, Doris Feindt, Ulrike Flaspöhler, V.i.S.d.P. Udo Wagener Astrid Fliedner, Uwe Forsthövel, Uwe Geitner, Dr. Vera Gerling, 10 vierzig gründe, das domicil zu mögen 32 kunstausstellungen im domicil Jörg Gerlings, Michael Gremmelmaier, Stu Grimshaw, Michael Idee und Konzept Günter U. Maiß Gründel, Julia Haase, Andreas Heuser, Achim Kämper, Markus 12 ein musikmöbel mit profil 34 lebe wohl leopoldstraße! hallo hansastraße! 2Chefredakteur Ralph Brix Keil, Anke Klusmeier, Stefan Kronenberg, Sebastian Kruse, Mario Küchler, Dr. Klaus Kwetkat, Ludger Lammers, Jürgen 14 domicil milestones 37 hansastraße und co. Redaktion (Konzept, Text, Bild) Leuchtmann, Gerald Linning-Droste, Jeannette Lochny, Günter Günter U. Maiß, Andre Noll, Frank Scheele 17 wer vor stand 38 mehr als nur ein kurzer auftritt Maiß, Gabriele Maleike, Petra Mecklenburg, Torsten Michael, Autoren Michael Batt (mb), Ralph Brix (rab), Gün- Crispin Müller, Elke Nachtigall, Andre Noll, Hans-Joachim 18 montag? – da is‘ domicil! 40 pinnwand ter U. -

Watching Television Over an IP Network
Watching Television Over an IP Network Meeyoung Cha⋆ Pablo Rodriguez¶ Jon Crowcroft† Sue Moon‡ Xavier Amatriain¶ ⋆MPI-SWS ¶Telefonica Research †University of Cambridge ‡KAIST ABSTRACT 1. INTRODUCTION For half a century, television has been a dominant and per- Since the 1950’s, television has been a dominant and perva- vasive mass media, driving many technological advances. sive mass media; it is watched across all age groups and by Despite its widespread usage and importance to emerging almost all countries in the world. Over the years, television applications, the ingrained TV viewing habits are not com- has transformed itself into a new media. The number of pletely understood. This was primarily due to the difficulty channels has increased from a few free-to-air broadcasts to of instrumenting monitoring devices at individual homes at several hundreds for cable, satellite, and Internet TV net- a large scale. The recent boom of Internet TV (IPTV) has works, that transmit more channels to each user. The video enabled us to monitor the user behavior and network usage signal itself has changed from black & white and color analog of an entire network. Such analysis can provide a clearer to high-quality digital stream. picture of how people watch TV and how the underlying Many technological advances were produced by trying to networks and systems can better adapt to future challenges. meet user needs and expectations in such a widespread me- In this paper, we present the first analysis of IPTV work- dia. For example, the large number of users that concur- loads based on network traces from one of the world’s largest rently watch TV sparked the use of IP multicast by network IPTV systems. -
David Arendale's 2017 Guide to Ipad Apps
David Arendale’s 2017 Guide to iPad Apps Revised February 24, 2017 Photos courtesy Apple, Inc. David Arendale, Ph.D., Associate Professor of History and Higher Education, Manager EOA National Best Practices Center, and Author “Access at the Crossroads: Learning Assistance in Higher Education.” http://z.umn.edu/bookinfo University of Minnesota, 275D Peik Hall, Curriculum & Instruction Department, College of Education and Human Development, 159 Pillsbury Drive SE, Minneapolis, MN 55455; [email protected]; http://arendale.org; (612) 625-2928; http://twitter.com/DavidArendale; http://www.linkedin.com/in/davidarendale Click on this link, http://z.umn.edu/davidipadapps to download the most recent version of this directory. Click on this link, http://z.umn.edu/appletvapps to download the most recent version of a companion directory that provides an overview of Apple TV apps downloaded by David Arendale for educational and personal use. Introduction This document provides an overview of the iPads apps I have found useful as an educator and in my personal life. Most of the apps were free, some cost a dollar or two. Only a few cost $9.99. Many thanks to my colleagues in my home academic department of Curriculum & Instruction as well as the College of Education and Human Development staff within the Office of Information Technology at the University of Minnesota. I received good recommendations from them reflected in this document. Updating iPad Apps If you own an iPad2 or higher, updating apps is not a problem. In fact, the new Apple operating system has made it easier. If you own the original iPad1, updating has stopped since Apple will no longer provide updated operating systems. -

