A Survey of Distributed File Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AIX® Version 6.1 Performance Toolbox Guide Limiting Access to Data Suppliers
AIX Version 6.1 Performance Toolbox Version 3 Guide and Reference AIX Version 6.1 Performance Toolbox Version 3 Guide and Reference Note Before using this information and the product it supports, read the information in Appendix G, “Notices,” on page 431. This edition applies to AIX Version 6.1 and to all subsequent releases and modifications until otherwise indicated in new editions. (c) Copyright AT&T, 1984, 1985, 1986, 1987, 1988, 1989. All rights reserved. Copyright Sun Microsystems, Inc., 1985, 1986, 1987, 1988. All rights reserved. The Network File System (NFS) was developed by Sun Microsystems, Inc. This software and documentation is based in part on the Fourth Berkeley Software Distribution under license from The Regents of the University of California. We acknowledge the following institutions for their role in its development: the Electrical Engineering and Computer Sciences Department at the Berkeley Campus. The Rand MH Message Handling System was developed by the Rand Corporation and the University of California. Portions of the code and documentation described in this book were derived from code and documentation developed under the auspices of the Regents of the University of California and have been acquired and modified under the provisions that the following copyright notice and permission notice appear: Copyright Regents of the University of California, 1986, 1987, 1988, 1989. All rights reserved. Redistribution and use in source and binary forms are permitted provided that this notice is preserved and that due credit is given to the University of California at Berkeley. The name of the University may not be used to endorse or promote products derived from this software without specific prior written permission. -

The New Standard for Data Archiving
The new standard for data archiving 1 Explosively increasing 2 Why data management digital data is important Ever-increasing volumes of digital data are mounting up every day due to rapidly growing Today, files can be lost from computers in any number of ways—you might accidentally internet technology, widespread use of SNS, data transmission between network- connected delete a file, a virus might wipe one out, or there could be a complete hard drive failure. devices, and other trends. Within the video production industry, data-heavy video content When a hard drive dies an untimely death, it can feel like a house has burnt down. (for example, 4K, 8K, and 4K/8K high-frame-rate video) is becoming a major source of video Important personal items are usually gone forever—photos, significant documents, broadcasting. Many companies and research institutes are creating high volumes of data downloaded music, and more. (big data) for use in AI systems. Somehow, these newly created assets need to be managed effectively, stored safely, and utilized along with the old assets. There are many options for backing up content without any sophisticated equipment—you can 163,000 EB use DVDs, external hard drives, optical discs, or even online storage. It’s a good idea to back up data to multiple places. Computer Natural Viruses Disasters 4% Other 2% 40,026 EB 3% 2,837 EB 8,591 EB 1,227 EB Software Corruption 9% 2010 2012 2015 2020 2025 System/ Hardware 1 EB = 1,000,000 TB Malfunction 56% User Error Performance 26% Source: Ontrack Data Recovery High Performance www.ontrack.co.uk/understandingdataloss E-commerce, Financial HOT SSD RAM Capacity Optimized Back Oce, General Service WARM HDD Sony's Optical Disc Archive storage system offers the solution, Long-Term Archive COLD with a low total cost of ownership through the use of long-life Auto Loader, O-line Tape Optical Disc Cost media, and it includes inter-generational compatibility based on the same optical disc technology used in DVDs and Blu-ray discs. -

