Revisiting the Distributions of Jupiter's Irregular Moons: II. Orbital
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Astrometric Positions for 18 Irregular Satellites of Giant Planets from 23
Astronomy & Astrophysics manuscript no. Irregulares c ESO 2018 October 20, 2018 Astrometric positions for 18 irregular satellites of giant planets from 23 years of observations,⋆,⋆⋆,⋆⋆⋆,⋆⋆⋆⋆ A. R. Gomes-Júnior1, M. Assafin1,†, R. Vieira-Martins1, 2, 3,‡, J.-E. Arlot4, J. I. B. Camargo2, 3, F. Braga-Ribas2, 5,D.N. da Silva Neto6, A. H. Andrei1, 2,§, A. Dias-Oliveira2, B. E. Morgado1, G. Benedetti-Rossi2, Y. Duchemin4, 7, J. Desmars4, V. Lainey4, W. Thuillot4 1 Observatório do Valongo/UFRJ, Ladeira Pedro Antônio 43, CEP 20.080-090 Rio de Janeiro - RJ, Brazil e-mail: [email protected] 2 Observatório Nacional/MCT, R. General José Cristino 77, CEP 20921-400 Rio de Janeiro - RJ, Brazil e-mail: [email protected] 3 Laboratório Interinstitucional de e-Astronomia - LIneA, Rua Gal. José Cristino 77, Rio de Janeiro, RJ 20921-400, Brazil 4 Institut de mécanique céleste et de calcul des éphémérides - Observatoire de Paris, UMR 8028 du CNRS, 77 Av. Denfert-Rochereau, 75014 Paris, France e-mail: [email protected] 5 Federal University of Technology - Paraná (UTFPR / DAFIS), Rua Sete de Setembro, 3165, CEP 80230-901, Curitiba, PR, Brazil 6 Centro Universitário Estadual da Zona Oeste, Av. Manual Caldeira de Alvarenga 1203, CEP 23.070-200 Rio de Janeiro RJ, Brazil 7 ESIGELEC-IRSEEM, Technopôle du Madrillet, Avenue Galilée, 76801 Saint-Etienne du Rouvray, France Received: Abr 08, 2015; accepted: May 06, 2015 ABSTRACT Context. The irregular satellites of the giant planets are believed to have been captured during the evolution of the solar system. Knowing their physical parameters, such as size, density, and albedo is important for constraining where they came from and how they were captured. -

The Effect of Jupiter\'S Mass Growth on Satellite Capture
A&A 414, 727–734 (2004) Astronomy DOI: 10.1051/0004-6361:20031645 & c ESO 2004 Astrophysics The effect of Jupiter’s mass growth on satellite capture Retrograde case E. Vieira Neto1;?,O.C.Winter1, and T. Yokoyama2 1 Grupo de Dinˆamica Orbital & Planetologia, UNESP, CP 205 CEP 12.516-410 Guaratinguet´a, SP, Brazil e-mail: [email protected] 2 Universidade Estadual Paulista, IGCE, DEMAC, CP 178 CEP 13.500-970 Rio Claro, SP, Brazil e-mail: [email protected] Received 13 June 2003 / Accepted 12 September 2003 Abstract. Gravitational capture can be used to explain the existence of the irregular satellites of giants planets. However, it is only the first step since the gravitational capture is temporary. Therefore, some kind of non-conservative effect is necessary to to turn the temporary capture into a permanent one. In the present work we study the effects of Jupiter mass growth for the permanent capture of retrograde satellites. An analysis of the zero velocity curves at the Lagrangian point L1 indicates that mass accretion provides an increase of the confinement region (delimited by the zero velocity curve, where particles cannot escape from the planet) favoring permanent captures. Adopting the restricted three-body problem, Sun-Jupiter-Particle, we performed numerical simulations backward in time considering the decrease of M . We considered initial conditions of the particles to be retrograde, at pericenter, in the region 100 R a 400 R and 0 e 0:5. The results give Jupiter’s mass at the X moment when the particle escapes from the planet. -

