Strange Uniform Random Variables
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hausdorff Measure
Hausdorff Measure Jimmy Briggs and Tim Tyree December 3, 2016 1 1 Introduction In this report, we explore the the measurement of arbitrary subsets of the metric space (X; ρ); a topological space X along with its distance function ρ. We introduce Hausdorff Measure as a natural way of assigning sizes to these sets, especially those of smaller \dimension" than X: After an exploration of the salient properties of Hausdorff Measure, we proceed to a definition of Hausdorff dimension, a separate idea of size that allows us a more robust comparison between rough subsets of X. Many of the theorems in this report will be summarized in a proof sketch or shown by visual example. For a more rigorous treatment of the same material, we redirect the reader to Gerald B. Folland's Real Analysis: Modern techniques and their applications. Chapter 11 of the 1999 edition served as our primary reference. 2 Hausdorff Measure 2.1 Measuring low-dimensional subsets of X The need for Hausdorff Measure arises from the need to know the size of lower-dimensional subsets of a metric space. This idea is not as exotic as it may sound. In a high school Geometry course, we learn formulas for objects of various dimension embedded in R3: In Figure 1 we see the line segment, the circle, and the sphere, each with it's own idea of size. We call these length, area, and volume, respectively. Figure 1: low-dimensional subsets of R3: 2 4 3 2r πr 3 πr Note that while only volume measures something of the same dimension as the host space, R3; length, and area can still be of interest to us, especially 2 in applications. -

Caratheodory's Extension Theorem
Caratheodory’s extension theorem DBW August 3, 2016 These notes are meant as introductory notes on Caratheodory’s extension theorem. The presentation is not completely my own work; the presentation heavily relies on the pre- sentation of Noel Vaillant on http://www.probability.net/WEBcaratheodory.pdf. To make the line of arguments as clear as possible, the starting point is the notion of a ring on a topological space and not the notion of a semi-ring. 1 Elementary definitions and properties We fix a topological space Ω. The power set of Ω is denoted P(Ω) and consists of all subsets of Ω. Definition 1. A ring on on Ω is a subset R of P(Ω), such that (i) ∅ ∈ R (ii) A, B ∈ R ⇒ A ∪ B ∈ R (iii) A, B ∈ R ⇒ A \ B ∈ R Definition 2. A σ-algebra on Ω is a subset Σ of P(Ω) such that (i) ∅ ∈ Σ (ii) (An)n∈N ∈ Σ ⇒ ∪n An ∈ Σ (iii) A ∈ Σ ⇒ Ac ∈ Σ Since A∩B = A\(A\B) it follows that any ring on Ω is closed under finite intersections; c c hence any ring is also a semi-ring. Since ∩nAn = (∪nA ) it follows that any σ-algebra is closed under arbitrary intersections. And from A \ B = A ∩ Bc we deduce that any σ-algebra is also a ring. If (Ri)i∈I is a set of rings on Ω then it is clear that ∩I Ri is also a ring on Ω. Let S be any subset of P(Ω), then we call the intersection of all rings on Ω containing S the ring generated by S. -