Revista INFO
MINILAPTOPS Tecnologia.Tendências.Internet Dell x Sony EXCEL Coloque dois gráficos num só GENOMA VÍDEO Hackear o DNA 6 opções para curtir virou hobby! o melhor do streaming TENDÊNCIAS FOTO O que você pode ganhar Com o HDR, você cria com a geração web imagens surpreendentes Wii iPHONE Por que o console está 3 táticas para adaptar virando coisa séria um blog para a telinha CARREIRA Fumar pode ser DÁ PARA pior do que ter CONFIAR NO ficha na polícia 00278> WWW.INFO.ABRIL.COM.BR B 9 771415 327006 R$ 10,95 Google ABRIL 2009 SÓ ESTE ANO PELO MENOS 10 FALHAS CRÍTICAS s, BUS AFETARAM GMAIL,GMAIL, GOOGLEGOOGLE DOCDOCs, BUSCA... (NEM EXPOSTO) CONFIRA 16 DICAS PARA NÃO FICAR NA MÃO Abril2009 UMA DAS SUMÁRIO MATÉRIAS DESTA TIRAGEM DA EDIÇÃO: 183 580 EXEMPLARES EDIÇÃO É UMA PPEGADINHAº DE ABRIL DE 1 B SAIBASAI PÁGINA MAIS NA8 8 SCRAP 10 WWW.INFO.ABRIL.COM.BR 12 CORREIO LIVRE MASHUP 15 16 MASHUP 24 JOHN C. DVORAK 26 DAGOMIR MARQUEZI 28 SANDRA CARVALHO TENDÊNCIAS 45 46 PLANETA TERRA A produção de energia eólica no Brasil tem tudo para decolar no ano de 2009 CAPA 32 © 1 50 BIOTECNOLOGIA Como biólogos amadores estão alterando o DNA em laboratórios DÁ PARA CONFIAR NO GOOGLE? de fundo de quintal FALHAS SUCESSIVAS EM SERVIÇOS COMO O BUSCADOR, O GMAIL 54 ENTREVISTA E O GOOGLE DOCS MOSTRAM QUE NADA É INFALÍVEL Don Tapscott explica como a nova geração web influencia o modo como vivemos 76 CARREIRA 94 VÍDEO • TES TE T O cigarro pode queimar as O streaming tem tudo para S E E T chances de contratação em superar as redes P2P T INOVAÇÃO LAB 57 E INFO S empresas -
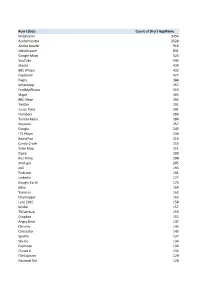
Row Labels Count of Short Appname Mobileiron 3454 Authenticator 2528
Row Labels Count of Short AppName MobileIron 3454 Authenticator 2528 Adobe Reader 916 vWorkspace 831 Google Maps 624 YouTube 543 iBooks 434 BBC iPlayer 432 Facebook 427 Pages 388 WhatsApp 357 FindMyiPhone 313 Skype 303 BBC News 292 Twitter 291 Junos Pulse 291 Numbers 289 TuneIn Radio 284 Keynote 257 Google 243 ITV Player 234 BoardPad 219 Candy Crush 215 Tube Map 211 Zipcar 209 Bus Times 208 mod.gov 205 4oD 193 Podcasts 191 LinkedIn 177 Google Earth 172 eBay 164 Yammer 163 Citymapper 163 Lync 2010 158 Kindle 157 TVCatchup 153 Dropbox 152 Angry Birds 147 Chrome 143 Calculator 143 Spotify 137 Sky Go 136 Evernote 134 iTunes U 132 FileExplorer 129 National Rail 128 iPlayer Radio 127 FasterScan 125 BBC Weather 125 FasterScan HD 124 Gmail 123 Instagram 116 Cleaner Brent 107 Viber 104 Find Friends 98 PDF Expert 95 Solitaire 91 SlideShark 89 Netflix 89 Dictation 89 com.amazon.AmazonUK 88 Flashlight 81 iMovie 79 Temple Run 2 77 Smart Office 2 74 Dictionary 72 UK & ROI 71 Journey Pro 71 iPhoto 70 TripAdvisor 68 Guardian iPad edition 68 Shazam 67 Messenger 65 Bible 64 BBC Sport 63 Rightmove 62 London 62 Sky Sports 61 Subway Surf 60 Temple Run 60 Yahoo Mail 58 thetrainline 58 Minion Rush 58 Demand 5 57 Documents 55 Argos 55 LBC 54 Sky+ 51 MailOnline 51 GarageBand 51 Calc 51 TV Guide 49 Phone Edition 49 Translate 48 Print Portal 48 Standard 48 Word 47 Skitch 47 CloudOn 47 Tablet Edition 46 MyFitnessPal 46 Bus London 46 Snapchat 45 Drive 42 4 Pics 1 Word 41 TED 39 Skyscanner 39 SoundCloud 39 PowerPoint 39 Zoopla 38 Flow Free 38 Excel 38 Radioplayer -