SYSTEM V RELEASE 4 Migration Guide
- ATlaT UN/~ SYSTEM V RELEASE 4 Migration Guide UNIX Software Operation Copyright 1990,1989,1988,1987,1986,1985,1984,1983 AT&T All Rights Reserved Printed In USA Published by Prentice-Hall, Inc. A Division of Simon & Schuster Englewood Cliffs, New Jersey 07632 No part of this publication may be reproduced or transmitted in any form or by any means-graphic, electronic, electrical, mechanical, or chemical, including photocopying, recording in any medium, tap ing, by any computer or information storage and retrieval systems, etc., without prior permissions in writing from AT&T. IMPORTANT NOTE TO USERS While every effort has been made to ensure the accuracy of all information in this document, AT&T assumes no liability to any party for any loss or damage caused by errors or omissions or by state ments of any kind in this document, its updates, supplements, or special editions, whether such er rors are omissions or statements resulting from negligence, accident, or any other cause. AT&T furth er assumes no liability arising out of the application or use of any product or system described herein; nor any liability for incidental or consequential damages arising from the use of this docu ment. AT&T disclaims all warranties regarding the information contained herein, whether expressed, implied or statutory, including implied warranties of merchantability or fitness for a particular purpose. AT&T makes no representation that the interconnection of products in the manner described herein will not infringe on existing or future patent rights, nor do the descriptions contained herein imply the granting or license to make, use or sell equipment constructed in accordance with this description. -

Andrew File System (AFS) Google File System February 5, 2004
Advanced Topics in Computer Systems, CS262B Prof Eric A. Brewer Andrew File System (AFS) Google File System February 5, 2004 I. AFS Goal: large-scale campus wide file system (5000 nodes) o must be scalable, limit work of core servers o good performance o meet FS consistency requirements (?) o managable system admin (despite scale) 400 users in the “prototype” -- a great reality check (makes the conclusions meaningful) o most applications work w/o relinking or recompiling Clients: o user-level process, Venus, that handles local caching, + FS interposition to catch all requests o interaction with servers only on file open/close (implies whole-file caching) o always check cache copy on open() (in prototype) Vice (servers): o Server core is trusted; called “Vice” o servers have one process per active client o shared data among processes only via file system (!) o lock process serializes and manages all lock/unlock requests o read-only replication of namespace (centralized updates with slow propagation) o prototype supported about 20 active clients per server, goal was >50 Revised client cache: o keep data cache on disk, metadata cache in memory o still whole file caching, changes written back only on close o directory updates are write through, but cached locally for reads o instead of check on open(), assume valid unless you get an invalidation callback (server must invalidate all copies before committing an update) o allows name translation to be local (since you can now avoid round-trip for each step of the path) Revised servers: 1 o move -

Restoring in All Situations
Restoring in all situations Desktop and laptop protection 1 Adapt data restore methods to different situations Executive Summary Whether caused by human error, a cyber attack, or a physical disaster, data loss costs organizations millions of euros every year (3.5 million euros on average according to the Ponemon Institute). Backup Telecommuting Office remains the method of choice to protect access to company data and ensure their availability. But a good backup strategy must necessarily be accompanied by a good disaster recovery strategy. Nomadization The purpose of this white paper is to present the best restore practices depending on the situation you are in, in order to save valuable time! VMs / Servers Apps & DBs NAS Laptops Replication 2 Table of Contents EXECUTIVE SUMMARY .......................................................................................................................... 2 CONTEXT ................................................................................................................................................ 4 WHAT ARE THE STAKES BEHIND THE RESTORING ENDPOINT USER DATA? ................................. 5 SOLUTION: RESTORING ENDPOINT DATA USING LINA ................................................................... 6-7 1. RESTORE FOR THE MOST NOVICE USERS ................................................................................ 8-10 2. RESTORE FOR OFF SITE USERS ................................................................................................11-13 3. RESTORE FOLLOWING LOSS, -

IBM Connect:Direct for Microsoft Windows: Documentation Fixpack 1 (V6.1.0.1)
IBM Connect:Direct for Microsoft Windows 6.1 Documentation IBM This edition applies to Version 5 Release 3 of IBM® Connect:Direct and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 1993, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Chapter 1. Release Notes.......................................................................................1 Requirements...............................................................................................................................................1 Features and Enhancements....................................................................................................................... 2 Special Considerations................................................................................................................................ 3 Known Restrictions...................................................................................................................................... 4 Restrictions for Connect:Direct for Microsoft Windows........................................................................ 4 Restrictions for Related Software.......................................................................................................... 6 Installation Notes.........................................................................................................................................6 -

