(Aka “Code Pages”) Like Lati
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
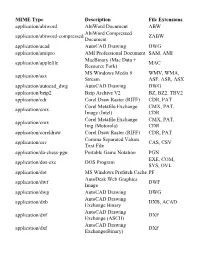
MIME Type Description File Extensions Application/Abiword
MIME Type Description File Extensions application/abiword AbiWord Document ABW AbiWord Compressed application/abiword-compressed ZABW Document application/acad AutoCAD Drawing DWG application/amipro AMI Professional Document SAM, AMI MacBinary (Mac Data + application/applefile MAC Resource Fork) MS Windows Media 9 WMV, WMA, application/asx Stream ASF, ASR, ASX application/autocad_dwg AutoCAD Drawing DWG application/bzip2 Bzip Archive V2 BZ, BZ2, TBV2 application/cdr Corel Draw Raster (RIFF) CDR, PAT Corel Metafile Exchange CMX, PAT, application/cmx Image (Intel) CDR Corel Metafile Exchange CMX, PAT, application/cmx Img (Motorola) CDR application/coreldraw Corel Draw Raster (RIFF) CDR, PAT Comma Separated Values application/csv CAS, CSV Text File application/da-chess-pgn Portable Game Notation PGN EXE, COM, application/dos-exe DOS Program SYS, OVL application/dot MS Windows Prefetch Cache PF AutoDesk Web Graphics application/dwf DWF Image application/dwg AutoCAD Drawing DWG AutoCAD Drawing application/dxb DXB, ACAD Exchange Binary AutoCAD Drawing application/dxf DXF Exchange (ASCII) AutoCAD Drawing application/dxf DXF Exchange(Binary) EMF, TMP, EMF, TMP, application/emf Windows Enhanced Metafile WMF application/envoy Envoy Document EVY, ENV Comma Separated Values application/excel CAS, CSV Text File MS Excel XLS, XLA, application/excel Worksheet/Add-In/Template XLT, XLB EXE, COM, application/exe DOS Program SYS, OVL EXE, VXD, application/exe MS Windows Driver (16 bit) SYS, DRV, 386 MS Windows Program (16 application/exe EXE, MOD, BIN bit) -

Symantec Web Security Service Policy Guide
Web Security Service Policy Guide Revision: NOV.07.2020 Symantec Web Security Service/Page 2 Policy Guide/Page 3 Copyrights Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. Copyright © 2020 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. Policy Guide/Page 4 Symantec WSS Policy Guide The Symantec Web Security Service solutions provide real-time protection against web-borne threats. As a cloud-based product, the Web Security Service leverages Symantec's proven security technology, including the WebPulse™ cloud community. With extensive web application controls and detailed reporting features, IT administrators can use the Web Security Service to create and enforce granular policies that are applied to all covered users, including fixed locations and roaming users. If the WSS is the body, then the policy engine is the brain. While the WSS by default provides malware protection (blocks four categories: Phishing, Proxy Avoidance, Spyware Effects/Privacy Concerns, and Spyware/Malware Sources), the additional policy rules and options you create dictate exactly what content your employees can and cannot access—from global allows/denials to individual users at specific times from specific locations. -
![Archive and Compressed [Edit]](https://docslib.b-cdn.net/cover/8796/archive-and-compressed-edit-1288796.webp)
Archive and Compressed [Edit]
Archive and compressed [edit] Main article: List of archive formats • .?Q? – files compressed by the SQ program • 7z – 7-Zip compressed file • AAC – Advanced Audio Coding • ace – ACE compressed file • ALZ – ALZip compressed file • APK – Applications installable on Android • AT3 – Sony's UMD Data compression • .bke – BackupEarth.com Data compression • ARC • ARJ – ARJ compressed file • BA – Scifer Archive (.ba), Scifer External Archive Type • big – Special file compression format used by Electronic Arts for compressing the data for many of EA's games • BIK (.bik) – Bink Video file. A video compression system developed by RAD Game Tools • BKF (.bkf) – Microsoft backup created by NTBACKUP.EXE • bzip2 – (.bz2) • bld - Skyscraper Simulator Building • c4 – JEDMICS image files, a DOD system • cab – Microsoft Cabinet • cals – JEDMICS image files, a DOD system • cpt/sea – Compact Pro (Macintosh) • DAA – Closed-format, Windows-only compressed disk image • deb – Debian Linux install package • DMG – an Apple compressed/encrypted format • DDZ – a file which can only be used by the "daydreamer engine" created by "fever-dreamer", a program similar to RAGS, it's mainly used to make somewhat short games. • DPE – Package of AVE documents made with Aquafadas digital publishing tools. • EEA – An encrypted CAB, ostensibly for protecting email attachments • .egg – Alzip Egg Edition compressed file • EGT (.egt) – EGT Universal Document also used to create compressed cabinet files replaces .ecab • ECAB (.ECAB, .ezip) – EGT Compressed Folder used in advanced systems to compress entire system folders, replaced by EGT Universal Document • ESS (.ess) – EGT SmartSense File, detects files compressed using the EGT compression system. • GHO (.gho, .ghs) – Norton Ghost • gzip (.gz) – Compressed file • IPG (.ipg) – Format in which Apple Inc. -