Construction of Geometric Outer-Measures and Dimension Theory
Construction of Geometric Outer-Measures and Dimension Theory by David Worth B.S., Mathematics, University of New Mexico, 2003 THESIS Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science Mathematics The University of New Mexico Albuquerque, New Mexico December, 2006 c 2008, David Worth iii DEDICATION To my lovely wife Meghan, to whom I am eternally grateful for her support and love. Without her I would never have followed my education or my bliss. iv ACKNOWLEDGMENTS I would like to thank my advisor, Dr. Terry Loring, for his years of encouragement and aid in pursuing mathematics. I would also like to thank Dr. Cristina Pereyra for her unfailing encouragement and her aid in completing this daunting task. I would like to thank Dr. Wojciech Kucharz for his guidance and encouragement for the entirety of my adult mathematical career. Moreover I would like to thank Dr. Jens Lorenz, Dr. Vladimir I Koltchinskii, Dr. James Ellison, and Dr. Alexandru Buium for their years of inspirational teaching and their influence in my life. v Construction of Geometric Outer-Measures and Dimension Theory by David Worth ABSTRACT OF THESIS Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science Mathematics The University of New Mexico Albuquerque, New Mexico December, 2006 Construction of Geometric Outer-Measures and Dimension Theory by David Worth B.S., Mathematics, University of New Mexico, 2003 M.S., Mathematics, University of New Mexico, 2008 Abstract Geometric Measure Theory is the rigorous mathematical study of the field commonly known as Fractal Geometry. In this work we survey means of constructing families of measures, via the so-called \Carath´eodory construction", which isolate certain small- scale features of complicated sets in a metric space. -
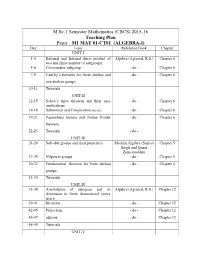
M.Sc. I Semester Mathematics (CBCS) 2015-16 Teaching Plan
M.Sc. I Semester Mathematics (CBCS) 2015-16 Teaching Plan Paper : M1 MAT 01-CT01 (ALGEBRA-I) Day Topic Reference Book Chapter UNIT-I 1-4 External and Internal direct product of Algebra (Agrawal, R.S.) Chapter 6 two and finite number of subgroups; 5-6 Commutator subgroup - do - Chapter 6 7-9 Cauchy’s theorem for finite abelian and - do - Chapter 6 non abelian groups. 10-11 Tutorials UNIT-II 12-15 Sylow’s three theorem and their easy - do - Chapter 6 applications 16-18 Subnormal and Composition series, - do - Chapter 6 19-21 Zassenhaus lemma and Jordan Holder - do - Chapter 6 theorem. 22-23 Tutorials - do - UNIT-III 24-26 Solvable groups and their properties Modern Algebra (Surjeet Chapter 5 Singh and Quazi Zameeruddin) 27-29 Nilpotent groups - do - Chapter 5 30-32 Fundamental theorem for finite abelian - do - Chapter 4 groups. 33-34 Tutorials UNIT-IV 35-38 Annihilators of subspace and its Algebra (Agrawal, R.S.) Chapter 12 dimension in finite dimensional vector space 39-41 Invariant, - do - Chapter 12 42-45 Projection, - do - Chapter 12 46-47 adjoins. - do - Chapter 12 48-49 Tutorials UNIT-V 50-54 Singular and nonsingular linear Algebra (Agrawal, R.S.) Chapter 12 transformation 55-58 quadratic forms and Diagonalization. - do - Chapter12 59-60 Tutorials - do - 61-65 Students Interaction & Difficulty solving - - M.Sc. I Semester Mathematics (CBCS) 2015-16 Teaching Plan Paper : M1 MAT 02-CT02 (REAL ANALYSIS) Day Topic Reference Book Chapter UNIT-I 1-2 Length of an interval, outer measure of a Theory and Problems of Chapter 2 subset of R, Labesgue outer measure of a Real Variables: Murray subset of R R. -