The Convention Ear 58 (Y)Ears of Telling It Like It Isn’T!
The Convention Ear 58 (Y)Ears of Telling It Like It Isn’t! Wednesday, July 25, 2018 Volume LIX, Issue III 25 Hour Convention Coverage Astronomers, Classicists Scramble to Invent Twelve More Stories About Zeus in Order to Name New Moons of Jupiter That’s Entertainment! Results With the recent discovery of twelve new moons around Jupiter, astronomers Congratulations to the following dele- and classicists have put aside their differences (they’ve agreed to spell it gates who have been selected to per- “Jupiter” not “Iuppiter”) to take on the challenge of naming the celestial bod- ies. As is tradition, the new moons will be named after various loves the king form in That's Entertainment! of the gods was said to have had; the only problem is, after 53 moons, we’ve Soren Adams (KY) run out of names. Madelyn Bedard & Ruth Weaver (MA) “This is a different kind of nomenclature problem than what we’re used to,” Cameron Crowley (TX) said astronomer Dr. Joey Chatelain, who looks at the sky for a living. “We’ve Sophia Dort (VA) already used Metis, Adrastea, Amalthea, Thebe, Io, Europa, Ganymede, Cal- Jeffrey Frenkel-Popell (CA) listo,” <we left at this point, did laundry, got lunch, then came back - the list Keon Honaryar (CA) was still going> “... Sinope, Sponde, Autonoe, Megaclite, and S/2003 J 2. We Kiana Hu (CA) simply don’t have any more names to use.” Illinois Dance Troupe (IL) To solve this problem, astronomers have turned to classicists for help. “The Owen Lockwood (OH) answer is simple,” said one leading Classics professor, who wished to remain Akhila Nataraj (FL) anonymous. -

Ice& Stone 2020
Ice & Stone 2020 WEEK 33: AUGUST 9-15 Presented by The Earthrise Institute # 33 Authored by Alan Hale About Ice And Stone 2020 It is my pleasure to welcome all educators, students, topics include: main-belt asteroids, near-Earth asteroids, and anybody else who might be interested, to Ice and “Great Comets,” spacecraft visits (both past and Stone 2020. This is an educational package I have put future), meteorites, and “small bodies” in popular together to cover the so-called “small bodies” of the literature and music. solar system, which in general means asteroids and comets, although this also includes the small moons of Throughout 2020 there will be various comets that are the various planets as well as meteors, meteorites, and visible in our skies and various asteroids passing by Earth interplanetary dust. Although these objects may be -- some of which are already known, some of which “small” compared to the planets of our solar system, will be discovered “in the act” -- and there will also be they are nevertheless of high interest and importance various asteroids of the main asteroid belt that are visible for several reasons, including: as well as “occultations” of stars by various asteroids visible from certain locations on Earth’s surface. Ice a) they are believed to be the “leftovers” from the and Stone 2020 will make note of these occasions and formation of the solar system, so studying them provides appearances as they take place. The “Comet Resource valuable insights into our origins, including Earth and of Center” at the Earthrise web site contains information life on Earth, including ourselves; about the brighter comets that are visible in the sky at any given time and, for those who are interested, I will b) we have learned that this process isn’t over yet, and also occasionally share information about the goings-on that there are still objects out there that can impact in my life as I observe these comets. -
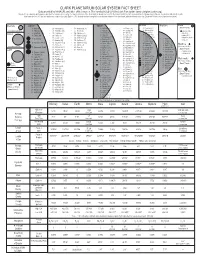
CLARK PLANETARIUM SOLAR SYSTEM FACT SHEET Data Provided by NASA/JPL and Other Official Sources
CLARK PLANETARIUM SOLAR SYSTEM FACT SHEET Data provided by NASA/JPL and other official sources. This handout ©July 2013 by Clark Planetarium (www.clarkplanetarium.org). May be freely copied by professional educators for classroom use only. The known satellites of the Solar System shown here next to their planets with their sizes (mean diameter in km) in parenthesis. The planets and satellites (with diameters above 1,000 km) are depicted in relative size (with Earth = 0.500 inches) and are arranged in order by their distance from the planet, with the closest at the top. Distances from moon to planet are not listed. Mercury Jupiter Saturn Uranus Neptune Pluto • 1- Metis (44) • 26- Hermippe (4) • 54- Hegemone (3) • 1- S/2009 S1 (1) • 33- Erriapo (10) • 1- Cordelia (40.2) (Dwarf Planet) (no natural satellites) • 2- Adrastea (16) • 27- Praxidike (6.8) • 55- Aoede (4) • 2- Pan (26) • 34- Siarnaq (40) • 2- Ophelia (42.8) • Charon (1186) • 3- Bianca (51.4) Venus • 3- Amalthea (168) • 28- Thelxinoe (2) • 56- Kallichore (2) • 3- Daphnis (7) • 35- Skoll (6) • Nix (60?) • 4- Thebe (98) • 29- Helike (4) • 57- S/2003 J 23 (2) • 4- Atlas (32) • 36- Tarvos (15) • 4- Cressida (79.6) • Hydra (50?) • 5- Desdemona (64) • 30- Iocaste (5.2) • 58- S/2003 J 5 (4) • 5- Prometheus (100.2) • 37- Tarqeq (7) • Kerberos (13-34?) • 5- Io (3,643.2) • 6- Pandora (83.8) • 38- Greip (6) • 6- Juliet (93.6) • 1- Naiad (58) • 31- Ananke (28) • 59- Callirrhoe (7) • Styx (??) • 7- Epimetheus (119) • 39- Hyrrokkin (8) • 7- Portia (135.2) • 2- Thalassa (80) • 6- Europa (3,121.6) -