4010, 237 8514, 226 80486, 280 82786, 227, 280 a AA. See Anti-Aliasing (AA) Abacus, 16 Accelerated Graphics Port (AGP), 219 Acce
Index 4010, 237 AIB. See Add-in board (AIB) 8514, 226 Air traffic control system, 303 80486, 280 Akeley, Kurt, 242 82786, 227, 280 Akkadian, 16 Algebra, 26 Alias Research, 169 Alienware, 186 A Alioscopy, 389 AA. See Anti-aliasing (AA) All-In-One computer, 352 Abacus, 16 All-points addressable (APA), 221 Accelerated Graphics Port (AGP), 219 Alpha channel, 328 AccelGraphics, 166, 273 Alpha Processor, 164 Accel-KKR, 170 ALT-256, 223 ACM. See Association for Computing Altair 680b, 181 Machinery (ACM) Alto, 158 Acorn, 156 AMD, 232, 257, 277, 410, 411 ACRTC. See Advanced CRT Controller AMD 2901 bit-slice, 318 (ACRTC) American national Standards Institute (ANSI), ACS, 158 239 Action Graphics, 164, 273 Anaglyph, 376 Acumos, 253 Anaglyph glasses, 385 A.D., 15 Analog computer, 140 Adage, 315 Anamorphic distortion, 377 Adage AGT-30, 317 Anatomic and Symbolic Mapper Engine Adams Associates, 102 (ASME), 110 Adams, Charles W., 81, 148 Anderson, Bob, 321 Add-in board (AIB), 217, 363 AN/FSQ-7, 302 Additive color, 328 Anisotropic filtering (AF), 65 Adobe, 280 ANSI. See American national Standards Adobe RGB, 328 Institute (ANSI) Advanced CRT Controller (ACRTC), 226 Anti-aliasing (AA), 63 Advanced Remote Display Station (ARDS), ANTIC graphics co-processor, 279 322 Antikythera device, 127 Advanced Visual Systems (AVS), 164 APA. See All-points addressable (APA) AED 512, 333 Apalatequi, 42 AF. See Anisotropic filtering (AF) Aperture grille, 326 AGP. See Accelerated Graphics Port (AGP) API. See Application program interface Ahiska, Yavuz, 260 standard (API) AI. -

File Server Scaling with Network-Attached Secure Disks
Appears in Proceedings of the ACM International Conference on Measurement and Modeling of Computer Systems (Sigmetrics ‘97), Seattle, Washington, June 15-18, 1997. File Server Scaling with Network-Attached Secure Disks Garth A. Gibson†, David F. Nagle*, Khalil Amiri*, Fay W. Chang†, Eugene M. Feinberg*, Howard Gobioff†, Chen Lee†, Berend Ozceri*, Erik Riedel*, David Rochberg†, Jim Zelenka† *Department of Electrical and Computer Engineering †School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213-3890 [email protected] http://www.cs.cmu.edu/Web/Groups/NASD/ Abstract clients with efficient, scalable, high-bandwidth access to stored data. This paper discusses a powerful approach to fulfilling this By providing direct data transfer between storage and client, net- need. Network-attached storage provides high bandwidth by work-attached storage devices have the potential to improve scal- directly attaching storage to the network, avoiding file server ability for existing distributed file systems (by removing the server store-and-forward operations and allowing data transfers to be as a bottleneck) and bandwidth for new parallel and distributed file striped over storage and switched-network links. systems (through network striping and more efficient data paths). The principal contribution of this paper is to demonstrate the Together, these advantages influence a large enough fraction of the potential of network-attached storage devices for penetrating the storage market to make commodity network-attached storage fea- markets defined by existing distributed file system clients, specifi- sible. Realizing the technology’s full potential requires careful cally the Network File System (NFS) and Andrew File System consideration across a wide range of file system, networking and (AFS) distributed file system protocols. -
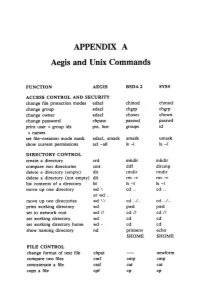
APPENDIX a Aegis and Unix Commands
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

