Apollo Domain/OS Design Principles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AIX® Version 6.1 Performance Toolbox Guide Limiting Access to Data Suppliers
AIX Version 6.1 Performance Toolbox Version 3 Guide and Reference AIX Version 6.1 Performance Toolbox Version 3 Guide and Reference Note Before using this information and the product it supports, read the information in Appendix G, “Notices,” on page 431. This edition applies to AIX Version 6.1 and to all subsequent releases and modifications until otherwise indicated in new editions. (c) Copyright AT&T, 1984, 1985, 1986, 1987, 1988, 1989. All rights reserved. Copyright Sun Microsystems, Inc., 1985, 1986, 1987, 1988. All rights reserved. The Network File System (NFS) was developed by Sun Microsystems, Inc. This software and documentation is based in part on the Fourth Berkeley Software Distribution under license from The Regents of the University of California. We acknowledge the following institutions for their role in its development: the Electrical Engineering and Computer Sciences Department at the Berkeley Campus. The Rand MH Message Handling System was developed by the Rand Corporation and the University of California. Portions of the code and documentation described in this book were derived from code and documentation developed under the auspices of the Regents of the University of California and have been acquired and modified under the provisions that the following copyright notice and permission notice appear: Copyright Regents of the University of California, 1986, 1987, 1988, 1989. All rights reserved. Redistribution and use in source and binary forms are permitted provided that this notice is preserved and that due credit is given to the University of California at Berkeley. The name of the University may not be used to endorse or promote products derived from this software without specific prior written permission. -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -

A Survey of Distributed File Systems
A Survey of Distributed File Systems M. Satyanarayanan Department of Computer Science Carnegie Mellon University February 1989 Abstract Abstract This paper is a survey of the current state of the art in the design and implementation of distributed file systems. It consists of four major parts: an overview of background material, case studies of a number of contemporary file systems, identification of key design techniques, and an examination of current research issues. The systems surveyed are Sun NFS, Apollo Domain, Andrew, IBM AIX DS, AT&T RFS, and Sprite. The coverage of background material includes a taxonomy of file system issues, a brief history of distributed file systems, and a summary of empirical research on file properties. A comprehensive bibliography forms an important of the paper. Copyright (C) 1988,1989 M. Satyanarayanan The author was supported in the writing of this paper by the National Science Foundation (Contract No. CCR-8657907), Defense Advanced Research Projects Agency (Order No. 4976, Contract F33615-84-K-1520) and the IBM Corporation (Faculty Development Award). The views and conclusions in this document are those of the author and do not represent the official policies of the funding agencies or Carnegie Mellon University. 1 1. Introduction The sharing of data in distributed systems is already common and will become pervasive as these systems grow in scale and importance. Each user in a distributed system is potentially a creator as well as a consumer of data. A user may wish to make his actions contingent upon information from a remote site, or may wish to update remote information. -
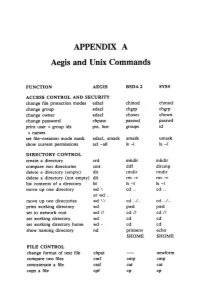
APPENDIX a Aegis and Unix Commands
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -
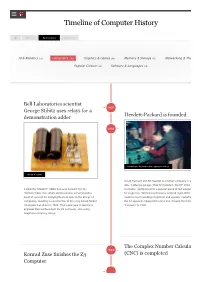
Timeline of Computer History
Timeline of Computer History By Year By Category Search AI & Robotics (55) Computers (145)(145) Graphics & Games (48) Memory & Storage (61) Networking & The Popular Culture (50) Software & Languages (60) Bell Laboratories scientist 1937 George Stibitz uses relays for a Hewlett-Packard is founded demonstration adder 1939 Hewlett and Packard in their garage workshop “Model K” Adder David Packard and Bill Hewlett found their company in a Alto, California garage. Their first product, the HP 200A A Called the “Model K” Adder because he built it on his Oscillator, rapidly became a popular piece of test equipm “Kitchen” table, this simple demonstration circuit provides for engineers. Walt Disney Pictures ordered eight of the 2 proof of concept for applying Boolean logic to the design of model to test recording equipment and speaker systems computers, resulting in construction of the relay-based Model the 12 specially equipped theatres that showed the movie I Complex Calculator in 1939. That same year in Germany, “Fantasia” in 1940. engineer Konrad Zuse built his Z2 computer, also using telephone company relays. The Complex Number Calculat 1940 Konrad Zuse finishes the Z3 (CNC) is completed Computer 1941 The Zuse Z3 Computer The Z3, an early computer built by German engineer Konrad Zuse working in complete isolation from developments elsewhere, uses 2,300 relays, performs floating point binary arithmetic, and has a 22-bit word length. The Z3 was used for aerodynamic calculations but was destroyed in a bombing raid on Berlin in late 1943. Zuse later supervised a reconstruction of the Z3 in the 1960s, which is currently on Operator at Complex Number Calculator (CNC) display at the Deutsches Museum in Munich. -