Section 17.5. the Carathéodry-Hahn Theorem: the Extension of A
17.5. The Carath´eodory-Hahn Theorem 1 Section 17.5. The Carath´eodry-Hahn Theorem: The Extension of a Premeasure to a Measure Note. We have µ defined on S and use µ to define µ∗ on X. We then restrict µ∗ to a subset of X on which µ∗ is a measure (denoted µ). Unlike with Lebesgue measure where the elements of S are measurable sets themselves (and S is the set of open intervals), we may not have µ defined on S. In this section, we look for conditions on µ : S → [0, ∞] which imply the measurability of the elements of S. Under these conditions, µ is then an extension of µ from S to M (the σ-algebra of measurable sets). ∞ Definition. A set function µ : S → [0, ∞] is finitely additive if whenever {Ek}k=1 ∞ is a finite disjoint collection of sets in S and ∪k=1Ek ∈ S, we have n n µ · Ek = µ(Ek). k=1 ! k=1 [ X Note. We have previously defined finitely monotone for set functions and Propo- sition 17.6 gives finite additivity for an outer measure on M, but this is the first time we have discussed a finitely additive set function. Proposition 17.11. Let S be a collection of subsets of X and µ : S → [0, ∞] a set function. In order that the Carath´eodory measure µ induced by µ be an extension of µ (that is, µ = µ on S) it is necessary that µ be both finitely additive and countably monotone and, if ∅ ∈ S, then µ(∅) = 0. -

2.5 Outer Measure and Measurable Sets. Note the Results of This Section Concern Any Given Outer Measure Λ
2.5 Outer Measure and Measurable sets. Note The results of this section concern any given outer measure ¸. If an outer measure ¸ on a set X were a measure then it would be additive. In particular, given any two sets A; B ⊆ X we have that A \ B and A \ Bc are disjoint with (A \ B) [ (A \ Bc) = A and so we would have ¸(A) = ¸(A \ B) + ¸(A \ Bc): We will see later that this does not necessarily hold for all A and B but it does lead to the following definition. Definition Let ¸ be an outer measure on a set X. Then E ⊆ X is said to be measurable with respect to ¸ (or ¸-measurable) if ¸(A) = ¸(A \ E) + ¸(A \ Ec) for all A ⊆ X. (7) (This can be read as saying that we take each and every possible “test set”, A, look at the measures of the parts of A that fall within and without E, and check whether these measures add up to that of A.) Since ¸ is subadditive we have ¸(A) · ¸(A\E)+¸(A\Ec) so, in checking measurability, we need only verify that ¸(A) ¸ ¸(A \ E) + ¸(A \ Ec) for all A ⊆ X. (8) Let M = M(¸) denote the collection of ¸-measurable sets. Theorem 2.6 M is a field. Proof Trivially Á and X are in M. Take any E1;E2 2 M and any test set A ⊆ X. Then c ¸(A) = ¸(A \ E1) + ¸(A \ E1): c Now apply the definition of measurability for E2 with the test set A \ E1 to get c c c c ¸(A \ E1) = ¸((A \ E1) \ E2) + ¸((A \ E1) \ E2) c c = ¸(A \ E1 \ E2) + ¸(A \ (E1 [ E2) ): Combining c c ¸(A) = ¸(A \ E1) + ¸(A \ E1 \ E2) + ¸(A \ (E1 [ E2) ): (9) 1 We hope to use the subadditivity of ¸ on the first two term on the right hand side of (9). -

2.1.3 Outer Measures and Construction of Measures Recall the Construction of Lebesgue Measure on the Real Line
CHAPTER 2. THE LEBESGUE INTEGRAL I 11 2.1.3 Outer measures and construction of measures Recall the construction of Lebesgue measure on the real line. There are various approaches to construct the Lebesgue measure on the real line. For example, consider the collection of finite union of sets of the form ]a; b]; ] − 1; b]; ]a; 1[ R: This collection is an algebra A but not a sigma-algebra (this has been discussed on p.7). A natural measure on A is given by the length of an interval. One attempts to measure the size of any subset S of R covering it by countably many intervals (recall also that R can be covered by countably many intervals) and we define this quantity by 1 1 X [ m∗(S) = inff jAkj : Ak 2 A;S ⊂ Akg (2.7) k=1 k=1 where jAkj denotes the length of the interval Ak. However, m∗(S) is not a measure since it is not additive, which we do not prove here. It is only sigma- subadditive, that is k k [ X m∗ Sn ≤ m∗(Sn) n=1 n=1 for any countable collection (Sn) of subsets of R. Alternatively one could choose coverings by open intervals (see the exercises, see also B.Dacorogna, Analyse avanc´eepour math´ematiciens)Note that the quantity m∗ coincides with the length for any set in A, that is the measure on A (this is surprisingly the more difficult part!). Also note that the sigma-subadditivity implies that m∗(A) = 0 for any countable set since m∗(fpg) = 0 for any p 2 R. -