Using Netpresenz
NetPresenz 4.1 from netpresenz.com NB: Please click the "I Paid" checkbox in NetPresenz Setup - FTP Setup dialog. Contents What NetPresenz Does Features Using NetPresenz Setup FTP Setup WWW and Gopher Setup FTP Setup Details Scripting NetPresenz Setup Using NetPresenz Referring to your Server Using NetPresenz from a Un*x FTP Client Remote Volume Mounting Miscellaneous FTP Commands WWW Server Side Includes CGIs Java Missing files Gopher Security Considerations Avoid the Wrath of your Network Admin Limitations Remote Site Access Restrictions Acknowledgements How It Works What NetPresenz Does NetPresenz is a Macintosh implementation of the WWW, Gopher and FTP server protocols. It should be compatible with most FTP clients, and all WWW and Gopher clients. Basically it allows your Mac to act as an FTP server so you (and others) can access your files from anywhere around the world. Obviously there are some serious security considerations you should look into before using this software (see the Security Considerations section). NetPresenz requires System 7, MacTCP 1.1, and File Sharing enabled. It honours the Users & Groups privileges and passwords, and supports multiple logins, anonymous FTP (user name “anonymous” or “ftp”), as well as MacBinary and BinHex transfers, and the “MACB” FTP command. You can run NetPresenz as a foreground application (displaying the log), or as a background only application (use NetPresenz Setup to toggle between the two). Features Support WWW, Gopher and FTP connections. Full CGI support. Multiple simultaneous users. Honours System 7 Users & Groups (in fact depends on them!). Server Side Includes (SSI), counters and include files, file modification date and so forth. -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Name Synopsis Description Options Examples See Also
T1UNMAC(1) General Commands Manual T1UNMAC(1) NAME t1unmac − translate a Mac PostScript Type 1 font into PFAorPFB format SYNOPSIS t1unmac [−a|−b][−r][input [output]] DESCRIPTION t1unmac extracts POST resources from a Macintosh PostScript font file and creates a PFA (hexadecimal) or PFB (binary) font file. The file input should be in MacBinary I or II, AppleSingle, AppleDouble, or BinHexformat, or it can be a rawresource fork. If the file is a raw resource fork, you need to give the ‘−−raw’ option; otherwise t1unmac should automatically figure out what kind of file you have.Ifthe file output is not specified output goes to the standard output. OPTIONS −−pfa, −a Output in PFA(ASCII) format. −−pfb, −b Output in PFB (binary) format. This is the default. −−raw, −r Indicates that the input is a rawresource fork. −−macbinary Indicates that the input is in MacBinary I or II format. −−applesingle Indicates that the input is in AppleSingle format. −−appledouble Indicates that the input is in AppleDouble format. −−binhex Indicates that the input is in BinHex4.0 format. −−block−length=num, −l num PFB only: Set the maximum output block length to num. The default length is as large as memory allows. −−line−length=num, −l num PFAonly: Set the maximum length of encrypted lines in the output to num. (These are the lines consisting wholly of hexadecimal digits.) The default is 64. EXAMPLES On Mac OS X, you can use t1unmac to translate a font into PFAorPFB format as follows: % t1unmac −−rawFONTFILENAME/..namedfork/rsrc > OUTPUT SEE ALSO t1mac(1), t1ascii(1), t1binary(1), t1asm(1), t1disasm(1) AUTHORS Lee Hetherington ([email protected]) Eddie Kohler ([email protected]) Ported to Microsoft C/C++ Compiler and MS-DOS operating system by Kai-Uwe Herbing ([email protected]). -