Cladistical Analysis of the Jovian Satellites. T. R. Holt1, A. J. Brown2 and D
47th Lunar and Planetary Science Conference (2016) 2676.pdf Cladistical Analysis of the Jovian Satellites. T. R. Holt1, A. J. Brown2 and D. Nesvorny3, 1Center for Astrophysics and Supercomputing, Swinburne University of Technology, Melbourne, Victoria, Australia [email protected], 2SETI Institute, Mountain View, California, USA, 3Southwest Research Institute, Department of Space Studies, Boulder, CO. USA. Introduction: Surrounding Jupiter there are multi- Results: ple satellites, 67 known to-date. The most recent classi- fication system [1,2], based on orbital characteristics, uses the largest member of the group as the name and example. The closest group to Jupiter is the prograde Amalthea group, 4 small satellites embedded in a ring system. Moving outwards there are the famous Galilean moons, Io, Europa, Ganymede and Callisto, whose mass is similar to terrestrial planets. The final and largest group, is that of the outer Irregular satel- lites. Those irregulars that show a prograde orbit are closest to Jupiter and have previously been classified into three families [2], the Themisto, Carpo and Hi- malia groups. The remainder of the irregular satellites show a retrograde orbit, counter to Jupiter's rotation. Based on similarities in semi-major axis (a), inclination (i) and eccentricity (e) these satellites have been grouped into families [1,2]. In order outward from Jupiter they are: Ananke family (a 2.13x107 km ; i 148.9o; e 0.24); Carme family (a 2.34x107 km ; i 164.9o; e 0.25) and the Pasiphae family (a 2:36x107 km ; i 151.4o; e 0.41). There are some irregular satellites, recently discovered in 2003 [3], 2010 [4] and 2011[5], that have yet to be named or officially classified. -
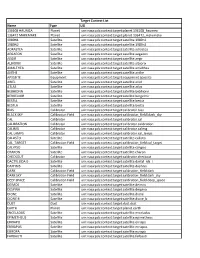
PDS4 Context List
Target Context List Name Type LID 136108 HAUMEA Planet urn:nasa:pds:context:target:planet.136108_haumea 136472 MAKEMAKE Planet urn:nasa:pds:context:target:planet.136472_makemake 1989N1 Satellite urn:nasa:pds:context:target:satellite.1989n1 1989N2 Satellite urn:nasa:pds:context:target:satellite.1989n2 ADRASTEA Satellite urn:nasa:pds:context:target:satellite.adrastea AEGAEON Satellite urn:nasa:pds:context:target:satellite.aegaeon AEGIR Satellite urn:nasa:pds:context:target:satellite.aegir ALBIORIX Satellite urn:nasa:pds:context:target:satellite.albiorix AMALTHEA Satellite urn:nasa:pds:context:target:satellite.amalthea ANTHE Satellite urn:nasa:pds:context:target:satellite.anthe APXSSITE Equipment urn:nasa:pds:context:target:equipment.apxssite ARIEL Satellite urn:nasa:pds:context:target:satellite.ariel ATLAS Satellite urn:nasa:pds:context:target:satellite.atlas BEBHIONN Satellite urn:nasa:pds:context:target:satellite.bebhionn BERGELMIR Satellite urn:nasa:pds:context:target:satellite.bergelmir BESTIA Satellite urn:nasa:pds:context:target:satellite.bestia BESTLA Satellite urn:nasa:pds:context:target:satellite.bestla BIAS Calibrator urn:nasa:pds:context:target:calibrator.bias BLACK SKY Calibration Field urn:nasa:pds:context:target:calibration_field.black_sky CAL Calibrator urn:nasa:pds:context:target:calibrator.cal CALIBRATION Calibrator urn:nasa:pds:context:target:calibrator.calibration CALIMG Calibrator urn:nasa:pds:context:target:calibrator.calimg CAL LAMPS Calibrator urn:nasa:pds:context:target:calibrator.cal_lamps CALLISTO Satellite urn:nasa:pds:context:target:satellite.callisto -

