Identity in Phonology: Contrast
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Contrastive Feature Typologies of Arabic Consonant Reflexes
languages Article Contrastive Feature Typologies of Arabic Consonant Reflexes Islam Youssef Department of Languages and Literature Studies, University of South-Eastern Norway, 3833 Bø i Telemark, Norway; [email protected] Abstract: Attempts to classify spoken Arabic dialects based on distinct reflexes of consonant phonemes are known to employ a mixture of parameters, which often conflate linguistic and non- linguistic facts. This article advances an alternative, theory-informed perspective of segmental typology, one that takes phonological properties as the object of investigation. Under this approach, various classificatory systems are legitimate; and I utilize a typological scheme within the framework of feature geometry. A minimalist model designed to account for segment-internal representations produces neat typologies of the Arabic consonants that vary across dialects, namely qaf,¯ gˇ¯ım, kaf,¯ d. ad,¯ the interdentals, the rhotic, and the pharyngeals. Cognates for each of these are analyzed in a typology based on a few monovalent contrastive features. A key benefit of the proposed typologies is that the featural compositions of the various cognates give grounds for their behavior, in terms of contrasts and phonological activity, and potentially in diachronic processes as well. At a more general level, property-based typology is a promising line of research that helps us understand and categorize purely linguistic facts across languages or language varieties. Keywords: phonological typology; feature geometry; contrastivity; Arabic dialects; consonant reflexes Citation: Youssef, Islam. 2021. Contrastive Feature Typologies of 1. Introduction Arabic Consonant Reflexes. Languages Modern Arabic vernaculars have relatively large, but varying, consonant inventories. 6: 141. https://doi.org/10.3390/ Because of that, they have been typologized according to differences in the reflexes of their languages6030141 consonant phonemes—differences which suggest common origins or long-term contact (Watson 2011a, p. -

1 Linguistics 288B 12
Features: the atoms of segment structure Each feature encodes one of the aspects of speech production Linguistics 288b The specification of features is either positive or negative; specification is therefore binary/bivalent. Phonology 3 Features are conventionally arranged in a column called a feature matrix. Linguistics 288b 2 Features Why do we need features? [p] natural classes: an economical way of +consonantal characterizing segments (e.g. /s z S Z tS dZ/ = -syllabic [+sibilant]; /p t k b d g f v s z T D S Z tS dZ h // = -sonorant obstruents ([-sonorant, +consonantal]) -voice +labial better understanding of allophonic variation (e.g. -round assimilation - e.g. liquid devoicing /pr/ → [pr8] -continuant -nasal -lateral Linguistics 288b 3 Linguistics 288b 4 Allophonic variation Liquid devoicing Allophonic variation is not simply the substitution /p r/ →[pr8] of one allophone for another, but an +consonantal +consonantal -syllabic -syllabic ø environmentally conditioned change of a feature -sonorant +sonorant -voice +voice or features +labial +coronal /pr/ [p ] ‘pray’ [p ], ‘prime’ [p ] -continuant +continuant → r8 r8ej r8ajm -nasal -nasal -lateral -lateral etc. etc. Linguistics 288b 5 Linguistics 288b 6 1 Natural classes Natural classes Reason: simplicity in scientific modeling Examples of natural classes in English: (Occam’s razor). / s z S Z tS dZ/ = [+sibilant] /p t k b d g f v s z T D s z S Z tS dZ h // = [-sonorant, A set of segments is said to constitute a natural +consonantal] (obstruents) class if fewer features are needed to specify the /l/ = [+lateral] set as a whole then to specify any one member of the set. -

