ABSTRACT NORMAN, MATTHEW ROSS. Investigation of Higher
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dreaming of a Better Christmas for UK Kids
Dec 02, 2014 10:37 GMT Dreaming of a better Christmas for UK kids Dreams, the UK’s leading bed specialist, has teamed up with Bauer Media’s Cash For Kids charity to support the company’s ‘Mission Christmas’ initiative to help disadvantaged children around the UK this December. Throughout the month, customers will be able to make donations or bring along a gift to any of Dreams’ 160 retail stores, which will be the official ‘drop-off points’ for the scheme. Donations will be distributed to local charitable and voluntary organisations around the country at the end of the month, to benefit children under the age of 18 living below the poverty line. A list of charities supported can be found at the Cash For Kids web site at www.cashforkids.uk.com. The ‘Mission Christmas’ campaign also sees support from top celebrities including Ant & Dec, comedian John Bishop and more. This year, the charity aims to build on the £8 million plus gifts and cash they delivered to disadvantaged children across the UK last Christmas, and it is the first time the organisation has chosen to work with a national retail partner to raise funds and donations for the initiative. Sally Aitchison, managing director, Cash For Kids, said, “We are thrilled to have Dreams supporting Cash For Kids Mission Christmas. The success of this campaign relies on ease of access for people to drop off gifts. A company like Dreams that has so many branches in every city will have such an impact on the campaign. We are very excited to have them as a partner.” Lisa Bond, marketing director, Dreams, said, “It is a privilege for us to support a scheme like Cash For Kids Mission Christmas through our network of stores, and hope that the donations from around the UK will truly make a difference to children’s lives during Christmas and beyond.” End Child Poverty estimates that four million children currently live below the poverty line across the UK, which equates to one in three children. -

Basisdaten 2016 1
Verzeichnis der Tabellen und Grafiken Media Perspektiven Basisdaten 2016 1 Seite Rundfunk: Programmangebot und Empfangssituation TV-Haushalte nach Empfangsebenen in Deutschland 2016 4 Empfangspotenzial der deutschen Fernsehsender 2016 4 Öffentlich-rechtlicher Rundfunk: Erträge/Leistungen Rundfunkgebühren/Rundfunkbeitrag 6 Erträge aus der Rundfunkgebühr bzw. dem Rundfunkbeitrag 7 Werbefunkumsätze der ARD-Werbung 7 Werbefernsehumsätze von ARD und ZDF 7 Programmleistung der ARD 2015: Erstes Fernsehprogramm 8 Programmleistung von ARD und ZDF für KiKA und Phoenix 2015 8 Programmleistung von ARD und ZDF für Arte 2015 9 Programmleistung des ZDF 2015 9 Programmleistung von 3sat 2015 10 Programmleistung von Deutschlandradio 2015 10 Programmleistung der Deutschen Welle 2015 11 Programmleistung der ARD 2015: Hörfunk 11 Privater Rundfunk: Erträge/Leistungen Werbeumsätze privater Hörfunkanbieter 12 Bruttowerbeumsätze privater Fernsehanbieter 12 Programmleistung von RTL 2015 13 Programmleistung von ProSieben 2015 14 Programmleistung von Sat.1 2015 14 Programmleistung von VOX 2015 14 Programmleistung von Super RTL 2015 15 Programmleistung von RTL II 2015 15 Programmleistung von kabel eins 2015 16 Programmleistung von Sport1 2015 16 Programmprofile im dualen Rundfunksystem Spartenprofile von Das Erste, ZDF, RTL, Sat.1 und ProSieben 2013 bis 2015 17 Programmstruktur 2015: Sparten und Formen von Das Erste, ZDF, RTL, Sat.1 und ProSieben 19 Themenstruktur der wichtigsten Nachrichtensendungen von ARD, ZDF, RTL und Sat.1 22 Themenkategorien und ausgewählte -