02. Solar System (2001) 9/4/01 12:28 PM Page 2
01. Solar System Cover 9/4/01 12:18 PM Page 1 National Aeronautics and Educational Product Space Administration Educators Grades K–12 LS-2001-08-002-HQ Solar System Lithograph Set for Space Science This set contains the following lithographs: • Our Solar System • Moon • Saturn • Our Star—The Sun • Mars • Uranus • Mercury • Asteroids • Neptune • Venus • Jupiter • Pluto and Charon • Earth • Moons of Jupiter • Comets 01. Solar System Cover 9/4/01 12:18 PM Page 2 NASA’s Central Operation of Resources for Educators Regional Educator Resource Centers offer more educators access (CORE) was established for the national and international distribution of to NASA educational materials. NASA has formed partnerships with universities, NASA-produced educational materials in audiovisual format. Educators can museums, and other educational institutions to serve as regional ERCs in many obtain a catalog and an order form by one of the following methods: States. A complete list of regional ERCs is available through CORE, or electroni- cally via NASA Spacelink at http://spacelink.nasa.gov/ercn NASA CORE Lorain County Joint Vocational School NASA’s Education Home Page serves as a cyber-gateway to informa- 15181 Route 58 South tion regarding educational programs and services offered by NASA for the Oberlin, OH 44074-9799 American education community. This high-level directory of information provides Toll-free Ordering Line: 1-866-776-CORE specific details and points of contact for all of NASA’s educational efforts, Field Toll-free FAX Line: 1-866-775-1460 Center offices, and points of presence within each State. Visit this resource at the E-mail: [email protected] following address: http://education.nasa.gov Home Page: http://core.nasa.gov NASA Spacelink is one of NASA’s electronic resources specifically devel- Educator Resource Center Network (ERCN) oped for the educational community. -

+ View the NASA Portal + Nearearth Object (NEO) Program Planetary Satellite Discovery Circumstances the Tables B
27/05/2015 Planetary Satellite Discovery Circumstances + View the NASA Portal Search JPL + NearEarth Object (NEO) Program Planetary Satellite Discovery Circumstances The tables below show the discovery circumstances of planetary satellites and satellites of Pluto officially recognized by the International Astronomical Union (IAU). A total of 177 planetary satellites (including those of Pluto but not Earth) are represented below. References are listed where known. These data were last updated 2015 Mar09. IAU IAU provisional year discoverer(s)/spacecraft mission references number name designation discovered Satellites of Mars: 2 I Phobos 1877 A. Hall II Deimos 1877 A. Hall Satellites of Jupiter: 67 I Io 1610 Galileo II Europa 1610 Galileo III Ganymede 1610 Galileo IV Callisto 1610 Galileo V Amalthea 1892 E.E. Barnard VI Himalia 1904 C. Perrine VII Elara 1905 C. Perrine VIII Pasiphae 1908 P. Melotte IX Sinope 1914 S.B. Nicholson X Lysithea 1938 S.B. Nicholson XI Carme 1938 S.B. Nicholson XII Ananke 1951 S.B. Nicholson XIII Leda 1974 C. Kowal XIV Thebe S/1979 J2 1980 Voyager Science Team XV Adrastea S/1979 J1 1979 Voyager Science Team XVI Metis S/1979 J3 1980 Voyager Science Team XVII Callirrhoe S/1999 J1 1999 J.V. Scotti, T.B. Spahr, IAUC 7460 R.S. McMillan, J.A. Larsen, J. Montani, A.E. Gleason, T. Gehrels XVIII Themisto S/1975 J1 2000 S.S. Sheppard, D.C. Jewitt, IAUC 7525 S/2000 J1 Y. Fernandez, G. Magnier XIX Megaclite S/2000 J8 2000 S.S. Sheppard, D.C. Jewitt, IAUC 7555 Y. -