Mac OS X Server File Services Administration for Version 10.4 Or Later
Mac OS X Server File Services Administration For Version 10.4 or Later K Apple Computer, Inc. © 2005 Apple Computer, Inc. All rights reserved. The owner or authorized user of a valid copy of Mac OS X Server software may reproduce this publication for the purpose of learning to use such software. No part of this publication may be reproduced or transmitted for commercial purposes, such as selling copies of this publication or for providing paid-for support services. Every effort has been made to ensure that the information in this manual is accurate. Apple Computer, Inc., is not responsible for printing or clerical errors. Apple 1 Infinite Loop Cupertino CA 95014-2084 www.apple.com The Apple logo is a trademark of Apple Computer, Inc., registered in the U.S. and other countries. Use of the “keyboard” Apple logo (Option-Shift-K) for commercial purposes without the prior written consent of Apple may constitute trademark infringement and unfair competition in violation of federal and state laws. Apple, the Apple logo, AppleShare, AppleTalk, Mac, Macintosh, QuickTime, Xgrid, and Xserve are trademarks of Apple Computer, Inc., registered in the U.S. and other countries. Finder is a trademark of Apple Computer, Inc. Adobe and PostScript are trademarks of Adobe Systems Incorporated. UNIX is a registered trademark in the United States and other countries, licensed exclusively through X/Open Company, Ltd. Other company and product names mentioned herein are trademarks of their respective companies. Mention of third-party products is for informational purposes only and constitutes neither an endorsement nor a recommendation. -

IDOL Keyview Viewing SDK 12.7 Programming Guide
KeyView Software Version 12.7 Viewing SDK Programming Guide Document Release Date: October 2020 Software Release Date: October 2020 Viewing SDK Programming Guide Legal notices Copyright notice © Copyright 2016-2020 Micro Focus or one of its affiliates. The only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Documentation updates The title page of this document contains the following identifying information: l Software Version number, which indicates the software version. l Document Release Date, which changes each time the document is updated. l Software Release Date, which indicates the release date of this version of the software. To check for updated documentation, visit https://www.microfocus.com/support-and-services/documentation/. Support Visit the MySupport portal to access contact information and details about the products, services, and support that Micro Focus offers. This portal also provides customer self-solve capabilities. It gives you a fast and efficient way to access interactive technical support tools needed to manage your business. As a valued support customer, you can benefit by using the MySupport portal to: l Search for knowledge documents of interest l Access product documentation l View software vulnerability alerts l Enter into discussions with other software customers l Download software patches l Manage software licenses, downloads, and support contracts l Submit and track service requests l Contact customer support l View information about all services that Support offers Many areas of the portal require you to sign in. -

IDOL Connector Framework Server 12.0 Administration Guide
Connector Framework Server Software Version 12.0 Administration Guide Document Release Date: June 2018 Software Release Date: June 2018 Administration Guide Legal notices Copyright notice © Copyright 2018 Micro Focus or one of its affiliates. The only warranties for products and services of Micro Focus and its affiliates and licensors (“Micro Focus”) are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. Micro Focus shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Trademark notices Adobe™ is a trademark of Adobe Systems Incorporated. Microsoft® and Windows® are U.S. registered trademarks of Microsoft Corporation. UNIX® is a registered trademark of The Open Group. Documentation updates The title page of this document contains the following identifying information: l Software Version number, which indicates the software version. l Document Release Date, which changes each time the document is updated. l Software Release Date, which indicates the release date of this version of the software. To verify you are using the most recent edition of a document, go to https://softwaresupport.softwaregrp.com/group/softwaresupport/search-result?doctype=online help. You will also receive new or updated editions of documentation if you subscribe to the appropriate product support service. Contact your Micro Focus sales representative for details. To check for new versions of software, go to https://www.hpe.com/software/entitlements. To check for recent software patches, go to https://softwaresupport.softwaregrp.com/patches. The sites listed in this section require you to sign in with a Software Passport. -