LING 220 LECTURE #8 PHONOLOGY (Continued) FEATURES Is The
LING 220 LECTURE #8 PHONOLOGY (Continued) FEATURES Is the segment the smallest unit of phonological analysis? The segment is not the ultimate unit: features are the ultimate units of phonology that make up segments. Features define natural classes: ↓ classes consist of sounds that share phonetic characteristics, and undergo the same processes (see above). DISTINCTIVE FEATURE: a feature that signals the difference in meaning by changing its plus (+) or minus (-) value. Example: tip [-voice] dip [+voice] Binary system: a feature is either present or absent. pluses and minuses: instead of two separate labels, such as voiced and voiceless, we apply only one: [voice] [+voice] voiced sounds [-voice] voiceless sounds THE FEATURES OF ENGLISH: 1. Major class features 2. Laryngeal features 3. Place features 4. Dorsal features 5. Manner features 1 1. MAJOR CLASS FEATURES: they distinguish between consonants, glides, and vowels. obstruents, nasals and liquids (Obstruents: oral stops, fricatives and affricates) [consonantal]: sounds produced with a major obstruction in the oral tract obstruents, liquids and nasals are [+consonantal] [syllabic]:a feature that characterizes vowels and syllabic liquids and nasals [sonorant]: a feature that refers to the resonant quality of the sound. vowels, glides, liquids and nasals are [+sonorant] STUDY Table 3.30 on p. 89. 2. LARYNGEAL FEATURES: they represent the states of the glottis. [voice] voiced sounds: [+voice] voiceless sounds: [-voice] [spread glottis] ([SG]): this feature distinguishes between aspirated and unaspirated consonants. aspirated consonants: [+SG] unaspirated consonants: [-SG] [constricted glottis] ([CG]): sounds made with the glottis closed. glottal stop [÷]: [+CG] 2 3. PLACE FEATURES: they refer to the place of articulation. -

Pdf (Accessed on 02 February 2007)
Features in Phonology1 Maria Gouskova Contents 1 What are features? 2 2 The main features 3 2.1 Manner features . 3 2.1.1 Consonantal . 3 2.1.2 Sonorant . 4 2.1.3 Nasal . 5 2.1.4 Continuant . 6 2.2 Laryngealfeatures...................................................... 7 2.2.1 Voice . 7 2.2.2 Spread glottis . 8 2.2.3 Constricted glottis . 8 2.3 Place features . 9 2.3.1 Labial ........................................................ 9 2.3.2 Coronal . 10 2.3.3 Dorsal . 11 3 Vocalic features 11 3.1 Round . 11 3.2 Back............................................................. 12 3.3 Height . 12 3.4 ATR ............................................................. 13 4 Minor features 14 4.1 Minor consonantal features . 14 4.1.1 Lateral........................................................ 14 4.1.2 Strident . 14 4.1.3 Anterior . 15 4.1.4 Secondary articulations on consonants . 15 5 Controversial distinctions 16 5.1 Consonantal distinctions . 17 5.1.1 Glides vs. vowels . 17 5.1.2 Approximants as a class . 18 5.1.3 Exoticdistinctionsamongcoronals . 19 5.1.4 Affricates ...................................................... 19 5.1.5 Labialsandtrills................................................... 20 5.1.6 Pharyngeals and glottals . 20 5.1.7 Laryngealcontroversies ............................................... 21 5.2 Vocalic distinctions . 22 5.2.1 DoesEnglishhaveanATRdistinction?. 22 5.2.2 The featural status of central vowels . 22 5.2.3 How to characterize length contrasts . 23 6 Are features privative, binary, or multivalued? 24 7 Same pattern, different sound? 25 8 Are features innate or learned? 25 9 How to write rules, SPE-style 26 10 Conclusion 27 1 Maria Gouskova Phonology I, NYU 1 What are features? When we talk about sounds in a phonetics or phonology class, we usually use phonetic terms to describe them: alveolar, palatal, interdental, trill. -
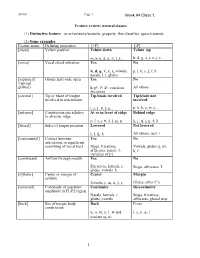
Distinctive Feature
24.901Page 1 Feature review; natural classes (1) Distinctive feature: an articulatory/acoustic property that classifies speech sounds (2) Some examples: Feature name Defining properties [+F] [-F] [nasal] Velum position Velum down Velum up m, n, N, a), e), o), j) ,r)... b, d, g, a, e, o, j, r… [voice] Vocal chord vibration Yes No b, d, g, v, z, Z, vowels, p, t, k, s, S, f, h nasals, l, r, glides [aspirated] Glottis held wide open Yes No ([spread glottis]) h, pÓ, tÓ, kÓ, voiceless All others fricatives [coronal] Tip or blade of tongue Tip/blade involved Tip/blade not involved in articulation involved t, s, S, T, l, n… p, k, h, a, w, j… [anterior] Constriction site relative At or in front of ridge Behind ridge to alveolar ridge p, f, t, s, T, d, l, m, n k, S, tS, j, N, :, λ [lateral] Sides of tongue position Lowered Not lowered l, :, L, λ All others, incl. r [consonantal] Contact between Yes No articulators or significant narrowing of vocal tract Stops, fricatives, Vowels, glides (j, w), affricates, nasals, l, h, / varieties of [r] [continuant] Airflow through mouth Yes No Fricatives, laterals, r, Stops, affricates, / glides, vowels, h [syllabic] Center or margin of Center Margin syllable Vowels, r`, m`, n`, l`, s` Glides, other C’s [sonorant] Continuity of spectrum Continuity Discontinuity amplitude in F1-F2 region Nasals, laterals, r, Stops, fricatives, glides, vowels affricates, glottal stop [back] Site of tongue body Back Front constriction u, o, ¨, A, :, w and i, e, y, œ, j uvulars (q, R) 1 24.901Page 2 Feature name Defining properties [+F] [-F] [round] Lip pursing Yes No o, O, u, U, y, w, kw All others [low] Jaw position Lowered Not lowered a, œ, A All others [high] Tongue body vertical Raised Not raised position i, u, y, ¨, j, w, velar C’s All others (3) Speech sounds are bundles of distinctive features. -