Perfect Little Planet Educator's Guide
Educator’s Guide Perfect Little Planet Educator’s Guide Table of Contents Vocabulary List 3 Activities for the Imagination 4 Word Search 5 Two Astronomy Games 7 A Toilet Paper Solar System Scale Model 11 The Scale of the Solar System 13 Solar System Models in Dough 15 Solar System Fact Sheet 17 2 “Perfect Little Planet” Vocabulary List Solar System Planet Asteroid Moon Comet Dwarf Planet Gas Giant "Rocky Midgets" (Terrestrial Planets) Sun Star Impact Orbit Planetary Rings Atmosphere Volcano Great Red Spot Olympus Mons Mariner Valley Acid Solar Prominence Solar Flare Ocean Earthquake Continent Plants and Animals Humans 3 Activities for the Imagination The objectives of these activities are: to learn about Earth and other planets, use language and art skills, en- courage use of libraries, and help develop creativity. The scientific accuracy of the creations may not be as im- portant as the learning, reasoning, and imagination used to construct each invention. Invent a Planet: Students may create (draw, paint, montage, build from household or classroom items, what- ever!) a planet. Does it have air? What color is its sky? Does it have ground? What is its ground made of? What is it like on this world? Invent an Alien: Students may create (draw, paint, montage, build from household items, etc.) an alien. To be fair to the alien, they should be sure to provide a way for the alien to get food (what is that food?), a way to breathe (if it needs to), ways to sense the environment, and perhaps a way to move around its planet. -

385557Main Jupiter Facts1(2).Pdf
Jupiter Ratio (Jupiter/Earth) Io Europa Ganymede Callisto Metis Mass 1.90 x 1027 kg 318 15 3 Adrastea Amalthea Thebe Themisto Leda Volume 1.43 x 10 km 1320 National Aeronautics and Space Administration Equatorial Radius 71,492 km 11.2 Himalia Lysithea63 ElaraMoons S/2000 and Counting! Carpo Gravity 24.8 m/s2 2.53 Jupiter Euporie Orthosie Euanthe Thyone Mneme Mean Density 1330 kg/m3 0.240 Harpalyke Hermippe Praxidike Thelxinoe Distance from Sun 7.79 x 108 km 5.20 Largest, Orbit Period 4333 days 11.9 Helike Iocaste Ananke Eurydome Arche Orbit Velocity 13.1 km/sec 0.439 Autonoe Pasithee Chaldene Kale Isonoe Orbit Eccentricity 0.049 2.93 Fastest,Aitne Erinome Taygete Carme Sponde Orbit Inclination 1.3 degrees Kalyke Pasiphae Eukelade Megaclite Length of Day 9.93 hours 0.414 Strongest Axial Tilt 3.13 degrees 0.133 Sinope Hegemone Aoede Kallichore Callirrhoe Cyllene Kore S/2003 J2 • Composition: Almost 90% hydrogen, 10% helium, small amounts S/2003of ammonia, J3methane, S/2003 ethane andJ4 water S/2003 J5 • Jupiter is the largest planet in the solar system, in fact all the otherS/2003 planets J9combined S/2003 are not J10 as large S/2003 as Jupiter J12 S/2003 J15 S/2003 J16 S/2003 J17 • Jupiter spins faster than any other planet, taking less thanS/2003 10 hours J18 to rotate S/2003 once, which J19 causes S/2003 the planet J23 to be flattened by 6.5% relative to a perfect sphere • Jupiter has the strongest planetary magnetic field in the solar system, if we could see it from Earth it would be the biggest object in the sky • The Great Red Spot, -

Moon: Does It Have a Purpose
MOON: DOES IT HAVE A PURPOSE Zia H Shah MD “Allah it is Who made the sun radiate a brilliant light and the moon reflect a luster, and ordained for it stages, that you might learn the method of calculating the years and determining time. Allah has not created this system but for a purpose. He expounds the Signs in detail for a people who have knowledge. In the alternation of the night and the day, and in all that Allah has created in the heavens and the earth, there are many Signs for a people who are mindful of their duty to Allah.” (Al Quran 10:6-7) If you wonder what your life would be like without the moon, the surprising answer is that you wouldn't be here to wonder at all! Earth before the impact that created the moon for our planet was a totally different planet. So suggests a discovery channel documentary, if there were no moon: http://www.youtube.com/watch?v=HIQoP-R5A9w The main message of the documentary is that if there were no moon, there would have been no land based life on our planet. The Earth has a large moon, making it unique in the inner solar system. The inner Solar System, that is the habitable zone of our solar system, includes the planets Mercury, Venus, Earth and Mars. Mercury and Venus have no moons, and Mars has only two small asteroid-sized objects orbiting it. There are 139 moons in our solar system, but our moon enjoys some special features.