A History of the Personal Computer Index/11
A History of the Personal Computer 6100 CPU. See Intersil Index 6501 and 6502 microprocessor. See MOS Legend: Chap.#/Page# of Chap. 6502 BASIC. See Microsoft/Prog. Languages -- Numerals -- 7000 copier. See Xerox/Misc. 3 E-Z Pieces software, 13/20 8000 microprocessors. See 3-Plus-1 software. See Intel/Microprocessors Commodore 8010 “Star” Information 3Com Corporation, 12/15, System. See Xerox/Comp. 12/27, 16/17, 17/18, 17/20 8080 and 8086 BASIC. See 3M company, 17/5, 17/22 Microsoft/Prog. Languages 3P+S board. See Processor 8514/A standard, 20/6 Technology 9700 laser printing system. 4K BASIC. See Microsoft/Prog. See Xerox/Misc. Languages 16032 and 32032 micro/p. See 4th Dimension. See ACI National Semiconductor 8/16 magazine, 18/5 65802 and 65816 micro/p. See 8/16-Central, 18/5 Western Design Center 8K BASIC. See Microsoft/Prog. 68000 series of micro/p. See Languages Motorola 20SC hard drive. See Apple 80000 series of micro/p. See Computer/Accessories Intel/Microprocessors 64 computer. See Commodore 88000 micro/p. See Motorola 80 Microcomputing magazine, 18/4 --A-- 80-103A modem. See Hayes A Programming lang. See APL 86-DOS. See Seattle Computer A+ magazine, 18/5 128EX/2 computer. See Video A.P.P.L.E. (Apple Pugetsound Technology Program Library Exchange) 386i personal computer. See user group, 18/4, 19/17 Sun Microsystems Call-A.P.P.L.E. magazine, 432 microprocessor. See 18/4 Intel/Microprocessors A2-Central newsletter, 18/5 603/4 Electronic Multiplier. Abacus magazine, 18/8 See IBM/Computer (mainframe) ABC (Atanasoff-Berry 660 computer. -

Apollo Computerapr 15,981
apollo computerAPR 15,981 APOLLO DOMAIN ARCHITECTURE (February 1981) apollo computer inc. 5 Executive ParK Drive, N. Billerica, MA 01862617-667-8800 ARCHITECTURE EVOLUTION (1960-80) 1980s l.tARCHITECTURE EVOLUTION: This figure depicts the evolution of architecture over the called dedicated minicomputers. Minicomputers are past 20 years. In the center diamonD at the top we show characterized by having goodinteractivenesst good batch computing of the 1960's which is characterb:ed by, human interfaces, and very good performance, but first, very littte or n~ interactivenessand, second, very lacked in the· sharing of peripherals and data among a ritfle or no sharing of peripherals and data fifes. tn the late community of users. 1960's computer architecture evolved into two distinct The Apollo DOMAIN system has evolved as a direct result forms. On the one hand there was timesharing which was of improvements in technology and is widely h.eld to be intended for people who, needed/arge machine the architecture of the 1960's. It combines the goOd parts architecture, but could sacrifice certain degrees of of both timesharing and dedicated minicomputers, but performance and interactive ness. Timesharrng systems eliminates Ute disadvantages of both of these earlier are characterized by poor interactiveness but very good forms. The ApolfoDOMAIN system has good sharing sharing characteristics and also large machine capabilities provided by a high speed interactive network architecture. On the other hand batch evolved into a form as well as interactiveness provided by a dedicated computer available to each user. GOVERNING PRINCIPLES • DEDICATED CPU PER USER • INTEGRAL WIDE BAND LOCAL NETWORK • HIGH LEVEL DESIGN (ISP, VAS, PMS INDEPENDENCE) • USE OF ADVANCED TECHNOLOGIES (VLSI CPU, WINCHESTER DISKS, etc.) 1.2 GOVERNING PRINCIPLES: There are several principles that have been used to design of the architecture is based on high level govern the design < of the Apollo computer system. -