Dropdmg 2.6 Manual
DropDMG 2.6 Manual Michael Tsai c-command.com April 28, 2005 Contents 1 Introduction 4 1.1 Disk Images ......................................... 4 1.2 DropDMG .......................................... 4 2 Setting Up DropDMG 5 2.1 Requirements ........................................ 5 2.2 Installation ......................................... 5 2.3 Updating From DropDMG 1.x–2.x ............................ 6 2.4 Always Run With Root Access .............................. 6 3 Basic Operations 6 3.1 The Status Window .................................... 6 3.2 Creating and Converting .................................. 7 3.2.1 Drag and Drop ................................... 7 3.2.2 Service ........................................ 7 3.2.3 Automator Workflows ............................... 8 3.2.4 AppleScript ..................................... 8 3.2.5 Command-Line ................................... 8 3.2.6 Menu ........................................ 8 3.3 Fixing Disk Images ..................................... 9 3.4 Getting Information About Disk Images ......................... 9 3.5 Mounting Images ...................................... 9 3.6 Verifying Disk Images ................................... 9 3.7 Making Images With Background Pictures ........................ 9 4 License Agreements 10 5 Configurations 11 6 Overriding the Preferences 12 7 Preferences 13 7.1 Format ............................................ 13 7.2 Encrypt using passphrase ................................. 15 7.3 Limit segments to MB ................................ -

Sophos Anti-Virus Mac OS 8 Or 9 User Manual
Mac OS 8 or 9 User manual For network and single users Sophos Anti-Virus for Mac OS 8 or 9 About this manual This user manual explains how to use Sophos Anti-Virus for Mac OS 8 or 9 and how to configure virus scanning virus alerts disinfection reporting logging. The manual also provides help in resolving common problems. If you are using Mac OS X, refer instead to the Sophos Anti-Virus Mac OS X user manual. For information on the installation, initial setup, updating or uninstallation of Sophos Anti-Virus, see the Sophos Anti-Virus Mac OS 8 or 9 on a network installation guide or the Sophos Anti-Virus Mac OS 8 or 9 single user installation guide. Sophos documentation is published on the Sophos CD each month and at www.sophos.com/support/docs/ 2 Contents Technical support UK (24 hours): (+44) 1235 559933 [email protected] USA (24 hours): (+1) 888 767 4679 [email protected] Australia (24 hours): (+61) 2 9409 9111 [email protected] France: (+33) 1 40 90 20 90 [email protected] Germany (24 hours): (+49) 6136 91193 [email protected] Italy: (+39) 02 662810 0 [email protected] Japan (24 hours): (+81) 45 227 1800 [email protected] Singapore (24 hours): (+65) 6776 7467 [email protected] FAQs and virus information are available on the Sophos website www.sophos.com If you contact technical support, provide as much information as possible, including Sophos software version number(s), operating system(s) and patch level(s), and the exact text of any error messages. -

Submitting and Receiving Data to and from Applied Biosystems Genetic Analysis Technical Support
Technical Support Bulletin 2 June 6, 2006 SUBJECT: Submitting and Receiving Data to and from Applied Biosystems Genetic Analysis Technical Support Scope: Submitting and Receiving Data to and from Applied Biosystems Genetic Analysis Technical Support Overview During the course of troubleshooting, you may be asked to submit data to Technical Support. For your convenience, we offer the options of emailing the files, uploading them via the Applied Biosystems web site, or using File Transfer Protocol (FTP). Problem Data can become corrupt when transferring files between computers or during the transmission process, so it is recommended that prior to transferring or sending the data that you compress the files. When downloading files or receiving files from Applied Biosystems, you will often receive them in a compressed format and will need to decompress them in order to access the data or files. Solution Compressing Data – Macintosh® Platform Decompressing Data – Macintosh® Platform Compressing Data – PC Platform Decompressing Data – PC Platform How to Email Data How to upload data via the Applied Biosystems Web Site How to upload data via the Applied Biosystems FTP Site Page 1 Compressing Data – Macintosh® Platform Note: Apple included the installers for DropStuff and Stuffit Expander on many of their later systems. Doing a find on the system may show that the programs are there. If the you do not have the program on your computer, you can download it by going to http://www.appliedbiosystems.com, click SupportÆSoftware Downloads and click on Stuffit Expander). Before compressing the data, place all of the files you wish to send into 1 folder.