Chapter 1 – 15 Essay Question Review
Chapter 1 – 15 Essay Question Review Chapter 1 1. Explain why an operating system can be viewed as a resource allocator. Ans: A computer system has many resources that may be required to solve a problem: CPU time, memory space, file-storage space, I/O devices, and so on. The operating system acts as the manager of these resources. Facing numerous and possibly conflicting requests for resources, the operating system must decide how to allocate them to specific programs and users so that it can operate the computer system efficiently and fairly. Feedback: 1.1.2 2. Explain the purpose of an interrupt vector. Ans: The interrupt vector is merely a table of pointers to specific interrupt-handling routines. Because there are a fixed number of interrupts, this table allows for more efficient handling of the interrupts than with a general-purpose, interrupt-processing routine. Feedback: 1.2.1 3. What is a bootstrap program, and where is it stored? Ans: A bootstrap program is the initial program that the computer runs when it is powered up or rebooted. It initializes all aspects of the system, from CPU registers to device controllers to memory contents. Typically, it is stored in read-only memory (ROM) or electrically erasable programmable read-only memory (EEPROM), known by the general term firmware, within the computer hardware. Feedback: 1.2.1 4. What role do device controllers and device drivers play in a computer system? Ans: A general-purpose computer system consists of CPUs and multiple device controllers that are connected through a common bus. -

An Advanced Solution for Long-Term Retention of Enterprise Digital
Data Management, Simplified. Enterprise Edition An Advanced Solution for Long-term Retention of Enterprise Digital Assets A centrally managed, secure archive is a key requirement for today’s enterprises, which must contend with exponential growth in data volumes, long-term retention requirements, and e-discovery mandates. Atempo Digital Archive, Enterprise Edition, is a comprehensive solution that addresses each of these data archiving challenges. Providing capabilities for both automatically and manually archiving data in long-term storage platforms, Atempo Digital Archive ensures that all corporate data is easy to find and access for as long as it needs to be retained. An Answer to Each Archiving Need Addressing Today’s Storage Management Challenges Enabling the Long-term Retention of Digital Assets Today, organizations must manage more, and more Digital information represents both the lifeblood of a critical, data than ever before—and data volumes continue business today, and the basis of records that may need to grow at an explosive pace. Traditional backup and to be accessed for generations. With its integrated recovery solutions have proven ill-equipped to keep up capabilities for full content indexing, search, and metadata with these demands. To ensure these increasing volumes indexing, Atempo Digital Archive allows users to retrieve of critical information are always available when needed, information quickly and easily. In addition, it offers organizations require advanced new archiving capabilities. refreshing mechanisms that verify whether storage Atempo Digital Archive is the one solution that enables media is still readable, and that ensure information IT organizations to address their storage management can continue to be accessed on an ongoing basis. -

Solaris 10 System Administration - Part II
Solaris 10 System Administration - Part II Duration: 5 Days Course Code: SSA2 Overview: This Solaris System Administration training course will provide delegates with practical experience of configuring various aspects of a Oracle Solaris system up to and including Solaris version 10. This course extends the skills a delegate will have gained from attending the Solaris System Administration - Part 1 course. Delegates will cover more specialised tasks such as managing the system log and configuring remote file sharing with NFS whilst gaining the key skills required to prepare for the Oracle Solaris 10 System Administrator Certified Professional Part II exam (1Z0-878) . Target Audience: This Solaris 10 System Administration - Part II course is aimed at IT staff responsible for administering a networked server in a local area network,running the Oracle Solaris operating environment. It will extend their skills beyond basic administration tasks. Objectives: Administering Solaris systems involves many specialised tasks including; monitoring system events with syslog,performing network installations,dealing with various aspects of the network environment and assigning system roles to users. Delegates taking this class will gain the necessary knowledge and skills to perform these tasks. Prerequisites: Attendance on the Solaris Introduction and Solaris 10 System Administration - Part I courses or similar knowledge is required. Shell Programming knowledge is beneficial but not essential. This skill can be gained by attending the Solaris Shell Programming