National Software Works) Lessons Lerrned(U) 1/2 Massachusetts Computer Associates Inc Wakefield Sunclassified F3@602-83-C-8940Muntzet Al
AD-R146 737 NSW (NATIONAL SOFTWARE WORKS) LESSONS LERRNED(U) 1/2 MASSACHUSETTS COMPUTER ASSOCIATES INC WAKEFIELD SUNCLASSIFIED F3@602-83-C-8940MUNTZET AL. MAY 84 CAIDD-83i2-38ei-/ RRDC-TR-84-90- 9/ N-tL mImmIIIIIIu IIIIIIIIIIIIII I I I I IIfflllll IIIIIIIIIIIIEIIEEIIII 7 - EM"- s la 1L.", 1111.0 I 12.5 36 Em2L * 11111 1.8 11.25 l . 116 - .. .+,., . AD-A146 737 Sl LESSONS LEARNED -. S Mmmbmfu Cput~rAmdepusn 0 Ch... MM . .urm.It Kirk Sattbey aid Obpmwo .e.e DTIC ELECTE OCT 2 3, AIR DEVELOPMENT CENTER . uj ROMEAir Force Systems Command Griffiss Air Force Base, NY 13441 84 10 19 148 F0 This report has been reviewed by the RADC Public Affairs Office (PA) and is releasable to the National Technical Information Service (NTIS). At NTIS it will be releasable to the general public, including foreign nations. RADC-TR-84-90 has been reviewed and is approved for publication. 0 APPROVED:& " 3 PATRICIA J. BASKINGER Project Engineer APPROVED: RONALD S. OSO Acting Chief, Command & Control Division FOR THE COMMANDER: • JOHN A. RITZ Acting Chief, Plans Office 4S If your address has changed or if you wish to be removed from the RADC mailing list, or if the addressee is no longer employed by your organization, please notify RADC (COTD) Griffiss AFB NY 13441. This will assist us in . maintaining a current mailing list. Do not return copies of this report unless contractual obligations or notices on a specific document requires that it be returned. UNCLASSIFIED SECUR4ITY CLASSIFICATION OP T141 PAGE REPORT DOCUMENTATION PAGE I11111PORT SECURITY CLAESIP#CATION 1b. -

Strategic Interactions in Dram and Risc Technology: a Network Approach
Strategic interactions in dram and risc technology: A network approach Geert Duysters & Wim Vanhaverbeke 93.023 September 1993 MERIT, P.O. Box 616, 6200 MD Maastricht (Netherlands) - telephone (31)43-883875- fax: (31)43-216518 1 STRATEGIC INTERACTIONS IN DRA AND RISC TECHNOLOGY: A NETWORK APPROACH Geert Duysters and WiI Vanhaverbeke1 INTRODUCTION Cooperative agreements have been ignored in business literature for a veiy long time. Only recently, the use of cooperative agreements as part of corporate strategies gained substantial interest. This increase in attention is above all due to the fact that in the last decade the number of cooperative agreements by firms has rocketed. In fact cooperative agreements have outnumbered the fully owned foreign subsidiaries (Contractor and Lorange, 1988). In this paper we will use the term cooperation to denote cooperative agreements between partners which are not connected through (majority) ownership. A cooperative agreement can be seen as an agreement which is positioned between two extremes, arm's length transactions on the one hand and the merger of the two firs on the other hand. Cooperation among companies is usually analyzed in strategic management literature on the dyadic level or on the level of the partcipating firs. Only recently, interest by economists has grown to study cooperative efforts of firs within an inter-organisational network framework (see e.g. Hagedoom and Schakenraad. 1990, 1992, 1993). In high- tech industries where almost all incumbents are linked to each other by means of a network of cooperative agreements, an analysis on the level of the individual players or allances is not appropriate to understand the strategic value of cooperative strategies. -