Bauer Media Group Phase 1 Decision
Completed acquisitions by Bauer Media Group of certain businesses of Celador Entertainment Limited, Lincs FM Group Limited and Wireless Group Limited, as well as the entire business of UKRD Group Limited Decision on relevant merger situation and substantial lessening of competition ME/6809/19; ME/6810/19; ME/6811/19; and ME/6812/19 The CMA’s decision on reference under section 22(1) of the Enterprise Act 2002 given on 24 July 2019. Full text of the decision published on 30 August 2019. Please note that [] indicates figures or text which have been deleted or replaced in ranges at the request of the parties or third parties for reasons of commercial confidentiality. SUMMARY 1. Between 31 January 2019 and 31 March 2019 Heinrich Bauer Verlag KG (trading as Bauer Media Group (Bauer)), through subsidiaries, bought: (a) From Celador Entertainment Limited (Celador), 16 local radio stations and associated local FM radio licences (the Celador Acquisition); (b) From Lincs FM Group Limited (Lincs), nine local radio stations and associated local FM radio licences, a [] interest in an additional local radio station and associated licences, and interests in the Lincolnshire [] and Suffolk [] digital multiplexes (the Lincs Acquisition); (c) From The Wireless Group Limited (Wireless), 12 local radio stations and associated local FM radio licences, as well as digital multiplexes in Stoke, Swansea and Bradford (the Wireless Acquisition); and (d) The entire issued share capital of UKRD Group Limited (UKRD) and all of UKRD’s assets, namely ten local radio stations and the associated local 1 FM radio licences, interests in local multiplexes, and UKRD’s 50% interest in First Radio Sales (FRS) (the UKRD Acquisition). -

Q4 2013 Rajar Results Bauer Radio Records Highest Ever
Q4 2013 RAJAR RESULTS BAUER RADIO RECORDS HIGHEST EVER AUDIENCE OF OVER 16.4 MILLION - Bauer Radio achieves highest ever reach, hours and share - Bauer’s Passion Portfolio reaches 10m listeners for first time - Nationally, Kiss UK hits 5m listeners and records highest ever hours and share - Absolute 80s, Planet Rock & Kisstory claim commercial 1-2-3 for digital stations Bauer’s Passion Portfolio is the home of passionate, iconic national brands dedicated to music and entertainment: The Passion Portfolio recorded its highest-ever reach of 10m adults each week The newly acquired Absolute Radio Network performed strongly, reaching 3.5m listeners (adding almost 250,000 listeners, an increase of 7.5% yoy) Nationally, The Christian O’Connell Breakfast Show reached 1.4m listeners (up 4.0% yoy) Absolute Radio 80s remains the no. 1 commercial digital station, reaching 1.2m listeners (up 33% yoy) with hours up 27% yoy Planet Rock, the second most popular commercial digital station, reached 1.1m listeners (adding over 250,000 listeners yoy) with an impressive increase in listening hours up almost a third yoy Nationally, Kiss performed strongly, reaching over 5m adults each week (up 18% yoy) with its highest ever share & highest ever total hours (up 19% yoy) In London, Kiss 100 is the no.2 commercial station for reach with 1.83m listeners and the market-leader for both 15-24 and 15-34 year olds Rickie, Melvin and Charlie in the Morning had a strong quarter reaching almost 1.6m listeners across the UK Kisstory continues to grow in popularity since launching last May – now reaching 927,000 listeners each week heat radio reached 714,000 listeners. -

QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 15Th September 2019
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 15th September 2019 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 55,032,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % All Radio Q 48537 88 18.0 20.4 989221 100.0 All BBC Radio Q 33451 61 8.9 14.6 488274 49.4 All BBC Radio 15-44 Q 12966 51 4.6 8.9 115944 33.9 All BBC Radio 45+ Q 20485 69 12.5 18.2 372330 57.5 All BBC Network Radio1 Q 30828 56 7.7 13.8 425563 43.0 BBC Local Radio Q 7430 14 1.1 8.4 62711 6.3 All Commercial Radio Q 35930 65 8.6 13.2 475371 48.1 All Commercial Radio 15-44 Q 17884 71 8.5 12.0 214585 62.7 All Commercial Radio 45+ Q 18046 61 8.8 14.5 260786 40.3 All National Commercial1 Q 22361 41 3.8 9.5 211324 21.4 All Local Commercial (National TSA) Q 25988 47 4.8 10.2 264047 26.7 Other Radio Q 4035 7 0.5 6.3 25577 2.6 Source: RAJAR/Ipsos MORI/RSMB 1 See note on back cover. For survey periods and other definitions please see back cover. Please note that the information contained within this quarterly data release has yet to be announced or otherwise made public Embargoed until 00.01 am and as such could constitute relevant information for the purposes of section 118 of FSMA and non-public price sensitive 24th October 2019 information for the purposes of the Criminal Justice Act 1993. -

QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 27Th March 2011
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 27th March 2011 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 51,618,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % ALL RADIO Q 47266 92 20.5 22.4 1058098 100.0 ALL BBC Q 35074 68 11.3 16.6 581870 55.0 ALL BBC 15-44 Q 15955 63 7.6 12.1 193775 43.1 ALL BBC 45+ Q 19120 73 14.8 20.3 388095 63.7 All BBC Network Radio1 Q 31889 62 9.5 15.3 488535 46.2 BBC Local/Regional Q 10197 20 1.8 9.2 93335 8.8 ALL COMMERCIAL Q 34046 66 8.7 13.3 451178 42.6 ALL COMMERCIAL 15-44 Q 18556 73 9.5 13.0 241582 53.8 ALL COMMERCIAL 45+ Q 15490 59 8.0 13.5 209596 34.4 All National Commercial1 Q 15943 31 2.4 7.7 123363 11.7 All Local Commercial (National TSA) Q 27305 53 6.4 12.0 327815 31.0 Other Listening Q 3255 6 0.5 7.7 25051 2.4 Source: RAJAR/Ipsos MORI/RSMB 1 See note on back cover. For survey periods and other definitions please see back cover. Embargoed until 00.01 am Enquires to: RAJAR, 2nd floor, 5 Golden Square, London W1F 9BS 12th May 2011 Telephone: 020 7292 9040 Facsimile: 020 7292 9041 e mail: [email protected] Internet: www.rajar.co.uk ©Rajar 2011. -
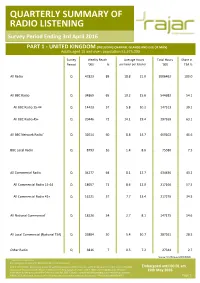
QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 3Rd April 2016
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 3rd April 2016 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 53,575,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % All Radio Q 47823 89 18.8 21.0 1006462 100.0 All BBC Radio Q 34869 65 10.2 15.6 544682 54.1 All BBC Radio 15-44 Q 14423 57 5.8 10.2 147513 39.1 All BBC Radio 45+ Q 20446 72 14.1 19.4 397169 63.1 All BBC Network Radio1 Q 32014 60 8.8 14.7 469102 46.6 BBC Local Radio Q 8793 16 1.4 8.6 75580 7.5 All Commercial Radio Q 34277 64 8.1 12.7 434436 43.2 All Commercial Radio 15-44 Q 18057 71 8.6 12.0 217166 57.5 All Commercial Radio 45+ Q 16221 57 7.7 13.4 217270 34.5 All National Commercial1 Q 18220 34 2.7 8.1 147175 14.6 All Local Commercial (National TSA) Q 26884 50 5.4 10.7 287261 28.5 Other Radio Q 3816 7 0.5 7.2 27344 2.7 Source: RAJAR/Ipsos MORI/RSMB 1 See note on back cover. For survey periods and other definitions please see back cover. Please note that the information contained within this quarterly data release has yet to be announced or otherwise made public Embargoed until 00.01 am and as such could constitute relevant information for the purposes of section 118 of FSMA and non-public price sensitive 19th May 2016 information for the purposes of the Criminal Justice Act 1993. -