Detection of Encrypted Traffic Generated by Peer-To-Peer Live
UNIVERSIDADE DA BEIRA INTERIOR Engenharia Detection of Encrypted Traffic Generated by Peer-to-Peer Live Streaming Applications Using Deep Packet Inspection André Filipe Ferreira Esteves Dissertation submitted in candidature for the degree of Master of Science in Computer Science and Engineering (2nd Cycle Degree) Supervisor: Dr. Mário Marques Freire Covilhã, October 2011 ii Work financed by FEDER funds through Programa Operacional Factores de Competitividade – COMPETE and by national funds through the Portuguese Fundação para a Ciência e a Tecnologia within the project TRAMANET: Traffic and Trust Management in Peer-to-Peer Networks with contracts PTDC/EIA/73072/2006 and FCOMP-01-0124-FEDER-007253. i ii Acknowledgements First i would like to start thanking the person who give the chance to integrate his dynamic research team where work and fun walk side by side, to professor Mário Freire my gratitude, for all the scientific knowledge acquired along this work, for the motivation, and also for the almost unlimited resources provided to make this research possible. I would also like to thank David Milheiro for the help mounting the research test-bed, and João Gomes and professor Pedro Inácio for the great suggestions to improve my work. I am also grateful to the University of Beira Interior, in special to the Computer Science Department and to the Multimedia Signal Processing research group for all the support and equipment provided for this work, and also for having such delight place to work. To my parents and my brother for all the motivation and support over the years, as without them i would not have made here. -

Live Streaming Performance of the Zattoo Network
Live Streaming Performance of the Zattoo Network Hyunseok Chang Sugih Jamin Wenjie Wang Alcatel-Lucent Bell Labs University of Michigan Zattoo Inc. Holmdel, NJ 07733 USA Ann Arbor, MI 48109 USA Ann Arbor, MI 48105 USA [email protected] [email protected] [email protected] ABSTRACT 1. INTRODUCTION A number of commercial peer-to-peer systems for live stream- We draw a distinction between three uses of peer-to-peer ing, such as PPLive, Joost, LiveStation, SOPCast, TVants, (P2P) networks: delay tolerant file download of archival ma- etc. have been introduced in recent years. The behavior of terial, delay sensitive progressive download (or streaming) these popular systems has been extensively studied in sev- of archival material, and real-time live streaming. In the eral measurement papers. Due to the proprietary nature first case, the completion of download is elastic, depending of these commercial systems, however, these studies have on available bandwidth in the P2P network. The applica- to rely on a “black-box” approach, where packet traces are tion buffer receives data as it trickles in and informs the collected from a single or a limited number of measurement user upon the completion of download. The user can then points, to infer various properties of traffic on the control and start playing back the file for viewing in the case of a video data planes. Although such studies are useful to compare file. In the second case, video playback starts as soon as different systems from end-user’s perspective, it is difficult the application assesses it has sufficient data buffered that, to intuitively understand the observed properties without given the estimated download rate and the playback rate, fully reverse-engineering the underlying systems. -

Ommunity Guide 2021-2022
American Coordinating Council of Norway Community Guide 2021-2022 ACCN’S 35TH Anniversary Independence Day Celebration is postponed until 2022 . The Empire state building 90 years www.accn.no DIN LEVERANDØR AV AMERIKANSKE MATVARER Oluf Lorentzen er en av Norges fremste Dear Reader importører av amerikanske matvarer til AMERICAN dagligvare- og storhusholdningsmarkedet. -20% Vi fører over 170 produkter med amerikansk TASTE opprinnelse, i mange forskjellige varegrupper. As I write this, the city of Oslo is still forbidding numbers of people gathering for events, even the 17th of May Nå kan du også handle direkte fra oss på celebrations have been cancelled. oluf.no! Bruk rabattkoden “ACCN20” This means that the American Coordinating Council of Norway's 35th Independence Day celebration, in Frogner for 20% på din neste handel! park, will have to be postponed until 2022. The American Coordinating Council of Norway (ACCN) started the planning of this event in February of this year. Many committees were formed, and many volunteers have been working hard, for many months. Hundreds of hours of organization have been in vain. The many elements required for an event of this size have been cancelled: bands, stage & sound, tents, tables, electricity, etc., etc. We are so sorry for this, but we are optimistic and hope to see you in 2022! I would like to thank the ACCN Board for all the hard work: ACCN Event Chair Chrys Hellem, Secretary Elaine Christiansen, Treasurer Karin Mandeville, Raffle Chair Jeanette Førland, Advisors Jan Søderstrøm, Ole Hillestad, & Web Designer Alexander Douglas. In addition, a well-deserved thanks to all our Committee Chair (men/women). -

Internet Enemies Report 2012 Ennemis of the Internet / 12 March 2012 / World Day Against Cybercensorship//////////////////////////// 2
INTERNET ENEMIES REPORT 2012 ENNEMIS OF THE INTERNET / 12 MARCH 2012 / WORLD DAY AGAINST CYBERCENSORSHIP//////////////////////////// 2 WORLD MAP OF CYBERCENSORSHIP................................3 INTRODUCTION...........................................................................................4 ENEMIES OF THE INTERNET BAHRAIN....................................................................................................................13 BELARUS...................................................................................................................15 BURMA......................................................................................................................17 CHINA.........................................................................................................................19 CUBA.........................................................................................................................23 IRAN..........................................................................................................................25 NORTH KOREA..........................................................................................................28 SAUDI ARABIA.........................................................................................................30 SYRIA........................................................................................................................32 TURKMENISTAN.......................................................................................................35