Solaris X Window System Reference Manual
Solaris X Window System Reference Manual Sun Microsystems, Inc. 2550 Garcia Avenue Mountain View, CA 94043 U.S.A. 1995 Sun Microsystems, Inc., 2550 Garcia Avenue, Mountain View, California 94043-1100 USA. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Portions of this product may be derived from the UNIX system, licensed from UNIX System Laboratories, Inc., a wholly owned subsidiary of Novell, Inc., and from the Berkeley 4.3 BSD system, licensed from the University of California. Third- party software, including font technology in this product, is protected by copyright and licensed from Sun's Suppliers. RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013 and FAR 52.227-19. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, Sun Microsystems, the Sun logo, SunSoft, the SunSoft logo, Solaris, SunOS, OpenWindows, DeskSet, ONC, ONC+, and NFS are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. OPEN LOOK is a registered trademark of Novell, Inc. -
Apollo Documentation Quick Reference Apollo
DISTRIBUTED TEXT EDITING COMPUTING LANGUAGES AND PROCESSING Apollo Documentation Quick Reference apollo Apollo Documentation Quick Reference Order No. 002685-A01 Restricted Rights Notice Use. duplication. or disclosure by the Government is subject to restrictions as set forth in subparagraph (c) (1) (ii) of the Rights in Technical Data and Computer Software clause at DFARS 52.227-7013. Apollo Computer Inc. 330 Billerica Road Chelmsford. MA 01824 (508) 256-6600 Notice: Notwithstanding any other lease or license agreement that may pertain to. or accompany the delivery of. this com puter software. the rights of the Government regarding its use. reproduction and disclosure are as set forth in Section 52.227-19 of the FARS Computer Software - Restricted Rights clause. © 1988. 1989 Apollo Computer Inc .• Chelmsford. Massachu setts. Unpublished -- all rights reserved under the Copyright Laws of the United States. This notice shall be marked on any reproduction of these data. In whole or In part. Copyright © 1988,1989 Apollo Computer Inc. All rights reserved. Printed in U.S.A. First Printing: July 1988 Latest Printing: July 1989 This document was produced using the Interleaf Technical Publishing Software (TPS) and the InterCAP Illustrator I Technical illustrating Sys tem, a product of InterCAP Graphics Systems Corporation. Interleaf and TPS are trademarks of Interleaf, Inc. Apollo and Domain are registered trademarks of Apollo Computer Inc. DEC Is a registered trademark of Digital Equipment Corporation. IBM, Personal Computer AT, and AT are registered trademarks of Interna tional Business Machines Corporation. XT Is a trademark of International Business Machines Corporation. APPLE and LaserWrlter are registered trademarks of Apple Computer, Inc. -

MIPS Oral History Panel Session 1: Founding the Company
MIPS Oral History Panel Session 1: Founding the Company John Hennessy, John Moussouris, Edward (Skip) Stritter, and Larry Weber Moderated by: Michael Malone Recorded: February 18, 2011 Mountain View, California CHM Reference number: X6042.2011 © 2011 Computer History Museum MIPS Oral History Panel Session 1: Founding the Company <Introduction by Edward (Skip) Stritter> Stritter: Hi, my name is Skip Stritter. In 1984, I got together with friends of mine, John Moussouris and John Hennessy, and we founded a new company called MIPS Computer Systems. So in 1984—I’ll try to set the context here-- minicomputers have completely established themselves over the former mainframe dominance, and it’s been a few years now since the IBM PC was announced, 1981, and before that the Apple II and Apple III computers, so personal computers were starting to spread, and starting to have an influence. But personal computers didn’t solve all the problems for intensive computer users. In a new type of computing, a new industry was building up that was called workstations. Workstation companies, such as Sun Microsystems, Apollo Computer, and in 1984, just recently established Silicon Graphics, were starting to introduce new technologies and new ways to think about computing on your desktop, but as powerful as the world of minicomputers and mainframes before it. Up to this point in 1984-- which by the way, is the year that Apple Macintosh was introduced-- workstations and high-end PCs had been based on 16-bit microprocessors, Intel 8086; and by 1984, Intel 286; Motorola 68000, which was used in the Apple Macintosh, were for the day the powerful 16-, almost 32-bit microprocessor generation.