PATHOLOGICAL 1. Introduction
PATHOLOGICAL APPLICATIONS OF LEBESGUE MEASURE TO THE CANTOR SET AND NON-INTEGRABLE DERIVATIVES PRICE HARDMAN WHITMAN COLLEGE 1. Introduction Pathological is an oft used word in the mathematical community, and in that context it has quite a different meaning than in everyday usage. In mathematics, something is said to be \pathological" if it is particularly poorly behaved or counterintuitive. However, this is not to say that mathe- maticians use this term in an entirely derisive manner. Counterintuitive and unexpected results often challenge common conventions and invite a reevalu- ation of previously accepted methods and theories. In this way, pathological examples can be seen as impetuses for mathematical progress. As a result, pathological examples crop up quite often in the history of mathematics, and we can usually learn a great deal about the history of a given field by studying notable pathological examples in that field. In addition to allowing us to weave historical narrative into an otherwise noncontextualized math- mematical discussion, these examples shed light on the boundaries of the subfield of mathematics in which we find them. It is the intention then of this piece to investigate the basic concepts, ap- plications, and historical development of measure theory through the use of pathological examples. We will develop some basic tools of Lebesgue mea- sure on the real line and use them to investigate some historically significant (and fascinating) examples. One such example is a function whose deriva- tive is bounded yet not Riemann integrable, seemingly in violation of the Fundamental Theorem of Calculus. In fact, this example played a large part in the development of the Lebesgue integral in the early years of the 20th century. -

Measure Theory 1 Measurable Spaces
Measure Theory 1 Measurable Spaces A measurable space is a set S, together with a nonempty collection, , of subsets of S, satisfying the following two conditions: S 1. For any A; B in the collection , the set1 A B is also in . S − S 2. For any A1; A2; , Ai . The elements of ·are· · 2calledS [measurable2 S sets. These two conditions are S summarized by saying that the measurable sets are closed under taking finite differences and countable unions. Think of S as the arena in which all the action (integrals, etc) will take place; and of the measurable sets are those that are \candidates for having a size". In some examples, all the measurable sets will be assigned a \size"; in others, only the smaller measurable sets will be (with the remaining mea- surable sets having, effectively “infinite size"). Several properties of measurable sets are immediate from the definition. 1. The empty set, , is measurable. [Since is nonempty, there exists some measurable set A.;So, A A = is measurable,S by condition 1 above.] − ; 2. For A and B any two measurable sets, A B, A B, and A B are all measurable. [The third is just condition 1\above.[For the second,− apply condition 2 to the sequence A; B; ; ; . For the first, note that ; ; · · · A B = A (A B): Use condition 1 twice.] It follows immediately, by rep\eated application− − of these facts, that the measurable sets are closed under taking any finite numbers of intersections, unions, and differences. 3. For A1; A2; measurable, their intersection, A , is also measurable. -

Bayesian Data Assimilation Based on a Family of Outer Measures
1 Bayesian data assimilation based on a family of outer measures Jeremie Houssineau and Daniel E. Clark Abstract—A flexible representation of uncertainty that remains way. This enabled new methods for multi-target filtering to be within the standard framework of probabilistic measure theory is derived, as in [9] and [19, Chapt. 4]. presented along with a study of its properties. This representation The proposed representation of uncertainty also enables the relies on a specific type of outer measure that is based on the measure of a supremum, hence combining additive and highly definition of a meaningful notion of pullback – as the inverse sub-additive components. It is shown that this type of outer of the usual concept of pushforward measure – that does measure enables the introduction of intuitive concepts such as not require a modification of the measurable space on which pullback and general data assimilation operations. the associated function is defined, i.e. it does not require the Index Terms—Outer measure; Data assimilation considered measurable function to be made bi-measurable. The structure of the paper is as follows. Examples of limitations encountered when using probability measures to INTRODUCTION represent uncertainty are given in Section I. The concepts of Uncertainty can be considered as being inherent to all types outer measure and of convolution of measures are recalled of knowledge about any given physical system and needs to be in Section II, followed by the introduction of the proposed quantified in order to obtain meaningful characteristics for the representation of uncertainty in Section III and examples of considered system. -