PRS Radio Dec 2018.Xlsx
No of Days in Total Per Amount from Amount from Domain StationId Station UDC Performance Date Period Minute Rate Broadcast Public Reception RADIO BR ONE BBC RADIO 1 B0001 31/12/2099 92 £12.2471 £7.3036 £4.9435 RADIO BR TWO BBC RADIO 2 B0002 31/12/2099 92 £25.4860 £25.3998 £0.0862 RADIO BR1EXT BBC 1XTRA CENSUS B0106 31/12/2099 92 £2.8113 £2.7199 £0.0914 RADIO BRASIA BBC ASIAN NETWORK (CENSUS) B0064 31/12/2099 92 £3.6951 £3.3058 £0.3892 RADIO BRBEDS BBC THREE COUNTIES RADIO (CENSUS) B0065 31/12/2099 92 £0.2445 £0.2442 £0.0003 RADIO BRBERK BBC RADIO BERKSHIRE (CENSUS) B0103 31/12/2099 92 £0.1436 £0.1435 £0.0002 RADIO BRBRIS BBC RADIO BRISTOL (CENSUS) B0066 31/12/2099 92 £0.1532 £0.1531 £0.0002 RADIO BRCAMB BBC RADIO CAMBRIDGESHIRE (CENSUS) B0067 31/12/2099 92 £0.1494 £0.1493 £0.0002 RADIO BRCLEV BBC RADIO TEES (CENSUS) B0068 31/12/2099 92 £0.1478 £0.1477 £0.0002 RADIO BRCMRU BBC RADIO CYMRU B0011 31/12/2099 92 £0.5707 £0.5690 £0.0017 RADIO BRCORN BBC RADIO CORNWALL (CENSUS) B0069 31/12/2099 92 £0.1535 £0.1534 £0.0002 RADIO BRCOVN BBC RADIO COVENTRY AND WATWICKSHIRE(CENSUS) B0070 31/12/2099 92 £0.1023 £0.1022 £0.0001 RADIO BRCUMB BBC RADIO CUMBRIA (CENSUS) B0071 31/12/2099 92 £0.1085 £0.1084 £0.0001 RADIO BRCYMM BBC RADIO CYMRU 2 B0114 31/12/2099 92 £0.5707 £0.5690 £0.0017 RADIO BRDEVN BBC RADIO DEVON (CENSUS) B0072 31/12/2099 92 £0.2421 £0.2419 £0.0003 RADIO BRDRBY BBC RADIO DERBY (CENSUS) B0073 31/12/2099 92 £0.1535 £0.1534 £0.0002 RADIO BRESSX BBC ESSEX (CENSUS) B0074 31/12/2099 92 £0.2091 £0.2089 £0.0002 RADIO BRFIVE BBC FIVE LIVE B0005 -

“Reaching 79% of Commercial Radio's Weekly Listeners…” National Coverage
2019 GTN UK is the British division of Global Traffic Network; the leading provider of custom traffic reports to commercial radio and television stations. GTN has similar operations in Australia, Brazil and Canada. GTN is the largest Independent radio network in the UK We offer advertisers access to over 240 radio stations across the country, covering every major conurbation with a solus opportunity enabling your brand to stand out with up to 48% higher ad recall than that of a standard ad break. With both a Traffic & Travel offering, as well as an Entertainment News package, we reach over 28 million adults each week, 80% of all commercial radio’s listeners, during peak listening times only, 0530- 0000. Are your brands global? So are we. Talk to us about a global partnership. Source: Clark Chapman research 2017 RADIO “REACHING 79% OF COMMERCIAL RADIO’S WEEKLY LISTENERS…” NATIONAL COVERAGE 240 radio stations across the UK covering all major conurbations REACH & FREQUENCY Reaching 28 million adults each week, 620 ratings. That’s 79% of commercial radio’s weekly listening. HIGHER ENGAGEMENT With 48% higher ad recall this is the stand-out your brand needs, directly next to “appointment-to-listen” content. BREAKFAST, MORNING, AFTERNOON, DRIVE All advertising is positioned within key radio listening times for maximum reach. 48% HIGHER AD RECALL THAN THAT OF A STANDARD AD BREAK Source: Clark Chapman research NATIONAL/DIGITAL LONDON NORTH EAST Absolute Radio Absolute Radio Capital North East Absolute Radio 70s Kiss Classic FM (North) Absolute -