Introductory Phonology
9781405184120_1_pre.qxd 06/06/2008 09:47 AM Page iii Introductory Phonology Bruce Hayes A John Wiley & Sons, Ltd., Publication 9781405184120_4_C04.qxd 06/06/2008 09:50 AM Page 70 4 Features 4.1 Introduction to Features: Representations Feature theory is part of a general approach in cognitive science which hypo- thesizes formal representations of mental phenomena. A representation is an abstract formal object that characterizes the essential properties of a mental entity. To begin with an example, most readers of this book are familiar with the words and music of the song “Happy Birthday to You.” The question is: what is it that they know? Or, to put it very literally, what information is embodied in their neurons that distinguishes a knower of “Happy Birthday” from a hypothetical person who is identical in every other respect but does not know the song? Much of this knowledge must be abstract. People can recognize “Happy Birth- day” when it is sung in a novel key, or by an unfamiliar voice, or using a different tempo or form of musical expression. Somehow, they can ignore (or cope in some other way with) inessential traits and attend to the essential ones. The latter include the linguistic text, the (relative) pitch sequences of the notes, the relative note dura- tions, and the musical harmonies that (often tacitly) accompany the tune. Cognitive science posits that humans possess mental representations, that is, formal mental objects depicting the structure of things we know or do. A typical claim is that we are capable of singing “Happy Birthday” because we have (during childhood) internalized a mental representation, fairly abstract in character, that embodies the structure of this song. -

Phonetics Sep 1–8, 2016
Claire Moore-Cantwell LING2010Q Handout 2 Handout 2: Phonetics Sep 1–8, 2016 Phonetics is the study of speech sounds (phones), i.e., the sounds that we make that are involved in language. • Articulatory phonetics is the study of how speech sounds are made. • Acoustic phonetics is the study of the physical properties of speech sounds, i.e., how speech sounds are transmitted from a speaker’s mouth to a hearer’s ear. • Auditory phonetics is the study of how speech sounds are perceived (e.g., segmented, categorized). Our focus will be on articulatory phonetics, and in this part of the course we will be covering the basic properties of speech sounds as well as phonetic features and natural classes. Different languages may contain different speech sounds, but there are only so many different sounds that the human vocal apparatus can make. ! The International Phonetic Alphabet = standardized transcription system for all the world’s spoken languages, typically written between square brackets or slashes. (1) a.[ hElow] b.[ sIli] c.[ læf] d.[ ælf@bEt] e.[ SiD] f.[ dZ2dZ] A preliminary note: Phonetics (and linguistics more generally) is not concerned with orthog- raphy/spelling. English spelling is notoriously unreliable for determining speech sounds: (2) Spelled the same, different speech sounds a.c ough, dough, bough, bought b.c omb, tomb, bomb c. the, thought (3) Same spelled word, different speech sounds a. bow, bow b. close, close c. tear, tear 1 Claire Moore-Cantwell LING2010Q Handout 2 (4) Spelled differently, same speech sounds a.m ade, paid b.l augh, graph, staff c. -