Another Method of Integration: Lebesgue Integral
Another method of Integration: Lebesgue Integral Shengjun Wang 2017/05 1 2 Abstract Centuries ago, a French mathematician Henri Lebesgue noticed that the Riemann Integral does not work well on unbounded functions. It leads him to think of another approach to do the integration, which is called Lebesgue Integral. This paper will briefly talk about the inadequacy of the Riemann integral, and introduce a more comprehensive definition of integration, the Lebesgue integral. There are also some discussion on Lebesgue measure, which establish the Lebesgue integral. Some examples, like Fσ set, Gδ set and Cantor function, will also be mentioned. CONTENTS 3 Contents 1 Riemann Integral 4 1.1 Riemann Integral . .4 1.2 Inadequacies of Riemann Integral . .7 2 Lebesgue Measure 8 2.1 Outer Measure . .9 2.2 Measure . 12 2.3 Inner Measure . 26 3 Lebesgue Integral 28 3.1 Lebesgue Integral . 28 3.2 Riemann vs. Lebesgue . 30 3.3 The Measurable Function . 32 CONTENTS 4 1 Riemann Integral 1.1 Riemann Integral In a first year \real analysis" course, we learn about continuous functions and their integrals. Mostly, we will use the Riemann integral, but it does not always work to find the area under a function. The Riemann integral that we studied in calculus is named after the Ger- man mathematician Bernhard Riemann and it is applied to many scientific areas, such as physics and geometry. Since Riemann's time, other kinds of integrals have been defined and studied; however, they are all generalizations of the Rie- mann integral, and it is hardly possible to understand them or appreciate the reasons for developing them without a thorough understanding of the Riemann integral [1]. -

Section 2.3. the Σ-Algebra of Lebesgue Measurable Sets
2.3. Lebesgue Measurable Sets 1 Section 2.3. The σ-Algebra of Lebesgue Measurable Sets Note. In Theorem 2.18 we will see that there are disjoint sets A and B such that m∗(A ∪· B) < m∗(A) + m∗(B) and so m∗ is not countably additive (it is not even finitely additive). We must have countable additivity in our measure in order to use it for integration. To accomplish this, we restrict m∗ to a smaller class than P(R) on which m∗ is countably additive. As we will see, the following condition will yield a collection of sets on which m∗ is countably additive. Definition. Any set E is (Lebesgue) measurable if for all A ⊂ R, m∗(A) = m∗(A ∩ E) + m∗(A ∩ Ec). This is called the Carath´eodory splitting condition. Note. It certainly isn’t clear that the Carath´eodory splitting condition leads to countable additivity, but notice that it does involve the sum of measures of two disjoint sets (A ∩ E and A ∩ Ec). Note. The Carath´eodory splitting condition, in a sense, requires us to “check” all ℵ2 subsets A of R in order to establish the measurability of a set E. It is shown in Problem 2.20 that if m∗(E) < ∞, then E is measurable if and only if m∗((a, b)) = m∗((a, b)∩E)+m∗((a, b)∩Ec). This is a significant result, since there are “only” ℵ1 intervals of the form (a, b). 2.3. Lebesgue Measurable Sets 2 Note. Recall that we define a function to be Riemann integrable if the upper Riemann integral equals the lower Riemann integral.