Distribution Rules
PERFORMING RIGHT SOCIETY LIMITED DISTRIBUTION RULES Appendices APPENDIX Standard distribution cycle Distribution Source April July October December Reconciliation BBC radio Oct – Dec Jan - Mar Apr - Jun Jul - Sept July BBC TV Sept - Dec Jan - Mar Apr - Jun Jul - Aug July BSkyB TV Sept - Dec Jan - Mar Apr - Jun Jul - Aug October All other TV Re Sept - Dec Jan - Mar Apr - Jun Jul - Aug April po (exc. music TV channels) rti All other radio ng Oct – Dec Jan - Mar Apr - Jun Jul - Sept April (and music TV channels) Pe ri od Public performance * Oct – Dec Jan - Mar Apr - Jun Jul - Sept April Online ** Oct – Dec Jan - Mar Apr - Jun Jul - Sept N/A International Jul-Dec Jan-Jun N/A (agencies) International Varies depending on affiliate society timetable N/A (affiliate societies) *Concerts using the live concert service are distributed outside the four major distributions with a target of within 60 days of the concert **It is not always possible to adhere to this timetable for some online services Broadcast sampling rates Since 2010 new TV and radio services are sampled at the following minimum rates. TV Sampling Threshold Sample Band Days 4 0-15K 10 15-30K 37 30-60K 91 60-100K 181 100-200K 365 200K+ Radio Sampling Threshold Sample Band Days 4 £0-£50K 8 £50-£100K 16 £100-£200K 32 £200-£500K 365 £750K+ At present services that existed before 2010 are still sampled at minimum rates calculated using a complex statistical formula. In practice, because of electronic reporting and the use of music recognition technology, many services have much higher sample rates, bordering on census for non-advertising plays. -

GTN UK Is the British Division of Global Traffic Network; the Leading Provider of Custom Traffic Reports to Commercial Radio and Television Stations
2020 GTN UK is the British division of Global Traffic Network; the leading provider of custom traffic reports to commercial radio and television stations. GTN has similar operations in Australia, Brazil and Canada. GTN is the largest Independent radio network in the UK We offer advertisers access to over 250 radio stations across the country, covering every major conurbation with a solus opportunity enabling your brand to stand out with up to 48% higher ad recall than that of a standard ad break. With both a Traffic & Travel offering, as well as an Entertainment News package, we reach over 28.6 million adults each week, 80% of all commercial radio’s listeners, during peak listening times only, 0530-0000. Are your brands global? So are we. Talk to us about a global partnership. Source: RAJAR Q3 2020/ Clark Chapman research RADIO “REACHING 73% OF COMMERCIAL RADIO’S WEEKLY LISTENERS…” NATIONAL COVERAGE 225 radio stations across the UK covering all major conurbations REACH & FREQUENCY Reaching over 28 million adults each week, 622 ratings. That’s 73% of commercial radio’s weekly listening. HIGHER ENGAGEMENT With 48% higher ad recall this is the stand-out your brand needs, directly next to “appointment-to-listen” content. BREAKFAST, MORNING, AFTERNOON, DRIVE All advertising is positioned within key radio listening times for maximum reach. 48% HIGHER AD RECALL THAN THAT OF A STANDARD AD BREAK Source: Clark Chapman research Source: RAJAR Q3 2020 NATIONAL/DIGITAL Absolute Radio Absolute Radio 70s (NR) Absolute 80s Absolute Radio 90s Absolute Radio -

QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 14Th September 2014
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 14th September 2014 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 53,502,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % All Radio Q 47614 89 19.0 21.4 1019059 100.0 All BBC Radio Q 34845 65 10.2 15.7 545934 53.6 All BBC Radio 15-44 Q 15116 59 6.5 11.1 167165 41.7 All BBC Radio 45+ Q 19729 71 13.6 19.2 378769 61.3 All BBC Network Radio1 Q 31686 59 8.7 14.7 466020 45.7 BBC Local Radio Q 8945 17 1.5 8.9 79914 7.8 All Commercial Radio Q 34045 64 8.3 13.1 445056 43.7 All Commercial Radio 15-44 Q 17922 70 8.6 12.2 219118 54.7 All Commercial Radio 45+ Q 16124 58 8.1 14.0 225938 36.5 All National Commercial1 Q 16954 32 2.6 8.2 138195 13.6 All Local Commercial (National TSA) Q 27213 51 5.7 11.3 306861 30.1 Other Radio Q 3870 7 0.5 7.3 28069 2.8 Source: RAJAR/Ipsos MORI/RSMB 1 See note on back cover. For survey periods and other definitions please see back cover. Embargoed until 00.01 am Enquiries to: RAJAR, 6th floor, 55 New Oxford St, London WC1A 1BS 23rd October 2014 Telephone: 020 7395 0630 Facsimile: 020 7395 0631 e mail: [email protected] Internet: www.rajar.co.uk ©Rajar 2014.