Phonological Features
Phonological features LING 451/551 Spring 2011 Prof. Hargus Feature • Segments are not indivisible units, but are composed of features. E.g. a feature matrix for /t/: [-continuant] [-sonorant] [+coronal] [-voiced] (an unordered list; re possible internal structure for features, see Hayes 4.6.6) • feature definitions: usually articulatory • feature values: +, -, 0 – 0 = n.a. to segment Functions of features • A feature system must be able to – Describe classes of sounds – Distinguish phonemes – Specify phonetic detail Describe classes • # features inversely proportional to size of class – [p t k b d g]: [-continuant, -sonorant]] – [p]: [-continuant, -sonorant, -voiced, +labial] • (check out FeaturePad from Bruce Hayes’ web site) – http://www.linguistics.ucla.edu/people/hayes/12 0a/FeaturePad.htm Terminological difs traditional phonetic term phonological feature stop [-continuant] nasal [+nasal] round [+round] labiodental [+labiodental] etc. why difs? Hayes (p. 74): phonol classes are broader than phonetic terms Operations on features • Formally, phonological rules are operations on features – A phonological rule adds a feature or changes some value of an already specified feature • In a phonological rule, --> is therefore a metaphor for ‘change’ or ‘add’. • Phonological rules identify classes of sounds via feature(s) • Justification: some phonological rules occur relatively frequently across languages while conceivable rules are rare or non-existent – E.g. post-nasal voicing of stops is common, typically affecting all stops of some language: • /p t k/ --> [b d g] / {m n ŋ} ___ • Hypothetical consonant inventory p t k f s x m n ŋ l w r • But Post-nasal voicing’ is not attested – *p f x --> [b v γ] / {m n ŋ} ___ • If rules are stated in terms of segments, then the unattested and common rules are equally complex. -

Lecture Notes and Other Handouts for Introductory Phonology
Lecture Notes and Other Handouts for Introductory Phonology: A Course Packet Steve Parker GIAL and SIL International Dallas, 2013 Copyright © 2013 by Steve Parker and other contributors Preface This set of materials is designed to be used as handouts accompanying an introductory course in phonology, particularly at the undergraduate level. It is specifically intended to be used in conjunction with Stephen Marlett’s 2001 textbook, An Introduction to Phonological Analysis. The latter is currently available for free download from the SIL Mexico branch website. However, this course packet could potentially also be adapted for use with other phonology textbooks. The materials included here have been developed by myself and others over many years, in conjunction with courses in introductory phonology taught at SIL programs in North Dakota, Oregon, Dallas, and Norman, OK. Most recently I have used them at GIAL. Two colleagues in particular have contributed significantly to many of these handouts: Jim Roberts and Steve Marlett, to whom my thanks. I would also like to express my appreciation and gratitude to Becky Thompson for her very practical service in helping combine all of the individual files into one exhaustive document, and formatting it for me. Many of the special phonetic characters appearing in these materials use IPA fonts available as freeware from the SIL International website. Unless indicated to the contrary on specific individual handouts, all materials used in this packet are the copyright of Steve Parker. These documents are intended primarily for educational use. You may make copies of these works for research or instructional purposes (under fair use guidelines) free of charge and without further permission. -

Chapter 3.Pdf
ChapterChapter 33 TheThe ConsonantsConsonants ofof EnglishEnglish 1 TheThe definitiondefinition ofof ““consonantconsonant”” In articulatory phonetics, a consonant is a sound in spoken language that is characterized by a closure or stricture of the vocal tract sufficient to cause audible turbulence. The word consonant comes from Latin and means "sounding with" or "sounding together," the idea being that consonants don't sound on their own, but occur only with a nearby vowel, which is the case in Latin. This conception of consonants, however, does not reflect the modern linguistic understanding which defines consonants in terms of vocal tract constriction. 2 3.3. AnAn overviewoverview ofof thethe EnglishEnglish consonantconsonant Manners of Place of Articulation Articulation Bilabial Labiodental Dental Alveolar Palatal Velar Glotal Stop Voiceless /p/ /t/ /k/ Voiced /b/ /d/ /g/ Fricatives Voiceless /f/ /P/ /s/ /S/ /h/ Voiced Voiced /v/ /D/ /z/ /Z/ Affricate Voiceless /tS/ Voiced Voiced /dZ/ Nasal-voiced /m/ /n/ /N/ Liquid-voiced /l/ /r/ […] Glide/Approximant Voiceless /hw/ /hw/ Voiced /w/ /j/ /w/ 3 3.13.1 StopStop ConsonantsConsonants 3.1.13.1.1 AspirationAspiration Aspiration is a period of voicelessness after the stop articulation and before the start of the voicing for the vowel. If you put a sheet of thin paper in front of your lips while saying “pie,” you can feel the burst of air that comes out during the period of voicelessness after the release of the stop. In a narrow transcription, aspiration may be indicated by a small raised h, [H]. Accordingly, these words may be transcribed as [ pHaI, tH aI, kH aI ]. -

Introduction to Linguistics Study Guide Anna Gartsman & Laura Hughes Northeastern University Senior Honors Project 2006-2007
Honors Project Cover Page Introductory Linguistics Study Guide By Anna Gartsman and Laura Hughes, Class of 2007 May 2007 Department of Linguistics College of Arts & Sciences Northeastern University Advisor: Janet Randall Project field: Linguistics Colleges/Majors: • Anna Gartsman: o School of Computer Science: Computer Science and Cognitive Psychology o School of Arts & Sciences: Linguistics • Laura Hughes o School of Arts & Sciences: Linguistics and Psychology Abstract: A step-by-step guide to the major areas of introductory-level theoretical linguistics (phonetics, phonology, morphology, syntax, semantics, and pragmatics) with a focus on practical problem-solving. Designed to assist students in low-level linguistics classes and tutors of same by providing additional explanations, examples and exercises. Introduction to Linguistics Study Guide Anna Gartsman & Laura Hughes Northeastern University Senior Honors Project 2006-2007 Contents Phonetics Syntax The International Phonetic Alphabet (IPA) Constituency Natural Classes Lexical Categories Features English Phrase Structure & Syntax Trees Ambiguous Sentences Phonology Complex Sentences Minimal Pairs Transformations Phonemes and Allophones Complementary & Contrastive Distribution Semantics Environments Connotation & Denotation Determining the Underlying Phoneme Processes of Semantic Change Rules Theta roles Analyzing Data Sets Tautologies, Contradictions, & Phonological Processes Contingencies Sense & Reference Morphology Presupposition & Entailment Basic Lexical Categories (Noun, Verb, -

Phonetics Review & Phonology
Phonetics Review & Phonology LIN 001Y – A09 WINTER 2017 FRIDAY JANUARY 27, 2017 TA – JEFF MORAN HW 2 & Phonetics: What Do We Need to Review? - -Vowel chart -Phoneme & allophones -Minimal Pairs -Complementary & contrastive distribution 3 Minute Warmup It’s Thursday! I’m so happy I want to tell the world about it! So, work with a partner to tell the world how happy you are… in IPA! (That’s a lot of exclamation marks!) Please transcribe the following phrase into IPA: Happy Thursday hæpi θɚzde Vowels Vowel Chart & Descriptions • All voiced • No/minimal air obstruction • So we don’t use place & manner of articulation So we describe them with: Front-Central-Back High-Mid-Low Tense vs. Lax Activity Practice saying each vowel sound. Then, for each monophthong and diphthong, say one word that contains that vowel sound. Monophthongs Diphthongs 1. [ɑi] 2. [ɔɪ] 3. [aʊ] American English IPA Consonants & Vowels Transcription activity Transcribe your full name Jeffrey Chapman Moran ʤɛfɹi ʧæpmən məɹæn Phonology: 30 Second Review Phonology is the branch of linguistics that is concerned with how sounds are systematically organized within a language It is distinct from phonetics, which as we have seen, is the study of the acoustic properties of sounds However, in order to understand phonological processes, one must have a good grasp of phonetics. More Basic Concepts Phonemes are abstract mental representations of sounds. Phonemes are marked by slashes ( ex. /b/ ) They reflect speaker knowledge of sounds. Allophones are the physical “realizations” of phonemes. They are the sounds that are actually made by speakers of a language.